SpringBoot结合Quartz实现数据库存储
目录
- 一、先创建一个SpringBoot项目
- 二、导入依赖
- 三、 导入DruidConnectionProvider.java(Druid连接池的Quartz扩展类)
- 四、 修改自定义quartz.properties配置(在项目中添加quartz.properties文件(这样就不会加载自带的properties文件) )
- 五、自定义MyJobFactory,解决spring不能在quartz中注入bean的问题
- 六、创建调度器schedule
- 七、 创建自定义任务
- 八、 更新quartz中的任务
- 小结:
一、先创建一个SpringBoot项目

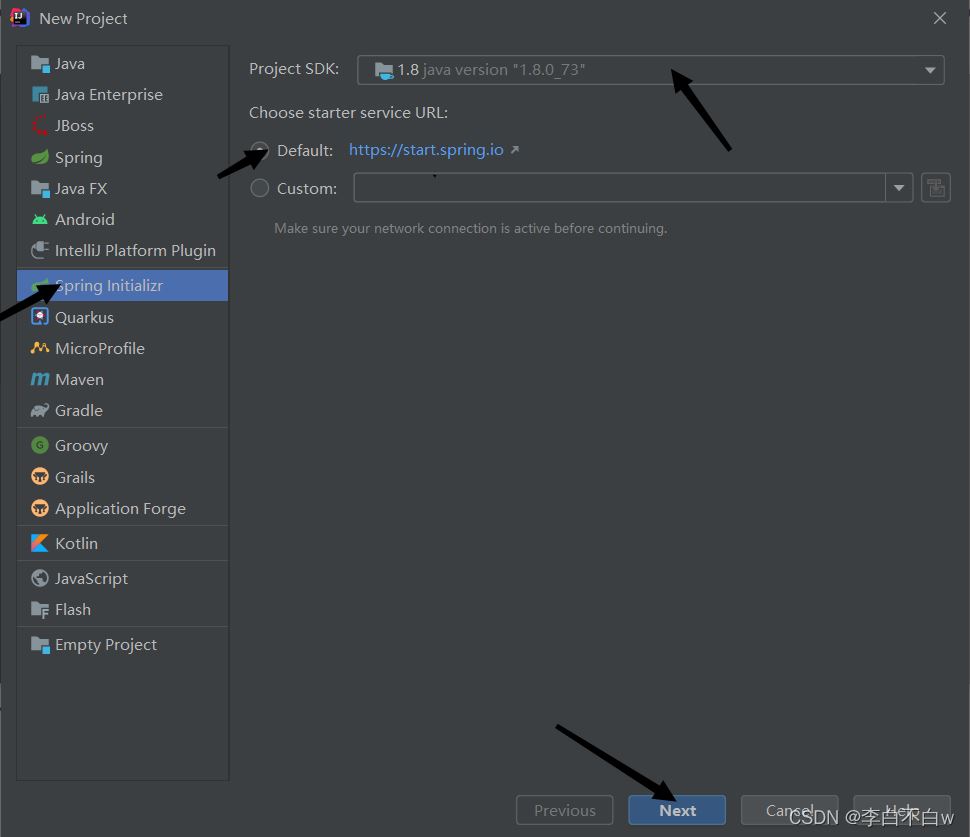
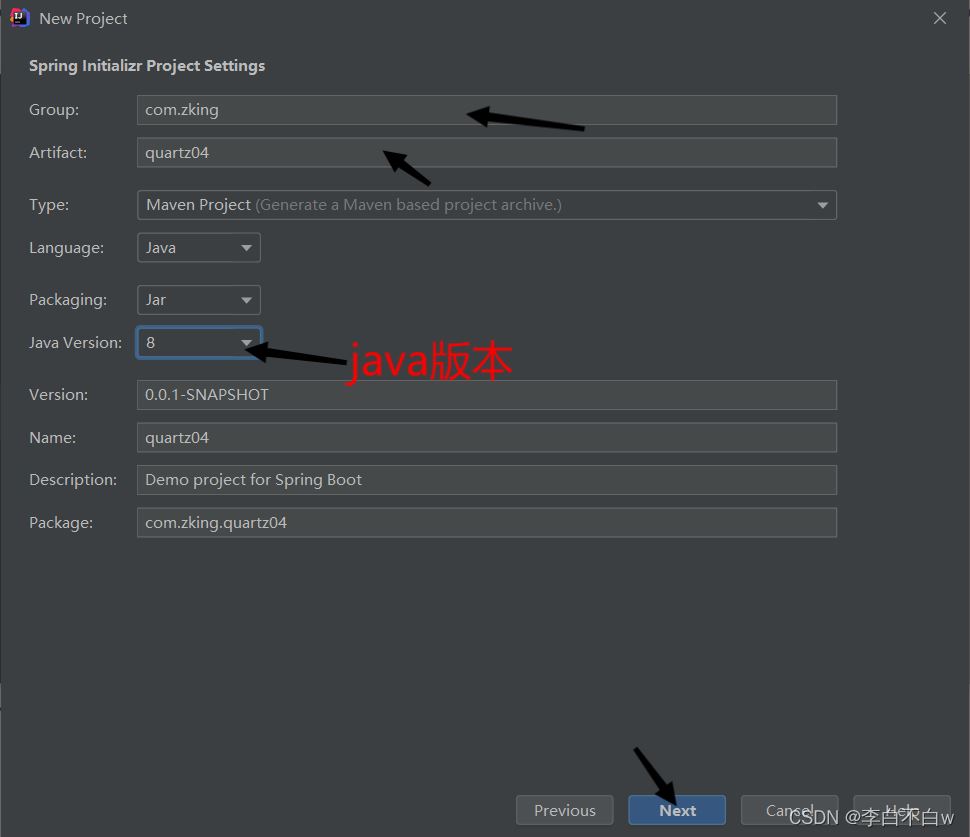
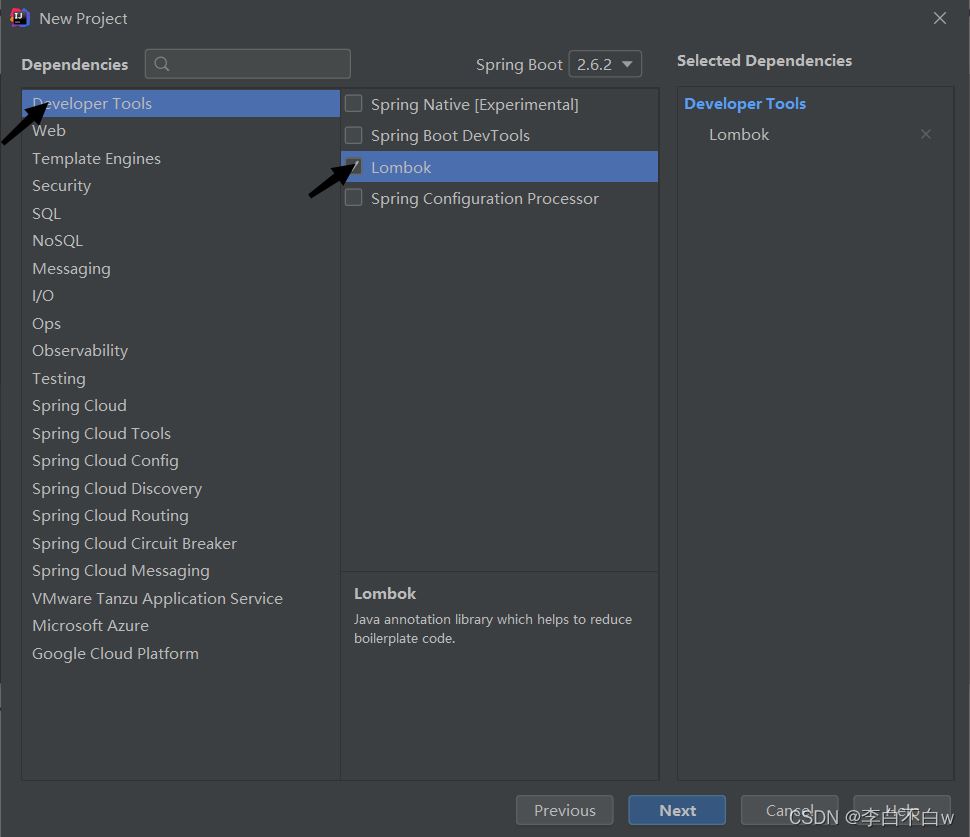
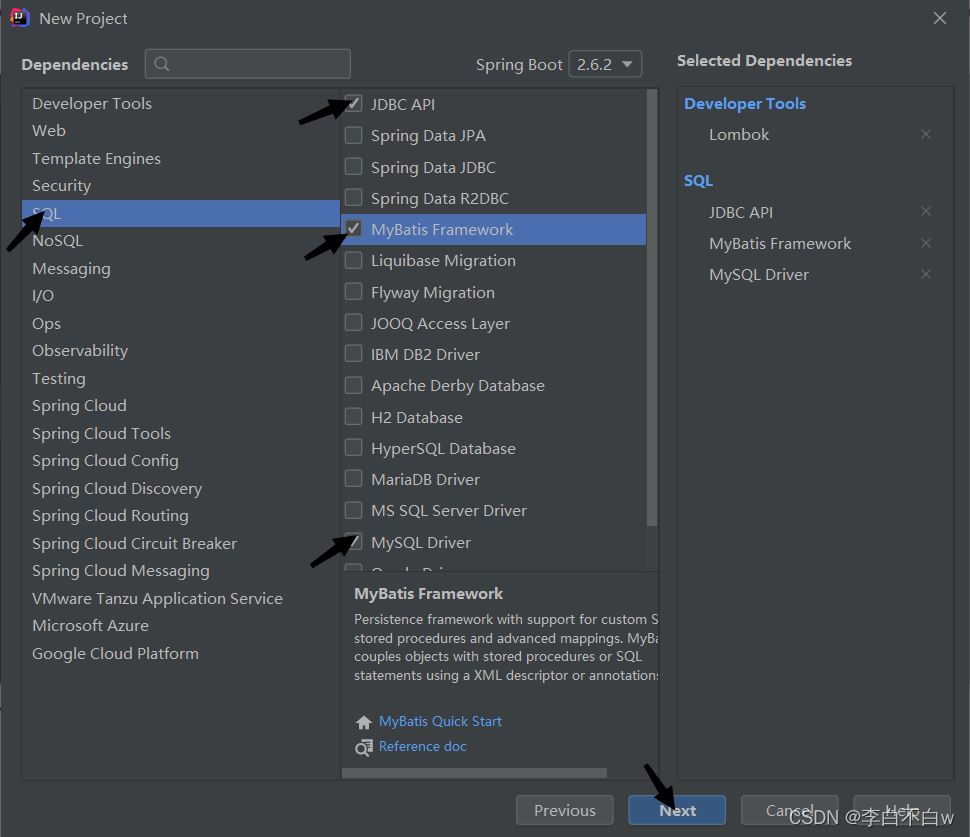
还有一个截屏忘了截屏,就是选择保存路径选择一下就点Finish就可以了。
更改application.properties为application.yml
application.yml文件如下
server:
port: 8080
#数据库连接池druid配置
spring:
datasource:
#1.JDBC
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/quartz?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false
username: root
password: 123
druid:
#2.连接池配置
#初始化连接池的连接数量 大小,最小,最大
initial-size: 5
min-idle: 5
max-active: 20
#配置获取连接等待超时的时间
max-wait: 60000
#配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
time-between-eviction-runs-millis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 30000
validation-query: SELECT 1 FROM DUAL
test-while-idle: true
test-on-borrow: true
test-on-return: false
# 是否缓存preparedStatement,也就是PSCache 官方建议MySQL下建议关闭 个人建议如果想用SQL防火墙 建议打开
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filter:
stat:
merge-sql: true
slow-sql-millis: 5000
#3.基础监控配置
web-stat-filter:
enabled: true
url-pattern: /*
#设置不统计哪些URL
exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"
session-stat-enable: true
session-stat-max-count: 100
stat-view-servlet:
enabled: true
url-pattern: /druid/*
reset-enable: true
#设置监控页面的登录名和密码
login-username: admin
login-password: admin
allow: 127.0.0.1
mybatis:
mapper-locations: classpath*:mapper/*.xml
type-aliases-package: com.zking.quartz02.model
二、导入依赖
1.导入Quartz依赖
<dependency> <groupId>org.quartz-scheduler</groupId> <artifactId>quartz-jobs</artifactId> <version>2.2.1</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-quartz</artifactId> </dependency>
2.用于我用的是Druid数据库连接池,所以我需要更换成Druid连接池,先引入Druid依赖。
<dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.10</version> </dependency>
三、 导入DruidConnectionProvider.java(Druid连接池的Quartz扩展类)
package com.zking.quartz02.utils;
import com.alibaba.druid.pool.DruidDataSource;
import org.quartz.SchedulerException;
import org.quartz.utils.ConnectionProvider;
import java.sql.Connection;
import java.sql.SQLException;
/*
#============================================================================
# JDBC
#============================================================================
org.quartz.jobStore.driverDelegateClass:org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.useProperties:false
org.quartz.jobStore.dataSource:qzDS
#org.quartz.dataSource.qzDS.connectionProvider.class:org.quartz.utils.PoolingConnectionProvider
org.quartz.dataSource.qzDS.connectionProvider.class:com.zking.q03.quartz.DruidConnectionProvider
