详解python中文编码问题
目录
- 1. 在Python中使用中文
- 1.1 Windows控制台
- 1.2 Windows IDLE(在Shell上运行)
- 1.3 在IDLE上运行代码
- 1.4 Windows Eclipse
- 1.5 从文件读取中文
- 1.6 在数据库中使用中文
- 1.7 在XML中使用中文
1. 在Python中使用中文
在Python中有两种默认的字符串:str和unicode。在Python中一定要注意区分“Unicode字符串”和“unicode对象”的区别。后面所有的“unicode字符串”指的都是python里的“unicode对象”。
事实上在Python中并没有“Unicode字符串”这样的东西,只有“unicode”对象。一个传统意义上的unicode字符串完全可以用str对象表示。只是这时候它仅仅是一个字节流,除非解码为unicode对象,没有任何实际的意义。
我们用“哈哈”在多个平台上测试,其中“哈”对应的不同编码是:
1. UNICODE (UTF8-16), C854;
2. UTF-8, E59388;
3. GBK, B9FE。
1.1 Windows控制台
下面是在windows控制台的运行结果:
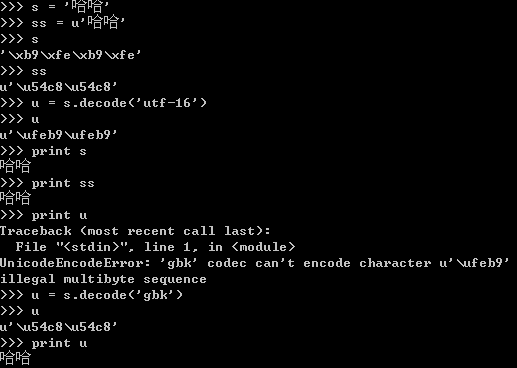
可以看出在控制台,中文字符的编码是GBK而不是UTF-16。将字符串s(GBK编码)使用decode进行解码后,可以得到同等的unicode对象。
注意:可以在控制台打印ss并不代表它可以直接被序列化,比如:

向文件直接输出ss会抛出同样的异常。在处理unicode中文字符串的时候,必须首先对它调用encode函数,转换成其它编码输出。这一点对各个环境都一样。
总结:在Python中,“str”对象就是一个字节数组,至于里面的内容是不是一个合法的字符串,以及这个字符串采用什么编码(gbk, utf-8, unicode)都不重要。这些内容需要用户自己记录和判断。这些的限制也同样适用于“unicode”对象。要记住“unicode”对象中的内容可绝对不一定就是合法的unicode字符串,我们很快就会看到这种情况。
总结:在windows的控制台上,支持gbk编码的str对象和unicode编码的unicode对象。
1.2 Windows IDLE(在Shell上运行)
在windows下的IDLE中,运行效果和windows控制台不完全一致:

可以看出,对于不使用“u”作标识的字符串,IDLE把其中的中文字符进行GBK编码。但是对于使用“u”的unicode字符串,IDLE居然一样是用了GBK编码,不同的是,这时候每一个字符都是unicode(对象)字符!!此时len(ss) = 4。
这样产生了一个神奇的问题,现在的ss无法在IDLE中正常显示。而且我也没有办法把ss转换成正常的编码!比如采用下面的方法:

这有可能是因为IDLE本地化做得不够好,对中文的支持有问题。建议在IDLE的SHELL中,不要使用u“中文”这种方式,因为这样得到的并不是你想要的东西。
这同时说明IDLE的Shell支持两种格式的中文字符串:GBK编码的“str”对象,和UNICODE编码的unicode对象。
1.3 在IDLE上运行代码
在IDLE的SHELL上运行文件,得到的又是不同的结果。文件的内容是:

直接运行的结果是:

毫无瑕疵,相当令人满意。我没有试过其它编码的文件是否能正常运行,但想来应该是不错的。
同样的代码在windows的控制台试演过,也没有任何问题。
1.4 Windows Eclipse
在Eclipse中处理中文更加困难,因为在Eclipse中,编写代码和运行代码属于不同的窗口,而且他们可以有不同的默认编码。对于如下代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
s = "哈哈"
ss = u'哈哈'
print repr(s)
print repr(ss)
print s.decode('utf-8').encode('gbk')
print ss.encode('gbk')
print s.decode('utf-8')
print ss
前四个print运行正常,最后两个print都会抛出异常:
'/xe5/x93/x88/xe5/x93/x88'
u'/u54c8/u54c8'
哈哈
哈哈
Traceback (most recent call last):
File "E:/Workspace/Eclipse/TestPython/Test/test_encoding_2.py", line 13, in <module>
print s.decode('utf-8')
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
也就是说,GBK编码的str对象可以正常打印,但是不能打印UNICODE编码的unicode对象。在源文件上点击“Run as”“Run”,然后在弹出对话框中选择“Common”:

