Redis缓存IO模型的演进教程示例精讲
目录
- 前言
- 事件模型
- 通信
- copy数据的开销
- 数据怎么知道发给哪个socket
- socket的数据怎么通知程序来取
- Reactor
- IO多路复用器
- select
- epoll
- epoll是怎么做到的?
- 单线程到多线程的演进
- 单线程
- 异步线程
- 多线程
- 多线程的作用点?
- 多线程的原理
前言
redis作为应用最广泛的nosql数据库之一,大大小小也经历过很多次升级。在4.0版本之前,单线程+IO多路复用使得redis的性能已经达到一个非常高的高度了。作者也说过,之所以设计成单线程是因为redis的瓶颈不在cpu上,而且单线程也不需要考虑多线程带来的锁开销问题。
然而随着时间的推移,单线程越来越不满足一些应用场景了,比如针对大key删除会造成主线程阻塞的问题,redis4.0出了一个异步线程。
针对单线程由于无法利用多核cpu的特性而导致无法满足更高的并发,redis6.0也推出了多线程模式。所以说redis是单线程越来越不准确了。
事件模型
redis本身是个事件驱动程序,通过监听文件事件和时间事件来完成相应的功能。其中文件事件其实就是对socket的抽象,把一个个socket事件抽象成文件事件,redis基于Reactor模式开发了自己的网络事件处理器。那么Reactor模式是什么?
通信
思考一个问题,我们的服务器是如何收到我们的数据的?首先双方先要建立TCP连接,连接建立以后,就可以收发数据了。发送方向socket的缓冲区发送数据,等待系统从缓冲区把数据取走,然后通过网卡把数据发出去,接收方的网卡在收到数据之后,会把数据copy到socket的缓冲区,然后等待应用程序来取,这是大概的发收数据流程。
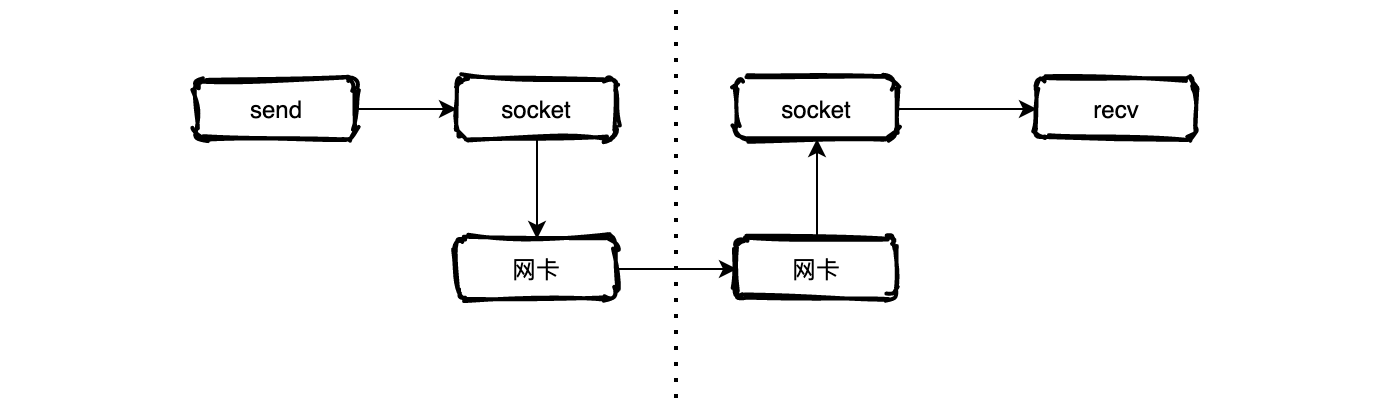
copy数据的开销
因为涉及到系统调用,整个过程可以发现一份数据需要先从用户态拷贝到内核态的socket,然后又要从内核态的socket拷贝到用户态的进程中去,这就是数据拷贝的开销。
数据怎么知道发给哪个socket
内核维护的socket那么多,网卡过来的数据怎么知道投递给哪个socket?
