关于Java 项目封装sqlite连接池操作持久化数据的方法
Sqlite
sqlite是C实现的一个开源SQL引擎,其api提供sql语法支持,通过sql解析后对存储层的磁盘文件进行操作,完整配置的sqlite库小于400kb,多用于移动端应用,小型项目中。
对Sqlite有兴趣的可以了解下其体系结构
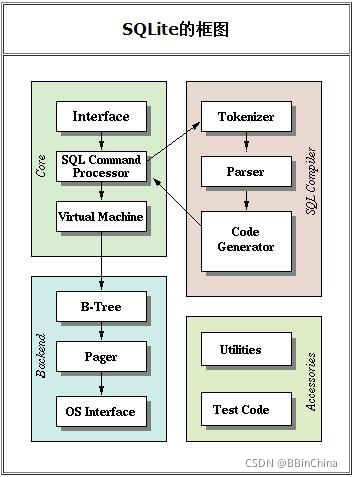
之前自研SQL解析器的时候便是借鉴了SQLcompiler的源码,这里不展开介绍
封装Java的Sqlite连接池
首先maven项目引入依赖sqlite-jdbc,其主要是java版的sqliteapi,关于Sqlite api的操作,大家可以看菜鸟教程
<dependency>
<groupId>org.xerial</groupId>
<artifactId>sqlite-jdbc</artifactId>
<version>3.30.1</version>
</dependency>
同时引入spring jdbc方便解析数据
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>5.3.12</version>
</dependency>
先编写测试用例
import org.junit.Test;
import org.springframework.jdbc.core.RowMapper;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.LinkedList;
import java.util.List;
public class TestSqliteHelper {
@Test
public void test() throws SQLException, ClassNotFoundException {
SqliteHelper sqliteHelper = SqliteHelper.GetSqliteHelper("test.db");
String sql = "CREATE TABLE COMPANY " +
"(ID INT PRIMARY KEY NOT NULL," +
" NAME TEXT NOT NULL, " +
" AGE INT NOT NULL, " +
" ADDRESS CHAR(50), " +
" SALARY REAL)";
sqliteHelper.ExecuteUpdate(sql);
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " +
"VALUES (1, 'Paul', 32, 'California', 20000.00 );";
sqliteHelper.ExecuteUpdate(sql);
sql = "SELECT * FROM COMPANY;";
List<String> datas = new LinkedList<>();
datas = sqliteHelper.ExecuteQuery(sql, new RowMapper<String>() {
@Override
public String mapRow(ResultSet rs, int index)
throws SQLException {
return rs.getString("NAME");
}
}
);
sqliteHelper.PutSqliteHelper();
}
}
再根据TDD实现ExecuteUpdate\GetSqliteHelper、ExecuteQuery、PutSqliteHelper等方法
import org.springframework.jdbc.core.RowMapper;
import java.sql.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.concurrent.locks.ReentrantLock;
public class SqliteHelper {
/**
* 磁盘文件名 即db
*/
private String path = null;
/**
* 操作链接
*/
private Connection connection = null;
/**
* 语法执行层
*/
private Statement statement = null;
/**
* 构建一次链接
*
* @param path
* @throws SQLException
* @throws ClassNotFoundException
*/
SqliteHelper(String path) throws SQLException, ClassNotFoundException {
this.path = path;
this.connection = this.getConnect(path);
}
/**
* 读写锁,也可以使用ConcurrentHashMap
*/
static ReentrantLock hashMapLock = new ReentrantLock();
/**
* Sqlite的连接池
*/
static HashMap<String, List<SqliteHelper>> sqlitePool = new HashMap<>();
