Jenkins迁移之pipeline共享库的实践示例
目录
- 背景
- 初期需求
- 成果展示
- 共享库
- 共享库结构
- 入口代码: loadPipeline.groovy
- 参数使用 jobInfo 对象管理
- pipeline 结构:defaultPipeline.groovy
- 动态参数:initParamsStage.groovy
- 共享库的扩展示例
背景
我们一直使用的 jenkins 服务还是 2.0 以下不支持 pipeline 的版本。平时创建任务多数使用 maven 项目,构建后的 shell 部署命令都是在各个 job 中独立维护。这种方式的缺点就是:
1.脚本维护麻烦 (环境对应的服务器变更,构建入参更新等等状况);
2.不利于后期功能扩展 (例如 java 服务想接入覆盖率服务);
3.不利于 jenkins 项目迁移 (例如磁盘不足等原因)。
刚好上述原因都遇到了,所以计划迁移到新的 Jenkins 服务中,所有 job 都通过 pipeline 来管理。在使用 pipelin 之后的感觉用 2 个字来形容:真香
顺便感谢一下大佬,但是不知道他的 id,所以直接贴一下他的gitee 共享库项目地址
我的共享库项目中缝合了大佬很多代码,写的太好了,忍不住借鉴一下
初期需求
迁移之初,参考了网上很多的 pipeline 使用教程。首先肯定不想在每个项目中,维护大量的 Jenkinsfile 文件 (万一需要修改,那不是得改到吐,虽然也可以用 git 项目来统一管理 jenkinsfile),最终采用了 Multibranch Pipeline with defaults(多分支流水线) + Pipeline: Multibranch with defaults 插件的方式,通过维护简单的 default jenkinfile 文件来实现 pipeline 的使用。第二个考虑的问题就是,后期对脚本的维护和扩展希望尽可能的简单,这自然就想到 pipeline 共享库的使用。
成果展示
先展示下目前的成果:
1.创建 job
这里是说在 Jenkins 中配置简单,其实还有一些信息配置的,是保存在文件或者数据库中
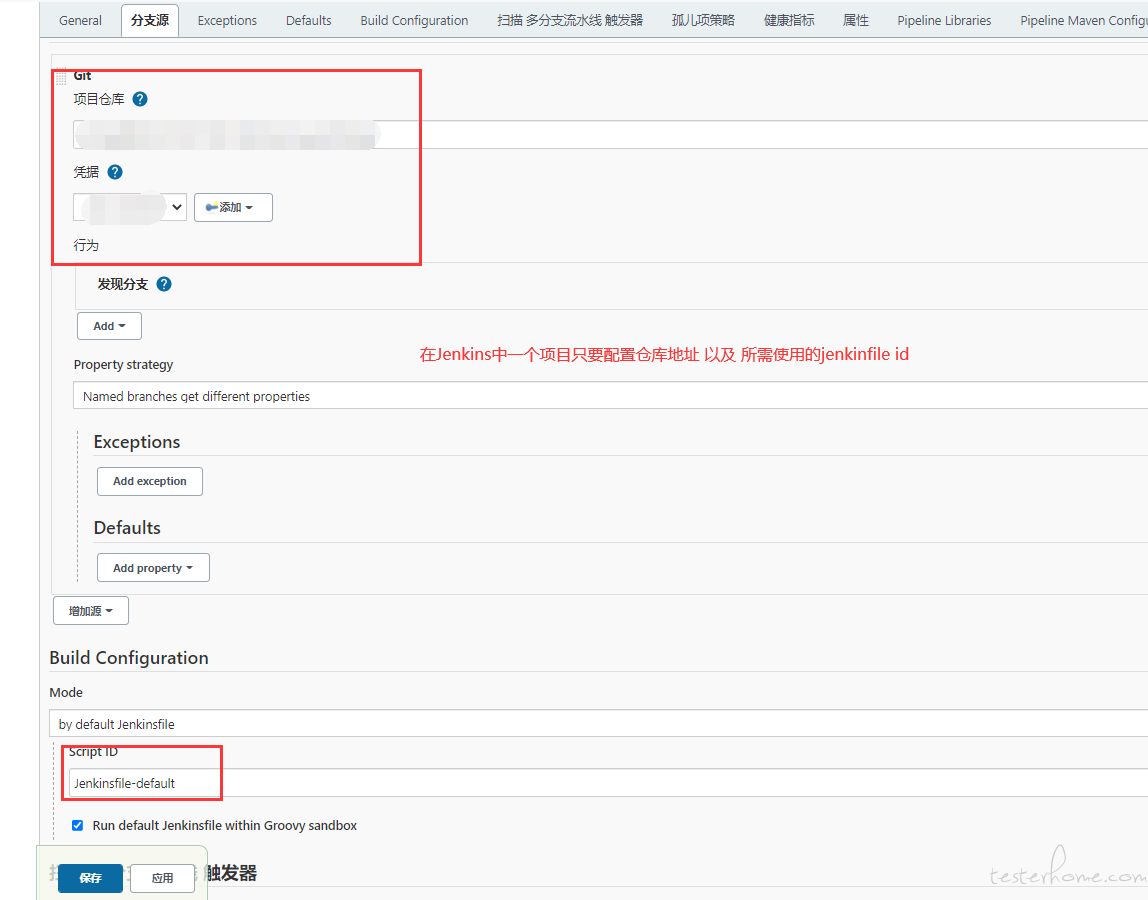
2.job 参数配置
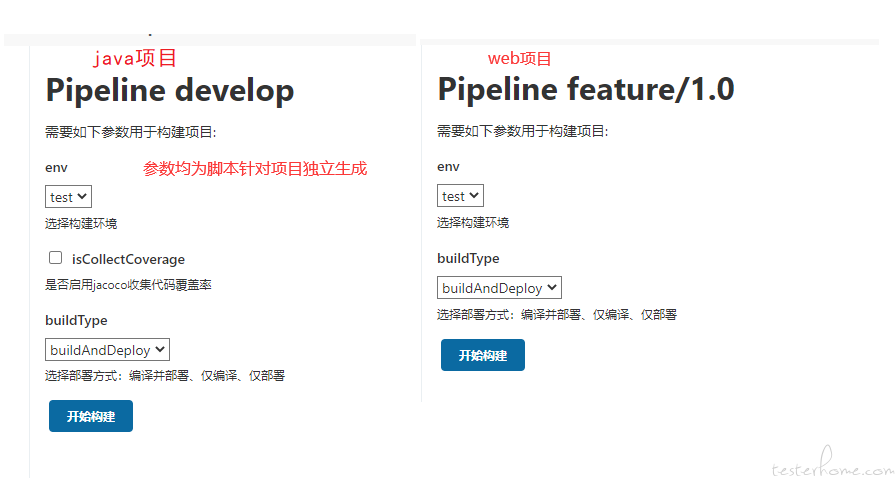
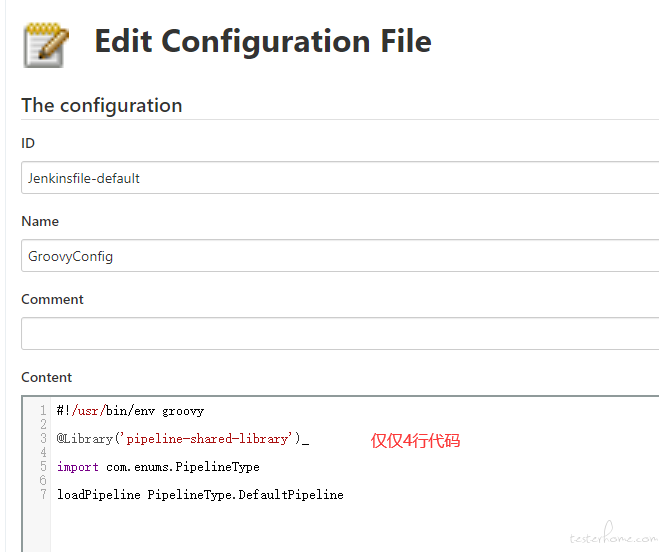
default jenkinsfile 文件的维护 (仅仅负责调用共享库,所有的实现均在共享库项目中完成)
共享库
共享库结构
├─resources │ app.json │ base.json │ host_info.json ├─src │ │ │ └─com │ │ common_util.groovy │ │ exec_shell.groovy │ │ Log.groovy │ │ │ ├─beans │ │ AppJobInfo.groovy │ │ HostInfo.groovy │ │ JavaJobInfo.groovy │ │ JobInfo.groovy │ │ │ ├─build │ │ androidBuild.groovy │ │ build.groovy │ │ gradleBuild.groovy │ │ mavenBuild.groovy │ │ npmBuild.groovy │ │ yarnBuild.groovy │ │ │ ├─deploy │ │ deploy.groovy │ │ │ ├─enums │ │ BuildType.groovy │ │ PipelineType.groovy │ │ ToolsType.groovy │ │ │ ├─qikqiak │ │ GlobalVars.groovy │ │ │ └─services │ JacocoHandle.groovy └─vars defaultPipeline.groovy initParamsStage.groovy loadPipeline.groovy testPipeline.groovy unknownPipeline.groovy
入口代码: loadPipeline.groovy
def call(PipelineType pipelineType) {
JobInfo jobInfo = creatJobInfo()
switch (pipelineType) {
case PipelineType.DefaultPipeline:
defaultPipeline jobInfo
break
case PipelineType.TestPipeline:
testPipeline jobInfo
break
default:
unknownPipeline null
break
}
}
参数使用 jobInfo 对象管理
/**
针对不同类型的项目,使用不同的jobInfo:JavaJobInfo/AppJobinfo
*/
class JobInfo {
/**
* 页面入参
*/
String jobName
String env
BuildType buildType
String branchName
JobInfo(Map map){
this.jobName = map.job_name
this.env = map.env
this.buildType = BuildType.getBuildTypeByKey(map.buildType)
this.branchName = map.branchName
}
/**
* 配置参数
*/
//通用字段
String groupName
ToolsType toolsType
Map<String, String> envMap
def setConfigParams(Map map){
this.groupName = map.groupName
this.toolsType = com.enums.ToolsType.getToolsTypeByKey(map.toolsType)
this.envMap = map.env_map
}
def getEnvKeyList(){
return this.envMap.keySet().toList()
}
def getHost(){
return this.envMap.get(this.env)
}
//默认项
/**
* 是否为自动构建
*/
boolean isAutoBuild = false
/**
* 自动构建时,默认构建的环境:加入构建指令需要环境参数时
*/
String defaultEnv = "test"
/**
* 默认构建方式:仅构建
*/
BuildType defaultBuildType = BuildType.BUILD