答案是端口,socket是一个四元组:
ip(client)+ port(client)+ip(server)+port(server)
注意千万不要说一台机器的理论最大并发是65535个,除了端口,还有ip,应该是端口数*ip数
这也是为什么一台电脑可以同时打开多个软件的原因。
socket的数据怎么通知程序来取
当数据已经从网卡copy到了对应的socket缓冲区中,怎么通知程序来取?假如socket数据还没到达,这时程序在干嘛?这里其实涉及到cpu对进程的调度的问题。从cpu的角度来看,进程存在运行态、就绪态、阻塞态。
- 就绪态:进程等待被执行,资源都已经准备好了,剩下的就等待cpu的调度了。
- 运行态:正在运行的进程,cpu正在调度的进程。
- 阻塞态:因为某些情况导致阻塞,不占有cpu,正在等待某些事件的完成。
当存在多个运行态的进程时,由于cpu的时间片技术,运行态的进程都会被cpu执行一段时间,看着好似同时运行一样,这就是所谓的并发。当我们创建一个socket连接时,它大概会这样:
sockfd = socket(AF_INET, SOCK_STREAM, 0) connect(sockfd, ....) recv(sockfd, ...) doSometing()
操作系统会为每个socket建立一个fd句柄,这个fd就指向我们创建的socket对象,这个对象包含缓冲区、进程的等待队列...。对于一个创建socket的进程来说,如果数据没到达,那么他会卡在recv处,这个进程会挂在socket对象的等待队列中,对cpu来说,这个进程就是阻塞的,它其实不占有cpu,它在等待数据的到来。
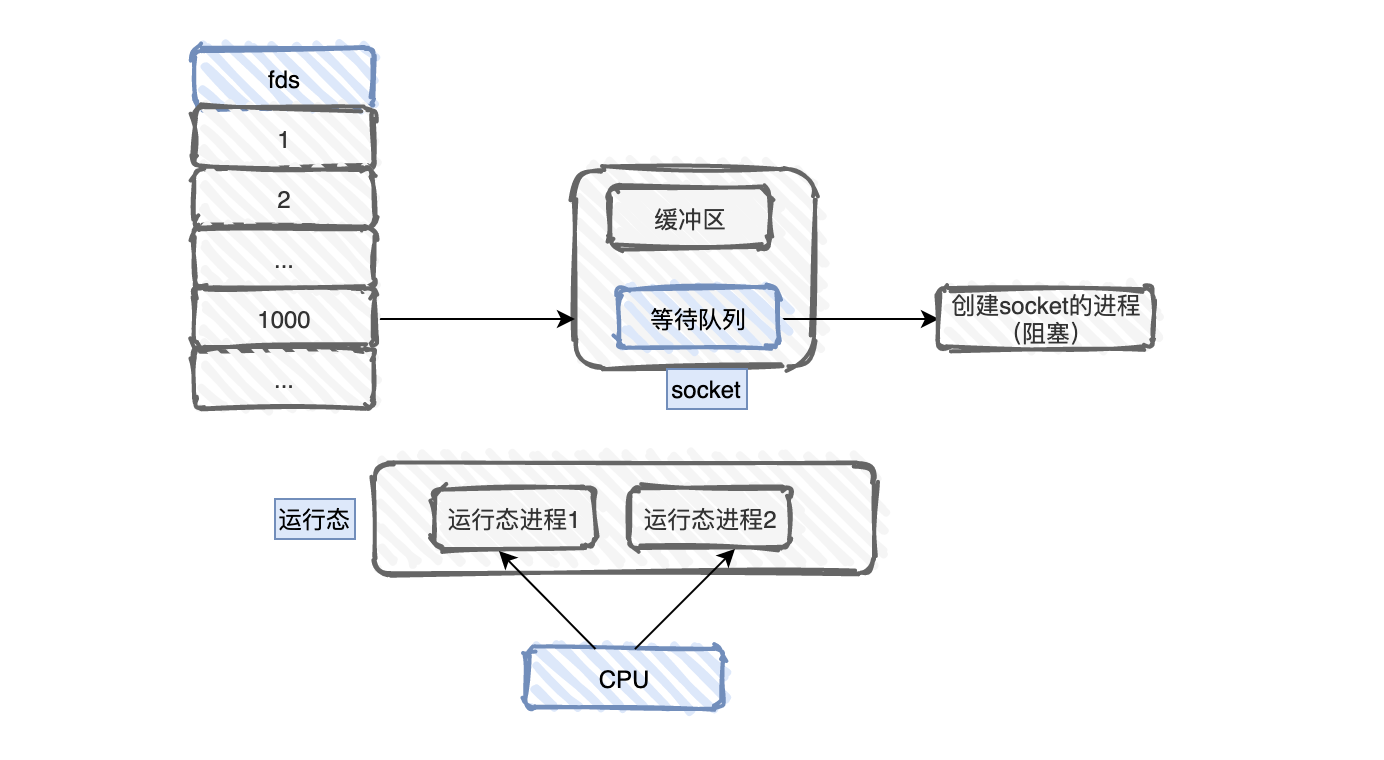
当数据到来时,网卡会告诉cpu,cpu执行中断程序,把网卡的数据copy到对应的socket的缓冲区中,然后唤醒等待队列中的进程,把这个进程重新放回运行队列中,当这个进程被cpu运行的时候,它就可以执行最后的读取操作了。这种模式有两个问题:
recv只能接收一个fd,如果要recv多个fd怎么办?
通过while循环效率稍低。
进程除了读取数据,还要处理接下里的逻辑,在数据没到达时,进程处于阻塞态,即使用了while循环来监听多个fd,其它的socket是不是因为其中一个recv阻塞,而导致整个进程的阻塞。
针对上述问题,于是Reactor模式和IO多路复用技术出现了。
Reactor
Reactor是一种高性能处理IO的模式,Reactor模式下主程序只负责监听文件描述符上是否有事件发生,这一点很重要,主程序并不处理文件描述符的读写。那么文件描述符的可读可写谁来做?答案是其他的工作程序,当某个socket发生可读可写的事件后,主程序会通知工作程序,真正从socket里面读取数据和写入数据的是工作程序。这种模式的好处就是就是主程序可以扛并发,不阻塞,主程序非常的轻便。事件可以通过队列的方式等待被工作程序执行。通过Reactor模式,我们只需要把事件和事件对应的handler(callback func),注册到Reactor中就行了,比如:
