mysql多主双向和级联复制
目录
- 一.解读
- 二.web设计
- 三.mysql设计
- 四、实操
- 1.mysql架构图(草稿)
- 2.配置
前言:
公司项目需求,要做一个内网用的物品管理的web系统,其中一个要求是要每个单位的本地PC在内网离线状态下(即无法访问总服务器)也能使用系统的服务。项目架构设计的是在线状态时访问总服务器,离线时,用户访问本地服务(是的,我们在每个本地PC上也部署了服务)。
注:
下级单位的本地PC能访问到总服务器时,称为在线,反之称为离线
一.解读
在离线状态的切换,对于web服务来说没什么影响,毕竟代码是一样的,所以不管部署在哪都一样。区别就是数据库中的数据。这就要求我们的主库,以及每个本机PC上部署的从库,他们之间能实现数据的自主同步。
关于可能的冲突,我们已经在业务层规避掉了。不同的单位,不会update相同的字段。不同的单位,不会在相同的表中insert。所以现在就只用关心mysql的自动同步,以及离线重连的自动续传了。
二.web设计
1.web后端,我设置了读写分离(只是为了装一下,其实大可不必,毕竟内网并发量不高)
2.在线时,单位的访问,均select本地mysql,update/insert/delete总服务器mysql
3.离线时,单位的访问,均在本地mysql
(这很好实现,不同的域名地址,对应不同的项目,项目内提前设定好数据库router,由用户自主决定访问哪个域名地址即可。实际上,如果断网了,总服务器访问不通,他会自然而然的去访问本机服务的域名地址)
三.mysql设计
1.同步方式毋庸置疑用的是mysql自带的binlog,mysql版本要选择5.7及以上的版本
2.多主双向:每个本机PC上的mysql,要与总服务器上的mysql保持双主同步。
3.总服务器要开启级联复制,将下级单位PC产生的binlog,同步给其他单位的PC。以便其他单位的PC在离线时可以使用这部分数据
四、实操
1.mysql架构图(草稿)
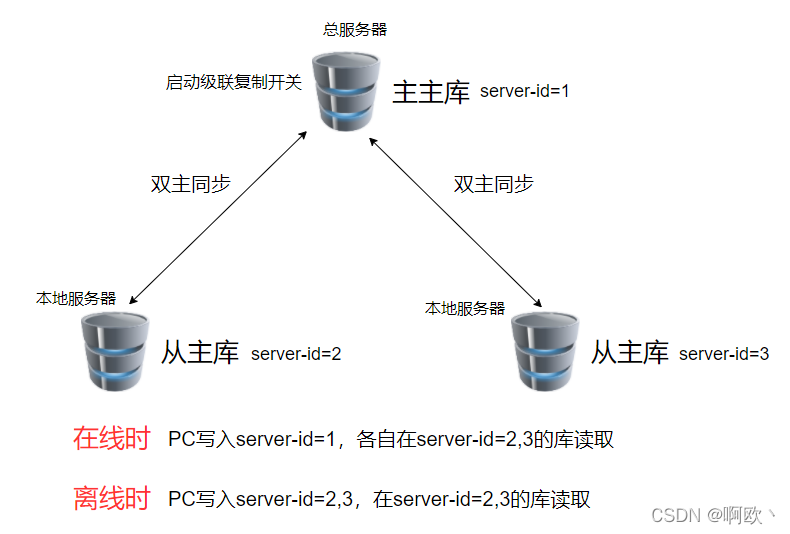
2.配置
一阶段,先把所有库的master功能启动,同时在库中创建访问账号供其他库使用:
主主库(总服务器)
①在mysql安装路径下找到启动文件my.ini或my.cnf,将如下信息放在启动文件的[mysqld]下:
log_bin=mysql-bin binlog_format=MIXED sync_binlog=1 expire_logs_days=7 binlog-do-db=equip_system slave-skip-errors=all master_info_repository=table relay_log_info_repository=table log-slave-updates=1
各参数的释义:
log_bin=mysql-bin:配置为mysql-bin时,mysql开启binlog功能
binlog_format=MIXED:binlog的记录方式,MIXED为混合记录方式
sync_binlog=1:
触发binlog由缓存刷新到磁盘所需要提交的事务数量,默认为0表示由磁盘文件系统控制,为1表示每提交一个事务即刷新一次(此时最安全,服务异常时丢失的事务最多只有1个,但IO消耗最大,高并发下忌用),常见的DBA一般设置为100。本项目并发量低,可设置为1expire_logs_days=7:binlog有效时长,设置为7表示binlog存在7天后删除binlog-do-db=equip_system:要同步的数据库名slave-skip-errors=all:表示同步出现异常时要跳过哪些异常,设置为all表示所有异常的同步都直接跳过不管。是否可以设置为all,要结合项目的具体业务。本项目可以。master_info_repository=table:可选< table | file >,设置为table更稳定,重启服务时可以自动续传relay_log_info_repository=table:可选< table | file >,设置为table更稳定,重启服务时可以自动续传
