浅谈HTTP 缓存的那些事儿
前言
HTTP 缓存机制作为 Web 应用性能优化的重要手段,对于从事 Web 开发的同学们来说,应该是知识体系的基础环节,也是想要成为前端架构的必备技能。
缓存的作用
我们为什么使用缓存,是因为缓存可以给我们的 Web 项目带来以下好处,以提高性能和用户体验。
- 加快了浏览器加载网页的速度;
- 减少了冗余的数据传输,节省网络流量和带宽;
- 减少服务器的负担,大大提高了网站的性能。
由于从本地缓存读取静态资源,加快浏览器的网页加载速度是一定的,也确实的减少了数据传输,就提高网站性能来说,可能一两个用户的访问对于减小服务器的负担没有明显效果,但如果这个网站在高并发的情况下,使用缓存对于减小服务器压力和整个网站的性能都会发生质的变化。
缓存规则简介
为了方便理解,我们认为浏览器存在一个缓存数据库,用于存储缓存信息(实际上静态资源是被缓存到了内存和磁盘中),在浏览器第一次请求数据时,此时缓存数据库没有对应的缓存数据,则需要请求服务器,服务器会将缓存规则和数据返回,浏览器将缓存规则和数据存储进缓存数据库。
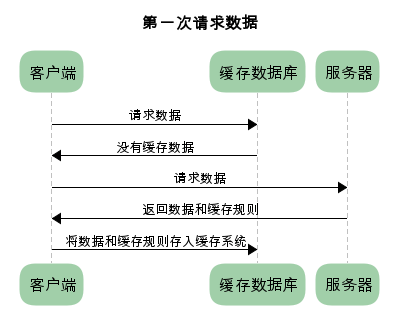
当浏览器地址栏输入地址后请求的 index.html 是不会被缓存的,但 index.html 内部请求的其他资源会遵循缓存策略,HTTP 缓存有多种规则,根据是否需要向服务器发送请求主要分为两大类,强制缓存和协商缓存。
强制缓存
1、强制缓存流程
强制缓存是第一次访问服务器获取数据后,在有效时间内不会再请求服务器,而是直接使用缓存数据,强制缓存的流程如下。
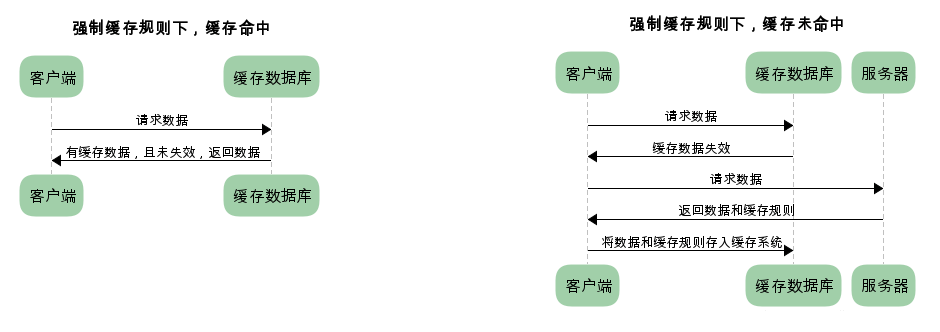
2、强制缓存判断到期时间
那么如何判断缓存是否到期呢?其实还是根据第一次访问时服务器的响应头来实现的,在 HTTP 1.0 版本和 HTTP 1.1 版本有所不同。
在 HTTP 1.0 版本,服务器使用的响应头字段为 Expires,值为未来的绝对时间(时间戳),浏览器请求时的当前时间超过了 Expires 设置的时间,代表缓存失效,需要再次向服务器发送请求,否则都会直接从缓存数据库中获取数据。
在 HTTP 1.1 版本,服务器使用的响应头字段为 Cache-Control,有多个值,意义各不相同。
- private:客户端可以缓存;
- public:客户端和代理服务器都可以缓存(对于前端而言,可以认为与
private效果相同); - max-age=xxx:缓存的内容将在
xxx秒后过期(相对时间,秒为单位); - no-cache:需要使用协商缓存(后面介绍)来验证数据是否过期;
- no-store:所有内容都不会缓存,强制缓存和协商缓存都不会触发。
Cache-Control 的值中最常用的为 max-age=xxx,缓存本身就是为了数据传输的优化和性能而存在的,所以 no-store 几乎不会使用。
注意:在 HTTP 1.0 版本中,Expires 字段的绝对时间是从服务器获取的,由于请求需要时间,所以浏览器的请求时间与服务器接收到请求所获取的时间是存在误差的,这也导致了缓存命中的误差,在 HTTP 1.1 版本中,因为 Cache-Control 的值 max-age=xxx 中的 xxx 是以秒为单位的相对时间,所以在浏览器接收到资源后开始倒计时,规避了 HTTP 1.0 中缓存命中存在误差的缺点,为了兼容低版本 HTTP 协议,正常开发中两种响应头会同时使用,HTTP 1.1 版本的实现优先级高于 HTTP 1.0。
3、通过 Network 查看强制缓存