org.quartz.dataSource.qzDS.driver:com.mysql.jdbc.Driver
org.quartz.dataSource.qzDS.URL:jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=UTF-8
org.quartz.dataSource.qzDS.user:root
org.quartz.dataSource.qzDS.password:root
org.quartz.dataSource.qzDS.maxConnections:30
org.quartz.dataSource.qzDS.validationQuery: select 0
*/
/**
* [Druid连接池的Quartz扩展类]
*/
public class DruidConnectionProvider implements ConnectionProvider {
/*
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
*
* 常量配置,与quartz.properties文件的key保持一致(去掉前缀),同时提供set方法,Quartz框架自动注入值。
*
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
*/
//JDBC驱动
public String driver;
//JDBC连接串
public String URL;
//数据库用户名
public String user;
//数据库用户密码
public String password;
//数据库最大连接数
public int maxConnection;
//数据库SQL查询每次连接返回执行到连接池,以确保它仍然是有效的。
public String validationQuery;
private boolean validateOnCheckout;
private int idleConnectionValidationSeconds;
public String maxCachedStatementsPerConnection;
private String discardIdleConnectionsSeconds;
public static final int DEFAULT_DB_MAX_CONNECTIONS = 10;
public static final int DEFAULT_DB_MAX_CACHED_STATEMENTS_PER_CONNECTION = 120;
//Druid连接池
private DruidDataSource datasource;
/*
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
*
* 接口实现
*
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
*/
public Connection getConnection() throws SQLException {
return datasource.getConnection();
}
public void shutdown() throws SQLException {
datasource.close();
}
public void initialize() throws SQLException{
if (this.URL == null) {
throw new SQLException("DBPool could not be created: DB URL cannot be null");
}
if (this.driver == null) {
throw new SQLException("DBPool driver could not be created: DB driver class name cannot be null!");
}
if (this.maxConnection < 0) {
throw new SQLException("DBPool maxConnectins could not be created: Max connections must be greater than zero!");
}
datasource = new DruidDataSource();
try{
datasource.setDriverClassName(this.driver);
} catch (Exception e) {
try {
throw new SchedulerException("Problem setting driver class name on datasource: " + e.getMessage(), e);
} catch (SchedulerException e1) {
}
}
datasource.setUrl(this.URL);
datasource.setUsername(this.user);
datasource.setPassword(this.password);
datasource.setMaxActive(this.maxConnection);
datasource.setMinIdle(1);
datasource.setMaxWait(0);
datasource.setMaxPoolPreparedStatementPerConnectionSize(this.DEFAULT_DB_MAX_CACHED_STATEMENTS_PER_CONNECTION);
if (this.validationQuery != null) {
datasource.setValidationQuery(this.validationQuery);
if(!this.validateOnCheckout)
datasource.setTestOnReturn(true);
else
datasource.setTestOnBorrow(true);
datasource.setValidationQueryTimeout(this.idleConnectionValidationSeconds);
}
}
/*
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
*
* 提供get set方法