type Reactor interface{
RegisterHandler(WriteCallback func(), "writeEvent");
RegisterHandler(ReadCallback func(), "readEvent");
}
当一个客户端向redis发起set key value的命令,这时候会向socket缓冲区写入这样的命令请求,当Reactor监听到对应的socket缓冲区有数据了,那么此时的socket是可读的,Reactor就会触发读事件,通过事先注入的ReadCallback回调函数来完成命令的解析、命令的执行。当socket的缓冲区有足够的空间可以被写,那么对应的Reactor就会产生可写事件,此时就会执行事先注入的WriteCallback回调函数。当发起的set key value执行完毕后,此时工作程序会向socket缓冲区中写入OK,最后客户端会从socket缓冲区中取走写入的OK。在redis中不管是ReadCallback,还是WriteCallback,它们都是一个线程完成的,如果它们同时到达那么也得排队,这就是redis6.0之前的默认模式,也是最广为流传的单线程redis。
整个流程下来可以发现Reactor主程序非常快,因为它不需要执行真正的读写,剩下的都是工作程序干的事:IO的读写、命令的解析、命令的执行、结果的返回..,这一点很重要。
IO多路复用器
通过上面我们知道Reactor它是一个抽象的理论,是一个模式,如何实现它?如何监听socket事件的到来?。最简单的办法就是轮询,我们既然不知道socket事件什么时候到达,那么我们就一直来问内核,假设现在有1w个socket连接,那么我们就得循环问内核1w次,这个开销明显很大。
用户态到内核态的切换,涉及到上下文的切换(context),cpu需要保护现场,在进入内核前需要保存寄存器的状态,在内核返回后还需要从寄存器里恢复状态,这是个不小的开销。
由于传统的轮询方法开销过大,于是IO多路复用复用器出现了,IO多路复用器有select、poll、evport、kqueue、epoll。Redis在I/O多路复用程序的实现源码中用#include宏定义了相应的规则,程序会在编译时自动选择系统中性能最高的I/O多路复用函数库来作为Redis的I/O多路复用程序的底层实现:
// Include the best multiplexing layer supported by this system. The following should be ordered by performances, descending.