@NonCPS
def setAutoBuildParams(){
this.env = defaultEnv
this.buildType = defaultBuildType
}
@Override
@NonCPS
public String toString() {
return "JobInfo{" +
"jobName='" + jobName + '\'' +
", env='" + env + '\'' +
", buildType=" + buildType +
", branchName='" + branchName + '\'' +
", groupName='" + groupName + '\'' +
", toolsType=" + toolsType +
", envMap=" + envMap +
", isAutoBuild=" + isAutoBuild +
", defaultEnv='" + defaultEnv + '\'' +
", defaultBuildType=" + defaultBuildType +
'}';
}
}
pipeline 结构:defaultPipeline.groovy
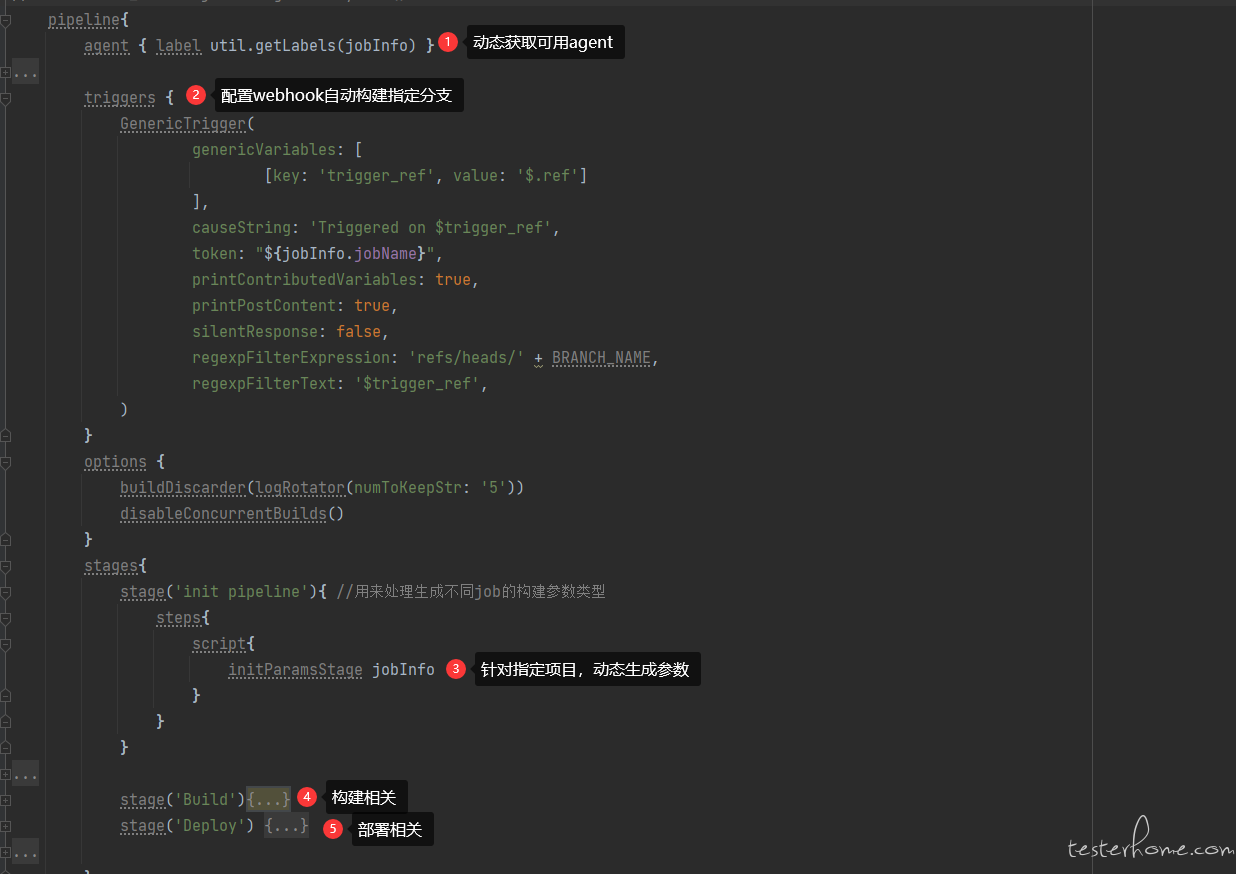
动态参数:initParamsStage.groovy
stage("init params step"){
script{
log.info("start init params...")
/**
* 先根据构建工具,来构建不同的构建参数
* 后期如果同一个构建工具,针对不同的job,入参类型不同,那么在根据job处理
*/
switch (jobInfo.toolsType){
case ToolsType.MVN:
properties([
parameters([
choice(name:'env', choices:env_list, description:'选择构建环境'),
booleanParam(defaultValue:false, name: 'isCollectCoverage',description: '是否启用jacoco收集代码覆盖率'),
choice(name:'buildType', choices:['buildAndDeploy', 'build', 'deploy'],
description:'选择部署方式:编译并部署、仅编译、仅部署')
])
])
break
case ToolsType.GRADLE:
if(jobInfo instanceof AppJobInfo){
properties([
parameters([
choice(name:'env', choices:env_list, description:'选择构建环境'),
choice(name:'buildType', choices:['buildAndDeploy', 'build', 'deploy'],
description:'选择部署方式:编译并部署、仅编译、仅部署')
])
])
}else{
properties([
parameters([
choice(name:'env', choices:env_list, description:'选择构建环境'),
booleanParam(defaultValue:false, name: 'isCollectCoverage',description: '是否启用jacoco收集代码覆盖率'),