/**
* sqlite对磁盘文件的操作是在一次连接上执行
*
* @param path sqlite数据存储的磁盘文件
* @return
*/
public static SqliteHelper GetSqliteHelper(String path) throws SQLException, ClassNotFoundException {
hashMapLock.lock();
List<SqliteHelper> sqliteHelpers = sqlitePool.get(path);
if (sqliteHelpers == null) {
sqliteHelpers = new LinkedList<>();
sqlitePool.put(path, sqliteHelpers);
}
SqliteHelper sqliteHelper = new SqliteHelper(path);
sqliteHelpers.add(sqliteHelper);
return sqliteHelper;
}
public void PutSqliteHelper() throws SQLException {
hashMapLock.lock();
List<SqliteHelper> sqliteHelpers = sqlitePool.get(this.path);
if (sqliteHelpers == null) {
sqliteHelpers = new LinkedList<>();
sqlitePool.put(path, sqliteHelpers);
}
if(sqliteHelpers.size() > 2){
releaseConn();
}else{
sqliteHelpers.add(this);
}
}
/**
* 获取Sqlite操作链接
*
* @param path sqlite数据表,为磁盘文件名
* @return
*/
private Connection getConnect(String path) throws ClassNotFoundException, SQLException {
Connection c = null;
Class.forName("org.sqlite.JDBC");
c = DriverManager.getConnection("jdbc:sqlite:" + path);
return c;
}
/**
* @param sql 执行的sqlite 语句
* @param row
* @param <T> 映射的模板
* @return
*/
public <T> List<T> ExecuteQuery(String sql, RowMapper<T> row) throws SQLException {
try {
List<T> datas = new ArrayList<>();
ResultSet resultSet = getStmt().executeQuery(sql);
while (resultSet.next()) {
datas.add(row.mapRow(resultSet, resultSet.getRow()));
}
resultSet.close();
return datas;
} finally {
releaseConn();
}
}
public void ExecuteUpdate(String sql) throws SQLException {
getStmt().executeUpdate(sql);
}
private Statement getStmt() throws SQLException {
if (this.statement == null) {
this.statement = this.connection.createStatement();
}
return this.statement;
}
private void releaseConn() throws SQLException {
if (this.connection != null) {
this.connection.close();
this.connection = null;
}
if (this.statement != null) {
this.statement.close();
this.statement = null;
}
}
}
到此这篇关于Java 项目封装sqlite连接池操作持久化数据的文章就介绍到这了,更多相关java sqlite连接池操作内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Java 数据库连接池c3p0 介绍
目录 1.配置参数 1.1.基础配置 1.2.连接池大小 1.3.连接池大小和连接存活时间 1.4.连接测试 1.5.预编译池 1.6.数据库中断的恢复 1.7.自定义连接生命周期管理 1.8.处理未提交的事务 1.9.调试 1.10.避免热部署内存泄露 1.11.其它配置 2.原始连接操作 3.使用 3.1.直接使用 3.1.1.引入依赖 3.1.2.使用例子 3.2.在 SpringBoot 中使用 3.1.1.引入依赖 3.1.2.单数据源 3.1.3.多数据源 前言: c3p0 是一个开
-