我们通过 Chrome 浏览器的开发者工具,打开 NetWork 查看强制缓存的相关信息。

上面是百度网站 Logo 图片的响应,我们可以清楚的看到,其中兼容了 HTTP 1.0 和 HTTP 1.1 版本,并使用强制缓存存储了 10 年。
下面看一看通过缓存取出的数据在 Network 中与其他资源的区别。

其实缓存的储存是内存和磁盘两个位置,由当前浏览器本身的策略决定,比较随机,从内存的缓存中取出的数据会显示 (from memory cache),从磁盘的缓存中取出的数据会显示 (from disk cache)。
4、NodeJS 服务器实现强制缓存
// 强制缓存
const http = require("http");
const url = require("url");
const path = require("path");
const mime = require("mime");
const fs = require("fs");
const server = http.createServer((req, res) => {
let { pathname } = url.parse(req.url, true);
pathname = pathname !== "/" ? pathname : "/index.html";
// 获取读取文件的绝对路径
let p = path.join(__dirname, pathname);
// 查看路径是否合法
fs.access(p, err => {
// 路径不合法则直接中断连接
if (err) return res.end("Not Found");
// 设置强制缓存
res.setHeader("Expires", new Date(Date.now() + 30000).toGMTString());
res.setHeader("Cache-Control", "max-age=30");
// 设置文件类型并响应给浏览器
res.setHeader("Content-Type", `${mime.getType(p)};charset=utf8`);
fs.createReadStream(p).pipe(res);
});
});
server.listen(3000, () => {
console.log("server start 3000");
});
上面 mime 模块的 getType 方法可以成功返回传入路径下文件对应的文件类型,如 text/html 和 application/javascript 等,是第三方模块,使用之前需要安装。
npm install mime
协商缓存
1、协商缓存流程
协商缓存又叫对比缓存,设置协商缓存后,第一次访问服务器获取数据时,服务器会将数据和缓存标识一起返回给浏览器,客户端会将数据和标识存入缓存数据库中,下一次请求时,会先去缓存中取出缓存标识发送给服务器进行询问,当服务器数据更改时会更新标识,所以服务器拿到浏览器发来的标识进行对比,相同代表数据未更改,响应浏览器通知数据未更改,浏览器会去缓存中获取数据,如果标识不同,代表服务器更改过数据,所以会将新的数据和新的标识返回浏览器,浏览器会将新的数据和标识存入缓存中,协商缓存的流程如下。
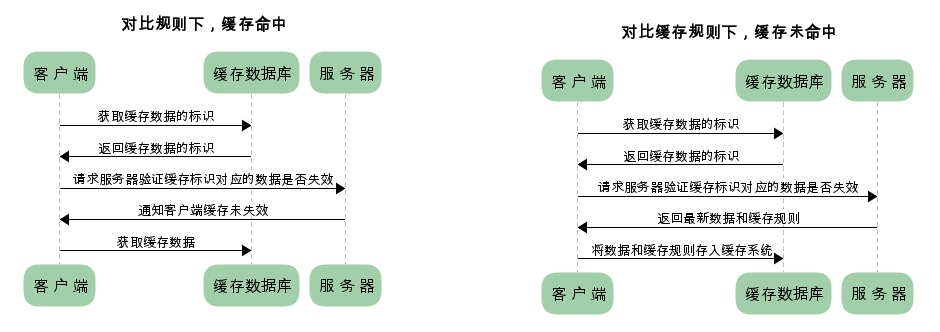
协商缓存和强制缓存不同的是,协商缓存每次请求都需要跟服务器通信,而且命中缓存服务器返回状态码不再是 200,而是 304。
2、协商缓存判断标识