# ifdef HAVE_EVPORT
# include "ae_evport.c"
# else
# ifdef HAVE_EPOLL
# include "ae_epoll.c"
# else
# ifdef HAVE_KQUEUE
# include "ae_kqueue.c"
# else
# include "ae_select.c"
# endif
# endif
# endif
我们这里主要介绍两种非常经典的复用器select和epoll,select是IO多路复用器的初代,select是如何解决不停地从用户态到内核态的轮询问题的?
select
既然每次轮询很麻烦,那么select就把一批socket的fds集合一次性交给内核,然后内核自己遍历fds,然后判断每个fd的可读可写状态,当某个fd的状态满足时,由用户自己判断去获取。
fds = []int{fd1,fd2,...}
for {
select (fds)
for i:= 0; i < len(fds); i++{
if isReady(fds[i]) {
read()
}
}
}
select的缺点:当一个进程监听多个socket的时候,通过select会把内核中所有的socket的等待队列都加上本进程(多对一),这样当其中一个socket有数据的时候,它就会把告诉cpu,同时把这个进程从阻塞态唤醒,等待被cpu的调度,同时会把进程从所有的socket的等待队列中移除,当cpu运行这个进程的时候,进程因为本身传进去了一批fds集合,我们并不知道哪个fd来数据了,所以只能都遍历一次,这样对于没有数据到来的fd来说,就白白浪费了。由于每次select要遍历socket集合,那么这个socket集合的数量过大就会影响整体效率,这原因也是select为什么支持最大1024个并发的。
epoll
如果有一种方法使得不用遍历所有的socket,当某个socket的消息到来时,只需要触发对应的socket fd,而不用盲目的轮询,那效率是不是会更高。epoll的出现就是为了解决这个问题:
epfd = epoll_create()
epoll_ctl(epfd, fd1, fd2...)
for {
epoll_wait()
for fd := range fds {
doSomething()
}
}
- 首先通过epoll_create创建一个epoll对象,它会返回一个fd句柄,和socket的句柄一样,也是管理在fds集合下。
- 通过epoll_ctl,把需要监听的socket fd和epoll对象绑定。
- 通过epoll_wait来获取有数据的socket fd,当没有一个socket有数据的时候,那么此处会阻塞,有数据的话,那么就会返回有数据的fds集合。
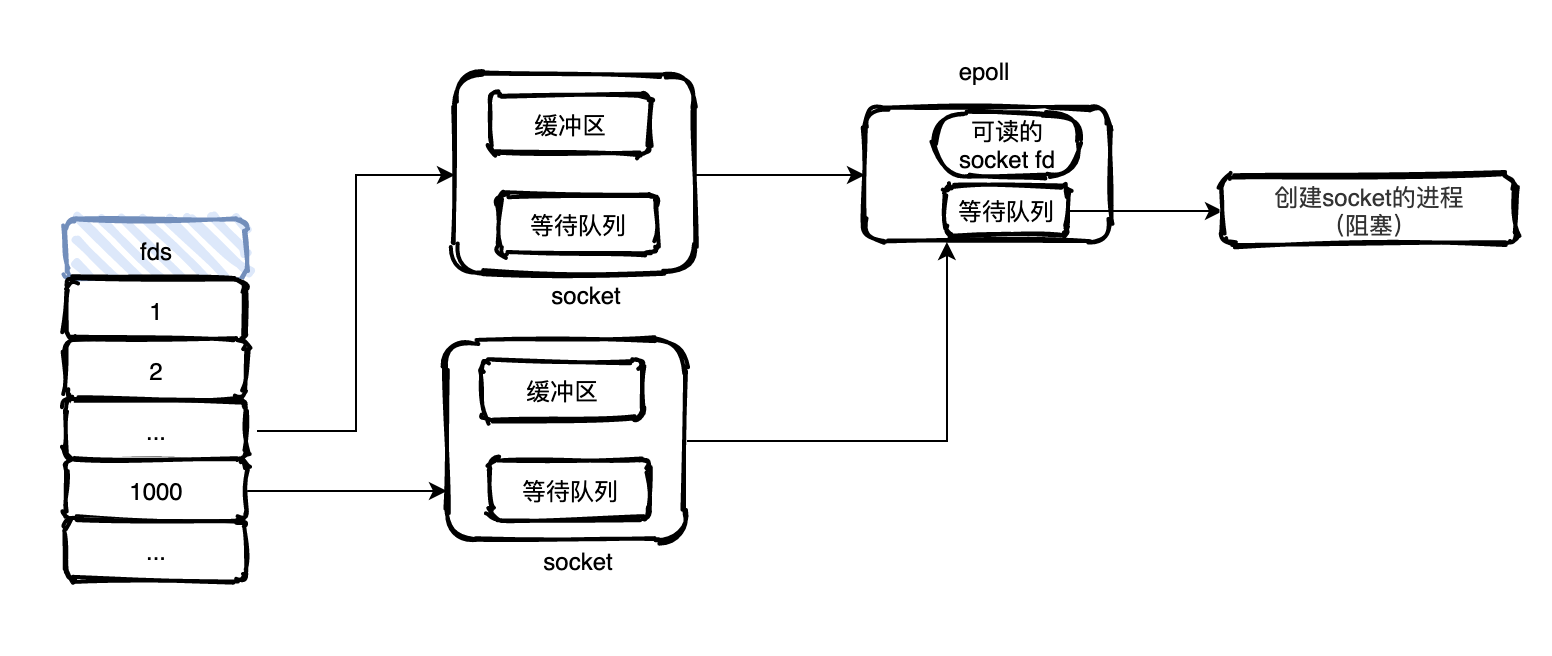
epoll是怎么做到的?
首先内核的socket不在和用户的进程绑定了,而是和epoll绑定,这样当socket的数据到来时,中断程序就会给epoll的一个就绪对列添加对应socket fd,这个队列里都是有数据的socket,然后和epoll关联的进程也会被唤醒,当cpu运行进程的时候,就可以直接从epoll的就绪队列中获取有事件的socket,执行接下来的读。整个流程下来,可以发现用户程序不用无脑遍历,内核也不用遍历,通过中断做到"谁有数据处理谁"的高效表现。