可以看出Eclipse控制台的缺省编码方式是GBK;所以不支持UNICODE也在情理之中。如果把文件中的coding修改成GBK,则可以直接打印GBK编码的str对象,比如s。
如果把源文件的编码设置成“UTF-8”,把控制台的编码也设置成“UTF-8”,按道理说打印的时候应该没有问题。但是实验表明,在打印UTF-8编码的str对象时,中文的最后一个字符会显示成乱码,无法正常阅读。不过我已经很满足了,至少人家没有抛异常不是:)
BTW: 使用的Eclipse版本是3.2.1。
1.5 从文件读取中文
在window下面用记事本编辑文件的时候,如果保存为UNICODE或UTF-8,分别会在文件的开头加上两个字节 “/xFF/xFE” 和三个字节“/xEF/xBB/xBF”。在读取的时候就可能会遇到问题,但是不同的环境对这几个多于字符的处理也不一样。
以windows下的控制台为例,用记事本保存三个不同版本的“哈哈”。

打开utf-8格式的文件并读取utf-8字符串后,解码变成unicode对象。但是会把附加的三个字符同样进行转换,变成一个unicode字符,字符的数据值为“/xFF/xFE”。这个字符不能被打印。编码的时候需要跳过这个字符。

打开unicode格式的文件后,得到的字符串正确。这时候适用utf-16解码,能得到正确的unicdoe对象,可以直接使用。多余的那个填充字符在进行转换时会被过滤掉。

打开ansi格式的文件后,没有填充字符,可以直接使用。
结论:读写使用python生成的文件没有任何问题,但是在处理由notepad生成的文本文件时,如果该文件可能是非ansi编码,需要考虑如何处理填充字符。
1.6 在数据库中使用中文
刚刚接触Python,我用的数据库是mysql。在执行插入、查找等操作时,如果运行环境使用的字符编码和mysql不一致,就可能导致运行时的错误。当然,和上面看到的情况一样,运行环境并不是关键因素,关键是查询语句的编码方式。如果在每次执行查询操作时都把查询字符串做一次编码转换,转变成mysql的默认字符编码,一样不会遇到问题。但是这样写代码也太痛苦了吧。
使用如下代码连接数据库:
self.conn = MySQLdb.connect(use_unicode = 1, charset='utf8', **server)
我不能理解的是既然数据库用的默认编码是UTF-8,我连接的时候也用的是UTF-8,为什么查询得到的文本内容却是UNICODE编码(unicode对象)?这是MySQLdb库的设置么?
1.7 在XML中使用中文
使用xml.dom.minidom和MySQLdb类似,对生成的dom对象调用toxml方法得到的是unicode对象。如果希望输出utf-8文本,有两种方法:
1.使用系统函数
在输出xml文档的时候进行编码,这是我觉得最好的方法。
xmldoc.toxml(encoding='utf-8') xmldoc.writexml(outfile, encoding = ‘utf-8')
2.自己编码生成
在使用toxml之后可以调用encode方法对文档进行编码。但这种方法无法得到合适的xml declaration(xml文档第一行中的encoding部分)。
不要尝试通过xmldoc.createProcessingInstruction来创建一个processing instraction:
<?xml version='1.0' encoding='utf-8'?>
xml declaration虽然看起来像是,但是事实上并不是一个processing instraction。可以通下面的方法得到一个满意的xml文件:
print >> outfile, “<?xml version='1.0' encoding='utf-8'?>” print >> outfile, xmldoc.toxml().encode(‘utf-8')[22:]
其中第二行需要过滤掉在调用xmldoc.toxml时生成的“<?xml version='1.0' ?>”,它的长度是22。
相面是两种方法的用法比较:

