Python 线性回归分析以及评价指标详解
废话不多说,直接上代码吧!
"""
# 利用 diabetes数据集来学习线性回归
# diabetes 是一个关于糖尿病的数据集, 该数据集包括442个病人的生理数据及一年以后的病情发展情况。
# 数据集中的特征值总共10项, 如下:
# 年龄
# 性别
#体质指数
#血压
#s1,s2,s3,s4,s4,s6 (六种血清的化验数据)
#但请注意,以上的数据是经过特殊处理, 10个数据中的每个都做了均值中心化处理,然后又用标准差乘以个体数量调整了数值范围。
#验证就会发现任何一列的所有数值平方和为1.
"""
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# Load the diabetes dataset
diabetes = datasets.load_diabetes()
# Use only one feature
# 增加一个维度,得到一个体质指数数组[[1],[2],...[442]]
diabetes_X = diabetes.data[:, np.newaxis,2]
print(diabetes_X)
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes.target[:-20]
diabetes_y_test = diabetes.target[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)
# The coefficients
# 查看相关系数
print('Coefficients: \n', regr.coef_)
# The mean squared error
# 均方差
# 查看残差平方的均值(mean square error,MSE)
print("Mean squared error: %.2f"
% mean_squared_error(diabetes_y_test, diabetes_y_pred))
# Explained variance score: 1 is perfect prediction
# R2 决定系数(拟合优度)
# 模型越好:r2→1
# 模型越差:r2→0
print('Variance score: %.2f' % r2_score(diabetes_y_test, diabetes_y_pred))
# Plot outputs
plt.scatter(diabetes_X_test, diabetes_y_test, color='black')
plt.plot(diabetes_X_test, diabetes_y_pred, color='blue', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()
对于回归模型效果的判断指标经过了几个过程,从SSE到R-square再到Ajusted R-square, 是一个完善的过程:
SSE(误差平方和):The sum of squares due to error
R-square(决定系数):Coefficient of determination
Adjusted R-square:Degree-of-freedom adjusted coefficient of determination
下面我对以上几个名词进行详细的解释下,相信能给大家带来一定的帮助!!
一、SSE(误差平方和)
计算公式如下:
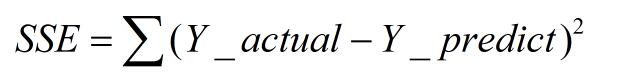
同样的数据集的情况下,SSE越小,误差越小,模型效果越好
缺点:
SSE数值大小本身没有意义,随着样本增加,SSE必然增加,也就是说,不同的数据集的情况下,SSE比较没有意义
二、R-square(决定系数)
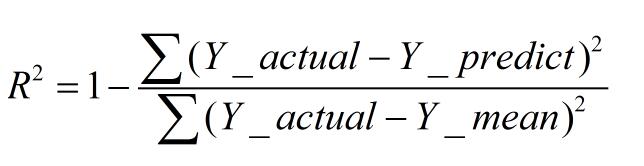
数学理解: 分母理解为原始数据的离散程度,分子为预测数据和原始数据的误差,二者相除可以消除原始数据离散程度的影响
其实“决定系数”是通过数据的变化来表征一个拟合的好坏。
理论上取值范围(-∞,1], 正常取值范围为[0 1] ------实际操作中通常会选择拟合较好的曲线计算R²,因此很少出现-∞
越接近1,表明方程的变量对y的解释能力越强,这个模型对数据拟合的也较好
越接近0,表明模型拟合的越差
经验值:>0.4, 拟合效果好
缺点:
数据集的样本越大,R²越大,因此,不同数据集的模型结果比较会有一定的误差
三、Adjusted R-Square (校正决定系数)
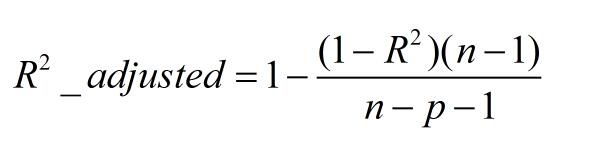
n为样本数量,p为特征数量
消除了样本数量和特征数量的影响
以上这篇Python 线性回归分析以及评价指标详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

8种用Python实现线性回归的方法对比详解
前言 说到如何用Python执行线性回归,大部分人会立刻想到用sklearn的linear_model,但事实是,Python至少有8种执行线性回归的方法,sklearn并不是最高效的. 今天,让我们来谈谈线性回归.没错,作为数据科学界元老级的模型,线性回归几乎是所有数据科学家的入门必修课.抛开涉及大量数统的模型分析和检验不说,你真的就能熟练应用线性回归了么?未必! 在这篇文章中,文摘菌将介绍8种用Python实现线性回归的方法.了解了这8种方法,就能够根据不同需求,灵活选取最为高效的方法实现线
-
Python线性回归实战分析
一.线性回归的理论 1)线性回归的基本概念 线性回归是一种有监督的学习算法,它介绍的自变量的和因变量的之间的线性的相关关系,分为一元线性回归和多元的线性回归.一元线性回归是一个自变量和一个因变量间的回归,可以看成是多远线性回归的特例.线性回归可以用来预测和分类,从回归方程可以看出自变量和因变量的相互影响关系. 线性回归模型如下: 对于线性回归的模型假定如下: (1) 误差项的均值为0,且误差项与解释变量之间线性无关 (2) 误差项是独立同分布的,即每个误差项之间相互独立且每个误差项的方差是相等的