*
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
*/
public String getDriver() {
return driver;
}
public void setDriver(String driver) {
this.driver = driver;
}
public String getURL() {
return URL;
}
public void setURL(String URL) {
this.URL = URL;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public int getMaxConnection() {
return maxConnection;
}
public void setMaxConnection(int maxConnection) {
this.maxConnection = maxConnection;
}
public String getValidationQuery() {
return validationQuery;
}
public void setValidationQuery(String validationQuery) {
this.validationQuery = validationQuery;
}
public boolean isValidateOnCheckout() {
return validateOnCheckout;
}
public void setValidateOnCheckout(boolean validateOnCheckout) {
this.validateOnCheckout = validateOnCheckout;
}
public int getIdleConnectionValidationSeconds() {
return idleConnectionValidationSeconds;
}
public void setIdleConnectionValidationSeconds(int idleConnectionValidationSeconds) {
this.idleConnectionValidationSeconds = idleConnectionValidationSeconds;
}
public DruidDataSource getDatasource() {
return datasource;
}
public void setDatasource(DruidDataSource datasource) {
this.datasource = datasource;
}
}
四、 修改自定义quartz.properties配置(在项目中添加quartz.properties文件(这样就不会加载自带的properties文件) )
# #============================================================================ # Configure Main Scheduler Properties \u8C03\u5EA6\u5668\u5C5E\u6027 #============================================================================ org.quartz.scheduler.instanceName: DefaultQuartzScheduler org.quartz.scheduler.instanceId = AUTO org.quartz.scheduler.rmi.export: false org.quartz.scheduler.rmi.proxy: false org.quartz.scheduler.wrapJobExecutionInUserTransaction: false org.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool org.quartz.threadPool.threadCount= 10 org.quartz.threadPool.threadPriority: 5 org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: true org.quartz.jobStore.misfireThreshold: 60000 #============================================================================ # Configure JobStore #============================================================================ #\u5B58\u50A8\u65B9\u5F0F\u4F7F\u7528JobStoreTX\uFF0C\u4E5F\u5C31\u662F\u6570\u636E\u5E93 org.quartz.jobStore.class: org.quartz.impl.jdbcjobstore.JobStoreTX org.quartz.jobStore.driverDelegateClass:org.quartz.impl.jdbcjobstore.StdJDBCDelegate #\u4F7F\u7528\u81EA\u5DF1\u7684\u914D\u7F6E\u6587\u4EF6 org.quartz.jobStore.useProperties:true #\u6570\u636E\u5E93\u4E2Dquartz\u8868\u7684\u8868\u540D\u524D\u7F00 org.quartz.jobStore.tablePrefix:qrtz_ org.quartz.jobStore.dataSource:qzDS #\u662F\u5426\u4F7F\u7528\u96C6\u7FA4\uFF08\u5982\u679C\u9879\u76EE\u53EA\u90E8\u7F72\u5230 \u4E00\u53F0\u670D\u52A1\u5668\uFF0C\u5C31\u4E0D\u7528\u4E86\uFF09 org.quartz.jobStore.isClustered = true #============================================================================ # Configure Datasources #============================================================================ #\u914D\u7F6E\u6570\u636E\u5E93\u6E90 org.quartz.dataSource.qzDS.connectionProvider.class: com.zking.quartz02.utils.DruidConnectionProvider org.quartz.dataSource.qzDS.driver: com.mysql.cj.jdbc.Driver #修改为自己的数据库名称、用户名和密码 org.quartz.dataSource.qzDS.URL: jdbc:mysql://localhost:3306/quartz?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false org.quartz.dataSource.qzDS.user: root org.quartz.dataSource.qzDS.password: 123 org.quartz.dataSource.qzDS.maxConnection: 10
在数据库中创建quartz相关的表
进入quartz的官网http://www.quartz-scheduler.org/,点击Downloads,
下载后在目录\docs\dbTables下有常用数据库创建quartz表的脚本,例如:“tables_mysql.sql”
五、自定义MyJobFactory,解决spring不能在quartz中注入bean的问题
package com.zking.quartz02.quartz;
import org.quartz.spi.TriggerFiredBundle;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.config.AutowireCapableBeanFactory;
import org.springframework.scheduling.quartz.AdaptableJobFactory;
import org.springframework.stereotype.Component;
//解决spring不能在quartz中注入bean的问题
@Component
public class MyJobFactory extends AdaptableJobFactory {
@Autowired
private AutowireCapableBeanFactory autowireCapableBeanFactory;
@Override
protected Object createJobInstance(TriggerFiredBundle bundle) throws Exception {
Object jobInstance = super.createJobInstance(bundle);
autowireCapableBeanFactory.autowireBean(jobInstance);
return jobInstance;
}
}
六、创建调度器schedule
package com.zking.quartz02.quartz;
//quartz配置类将调度器交给spring管理
import org.quartz.Scheduler;
import org.quartz.SchedulerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.config.PropertiesFactoryBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.scheduling.quartz.SchedulerFactoryBean;
import java.io.IOException;
import java.util.Properties;
@Configuration
public class QuartzConfiguration {
@Autowired
private MyJobFactory myJobFactory;
@Bean
public Scheduler scheduler(){
return this.getSchedulerFactoryBean().getScheduler();
}
//读取自定义配置文件,获取调度器工厂
@Bean
public SchedulerFactoryBean getSchedulerFactoryBean(){
//1.创建SchedulerFactoryBean sc=new SchedulerFactoryBean
SchedulerFactoryBean sc=new SchedulerFactoryBean();
//2.加载自定义的quartz.properties
sc.setQuartzProperties(this.getProperties());
//3.设置自定义的MyJobFactory
sc.setJobFactory(myJobFactory);
return sc;
}
//读取配置文件
@Bean
public Properties getProperties(){
try {
PropertiesFactoryBean propertiesFactoryBean =
new PropertiesFactoryBean();
//设置自定义配置文件位置
propertiesFactoryBean.setLocation(new ClassPathResource("/quartz.properties"));
//读取配置文件
propertiesFactoryBean.afterPropertiesSet();
return propertiesFactoryBean.getObject();
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
七、 创建自定义任务
首先我们需要自己创建一张表t_schedule_trigger,用来存放trigger的信息,然后从数据库读取这些信息来随时更新定时任务