单线程到多线程的演进
单线程
结合Reactor的思想加上高性能epoll IO模式,redis开发出一套高性能的网络IO架构:单线程的IO多路复用,IO多路复用器负责接受网络IO事件,事件最终以队列的方式排队等待被处理,这是最原始的单线程模型,为什么使用单线程?因为单线程的redis已经可以达到10w qps的负载(如果做一些复杂的集合操作,会降低),满足绝大部分应用场景了,同时单线程不用考虑多线程带来的锁的问题,如果还没达到你的要求,那么你也可以配置分片模式,让不同的节点处理不同的sharding key,这样你的redis server的负载能力就能随着节点的增长而进一步线性增长。
异步线程
在单线程模式下有这样一个问题,当执行删除某个很大的集合或者hash的时候会很耗时(不是连续内存),那么单线程的表现就是其他还在排队的命令就得等待。当等待的命令越来越多,那么不好的事情就会发生。于是redis4.0针对大key删除的情况,出了个异步线程。用unlink代替del去执行删除,这样当我们unlink的时候,redis会检测当删除的key是否需要放到异步线程去执行(比如集合的数量超过64个...),如果value足够大,那么就会放到异步线程里去处理,不会影响主线程。同样的还有flushall、flushdb都支持异步模式。此外redis还支持某些场景下是否需要异步线程来处理的模式(默认是关闭的):
lazyfree-lazy-eviction no lazyfree-lazy-expire no lazyfree-lazy-server-del no replica-lazy-flush no
lazyfree-lazy-eviction:针对redis有设置内存达到maxmemory的淘汰策略时,这时候会启动异步删除,此场景异步删除的缺点就是如果删除不及时,内存不能得到及时释放。
lazyfree-lazy-expire:对于有ttl的key,在被redis清理的时候,不执行同步删除,加入异步线程来删除。
replica-lazy-flush:在slave节点加入进来的时候,会执行flush清空自己的数据,如果flush耗时较久,那么复制缓冲区堆积的数据就越多,后面slave同步数据较相对慢,开启replica-lazy-flush后,slave的flush可以交由异步现成来处理,从而提高同步的速度。
lazyfree-lazy-server-del:这个选项是针对一些指令,比如rename一个字段的时候执行RENAME key newkey, 如果这时newkey是b存在的,对于rename来说它就要删除这个newkey原来的老值,如果这个老值很大,那么就会造成阻塞,当开启了这个选项时也会交给异步线程来操作,这样就不会阻塞主线程了。
多线程
redis单线程+异步线程+分片已经能满足了绝大部分应用,然后没有最好只有更好,redis在6.0还是推出了多线程模式。默认情况下,多线程模式是关闭的。