另外,在IDLE的shell中,不要用 u'中文' 对属性进行赋值。上面讨论过,这样得到的unicode字符串不正确。
到此这篇关于python中文编码问题的文章就介绍到这了,更多相关中文编码内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python基础之编码规范总结
一.PEP 8规范 官方文档:https://legacy.python.org/dev/peps/pep-0008/ 中文翻译: https://www.jb51.net/article/103944.htm 二.缩进 每一级缩进4个空格. 续行应该与包裹元素对齐,要么使用圆括号,方括号,花括号内的隐式行连接来垂直对齐,要么使用挂行缩进对齐.当使用挂行缩进对齐时,应该考虑到第一行不应该有参数,以及使用缩进以区分自己是续行. 对齐缩进(左右括号对齐) def long_function_name
-

Python新建项目自动添加介绍和utf-8编码的方法
你是不是觉得每次新建项目都要写一次# coding:utf-8,感觉特烦人 呐!懒(fu)人(li)教程来啦,先看效果图吧 中文版 如图进入设置 然后将下列内容粘贴进去就行了,是不是很简单 """ -*- coding:utf-8 -*- Author:${USER} Age:24 Call:199**9**9*9 Email:nsq88@vip.qq.com Time: ${DATE} ${TIHE} Software: ${PRODUCT_NAME} "&quo
-
python中字符串的编码与解码详析
1. 常用的编码 ASCII:只能表示一些字母,数字和特殊的字符,占一个字节 GBK:国家简体中文字符集和繁体字符集,兼容ASCII,占两个字节 Unicode:能够表示全世界上所有的字符,Unicode有人说占4个字节也有人说占2个字节,但中文占2个字节 UTF-8:Unicode的压缩版,占1~3个字节,其中中文占三个字节 2.补充:计算机表示的单位: bit: 位,计算机最小的表示单位 bytes:字节,最小的存储单位,1bytes=8bit,1bytes简写成1B 1KB = 1024B
-
Python之进行URL编码案例讲解
为什么要对URL进行encode 在写网络爬虫时,发现提交表单中的中文字符都变成了TextBox1=%B8%C5%C2%CA%C2%DB这种样子,观察这是中文对应的GB2312编码,实际上是进行了GB2312编码和urlencode. 那么为什么要对URL进行encode? 因为在标准的url规范中中文和很多的字符是不允许出现在url中的.为了字符编码(gbk.utf-8)和特殊字符不出现在url中,url转义是为了符合url的规范. 具体代码 urlencode编码:urllib中的quote
-
python 编码中为什么要写类型注解?
1.背景 我们先谈谈为什么在Python编码过程中强烈推荐使用类型注解 ? Python对于初学者来说是非常好上手,原因是在于对计算机底层原理的高度封装和动态语言的特性使得Python用起来非常的舒适.但这种"舒适"是有代价的,我们可能听说过一句形容动态语言的话,动态一时爽,一直动态一直爽.为什么会这么说?动态的确会赋予我们在编码时更多的灵活性与能力,但是动态带来的是更多的不确定性及混乱,导致了后来的维护者甚至作者自己都会产生很大的维护压力(可以想象一个经过几年迭代的复杂系统,如果大部
-
Python3 json模块之编码解码方法讲解
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它基于ECMAScript的一个子集. JSON采用完全独立于语言的文本格式,这些特性使JSON成为理想的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成,在接口数据开发和传输中非常常用. Python3中我们利用内置模块json解码和编码JSON对象.json模块提供了四个功能: dumps.dump.loads.load dumps 把数据类型转换成字符串 dump 把数据类型转换成字符串
-
解决python3 中的np.load编码问题
由于在Python2 中的默认编码为ASCII,但是在Python3中的默认编码为UTF-8. 问题: 所以在使用np.load(det.npy)的时候会出现错误提示: you may need to pass the encoding= option to numpy.load 解决方法: 当遇到这种情况的时候,用np.load(det.npy,encoding="latin1")就可以了. 补充:python解决numpy导入乱码问题------已解决 使用numpy的loadtx
-
python源文件的字符编码知识点详解
默认情况下,Python 源码文件以 UTF-8 编码方式处理.在这种编码方式中,世界上大多数语言的字符都可以同时用于字符串字面值.变量或函数名称以及注释中--尽管标准库中只用常规的 ASCII 字符作为变量或函数名,而且任何可移植的代码都应该遵守此约定.要正确显示这些字符,你的编辑器必须能识别 UTF-8 编码,而且必须使用能支持打开的文件中所有字符的字体. 1.如果不使用默认编码,要声明文件所使用的编码,文件的第一行要写成特殊的注释. 语法如下所示: # -*- coding: encodi
-
详解python中文编码问题
目录 1. 在Python中使用中文 1.1 Windows控制台 1.2 Windows IDLE(在Shell上运行) 1.3 在IDLE上运行代码 1.4 Windows Eclipse 1.5 从文件读取中文 1.6 在数据库中使用中文 1.7 在XML中使用中文 1. 在Python中使用中文 在Python中有两种默认的字符串:str和unicode.在Python中一定要注意区分"Unicode字符