choice(name:'buildType', choices:['buildAndDeploy', 'build', 'deploy'],
description:'选择部署方式:编译并部署、仅编译、仅部署')
])
])
}
break
default:
properties([
parameters([
choice(name:'env', choices:env_list, description:'选择构建环境'),
choice(name:'buildType', choices:['buildAndDeploy', 'build', 'deploy'],
description:'选择部署方式:编译并部署、仅编译、仅部署')
])
])
}
}
}
共享库的扩展示例
java 服务增加 jacoco 覆盖率功能
1.维护 JavaAppInfo 对象
class JavaJobInfo extends JobInfo{
boolean isCollectCoverage
JavaJobInfo(Map map) {
super(map)
this.isCollectCoverage = map.isCollectCoverage
}
//Jacoco相关属性
String jacocoPort
String projectId //jacoco覆盖率服务中,coverage_app表中的project_id字段
String commitId
String includes //需要增强类的通配符表达式
String excludes //需要排除增强类的通配符表达式
}
2.在部署时,启动 jacoco
def exec_jar(JavaJobInfo jobInfo){
def util = new common_util()
def log = new Log()
def jacocoHandle = new JacocoHandle()
//判断是否要启用jacoco服务
if(jobInfo.isCollectCoverage){
//先获取jacoco port
jacocoHandle.getJacocoPort(jobInfo)
//在获取本次构建代码最新的commit id
jacocoHandle.getCommitId(jobInfo)
def shell_str = "ssh root@${jobInfo.getHost()} '/home/deployscripts/deploy.sh -d jar //省略 "
if(jobInfo.includes !=""){
shell_str += " -I ${jobInfo.includes}"
}
if(jobInfo.excludes != ""){
shell_str += " -E ${jobInfo.excludes}"
}
shell_str += "'"
sh "${shell_str}"
}else{
sh "ssh root@${jobInfo.getHost()} '/home/deployscripts/deploy.sh -d jar //省略 "
}
}
以上就是Jenkins迁移之pipeline共享库的实践示例的详细内容,更多关于Jenkins迁移共享库pipeline的资料请关注我们其它相关文章!