log-slave-updates=1:配置为1表示开启级联复制
记得修改server-id,架构内互联的mysql均不能相同
server-id=100
②重启sql服务
③进入mysql命令行,执行以下命令
values为ON表示开启binlog成功
show variables like '%log_bin%';
有几个从主库,就创建几个账号,注意这个账号密码提前确定好记好,搞乱了就很头大:
CREATE USER '被同步库的账号名'@'被同步库的ip' IDENTIFIED BY '被同步库账号的密码'; GRANT REPLICATION SLAVE ON *.* TO '被同步库的账号名'@'被同步库的ip';
刷新权限:
flush privileges;
查看master状态:
show master status;
返回结果:

这个形如"mysql-bin.000003"的值要记录上,从主库连接时要用
主主库的一阶段配置完成了
从主库:
①在mysql安装路径下找到启动文件my.ini或my.cnf,将如下信息放在启动文件的[mysqld]下:
log_bin=mysql-bin binlog_format=MIXED sync_binlog=1 expire_logs_days=7 binlog-do-db=equip_system slave-skip-errors=all master_info_repository=table relay_log_info_repository=table
以上参数和主主库是一样的,区别在于从主库不需要开启级联复制。记得修改server-id
后边过程和主主库的配置是一样的,毕竟都是开启master功能的,这里就不赘述了。把产出的形如"mysql-bin.000003"的值记录下来就好了
一阶段各个库的master功能配置完成
二阶段,配置各个库的slave功能,即将其与要同步的库建立连接
从主库只需跟主主库建立连接即可
在mysql命令行中执行以下命令:
设置连接master的参数:
CHANGE MASTER TO MASTER_HOST='要同步的对方库的ip', MASTER_PORT=对方库的端口号, MASTER_USER='对方库为你创建的账号名', MASTER_PASSWORD='对方库为你创建的密码',MASTER_LOG_FILE='对方库master状态产出的File的值';
启动slave建立连接:
start slave;
查看连接状态:
show slave status\G
返回结果:
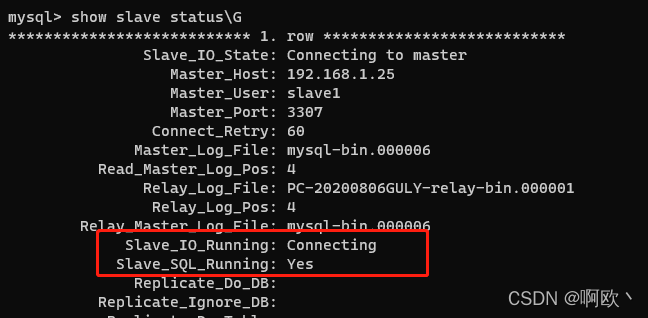
两个Running都为Yes时,表示连接成功了。不成功请自行查阅资料debug。我这里是对方库没开。
其余从主库操作一样,都是设置连接参数、启动slave建立连接、查看连接状态
主主库:
主主库流程同样是设置连接参数、启动slave建立连接、查看连接状态。不同点在于要设置多个master连接参数,所以设置连接参数的命令有一个小的变化,要多一个通道channel的设置,命令如下:
配置与从主库2的连接参数
CHANGE MASTER TO MASTER_HOST='从主库1的ip', MASTER_PORT='从主库1的端口号', MASTER_USER='从主库1为你创建的账号名', MASTER_PASSWORD='从主库1为你创建的密码',MASTER_LOG_FILE='从主库1的master状态的File值'for channel '1';
配置与从主库2的连接参数:
CHANGE MASTER TO MASTER_HOST='从主库2的ip', MASTER_PORT='从主库2的端口号', MASTER_USER='从主库2为你创建的账号名', MASTER_PASSWORD='从主库2为你创建的密码',MASTER_LOG_FILE='从主库2的master状态的File值'for channel '2';
有几个配几个:
...