Java开发druid数据连接池maven方式简易配置流程示例
目录 1.pom.xml文件引入druid和数据库连接jar包 2.jdbc.properties配置 3.ibatis-config.xml关于mybatis的参数配置 4.spring-mybatis.xml整合文件配置 5.web.xml配置检测访问 禁止访问的ip 6.根据需要配置各类监控Spring-mvc.xml 7.可选安全的加密操作 数据库加密 8.访问方式 1.pom.xml文件引入druid和数据库连接jar包 <properties> <druid.version&
-
详解Java数据库连接池
一.什么是数据库连接池 就是一个容器持有多个数据库连接,当程序需要操作数据库的时候直接从池中取出连接,使用完之后再还回去,和线程池一个道理. 二.为什么需要连接池,好处是什么? 1.节省资源,如果每次访问数据库都创建新的连接,创建和销毁都浪费系统资源 2.响应性更好,省去了创建的时间,响应性更好. 3.统一管理数据库连接,避免因为业务的膨胀导致数据库连接的无限增多. 4.便于监控. 三.都有哪些连接池方案 数据库连接池的方案有不少,我接触过的连接池方案有: 1.C3p0 这个连接池我很久之前看到
-
Java操作数据库连接池案例讲解
数据库连接池 概念:其实就是一个容器(集合),存放数据库连接的容器. 概念:其实就是一个容器(集合),存放数据库连接的容器. 当系统初始化好后,容器被创建,容器中会申请一些连接对象,当用户来访问数据库时,从容器中获取连接对象,用户访问完之后,会将连接对象归还给容器. 好处: 节约资源 用户访问高效 实现: 标准接口:DataSource javax.sql包下的 方法: 获取连接:getConnection() 归还连接:Connection.close().如果连接对象Connection是从
-
Java 数据库连接池 DBCP 的介绍
目录 1.配置参数 2.使用 2.1.直接使用 2.1.1.引入依赖 2.1.2.使用例子 2.2.在 SpringBoot 中使用 2.2.1.引入依赖 2.2.2.单数据源 2.2.3.多数据源 DBCP(Database connection pooling) 是 Apache 旗下 Commons 项目下的一个子项目,提供连接池功能:本文主要介绍 DBCP 的基本使用,文中使用到的软件版本:Java 1.8.0_191.DBCP 2.9.0.Spring Boot 2.3.12.RELE
-
Java httpClient连接池支持多线程高并发的实现
当采用HttpClient httpClient = HttpClients.createDefault() 实例化的时候.会导致Address already in use的异常. 信息: I/O exception (java.net.BindException) caught when processing request to {}->http://**.**.**.** Address already in use: connect 十一月 22, 2018 5:02:13 下午 or
-
Java 数据库连接池DBPool 介绍
目录 1.配置参数 2.使用 2.1.直接使用 2.1.1.引入依赖 2.1.2.使用例子 2.2.在 SpringBoot 中使用 2.1.1.引入依赖 2.1.2.单数据源 2.1.3.多数据源 前言: DBPool 是一个高效易配置的数据库连接池,支持 JDBC 4.2,但目前已经不维护了:本文简单介绍下 DBPool 的使用,文中使用到的软件版本:Java 1.8.0_191.DBPool 7.0.1.Spring Boot 2.3.12.RELEASE. 1.配置参数 参数 描述 na
-
java数据库连接池新手入门一篇就够了,太简单了!
1.什么是数据库连接池 就是一个容器持有多个数据库连接,当程序需要操作数据库的时候直接从池中取出连接,使用完之后再还回去,和线程池一个道理. 2.为什么需要连接池,好处是什么? 1.节省资源,如果每次访问数据库都创建新的连接,创建和销毁都浪费系统资源 2.响应性更好,省去了创建的时间,响应性更好. 3.统一管理数据库连接,避免因为业务的膨胀导致数据库连接的无限增多. 4.便于监控. 3.都有哪些连接池方案 数据库连接池的方案有不少,我接触过的连接池方案有: 1.C3p0 这个连接池我很久之前看到
-

关于Java 项目封装sqlite连接池操作持久化数据的方法
Sqlite sqlite是C实现的一个开源SQL引擎,其api提供sql语法支持,通过sql解析后对存储层的磁盘文件进行操作,完整配置的sqlite库小于400kb,多用于移动端应用,小型项目中. 对Sqlite有兴趣的可以了解下其体系结构 之前自研SQL解析器的时候便是借鉴了SQLcompiler的源码,这里不展开介绍 封装Java的Sqlite连接池 首先maven项目引入依赖sqlite-jdbc,其主要是java版的sqliteapi,关于Sqlite api的操作,大家可以看菜鸟教程
-
使用java数组 封装自己的数组操作示例