-
Python 线性回归分析以及评价指标详解
废话不多说,直接上代码吧! """ # 利用 diabetes数据集来学习线性回归 # diabetes 是一个关于糖尿病的数据集, 该数据集包括442个病人的生理数据及一年以后的病情发展情况. # 数据集中的特征值总共10项, 如下: # 年龄 # 性别 #体质指数 #血压 #s1,s2,s3,s4,s4,s6 (六种血清的化验数据) #但请注意,以上的数据是经过特殊处理, 10个数据中的每个都做了均值中心化处理,然后又用标准差乘以个体数量调整了数值范围. #验证就会发现任
-
python 线性回归分析模型检验标准--拟合优度详解
建立完回归模型后,还需要验证咱们建立的模型是否合适,换句话说,就是咱们建立的模型是否真的能代表现有的因变量与自变量关系,这个验证标准一般就选用拟合优度. 拟合优度是指回归方程对观测值的拟合程度.度量拟合优度的统计量是判定系数R^2.R^2的取值范围是[0,1].R^2的值越接近1,说明回归方程对观测值的拟合程度越好:反之,R^2的值越接近0,说明回归方程对观测值的拟合程度越差. 拟合优度问题目前还没有找到统一的标准说大于多少就代表模型准确,一般默认大于0.8即可 拟合优度的公式:R^2 = 1
-
Python字典底层实现原理详解
在Python中,字典是通过散列表或说哈希表实现的.字典也被称为关联数组,还称为哈希数组等.也就是说,字典也是一个数组,但数组的索引是键经过哈希函数处理后得到的散列值.哈希函数的目的是使键均匀地分布在数组中,并且可以在内存中以O(1)的时间复杂度进行寻址,从而实现快速查找和修改.哈希表中哈希函数的设计困难在于将数据均匀分布在哈希表中,从而尽量减少哈希碰撞和冲突.由于不同的键可能具有相同的哈希值,即可能出现冲突,高级的哈希函数能够使冲突数目最小化.Python中并不包含这样高级的哈希函数,几个重要
-
python实现高斯模糊及原理详解
高斯模糊是一种常见的模糊技术,相关知识点有:高斯函数.二维卷积. (一)一维高斯分布函数 一维(连续变量)高斯函数形式如下,高斯函数又称"正态分布函数": μ是分布函数的均值(或者期望),sigma是标准差. 一维高斯分布函数的图形: 从图可知,以x=0为中心,x取值距离中心越近,概率密度函数值越大,距离中心越远,密度函数值越小. (二)二维高斯分布函数 二维高斯分布函数的形式: 特别说明,当变量x和y相互独立时,则相关系数ρ=0,二维高斯分布函数可以简化为: 二维高斯分布函数的图形:
-
Python 实现静态链表案例详解
静态链表和动态链表区别 静态链表和动态链表的共同点是,数据之间"一对一"的逻辑关系都是依靠指针(静态链表中称"游标")来维持. 静态链表 使用静态链表存储数据,需要预先申请足够大的一整块内存空间,也就是说,静态链表存储数据元素的个数从其创建的那一刻就已经确定,后期无法更改. 不仅如此,静态链表是在固定大小的存储空间内随机存储各个数据元素,这就造成了静态链表中需要使用另一条链表(通常称为"备用链表")来记录空间存储空间的位置,以便后期分配给新添加元
-
python OpenCV 实现高斯滤波详解
目录 一.高斯滤波 二.C++代码 三.python代码 四.结果展示 1.原始图像 2.5x5卷积 3.9x9卷积 一.高斯滤波 高斯滤波是一种线性平滑滤波,适用于消除高斯噪声,广泛应用于图像处理的减噪过程. [1] 通俗的讲,高斯滤波就是对整幅图像进行加权平均的过程,每一个像素点的值,都由其本身和邻域内的其他像素值经过加权平均后得到.高斯滤波的具体操作是:用一个模板(或称卷积.掩模)扫描图像中的每一个像素,用模板确定的邻域内像素的加权平均灰度值去替代模板中心像素点的值. 二.C++代码
-
Python深度学习线性代数示例详解
目录 标量 向量 长度.维度和形状 矩阵 张量 张量算法的基本性质 降维 点积 矩阵-矩阵乘法 范数 标量 标量由普通小写字母表示(例如,x.y和z).我们用 R \mathbb{R} R表示所有(连续)实数标量的空间. 标量由只有一个元素的张量表示.下面代码,我们实例化了两个标量,并使用它们执行一些熟悉的算数运算,即加法.乘法.除法和指数. import torch x = torch.tensor([3.0]) y = torch.tensor([2.0]) x + y, x * y, x
-
python用matplotlib可视化绘图详解
目录 1.Matplotlib 简介 2.Matplotlib图形绘制 1)折线图 2)柱状图 3)条形图 3)饼图 4)散点图 5)直方图 6)箱型图 7)子图 1.Matplotlib 简介 Matplotlib 简介: Matplotlib 是一个python的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形,matplotlib 对于图像美化方面比较完善,可以自定义线条的颜色和样式,可以在一张绘图纸上绘制多张小图,也可以在一张图上绘制多条线,可以很方便地将数据可
-
python神经网络InceptionV3模型复现详解
目录 神经网络学习小记录21——InceptionV3模型的复现详解 学习前言什么是InceptionV3模型InceptionV3网络部分实现代码图片预测 学习前言 Inception系列的结构和其它的前向神经网络的结构不太一样,每一层的内容不是直直向下的,而是分了很多的块. 什么是InceptionV3模型 InceptionV3模型是谷歌Inception系列里面的第三代模型,其模型结构与InceptionV2模型放在了同一篇论文里,其实二者模型结构差距不大,相比于其它神经网络模型,Inc
-
Python中Numpy模块使用详解
目录 NumPy ndarray对象 Numpy数据类型 Numpy数组属性 NumPy NumPy(Numerical Python) 是 Python 的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库.Nupmy可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix)).据说NumPy将Python相当于变成一种免费的更强大的MatLab系统.