注意:job_name存放的任务类的全路径,在quartz中通过jobName和jobGroup来确定trigger的唯一性,所以这两列为联合唯一索引
t_schedule_trigger和t_schedule_trigger_param表生成的sql代码如下(去执行一下sql语句即可)
-- 注意:job_name存放的任务类的全路径,在quartz中通过jobName和jobGroup来确定trigger的唯一性,所以这两列为联合唯一索引 create table t_schedule_trigger ( id int primary key auto_increment, -- ID cron varchar(200) not null, -- 时间表达式 status char(1) not null, -- 使用状态 0:禁用 1:启用 job_name varchar(200) not null, -- 任务名称 job_group varchar(200) not null, -- 任务分组 unique index(job_name,job_group) ); -- 额外添加到任务中的参数 create table t_schedule_trigger_param ( param_id int primary key auto_increment, -- ID name varchar(200) not null, -- 参数名 value varchar(512), -- 参数值 schedule_trigger_id int not null, -- 外键:引用t_schedule_trigger(id) foreign key(schedule_trigger_id) references t_schedule_trigger(id) );
注1:t_schedule_trigger的子表t_schedule_trigger_param还可以用来传递额外添加到任务中的参数
注2:实现org.quartz.Job或org.springframework.scheduling.quartz.QuartzJobBean创建任务,可通过JobExecutionContext传参
八、 更新quartz中的任务
首先我们将t_schedule_trigger和t_schedule_trigger_param通过generatorConfig.xml自动生成实体类,XXmapper.java,XXmapper.xml.
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE generatorConfiguration PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd" >
<generatorConfiguration>
<!-- 引入配置文件 -->
<!-- <properties resource="jdbc.properties"/>-->
<!--指定数据库jdbc驱动jar包的位置-->
<classPathEntry location="D:\\installpath\\apache-maven-3.5.4\\jar\\mysql\\mysql-connector-java\\5.1.44\\mysql-connector-java-5.1.44.jar"/>
<!-- 一个数据库一个context -->
<context id="infoGuardian">
<!-- 注释 -->
<commentGenerator>
<property name="suppressAllComments" value="true"/><!-- 是否取消注释 -->
<property name="suppressDate" value="true"/> <!-- 是否生成注释代时间戳 -->
</commentGenerator>
<!-- jdbc连接 -->
<jdbcConnection driverClass="com.mysql.jdbc.Driver"
connectionURL="jdbc:mysql://localhost:3306/quartz?useUnicode=true&characterEncoding=UTF-8" userId="root" password="123"/>
<!-- 类型转换 -->
<javaTypeResolver>
<!-- 是否使用bigDecimal, false可自动转化以下类型(Long, Integer, Short, etc.) -->
<property name="forceBigDecimals" value="false"/>
</javaTypeResolver>
<!-- 01 指定javaBean生成的位置 -->
<!-- targetPackage:指定生成的model生成所在的包名 -->
<!-- targetProject:指定在该项目下所在的路径 -->
<javaModelGenerator targetPackage="com.zking.quartz02.model"
targetProject="src/main/java">
<!-- 是否允许子包,即targetPackage.schemaName.tableName -->
<property name="enableSubPackages" value="false"/>
<!-- 是否对model添加构造函数 -->
<property name="constructorBased" value="true"/>
<!-- 是否针对string类型的字段在set的时候进行trim调用 -->
<property name="trimStrings" value="false"/>
<!-- 建立的Model对象是否 不可改变 即生成的Model对象不会有 setter方法,只有构造方法 -->
<property name="immutable" value="false"/>
</javaModelGenerator>
<!-- 02 指定sql映射文件生成的位置 -->
<sqlMapGenerator targetPackage="mapper"
targetProject="src/main/resources">
<!-- 是否允许子包,即targetPackage.schemaName.tableName -->
<property name="enableSubPackages" value="false"/>
</sqlMapGenerator>