启动slave:
start slave;
查看slave状态:
show slave status\G
返回结果有多个status,依次查看,依次核对即可。
结语:
该架构具有高可用强稳定的特性:具有多主一从,一主多从,双主架构的所有优势:1.上方多增加一个主主库2,形成双机热备提高容灾能力;2.增加大量从主库,进行读写分离,提高高并发下的性能;3.内网离线产生的数据在切换至在线状态时自动同步至所有其他库;
到此这篇关于mysql多主双向和级联复制的文章就介绍到这了,更多相关mysql多主双向+级联复制内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL8.0.18配置多主一从
目录 1. 现实背景 2. 约定 3. 配置 master 3.1. 配置启动参数 3.2. 重启服务使参数生效 3.3. 以 root 身份登录,创建用户,赋予密码,授权,刷新权限 4. 配置 slave 服务器 4.1. 配置启动参数 4.2. 重启服务使参数生效 5. 配置多主一从 5.1. 查看 master 状态 5.2. 配置 slave 与 master 的关联 5.3. 准备表 5.4. 启动 slave,查看 slave 状态 1. 现实背景 现有 4 台主机,均能够自动地采集
-
Mysql实现主从配置和多主多从配置
我们现在模拟的是主从(1台主机.一台从机),其主从同步的原理,就是对bin-log二进制文件的同步,将这个文件的内容从主机同步到从机. 一.配置文件的修改 1.主机配置文件修改配置 我们首先需要mysql主机(192.168.254.130)的/etc/my.cnf配置文件,添加如下配置: #主机唯一ID server-id=1 #二进制日志 log-bin=mysql-bin #不需要同步的数据库 binlog-ignore-db=mysql binlog-ignore-db=informat
-

mysql多主双向和级联复制
目录 一.解读 二.web设计 三.mysql设计 四.实操 1.mysql架构图(草稿) 2.配置 前言: 公司项目需求,要做一个内网用的物品管理的web系统,其中一个要求是要每个单位的本地PC在内网离线状态下(即无法访问总服务器)也能使用系统的服务.项目架构设计的是在线状态时访问总服务器,离线时,用户访问本地服务(是的,我们在每个本地PC上也部署了服务). 注:下级单位的本地PC能访问到总服务器时,称为在线,反之称为离线 一.解读 在离线状态的切换,对于web服务来说没什么影响,毕竟代码是一
-
实现mysql级联复制的方法示例
所谓级联复制就是master服务器,只给一台slave服务器同步数据,然后slave服务器在向后端的所有slave服务器同步数据,降低master服务器的写压力,和复制数据的网络IO. 一,配置master服务器 1,修改主配置文件 vim /etc/my.cnf 在[mysql]配置块下添加如下两行配置 [mysql] log_bin #开启二进制日志功能 server_id=1 #为当前节点设置一个全局惟一的ID号 2,重启mysql服务,使配置生效 systemctl restart ma
-
MYSQL 完全备份、主从复制、级联复制、半同步小结
mysql 完全备份 1,启用二进制日志,并于数据库分离,单独存放 vim /etc/my.cnf 添加 log_bin=/data/bin/mysql-bin 创建/data/bin文件夹并授权 chown mysql.mysql /data/bin 2,完成备份数据库 mysqldump -A --single-transaction --master-data=2 | xz > /data/all.sql.xz 3,对数据库进行增删改 INSERT hellodb.students(stu
-
MySQL级联复制下如何进行大表的字段扩容