强制缓存是通过过期时间来控制是否访问服务器,而协商缓存每次都要与服务器交互对比缓存标识,同样的,对于协商缓存的实现在 HTTP 1.0 版本和 HTTP 1.1 版本也有所不同。
在 HTTP 1.0 版本中,服务器通过 Last-Modified 响应头来设置缓存标识,通常取请求数据的最后修改时间(绝对时间)作为值,而浏览器将接收到返回的数据和标识存入缓存,再次请求会自动发送 If-Modified-Since 请求头,值为之前返回的最后修改时间(标识),服务器取出 If-Modified-Since 的值与数据的上次修改时间对比,如果上次修改时间大于了 If-Modified-Since 的值,说明被修改过,则通过 Last-Modified 响应头返回新的最后修改时间和新的数据,否则未被修改,返回状态码 304 通知浏览器命中缓存。
在 HTTP 1.1 版本中,服务器通过 Etag 响应头来设置缓存标识(唯一标识,像一个指纹一样,生成规则由服务器来决定),浏览器接收到数据和唯一标识后存入缓存,下次请求时,通过 If-None-Match 请求头将唯一标识带给服务器,服务器取出唯一标识与之前的标识对比,不同,说明修改过,返回新标识和数据,相同,则返回状态码 304 通知浏览器命中缓存。
HTTP 协商缓存策略流程图如下:
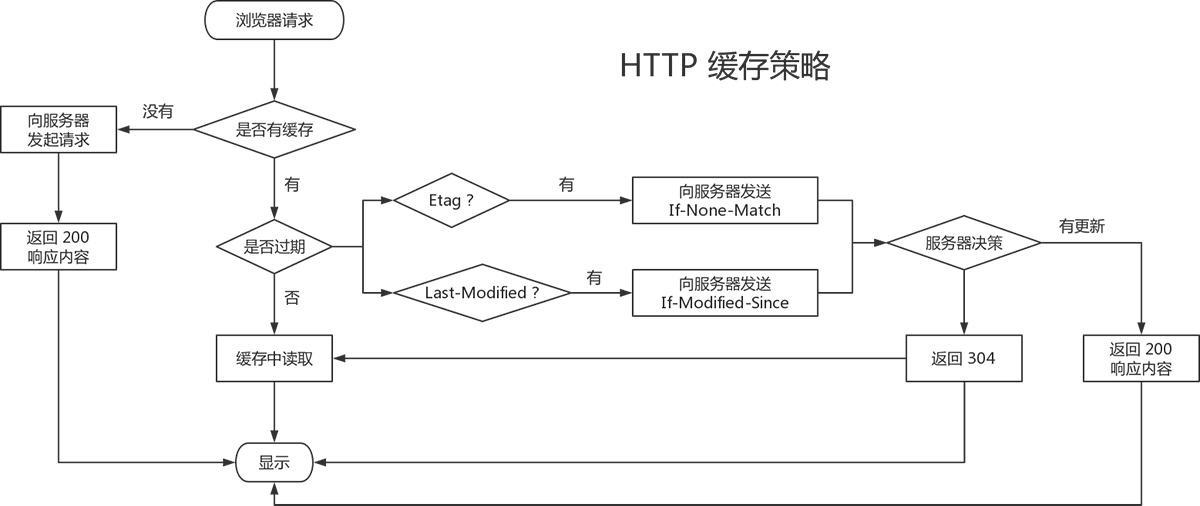
注意:使用协商缓存时 HTTP 1.0 版本还是不太靠谱,假设一个文件增加了一个字符后又删除了,文件相当于没更改,但是最后修改时间变了,会被当作修改处理,本应该命中缓存,服务器却重新发送了数据,因此 HTTP 1.1 中使用的 Etag 唯一标识是根据文件内容或摘要生成的,保证了只要文件内容不变,则一定会命中缓存,为了兼容低版本 HTTP 协议,开发中两种响应头也会同时使用,同样 HTTP 1.1 版本的实现优先级高于 HTTP 1.0。
3、通过 Network 查看协商缓存
我们同样通过 Chrome 浏览器的开发者工具,打开 NetWork 查看协商缓存的相关信息。
再次请求服务器的请求头信息:

命中协商缓存的响应头信息:
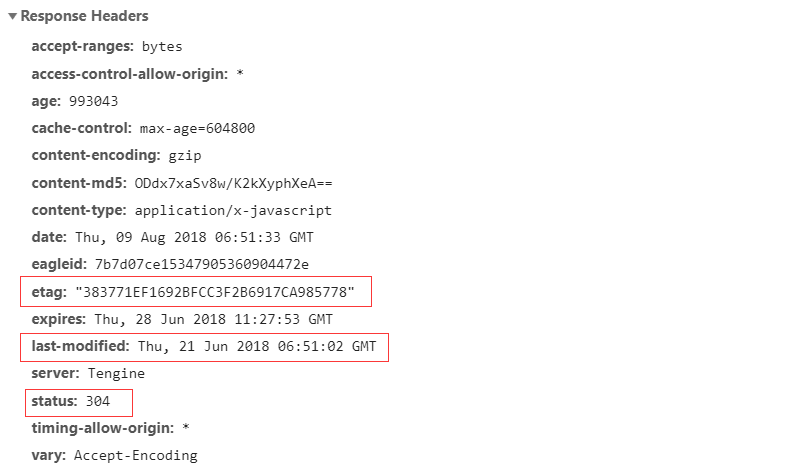
下面看一看通过协商缓存取出的数据在 Network 中与第一次加载的区别。
第一次请求:

缓存后请求:

通过两图的对比,我们可以发现,协商缓存生效时的状态码为 304,并且报文大小和请求时间大大减少,原因是服务端在进行标识比对后只返回了 header 部分,通过状态码来通知浏览器使用缓存,不再需要将报文主体部分一起返回给浏览器。
4、NodeJS 服务器实现协商缓存
// 协商缓存
const http = require("http");
const url = require("url");
const path = require("path");
const mime = require("mime");
const fs = require("fs");0
const crytpo = require("crytpo");
const server = http.createServer((req, res) => {
let { pathname } = url.parse(req.url, true);
pathname = pathname !== "/" ? pathname : "/index.html";
// 获取读取文件的绝对路径
let p = path.join(__dirname, pathname);