<!-- 03 生成XxxMapper接口 -->
<!-- type="ANNOTATEDMAPPER",生成Java Model 和基于注解的Mapper对象 -->
<!-- type="MIXEDMAPPER",生成基于注解的Java Model 和相应的Mapper对象 -->
<!-- type="XMLMAPPER",生成SQLMap XML文件和独立的Mapper接口 -->
<javaClientGenerator targetPackage="com.zking.quartz02.mapper"
targetProject="src/main/java" type="XMLMAPPER">
<!-- 是否在当前路径下新加一层schema,false路径com.oop.eksp.user.model, true:com.oop.eksp.user.model.[schemaName] -->
<property name="enableSubPackages" value="false"/>
</javaClientGenerator>
<!-- 配置表信息 -->
<!-- schema即为数据库名 -->
<!-- tableName为对应的数据库表 -->
<!-- domainObjectName是要生成的实体类 -->
<!-- enable*ByExample是否生成 example类 -->
<!--<table schema="" tableName="t_book" domainObjectName="Book"-->
<!--enableCountByExample="false" enableDeleteByExample="false"-->
<!--enableSelectByExample="false" enableUpdateByExample="false">-->
<!--<!– 忽略列,不生成bean 字段 –>-->
<!--<!– <ignoreColumn column="FRED" /> –>-->
<!--<!– 指定列的java数据类型 –>-->
<!--<!– <columnOverride column="LONG_VARCHAR_FIELD" jdbcType="VARCHAR" /> –>-->
<!--</table>-->
<table schema="" tableName="t_schedule_trigger_param" domainObjectName="ScheduleTriggerParam"
enableCountByExample="false" enableDeleteByExample="false"
enableSelectByExample="false" enableUpdateByExample="false">
<!-- 忽略列,不生成bean 字段 -->
<!-- <ignoreColumn column="FRED" /> -->
<!-- 指定列的java数据类型 -->
<!-- <columnOverride column="LONG_VARCHAR_FIELD" jdbcType="VARCHAR" /> -->
</table>
<table schema="" tableName="t_schedule_trigger" domainObjectName="ScheduleTrigger"
enableCountByExample="false" enableDeleteByExample="false"
enableSelectByExample="false" enableUpdateByExample="false">
<!-- 忽略列,不生成bean 字段 -->
<!-- <ignoreColumn column="FRED" /> -->
<!-- 指定列的java数据类型 -->
<!-- <columnOverride column="LONG_VARCHAR_FIELD" jdbcType="VARCHAR" /> -->
</table>
</context>
</generatorConfiguration>
记得修改数据库jdbc驱动jar包的位置为自己数据库jdbc驱动jar包的位置,jdbc连接数据库名、用户名和密码改为自己的。
注意:targetPackage改成自己的包名。
自动生成操作

命令:mybatis-generator:generate -e
注意:实体类上加一个@Data,XXmapper.java上加一个@Repository自己需要写一个查询全部的方法。
写一个IScheduleService接口,用来定时刷新任务,更新调度器中的任务
package com.zking.quartz02.service;
public interface IScheduleService {
//定时刷新任务,更新调度器中的任务
public void refresh();
}
实现IScheduleService接口
package com.zking.quartz02.service.impl;
import com.zking.quartz02.mapper.ScheduleTriggerMapper;
import com.zking.quartz02.mapper.ScheduleTriggerParamMapper;
import com.zking.quartz02.model.ScheduleTrigger;
import com.zking.quartz02.model.ScheduleTriggerParam;
import com.zking.quartz02.service.IScheduleService;
import org.quartz.*;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.List;
@Service
public class ScheduleServiceImpl implements IScheduleService {
@Resource
private ScheduleTriggerMapper scheduleTriggerMapper;
@Resource
private ScheduleTriggerParamMapper scheduleTriggerParamMapper;
@Resource
private Scheduler scheduler;
@Scheduled(cron = "*/10 * * * * ?")