本文实例讲述了使用java数组 封装自己的数组操作.分享给大家供大家参考,具体如下: 今天感冒了,全身酸软无力,啥样不想做,就来学习吧,此节我们从初步使用java中提供的数组,然后分析相关情况,过渡到封装我们自己的数组. 一.我们先来感受一下java提供的数组,以整型数组(int[])为例,相关代码如下: public class Main { public static void main(String[] args) { int[] arr = new int[10]; for(int i
-
Python3 多线程(连接池)操作MySQL插入数据
多线程(连接池)操作MySQL插入数据 针对于此篇博客的收获心得: 首先是可以构建连接数据库的连接池,这样可以多开启连接,同一时间连接不同的数据表进行查询,插入,为多线程进行操作数据库打基础 多线程根据多连接的方式,需求中要完成多语言的入库操作,我们可以启用多线程对不同语言数据进行并行操作 在插入过程中,一条一插入,比较浪费时间,我们可以把数据进行积累,积累到一定的条数的时候,执行一条sql命令,一次性将多条数据插入到数据库中,节省时间cur.executemany 1.主要模块 DBUtils
-
详解IDEA2020新建spring项目和c3p0连接池的创建和使用
目录 前言 1.环境准备:maven配置 2.导入jar包:c3p0-0.9.5.4.jar和mysql-connector-java.jar 3.编写测试类测试连接 前言 C3P0是一个开源的JDBC连接池,它实现了数据源和JNDI绑定,支持JDBC3规范和JDBC2的标准扩展,目前使用它的开源项目有Hibernate,Spring等. 1.环境准备:maven配置 打开idea,点击"+"新建项目,选择Spring,点击next,填写项目的名称,点击finish,新的Spring项
-
php连接与操作PostgreSQL数据库的方法
本文实例讲述了php连接与操作PostgreSQL数据库的方法.分享给大家供大家参考. 具体实现方法如下: 复制代码 代码如下: $pg=@pg_connect("host=localhost user=postgres password=sa dbname=employes") or die("can't connect to database."); $query="select * from employes order by serial_no&q
-
python连接、操作mongodb数据库的方法实例详解
本文实例讲述了python连接.操作mongodb数据库的方法.分享给大家供大家参考,具体如下: 数据库连接 from pymongo import MongoClient import pandas as pd #建立MongoDB数据库连接 client = MongoClient('162.23.167.36',27101)#或MongoClient("mongodb://162.23.167.36:27101/") #连接所需数据库,testDatabase为数据库名: db=
-
PHP连接及操作PostgreSQL数据库的方法详解
本文实例讲述了PHP连接及操作PostgreSQL数据库的方法.分享给大家供大家参考,具体如下: PostgreSQL扩展在默认情况下在最新版本的PHP 5.3.x中是启用的. 可以在编译时使用--without-pgsql来禁用它.仍然可以使用yum命令来安装PHP-PostgreSQL接口: yum install php-pgsql 在开始使用PHP连接PostgreSQL接口之前,请先在PostgreSQL安装目录中找到pg_hba.conf文件,并添加以下行: # IPv4 local
-
java 通过发送json,post请求,返回json数据的方法
实例如下所示: import java.io.BufferedReader; import java.io.DataOutputStream; import java.io.InputStream; import java.io.InputStreamReader; import java.io.OutputStream; import java.net.HttpURLConnection; import java.net.URL; import org.json.JSONArray; impo
-
java根据数据库表内容生产树结构json数据的方法
1.利用场景 组织机构树,通常会有组织机构表,其中有code(代码),pcode(上级代码),name(组织名称)等字段 2.构造数据(以下数据并不是组织机构数据,而纯属本人胡编乱造的数据) List<Tree<Test>> trees = new ArrayList<Tree<Test>>(); tests.add(new Test("0", "", "关于本人")); tests.add(new
-
python操作 hbase 数据的方法
配置 thrift python使用的包 thrift 个人使用的python 编译器是pycharm community edition. 在工程中设置中,找到project interpreter, 在相应的工程下,找到package,然后选择 "+" 添加, 搜索 hbase-thrift (Python client for HBase Thrift interface),然后安装包. 安装服务器端thrift. 参考官网,同时也可以在本机上安装以终端使用. thrift Ge