# io-threads 4 # work线程数 # io-threads-do-reads no # 是否开启
多线程的作用点?
通过上文我们知道当我们从一个socket中读取数据的时候,需要从内核copy到用户空间,当我们往socket中写数据的时候,需要从用户空间copy到内核。redis本身的计算还是很快的,慢的地方那么主要就是socket IO相关操作了。当我们的qps非常大的时候,单线程的redis无法发挥多核cpu的好处,那么通过开启多个线程利用多核cpu来分担IO操作是个不错的选择。
So for instance if you have a four cores boxes, try to use 2 or 3 I/O threads, if you have a 8 cores, try to use 6 threads.
开启的话,官方建议对于一个4核的机器来说,开2-3个IO线程,如果有8核,那么开6个IO线程即可。
多线程的原理
需要注意的是redis的多线程仅仅只是处理socket IO读写是多个线程,真正去运行指令还是一个线程去执行的。
- redis server通过EventLoop来监听客户端的请求,当一个请求到来时,主线程并不会立马解析执行,而是把它放到全局读队列clients_pending_read中,并给每个client打上CLIENT_PENDING_READ标识。
- 然后主线程通过RR(Round-robin)策略把所有任务分配给I/O线程和主线程自己。
- 每个线程(包括主线程和子线程)根据分配到的任务,通过client的CLIENT_PENDING_READ标识只做请求参数的读取和解析(这里并不执行命令)。
- 主线程会忙轮询等待所有的IO线程执行完,每个IO线程都会维护一个本地的队列io_threads_list和本地的原子计数器io_threads_pending,线程之间的任务是隔离的,不会重叠,当IO线程完成任务之后,io_threads_pending[index] = 0,当所有的io_threads_pending都是0的时候,就是任务执行完毕之时。
- 当所有read执行完毕之后,主线程通过遍历clients_pending_read队列,来执行真正的exec动作。
- 在完成命令的读取、解析、执行之后,就要把结果响应给客户端了。主线程会把需要响应的client加入到全局的clients_pending_write队列中。
- 主线程遍历clients_pending_write队列,再通过RR(Round-robin)策略把所有任务分给I/O线程和主线程,让它们将数据回写给客户端。
多线程模式下,每个IO线程负责处理自己的队列,不会互相干扰,IO线程要么同时在读,要么同时在写,不会同时读或写。主线程也只会在所有的子线程的任务处理完毕之后,才会尝试再次分配任务。同时最终的命令执行还是由主线程自己来完成,整个过程不涉及到锁。
以上就是Redis线程IO模型的演进教程示例精讲的详细内容,更多关于Redis线程IO模型的演进的资料请关注我们其它相关文章!