@Override
public void refresh() {
try {
//1.查询数据库中所有的任务
List<ScheduleTrigger> scheduleTriggers =
scheduleTriggerMapper.listScheduleTrigger();
//2.遍历所有任务
for (ScheduleTrigger scheduleTrigger : scheduleTriggers) {
Integer id = scheduleTrigger.getId();
String cron = scheduleTrigger.getCron();
String status = scheduleTrigger.getStatus();
String jobName = scheduleTrigger.getJobName();
String jobGroup = scheduleTrigger.getJobGroup();
//设置triggerKey
TriggerKey triggerKey = TriggerKey.triggerKey(jobName, jobGroup);
//通过triggerKey获取调度器中的触发器
CronTrigger cronTrigger = (CronTrigger)scheduler.getTrigger(triggerKey);
if(null==cronTrigger){//如果为空,表示调度器中没有该任务,不存在就添加任务
if("0".equals(status)){//如果该任务状态为0,表示该任务不用添加,此次循环结束
continue;
}
//创建触发器
CronTrigger cronTrigger1 = TriggerBuilder.newTrigger()
.withIdentity(jobName, jobGroup)
.withSchedule(CronScheduleBuilder.cronSchedule(cron))
.build();
//创建工作详情实例
JobDetail jobDetail = JobBuilder.newJob((Class<? extends Job>) Class.forName(jobName))
.withIdentity(jobName, jobGroup)
.build();
JobDataMap jobDataMap = jobDetail.getJobDataMap();
//查询该任务中所有的参数
List<ScheduleTriggerParam> scheduleTriggerParams = scheduleTriggerParamMapper.listScheduleTriggerParamById(id);
//遍历所有参数,将参数设置到jobDataMap中
for (ScheduleTriggerParam scheduleTriggerParam : scheduleTriggerParams) {
jobDataMap.put(scheduleTriggerParam.getName(),scheduleTriggerParam.getValue());
}
//添加任务,将触发器和工作详情实例添加到调度器中
scheduler.scheduleJob(jobDetail,cronTrigger1);
}else{//如果不为空,表示调度器中存在该任务
if("0".equals(status)){//如果任务状态改为禁用,移除该任务
JobKey jobKey = JobKey.jobKey(jobName, jobGroup);
scheduler.deleteJob(jobKey);//移除任务
}
//如果调度器中的触发器的表达式和数据库中的表达式不一致
//获取调度器中触发器的表达式
String cronExpression = cronTrigger.getCronExpression();
if(!cronExpression.equals(cron)){//不一致
//重新创建新的触发器
CronTrigger cronTrigger2 = TriggerBuilder.newTrigger()
.withIdentity(jobName, jobGroup)
.withSchedule(CronScheduleBuilder.cronSchedule(cron))
.build();
//更新调度器中的触发器
scheduler.rescheduleJob(triggerKey,cronTrigger2);
}
}
}
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
1) service层实现类使用@Scheduled注解声明一个方法用于定时刷新数据库中的调度任务;
2) 使用@Resource注解注入Scheduler,在第5点中已装配到Spring上下文;
3) 在启动类上加入@MapperScan(指定要变成实现类的接口所在的包路径,比如我的就是com.zking.quartz02.mapper),然后包下面的所有接口在编译之后都会生成相应的实现类;
4) 在启动类上加入@EnableScheduling启动Spring自带定时器任务;
小结:
要搞清楚一个问题:从数据库读取任务信息动态生成定时任务,和把quartz持久化到数据库是没有关系的。
前者是我们自己定义的业务表,而后者是quartz使用自己的表来存储信息。持久化到数据库后,
就算服务器重启或是多个quartz节点也没关系,因为他们共享数据库中的任务信息。
到此这篇关于SpringBoot结合Quartz实现数据库存储的文章就介绍到这了,更多相关SpringBoot Quartz数据库存储内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
SpringBoot中使用Quartz管理定时任务的方法
定时任务在系统中用到的地方很多,例如每晚凌晨的数据备份,每小时获取第三方平台的 Token 信息等等,之前我们都是在项目中规定这个定时任务什么时候启动,到时间了便会自己启动,那么我们想要停止这个定时任务的时候,就需要去改动代码,还得启停服务器,这是非常不友好的事情 直至遇见 Quartz,利用图形界面可视化管理定时任务,使得我们对定时任务的管理更加方便,快捷 一.Quartz 简介 Quartz是一个开源的作业调度框架,它完全由Java写成,并设计用于J2SE和J2EE应用中.它提供了巨大的灵
-
springboot整合Quartz实现动态配置定时任务的方法
前言 在我们日常的开发中,很多时候,定时任务都不是写死的,而是写到数据库中,从而实现定时任务的动态配置,下面就通过一个简单的示例,来实现这个功能. 一.新建一个springboot工程,并添加依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency
-

Springboot整个Quartz实现动态定时任务的示例代码
简介 Quartz是一款功能强大的任务调度器,可以实现较为复杂的调度功能,如每月一号执行.每天凌晨执行.每周五执行等等,还支持分布式调度.本文使用Springboot+Mybatis+Quartz实现对定时任务的增.删.改.查.启用.停用等功能.并把定时任务持久化到数据库以及支持集群. Quartz的3个基本要素 Scheduler:调度器.所有的调度都是由它控制. Trigger: 触发器.决定什么时候来执行任务. JobDetail & Job: JobDetail定义的是任务数据,而真正的
-
SpringBoot与Quartz集成实现分布式定时任务集群的代码实例
Spring Boot与Quartz集成实现分布式定时任务集群 直接贴代码 POM <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xs