// 查看路径是否合法
fs.stat(p, (err, statObj) => {
// 路径不合法则直接中断连接
if (err) return res.end("Not Found");
let md5 = crypto.createHash("md5"); // 创建加密的转换流
let rs = fs.createReadStream(p); // 创建可读流
// 读取文件内容并加密
rs.on("data", data => md5.update(data));
rs.on("end", () => {
let ctime = statObj.ctime.toGMTString(); // 获取文件最后修改时间
let flag = md5.digest("hex"); // 获取加密后的唯一标识
// 获取协商缓存的请求头
let ifModifiedSince = req.headers["if-modified-since"];
let ifNoneMatch = req.headers["if-none-match"];
if (ifModifiedSince === ctime || ifNoneMatch === flag) {
res.statusCode = 304;
res.end();
} else {
// 设置协商缓存
res.setHeader("Last-Modified", ctime);
res.setHeader("Etag", flag);
// 设置文件类型并响应给浏览器
res.setHeader("Content-Type", `${mime.getType(p)};charset=utf8`);
rs.pipe(res);
}
});
});
});
server.listen(3000, () => {
console.log("server start 3000");
});
在上面的代码中是通过可读流读取文件内容,并通过 crypto 模块进行了 md5 加密后的结果作为了唯一标识,这样就能保证只要文件内容不变,就会命中缓存,其中兼容了 HTTP 1.0 和 HTTP 1.1 两个版本,只要满足一个则直接返回 304 通知浏览器命中缓存。
注意:其实读取文件内容加密这种做法并不可取,假如读取的是大文件,在读取文件内容和进行 md5 加密这个过程会非常消耗时间,所以在开发中要针对业务的实际情况选择可以保证服务器性能的方式生成唯一标识,比如根据文件的摘要。
总结
为了使缓存策略更加健壮、灵活,HTTP 1.0 版本 和 HTTP 1.1 版本的缓存策略会同时使用,甚至强制缓存和协商缓存也会同时使用,对于强制缓存,服务器通知浏览器一个缓存时间,在缓存时间内,下次请求,直接使用缓存,超出有效时间,执行协商缓存策略,对于协商缓存,将缓存信息中的 Etag 和 Last-Modified 通过请求头 If-None-Match 和 If-Modified-Since 发送给服务器,由服务器校验同时设置新的强制缓存,校验通过并返回 304 状态码时,浏览器直接使用缓存,如果协商缓存也未命中,则服务器重新设置协商缓存的标识。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
HTTP缓存头Last-Modified和ETag介绍