-
详解python里使用正则表达式的分组命名方式
详解python里使用正则表达式的分组命名方式 分组匹配的模式,可以通过groups()来全部访问匹配的元组,也可以通过group()函数来按分组方式来访问,但是这里只能通过数字索引来访问,如果某一天产品经理需要修改需求,让你在它们之中添加一个分组,这样一来,就会导致匹配的数组的索引的变化,作为开发人员的你,必须得一行一行代码地修改.因此聪明的开发人员又想到一个好方法,把这些分组进行命名,只需要对名称进行访问分组,不通过索引来访问了,就可以避免这个问题.那么怎么样来命名呢?可以采用(?P<nam
-
详解Python实现多进程异步事件驱动引擎
本文介绍了详解Python实现多进程异步事件驱动引擎,分享给大家,具体如下: 多进程异步事件驱动逻辑 逻辑 code # -*- coding: utf-8 -*- ''' author: Jimmy contact: 234390130@qq.com file: eventEngine.py time: 2017/8/25 上午10:06 description: 多进程异步事件驱动引擎 ''' __author__ = 'Jimmy' from multiprocessing import
-
详解Python import方法引入模块的实例
详解Python import方法引入模块的实例 在Python用import或者from-import或者from-import-as-来导入相应的模块,作用和使用方法与C语言的include头文件类似.其实就是引入某些成熟的函数库和成熟的方法,避免重复造轮子,提高开发速度. python的import方法可以引入系统的模块,也可以引入我们自己写好的共用模块,这点和PHP非常相似,但是它们的具体细节还不是很一样.因为php是在引入的时候指明引入文件的具体路径,而python中不能够写文件路径进
-
详解python中executemany和序列的使用方法
详解python中executemany和序列的使用方法 一 代码 import sqlite3 persons=[ ("Jim","Green"), ("Hu","jie") ] conn=sqlite3.connect(":memory:") conn.execute("CREATE TABLE person(firstname,lastname)") conn.executeman
-
详解Python 序列化Serialize 和 反序列化Deserialize
详解Python 序列化Serialize 和 反序列化Deserialize 序列化 (serialization) 序列化是将对象状态转换为可保持或传输的格式的过程.与序列化相对的是反序列化, 它将流转换为对象.这两个过程结合起来,可以轻松地存储和传输数据. 序列化和反序列化的目的 1.以某种存储形式使自定义对象持久化: 2.将对象从一个地方传递到另一个地方. 3.使程序更具维护性 序列化 由于存在于内存中的对象都是暂时的,无法长期驻存,为了把对象的状态保持下来,这时需要把对象写入到磁盘
-
详解python里使用正则表达式的全匹配功能
详解python里使用正则表达式的全匹配功能 python中很多匹配,比如搜索任意位置的search()函数,搜索边界的match()函数,现在还需要学习一个全匹配函数,就是搜索的字符与内容全部匹配,它就是fullmatch()函数. 例子如下: #python 3.6 #蔡军生 #http://blog.csdn.net/caimouse/article/details/51749579 # import re text = 'This is some text -- with punctua
-
详解python实现读取邮件数据并下载附件的实例
详解python实现读取邮件数据并下载附件的实例 实现结果图: 实现代码: #!/usr/bin/python2.7 # _*_ coding: utf-8 _*_ """ @Author: MarkLiu """ import poplib import email from email.parser import Parser from email.header import decode_header from email.utils im
-
详解Python 模拟实现生产者消费者模式的实例
详解Python 模拟实现生产者消费者模式的实例 散仙使用python3.4模拟实现的一个生产者与消费者的例子,用到的知识有线程,队列,循环等,源码如下: Python代码 import queue import time import threading import random q=queue.Queue(5) #生产者 def pr(): name=threading.current_thread().getName() print(name+"线程启动......") for
-
详解 Python 读写XML文件的实例
详解 Python 读写XML文件的实例 Python 生成XML文件 from xml.dom import minidom # 生成XML文件方式 def generateXml(): impl = minidom.getDOMImplementation() # 创建一个xml dom # 三个参数分别对应为 :namespaceURI, qualifiedName, doctype doc = impl.createDocument(None, None, None) # 创建根元素 r