目录 MySQL级联复制下进行大表的字段扩容 一.背景 二.库表信息 三.方案选择 四.如何进行操作 五.总结 MySQL级联复制下进行大表的字段扩容 作者:雷文霆 爱可生华东交付服务部 DBA 成员,主要负责Mysql故障处理及相关技术支持.爱好看书,电影.座右铭,每一个不曾起舞的日子,都是对生命的辜负. 本文来源:原创投稿 *爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源. 一.背景 某客户的业务中有一张约4亿行的表,因为业务扩展,表中open_id varcha
-
MySQL高可用解决方案MMM(mysql多主复制管理器)
一.MMM简介: MMM即Multi-Master Replication Manager for MySQL:mysql多主复制管理器,基于perl实现,关于mysql主主复制配置的监控.故障转移和管理的一套可伸缩的脚本套件(在任何时候只有一个节点可以被写入),MMM也能对从服务器进行读负载均衡,所以可以用它来在一组用于复制的服务器启动虚拟ip,除此之外,它还有实现数据备份.节点之间重新同步功能的脚本.MySQL本身没有提供replication failover的解决方案,通过MMM方案能实
-
MySQL GTID主备不一致的修复方案
目录 方案一:重建 Replicas 前提条件 优点 缺点 操作步骤 Master Slave 方案二:使用percona-toolkit进行数据修复 前提条件 优点 缺点 操作步骤 背景示例 校验一致性 方案一:重建 Replicas MySQL 5.6及以上版在复制中引入了新的全局事务ID(GTID)支持. 在启用了GTID模式的情况下执行MySQL和MySQL 5.7的备份时,Percona XtraBackup会自动将GTID值存储在xtrabackup_binlog_info中. 该信
-
MySQL双主(主主)架构配置方案
在企业中,数据库高可用一直是企业的重中之重,中小企业很多都是使用mysql主从方案,一主多从,读写分离等,但是单主存在单点故障,从库切换成主库需要作改动.因此,如果是双主或者多主,就会增加mysql入口,增加高可用.不过多主需要考虑自增长ID问题,这个需要特别设置配置文件,比如双主,可以使用奇偶,总之,主之间设置自增长ID相互不冲突就能完美解决自增长ID冲突问题. 主从同步复制原理 在开始之前,我们先来了解主从同步复制原理. 复制分成三步: 1. master将改变记录到二进制日志(binary
-
Mysql一主多从部署的实现步骤
目录 1.下载地址 2.下载tar.gz包 3.安装 1.linux系统上创建mysql1用户 2.将tar.gz包上传到服务器上并且解压 3.将mysql-5.7.31-el7-x86_64目录下的文件mv到 /home/mysql1下 4.mkdir -p /home/mysql1/data 文件存储mysql1数据目录 5.将/etc/my.cfg文件复制到mysql家目录下 6.对/home/mysql1下赋权 7.修改mysql配置文件 8.数据文件初始化 4.使用mysql客户端da
-
Mysql双主配置的详细步骤
目录 前言 一.mysql配置文件 (1)节点A配置 (2)节点B配置 二.配置节点A为节点B的master(主从模式) 三.完成双主配置 四.测试 五.控制同步的库或表 六.一个账号多个IP 总结 前言 特点:在双主配置中,两台mysql互为主从节点.节点A是节点B的master,同时节点B也是节点A的master. 安装mysql步骤略过 一.mysql配置文件 (1)节点A配置 # 设置server-id,两节点必须不一样 server-id = 100 # 开启bin_log,模式为RO
-
详解MySQL主从复制实战 - 基于GTID的复制
基于GTID的复制 简介 基于GTID的复制是MySQL 5.6后新增的复制方式. GTID (global transaction identifier) 即全局事务ID, 保证了在每个在主库上提交的事务在集群中有一个唯一的ID. 在原来基于日志的复制中, 从库需要告知主库要从哪个偏移量进行增量同步, 如果指定错误会造成数据的遗漏, 从而造成数据的不一致. 而基于GTID的复制中, 从库会告知主库已经执行的事务的GTID的值, 然后主库会将所有未执行的事务的GTID的列表返回给从库. 并且可