-
springboot+Quartz实现任务调度的示例代码
在spring框架中通过 @Schedule 可以实现定时任务,通过该注解 cron 的属性描述的规则,spring会去调用这个方法. spring已经简单粗暴的实现了定时任务,为什么要使用Quartz ? 如果你现在有很多个定时任务,规则不同,例如: 想每月25号,信用卡自动还款 想每年4月1日自己给当年暗恋女神发一封匿名贺卡 想每隔1小时,备份一下自己的爱情动作片 学习笔记到云盘 maven 依赖 <dependency> <groupId>org.quartz-schedul
-
springboot整合quartz实现定时任务示例
在做项目时有时候会有定时器任务的功能,比如某某时间应该做什么,多少秒应该怎么样之类的. spring支持多种定时任务的实现.我们来介绍下使用spring的定时器和使用quartz定时器 1.我们使用spring-boot作为基础框架,其理念为零配置文件,所有的配置都是基于注解和暴露bean的方式. 2.使用spring的定时器: spring自带支持定时器的任务实现.其可通过简单配置来使用到简单的定时任务. @Component @Configurable @EnableScheduling p
-
springboot整合quartz定时任务框架的完整步骤
目录 Spring整合Quartz pom文件 对应的properties 文件 配置类 自定义任务类:ScheduledTask 获取spring中bean的工具类:SpringContextUtil 定时任务服务接口:QuartzService QuartzService实现类:QuartzServiceImpl ScheduledTaskRunner类 任务实体类:QuartzTask 任务service层 service实现类 任务controller 数据表 具体使用 具体效果 总结
-
Springboot2.x+Quartz分布式集群的实现
生产环境一般都是多节点高可用,Springboot本身自带有定时任务功能,但我们项目需求要求能对定时任务进行增,删,改,查.所以考虑引进Quartz,引入Quartz就需要考虑分布式集群,所以就有了这篇文章. 数据库脚本 Quartz数据库有11张表,既支持Mysql,也支持Oracle Mysql /* Navicat MySQL Data Transfer Source Server : 10.19.34.3_ehr_admin Source Server Version : 50639 S
-
SpringBoot定时任务两种(Spring Schedule 与 Quartz 整合 )实现方法
前言 最近在项目中使用到定时任务,之前一直都是使用Quartz 来实现,最近看Spring 基础发现其实Spring 提供 Spring Schedule 可以帮助我们实现简单的定时任务功能. 下面说一下两种方式在Spring Boot 项目中的使用. Spring Schedule 实现定时任务 Spring Schedule 实现定时任务有两种方式 1. 使用XML配置定时任务, 2. 使用 @Scheduled 注解. 因为是Spring Boot 项目 可能尽量避免使用XML配置的形式,
-
SpringBoot结合Quartz实现数据库存储
目录 一.先创建一个SpringBoot项目 二.导入依赖 三. 导入DruidConnectionProvider.java(Druid连接池的Quartz扩展类) 四. 修改自定义quartz.properties配置(在项目中添加quartz.properties文件(这样就不会加载自带的properties文件) ) 五.自定义MyJobFactory,解决spring不能在quartz中注入bean的问题 六.创建调度器schedule 七. 创建自定义任务 八. 更新quartz中的
-
SpringBoot整合Quartz实现定时任务详解
目录 Quartz简介 核心概念 Scheduler JobDetail Job Trigger SpringBoot整合Quartz 准备数据库表 Maven相关依赖 配置文件 quartz配置类 创建任务类 创建监听类 运行结果 Quartz简介 Quartz 是一个开源的作业调度框架,它完全由 Java 写成,并设计用于 J2SE 和 J2EE 应用中.它提供了巨大的灵活性而不牺牲简单性.你能够用它来为执行一个作业而创建简单的或复杂的调度.它有很多特征,如:数据库支持,集群,插件,EJB
-
SpringBoot+Quartz+数据库存储的完美集合
官网:http://www.quartz-scheduler.org/ 我们所需数据库 pom依赖 <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-quartz<
-
SpringBoot集成quartz实现定时任务详解
目录 准备知识点 什么是Quartz Quartz的体系结构 什么是Quartz持久化 实现案例 - 单实例方式 实现案例 - 分布式方式 后端实现 前端实现 测试效果 准备知识点 需要了解常用的Quartz框架. 什么是Quartz 来源百度百科, 官网地址:http://www.quartz-scheduler.org/ Quartz是OpenSymphony开源组织在Job scheduling领域又一个开源项目,它可以与J2EE与J2SE应用程序相结合也可以单独使用.Quartz可以用来
-
SpringBoot集成Quartz实现定时任务的方法
1 需求 在我的前后端分离的实验室管理项目中,有一个功能是学生状态统计.我的设计是按天统计每种状态的比例.为了便于计算,在每天0点,系统需要将学生的状态重置,并插入一条数据作为一天的开始状态.另外,考虑到学生的请假需求,请假的申请往往是提前做好,等系统时间走到实际请假时间的时候,系统要将学生的状态修改为请假. 显然,这两个子需求都可以通过定时任务实现.在网上略做搜索以后,我选择了比较流行的定时任务框架Quartz. 2 Quartz Quartz是一个定时任务框架,其他介绍网上也很详尽.这里要介
-
SpringBoot实现quartz定时任务可视化管理功能
前言 在实际框架或产品开发过程中,springboot中集成quarzt方式基本是以job和trigger的bean对象方式直接硬编码完成的,例如以下代码示例.对于系统内定义的所有定时任务类型,具体执行类,执行策略,运行状态都没有一个动态全局的管理,所有决定将quartz做成可视化配置管理,便于统一管理,也降低了使用门槛,只需要关心job类的实现即可 @Bean public JobDetail SMSJobDetail() { return JobBuilder.newJob(SMSJob.c
-
Springboot使用influxDB时序数据库的实现
目录 引入依赖 配置 构建实体类 保存数据 查询数据 项目中需要存放大量设备日志,且需要对其进行简单的数据分析,信息提取工作. 结合众多考量因素,项目决定使用时序数据库中的领头羊InfluxDB. 引入依赖 项目中使用influxdb-java,在pom文件中添加如下依赖(github地址:https://github.com/influxdata/influxdb-java): <dependency> <groupId>org.influxdb</groupId>
-
springboot实现敏感字段加密存储解密显示功能
springboot实现敏感字段加密存储,解密显示,通过mybatis,自定义注解+AOP切面,Base64加解密方式实现功能. 1.代码实现: 创建springboot项目 添加依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <de