tensorflow2.0与tensorflow1.0的性能区别介绍
从某种意义讲,tensorflow这个项目已经失败了,要不了几年以后,江湖上再无tensorflow
因为tensorflow2.0 和tensorflow1.0 从本质上讲就是两个项目,1.0的静态图有他的优势,比如性能方面,但是debug不方便,2.0的动态图就是在模仿pytorch,但是画虎不成反类犬.
为了对比1.0 与2.0
1. pip install tensorflow==2.0.0a0
2. 为了控制变量我把mnist保存到本地的mongodb
3. 两种网络结构是一样的
ipython
import mnist_data mnist_data.save_mnist_mongodb()
0 100 200 300 400 500 ...
Step 1600 : loss 0.597398758 ; accuracy 0.906712472 Step 1700 : loss 0.0526806675 ; accuracy 0.90900588 Step 1800 : loss 0.212036133 ; accuracy 0.911422193 Step 1900 : loss 0.245924264 ; accuracy 0.913889468 Step 2000 : loss 0.0638188794 ; accuracy 0.915765 20.71102285385132 Final step 2000 : loss tf.Tensor(0.06381888, shape=(), dtype=float32) ; accuracy tf.Tensor(0.915765, shape=(), dtype=float32)
tensorflow2.0 耗时20.7秒
pip install tensorflow==1.13.1
step 1700, training accuracy 0.960 step 1800, training accuracy 0.900 step 1900, training accuracy 0.930 12.46434211730957 test accuracy 0.942
tensorflow2.0 耗时12.46秒,所以在用cpu 做训练时,相同的网络结构,相同的数据集合,tensorflow2.0比tensorflow1.0慢60%,tensorflow 静态图有非常明显的速度优势.

这是 tensorflow2.0 在训练时的cpu占用32.3%
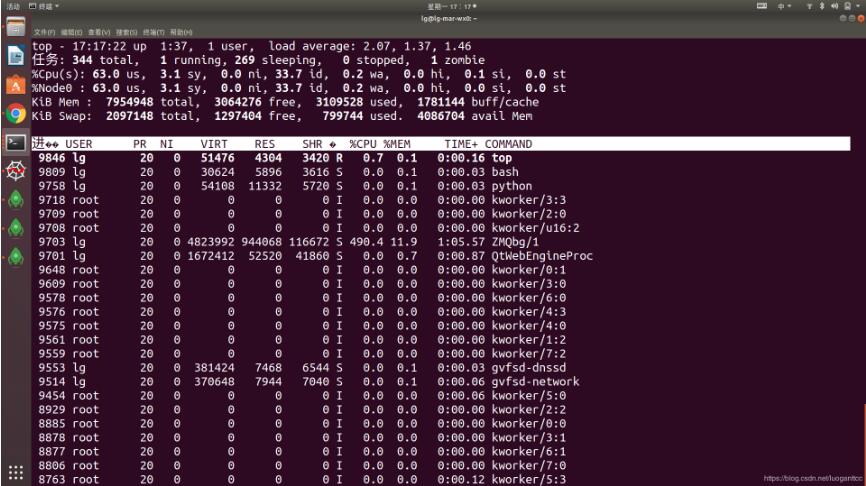
这是 tensorflow1.0 在训练时的cpu占用63%,这也是tensorflow1.0 的优势,更能发挥硬件的优势
以上这篇tensorflow2.0与tensorflow1.0的性能区别介绍就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
基于Tensorflow使用CPU而不用GPU问题的解决
之前的文章讲过用Tensorflow的object detection api训练MobileNetV2-SSDLite,然后发现训练的时候没有利用到GPU,反而CPU占用率贼高(可能会有Could not dlopen library 'libcudart.so.10.0'之类的警告).经调查应该是Tensorflow的GPU版本跟服务器所用的cuda及cudnn版本不匹配引起的.知道问题所在之后就好办了. 检查cuda和cudnn版本 首先查看cuda版本: cat /usr/local/
-
Tensorflow训练模型越来越慢的2种解决方案
1 解决方案 [方案一] 载入模型结构放在全局,即tensorflow会话外层. '''载入模型结构:最关键的一步''' saver = tf.train.Saver() '''建立会话''' with tf.Session() as sess: for i in range(STEPS): '''开始训练''' _, loss_1, acc, summary = sess.run([train_op_1, train_loss, train_acc, summary_op], feed_dic
-
浅谈Tensorflow由于版本问题出现的几种错误及解决方法
1.AttributeError: 'module' object has no attribute 'rnn_cell' S:将tf.nn.rnn_cell替换为tf.contrib.rnn 2.TypeError: Expected int32, got list containing Tensors of type '_Message' instead. S:由于tf.concat的问题,将tf.concat(1, [conv1, conv2]) 的格式替换为tf.concat( [con
-
tensorflow2.0保存和恢复模型3种方法
方法1:只保存模型的权重和偏置 这种方法不会保存整个网络的结构,只是保存模型的权重和偏置,所以在后期恢复模型之前,必须手动创建和之前模型一模一样的模型,以保证权重和偏置的维度和保存之前的相同. tf.keras.model类中的save_weights方法和load_weights方法,参数解释我就直接搬运官网的内容了. save_weights( filepath, overwrite=True, save_format=None ) Arguments: filepath: String,
-
tensorflow2.0与tensorflow1.0的性能区别介绍
从某种意义讲,tensorflow这个项目已经失败了,要不了几年以后,江湖上再无tensorflow 因为tensorflow2.0 和tensorflow1.0 从本质上讲就是两个项目,1.0的静态图有他的优势,比如性能方面,但是debug不方便,2.0的动态图就是在模仿pytorch,但是画虎不成反类犬. 为了对比1.0 与2.0 1. pip install tensorflow==2.0.0a0 2. 为了控制变量我把mnist保存到本地的mongodb 3. 两种网络结构是一样的 ip
-
vue学习笔记之vue1.0和vue2.0的区别介绍
今天我们来说一说vue1.0和vue2.0的主要变化有哪些 一.在每个组件模板,不在支持片段代码 VUE1.0是: <template> <h3>我是组件</h3><strong>我是加粗标签</strong> </template> VUE2.0:必须有根元素,包裹住所有的代码 <template id="aaa"> <div> <h3>我是组件</h3> <
-
Python3.0与2.X版本的区别实例分析
本文通过列举出一些常见的实例来分析Python3.0与2.X版本的区别,是作者经验的总结,对于Python程序设计人员来说有不错的参考价值.具体如下: 做为一个前端开发的码农,最近通过阅读最新版的<A byte of Python>并与老版本的<A byte of Python>做对比后,发现Python3.0在某些地方还是有些改变的.之后再查阅官方网站的文档,总结出一下区别: 1. 如果你下载的是最新版的Python,就会发现所有书中的Hello World例子将不再正确. Py
-
浅谈tensorflow1.0 池化层(pooling)和全连接层(dense)
池化层定义在tensorflow/python/layers/pooling.py. 有最大值池化和均值池化. 1.tf.layers.max_pooling2d max_pooling2d( inputs, pool_size, strides, padding='valid', data_format='channels_last', name=None ) inputs: 进行池化的数据. pool_size: 池化的核大小(pool_height, pool_width),如[3,3].
-
python_array[0][0]与array[0,0]的区别详解
在学习python的时候, 看到有些 代码中使用array[0][0] 来提取位置元素 不太明白. 动手实验了一下 import numpy as np a = np.array([np.arange(12),np.arange(12,24)]) >>>print a [[ 0 1 2 3 4 5 6 7 8 9 10 11] [12 13 14 15 16 17 18 19 20 21 22 23]] >>>print a[0][6] 6 [0][6] means:
-
python 中[0]*2与0*2的区别说明
程序用例: a=[[1,2],[4,5]] b=[0]*len(a) d=0*len(a) print("len(a)=",len(a)) print("b=",b) print("d=",d) print(2*[1,2]) print([1,2]*2) 输出如下: len(a)= 2 b= [0, 0] d= 0 [1, 2, 1, 2] [1, 2, 1, 2] 可以看出在矩阵后面程一个数等于将其复制几次. 补充:创建二维数组 以及 pyth
-

vue2.0/3.0的响应式原理及区别浅析
前言 自从vue3.0正式上线以来,好多小伙伴都转战vue3.0了,这里把我自己总结的3.0和2.0的原理以及他俩的区别写出来,方便自己学习. step 一,vue2.0的响应式原理 先看看官网的解释: 当你把一个普通的 JavaScript 对象传给 Vue 实例的 data 选项,Vue 将遍历此对象所有的属性,并使用 Object.defineProperty把这些属性全部转为 getter/setter.Object.defineProperty 是 ES5 中一个无法 shim 的特性
-
低版本Druid连接池+MySQL驱动8.0导致线程阻塞、性能受限
目录 现象 根因分析 getLastPacketReceivedTimeMs()方法调用时机 解决方案 现象 应用升级MySQL驱动8.0后,在并发量较高时,查看监控打点,Druid连接池拿到连接并执行SQL的时间大部分都超过200ms 对系统进行压测,发现出现大量线程阻塞的情况,线程dump信息如下: "http-nio-5366-exec-48" #210 daemon prio=5 os_prio=0 tid=0x00000000023d0800 nid=0x3be9 waiti
-
ThinkPHP6.0前置、后置中间件区别
目录 1. 创建中间件 2. 注册中间件 3. 前置.后置中间件 4. 前置.后置中间件的区别 5. 后置中间件登录拦截器(不推荐) 6. 前置中间件登录拦截器(推荐使用) 1. 创建中间件 命令行创建中间件类文件示例 // app\middleware\Auth php think make:middleware Auth // app\middleware\admin\Auth php think make:middleware admin/Auth // app\admin\middlew
-
python深度学习tensorflow1.0参数和特征提取
目录 tf.trainable_variables()提取训练参数 具体实例 tf.trainable_variables()提取训练参数 在tf中,参与训练的参数可用 tf.trainable_variables()提取出来,如: #取出所有参与训练的参数 params=tf.trainable_variables() print("Trainable variables:------------------------") #循环列出参数 for idx, v in enumera