相关推荐
-
关于Redis网络模型的源码详析
前言 Redis的网络模型是基于I/O多路复用程序来实现的.源码中包含四种多路复用函数库epoll.select.evport.kqueue.在程序编译时会根据系统自动选择这四种库其中之一.下面以epoll为例,来分析Redis的I/O模块的源码. epoll系统调用方法 Redis网络事件处理模块的代码都是围绕epoll那三个系统方法来写的.先把这三个方法弄清楚,后面就不难了. epfd = epoll_create(1024); 创建epoll实例 参数:表示该 epoll 实例最多可监听的
-

Redis中事件驱动模型示例详解
前言 Redis 是一个事件驱动的内存数据库,服务器需要处理两种类型的事件. 文件事件 时间事件 下面就会介绍这两种事件的实现原理. 文件事件 Redis 服务器通过 socket 实现与客户端(或其他redis服务器)的交互,文件事件就是服务器对 socket 操作的抽象. Redis 服务器,通过监听这些 socket 产生的文件事件并处理这些事件,实现对客户端调用的响应. Reactor Redis 基于 Reactor 模式开发了自己的事件处理器. 这里就先展开讲一讲 Reactor 模
-
Redis三种集群模式详解
目录 三种集群模式 一.主从复制 1.reids主从模式 2.redis复制原理 3.redis主从复制原理 4.redis主从复制优缺点 二.Sentinel 哨兵模式 1.Sentinel系统 2.Sentinel故障转移 2.1.Sentinel 哨兵监控过程 2.2.Sentinel 哨兵故障转移 3.Sentinel 哨兵优缺点 三.cluster 模式 1.reids cluster 2.Redis Cluster 数据分片原理 3.Redis Cluster 复制原理 4.redi
-
Redis入门教程详解
目录 Redis 一.Redis基本数据结构 1. 字符串 (String) 2. 散列(hash) 3. 列表(list) 4. 集合(Set) 5. 有序集合(sorted set) 二.Redis的高级数据结构 1. HyperLogLog 2. GEO 3. BitMap 三.Redis 高级特性 1. Redis事务 2. 发布订阅 3. 脚本 4. Redis Stream 四.Redis使用场景 1. 业务数据缓存 2. 业务数据处理 3. 全局一致计数 4. 高效统计计数 5.
-
Redis高效率原因及数据结构分析
目录 1.什么是redis?它主要用来干什么的? 2.redis为什么这么快? 基于内存存储实现 高效的数据结构 1.SDS简单动态字符串 2.字典 3.跳表 合理的数据编码 合理的线程模型 1.I/O多路复用 2.什么是I/O多路复用? 3.单线程模型 虚拟内存机制 Redis的虚拟内存机制是啥呢? 1.什么是redis?它主要用来干什么的? Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持
-
Redis缓存IO模型的演进教程示例精讲
目录 前言 事件模型 通信 copy数据的开销 数据怎么知道发给哪个socket socket的数据怎么通知程序来取 Reactor IO多路复用器 select epoll epoll是怎么做到的? 单线程到多线程的演进 单线程 异步线程 多线程 多线程的作用点? 多线程的原理 前言 redis作为应用最广泛的nosql数据库之一,大大小小也经历过很多次升级.在4.0版本之前,单线程+IO多路复用使得redis的性能已经达到一个非常高的高度了.作者也说过,之所以设计成单线程是因为redis的瓶
-
C++ Boost Intrusive库示例精讲
目录 一.说明 二.示例 一.说明 Boost.Intrusive 是一个特别适合在高性能程序中使用的库.该库提供了创建侵入式容器的工具.这些容器替换了标准库中的已知容器.它们的缺点是它们不能像 std::list 或 std::set 那样容易使用.但它们有以下优点: 侵入式容器不会动态分配内存.对 push_back() 的调用不会导致使用 new 进行动态分配.这是侵入式容器可以提高性能的一个原因. 侵入式容器不会动态分配内存.对 push_bacIntrusive 容器的调用存储原始对象
-
php实现的redis缓存类定义与使用方法示例
本文实例讲述了php实现的redis缓存类定义与使用方法.分享给大家供大家参考,具体如下: php+redis缓存类 <?php class redisCache { /** * $host : redis服务器ip * $port : redis服务器端口 * $lifetime : 缓存文件有效期,单位为秒 * $cacheid : 缓存文件路径,包含文件名 */ private $host; private $port; private $lifetime; private $cachei
-
C++语言io流处理基本操作教程示例详解
目录 一.输入输出流对象 流对象常用的处理函数 流控制字符 二.字符流操作 sstream 三. 文件流流类 四.文件指针定位 一.输入输出流对象 cout:标准输出流 cerr:标准出凑 和cout(只是用于如果是错误时要输出的) cin : 标准输入 流对象常用的处理函数 输出字符 put() 输入字符:get() 输出字符串:write() 输入字符串getline() char ch; cin.get(ch); cout << ch<<endl; cout.put(
-
C++语言io流处理基本操作教程示例
目录 一.输入输出流对象 流对象常用的处理函数 流控制字符 二.字符流操作 sstream 三. 文件流流类 四.文件指针定位 一.输入输出流对象 cout:标准输出流 cerr:标准出凑 和cout(只是用于如果是错误时要输出的) cin : 标准输入 流对象常用的处理函数 输出字符 put() 输入字符:get() 输出字符串:write() 输入字符串getline() char ch; cin.get(ch); cout << ch<<endl; cout.put(
-
SpringBoot Redis缓存数据实现解析
这篇文章主要介绍了SpringBoot Redis缓存数据实现解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.启用对缓存的支持 spring对缓存的支持有两种方式: a.注解驱动的缓存 b.XML声明的缓存 本文主要介绍纯Java配置的缓存,那么必须在配置类上添加@EnableCaching,这样的话就能启动注解驱动的缓存. 2.使用Redis缓存 缓存的条目不过是一个键值对(Key-Value),其中key描述了产生value的操作和
-
spring boot注解方式使用redis缓存操作示例
本文实例讲述了spring boot注解方式使用redis缓存操作.分享给大家供大家参考,具体如下: 引入依赖库 在pom中引入依赖库,如下 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <dependency> &l
-
Android进阶之从IO到NIO的模型机制演进
目录 引言 1 Basic IO模型 1.1 RandomAccessFile的缓冲区和BufferedInputStream缓冲区的区别 1.2 Basic IO模型底层原理 2 NIO模型 3 OKIO 引言 其实IO操作相较于服务端,客户端做的并不多,基本的场景就是读写文件的时候会使用到InputStream或者OutputStream,然而客户端能做的就是发起一个读写的指令,真正的操作是内核层通过ioctl指令执行读写操作,因为每次的IO操作都涉及到了线程的操作,因此会有性能上的损耗,那
-
Java客户端利用Jedis操作redis缓存示例代码
前言 Redis是一个开源的Key-Value数据缓存,和Memcached类似.Redis多种类型的value,包括string(字符串).list(链表).set(集合).zset(sorted set --有序集合)和hash(哈希类型). Jedis 是 Redis 官方首选的 Java 客户端开发包.下面就来给大家详细关于Java客户端利用Jedis操作redis缓存的相关内容,话不多说,直接来看示例代码吧. 示例代码: //连接redis ,redis的默认端口是6379 Jedis
-
在Python中使用AOP实现Redis缓存示例
越来越觉得的缓存是计算机科学里最NB的发明(没有之一),本文就来介绍了一下在Python中使用AOP实现Redis缓存示例,小伙伴们一起来了解一下 import redis enable=True #enable=False def readRedis(key): if enable: r = redis.Redis(host='10.224.38.31', port=8690,db=0, password='xxxx') val = r.get(key) if val is None: pri