第一次请求 请求: 复制代码 代码如下: GET /pic/201408/102.jpg HTTP/1.1 Host: www.jb51.net Connection: keep-alive Cache-Control: no-cache Accept: image/webp,*/*;q=0.8 Pragma: no-cache User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chro
-
10分钟彻底搞懂Http的强制缓存和协商缓存(小结)
浏览器缓存 浏览器缓存是浏览器在本地磁盘对用户最近请求过的文档进行存储,当访问者再次访问同一页面时,浏览器就可以直接从本地磁盘加载文档. 所以根据上面的特点,浏览器缓存有下面的优点: 减少冗余的数据传输 减少服务器负担 加快客户端加载网页的速度 浏览器缓存是Web性能优化的重要方式.那么浏览器缓存的过程究竟是怎么样的呢? 在浏览器第一次发起请求时,本地无缓存,向web服务器发送请求,服务器起端响应请求,浏览器端缓存.过程如下: 在第一次请求时,服务器会将页面最后修改时间通过Last-Modifi
-
浅谈HTTP 缓存的那些事儿
前言 HTTP 缓存机制作为 Web 应用性能优化的重要手段,对于从事 Web 开发的同学们来说,应该是知识体系的基础环节,也是想要成为前端架构的必备技能. 缓存的作用 我们为什么使用缓存,是因为缓存可以给我们的 Web 项目带来以下好处,以提高性能和用户体验. 加快了浏览器加载网页的速度: 减少了冗余的数据传输,节省网络流量和带宽: 减少服务器的负担,大大提高了网站的性能. 由于从本地缓存读取静态资源,加快浏览器的网页加载速度是一定的,也确实的减少了数据传输,就提高网站性能来说,可能一两个用户
-
浅谈Redis缓存有哪些淘汰策略
目录 Redis过期策略 定时删除 惰性删除 定期删除 Redis的内存淘汰机制 LRU和LFU的区别 LRU LFU Redis重启如何恢复数据呢? 总结 Redis过期策略 我们首先来了解一下Redis的内存淘汰机制. 定时删除 概述 redis默认是每隔 100ms 就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除.注意这里是随机抽取的.为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会
-
浅谈redis缓存在项目中的使用
背景 Redis 是一个开源的内存数据结构存储系统. 可以作为数据库.缓存和消息中间件使用. 支持多种类型的数据结构. Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence). 通过 Redis 哨兵(Sentinel)和 Redis 集群(Cluster)的自动分区,提供高可用性(high availability). 基本数
-

浅谈数据库缓存最终一致性的四种方案
背景 缓存是软件开发中一个非常有用的概念,数据库缓存更是在项目中必然会遇到的场景.而缓存一致性的保证,更是在面试中被反复问到,这里进行一下总结,针对不同的要求,选择恰到好处的一致性方案. 缓存是什么 存储的速度是有区别的.缓存就是把低速存储的结果,临时保存在高速存储的技术. 如图所示,金字塔更上面的存储,可以作为下面存储的缓存. 我们本次的讨论,主要针对数据库缓存场景,将以redis作为mysql的缓存为案例来进行. 为什么需要缓存 存储如mysql通常支持完整的ACID特性,因为可靠性,持久性
-
浅谈Redis 缓存的三大问题及其解决方案
目录 一.缓存穿透 1. 常见解决方案 2. 布隆过滤器 3. 缓存空数据与布隆过滤器的比较 二.缓存击穿 解决方案 三.缓存雪崩 解决方案 Redis 经常用于系统中的缓存,这样可以解决目前 IO 设备无法满足互联网应用海量的读写请求的问题. 一.缓存穿透 缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起 id 为-1 的数据或者特别大的不存在的数据.有可能是黑客利用漏洞攻击从而去压垮应用的数据库. 1. 常见解决方案 对于缓存穿透问题,常见的解决方案有以下三种: 验证拦截:
-
浅谈Redis缓存雪崩解决方案
目录 1.保持缓存层的高可用 2.限流降级组件 3.缓存不过期 4.优化缓存过期时间 5.使用互斥锁重建缓存 6.异步重建缓存 缓存层承载着大量的请求,有效保护了存储层.但是如果由于大量缓存失效或者缓存整体不能提供服务,导致大量的请求到达存储层,会使存储层负载增加(大量的请求查询数据库) .这就是缓存雪崩的场景; 解决缓存雪崩可以从下面的几点着手: 1.保持缓存层的高可用 使用Redis哨兵模式或者Redis集群部署方式,即是个别Redis节点下线,整个缓存层依然可以使用.除此之外还可以在多个机
-
浅谈Redis缓存更新策略
内存淘汰 超时剔除 主动更新 说明 不用自己维护,利用Redis的内存淘汰机制,当内存不足时自动淘汰部分数据.下次查询时更新缓存 给缓存数据添加TTL时间,到期后自动删除缓存,下次查询时更新缓存 编写业务逻辑,在修改数据的同时,更新缓存 一致性 差 一般 好 维护成本 无 低 高 业务场景需求: 在基本不会更新数据的情况下可以使用内存淘汰机制 在频繁更新数据的情况下可以使用主动更新,并以超时剔除作为兜底方案. 主动更新的三种方法 Cache Aside Pattern:由缓存的调用者,在更新
-
浅谈Redis缓存击穿、缓存穿透、缓存雪崩的解决方案
目录 前言 Redis缓存使用场景 Redis缓存穿透 解决方案 1.对空值缓存 2.添加参数校验 3.采用布隆过滤器 Redis缓存雪崩 解决方案 1.大量热点数据同时失效带来的缓存雪崩问题 2. 服务降级 3. Redis 缓存实例发生故障宕机带来的缓存雪崩问题 Redis缓存击穿 解决方案 1. 热key不过期 2. 分布式锁 总结 缓存击穿 缓存穿透 缓存雪崩 前言 在日常的项目中,缓存的使用场景是比较多的.缓存是分布式系统中的重要组件,主要解决在高并发.大数据场景下,热点数据访问的性能
-
浅谈Glide缓存key的问题
最近项目里面有个地方是在前面用glide加载图片后,后面再另外一个地方加载相同图片时没有复用glide的缓存,而是自己另外又重新缓存了一套. 查找后发现问题是glide缓存的key不一致的问题. 从key的生成可以看到和很多参数有关,逐一排查后,发现了width和height还有id不一样.这3个是项目外面传进来的. EngineKey key = keyFactory.buildKey(id, signature, width, height, loadProvider.getCacheDec
-
浅谈Ajax请求与浏览器缓存
在现代Web应用程序中,前端代码充斥着大量的Ajax请求,如果对于Ajax请求可以使用浏览器缓存,那么可以显著地减少网络请求,提高程序响应速度. 1. Ajax Request 使用jQuery框架可以很方便的进行Ajax请求,示例代码如下: $.ajax({ url : 'url', dataType : "xml", cache: true, success : function(xml, status){ } }); 非常简单,注意其中的第4行代码:cache:true,显式的要