相关推荐
-
jenkins 构建项目之 pipeline基础教程
一.pipeline 简介 pipeline ,简单来说,就是一套运行在 jenkins 上的工作流框架.将原来独立运行于单个或者多个节点的任务连接起来,实现单个任务难以完成的复杂流程 编排 和 可视化 的工作. 二.pipeline 有哪些好处 代码:pipeline 以代码的形式实现,通常被检入源代码控制,使团队能够编辑,审查和迭代其传送流程. 持久:无论是计划内的还是计划外的服务器重启,pipeline 都是可以恢复的. 可停止:pipeline 可接受交互式输入,以确定是否继续执行 p
-
Jenkins插件pipeline原理及使用方法解析
摘要: pipeline字面意思就是流水线,将很多步骤按顺序排列好,做完一个执行下一个.下面简单介绍下如何使用该插件帮我们完成一些流水线型的任务 pipeline字面意思就是流水线,将很多步骤按顺序排列好,做完一个执行下一个.下面简单介绍下如何使用该插件帮我们完成一些流水线型的任务 一,安装pipeline 进入jenkins的[系统管理]--[插件管理]页面,选择[可选插件]然后搜索pipeline. 然后选择直接安装,它会将依赖的一些插件也一并安装.安装完成后重启jenkins就可以使用了.
-

构建及部署jenkins pipeline实现持续集成持续交付脚本
目录 前言 新增的步骤脚本 需要注意的点: 关于执行启动应用脚本 关于健康检查 线程休眠 健康检查方式 遇到的问题及小技巧 小技巧: 问题: 具体的安全策略异常如下: 解决方案: 文末结语 前言 之前的文章中,已经全面介绍过jenkins pipeline的特点及用途,以及实操了一把,将我们的构建产物jar包丢到了目标主机.这篇是接着上篇的实操,实现构建即部署的脚本实现.会在之前的git clone(拉源码),maven build(构建),deploy jar(上传jia包)的基础上,在新增两
-
jenkins插件pipeline集成持续交付管道全面介绍
目录 前言 Jenkinspipeline是什么? 为什么使用pipeline? enkinsfile支持脚本式ScriptedPipeline和声明式DeclarativePipeline ScriptedPipeline 声明式DeclarativePipeline 使用Jenkinsfile的好处: 关于BlueOcean 前言 前篇博文我们实践了jenkins pipeline的脚本模式,体验到了pipeline的流式构建流程,以及通过bule ocean更清晰的展示了构建的全过程,下
-
jenkins插件Pipeline脚本jenkinsfile操作指南
目录 前言 一,安装pipeline支持插件 二,创建流式Item 三,编写pipeline脚本 脚本如下: 添加运行参数 四,尝试构建任务 五,pipeline的一点技巧 文末结语 前言 jenkins是一款流行的开源持续集成软件,插件丰富,扩展灵活.2.0后推出pipeline流式构建,支持构建任务脚本化.本文主要旨在使用jenkins 的pipeline功能完成java maven项目的打包,上传jar到目标服务器.pipeline推出时间不长,实际使用的不是很多,网上基本没啥参考资料,官
-
Jenkins迁移之pipeline共享库的实践示例
目录 背景 初期需求 成果展示 共享库 共享库结构 入口代码: loadPipeline.groovy 参数使用 jobInfo 对象管理 pipeline 结构:defaultPipeline.groovy 动态参数:initParamsStage.groovy 共享库的扩展示例 背景 我们一直使用的 jenkins 服务还是 2.0 以下不支持 pipeline 的版本.平时创建任务多数使用 maven 项目,构建后的 shell 部署命令都是在各个 job 中独立维护.这种方式的缺点就是:
-
Python调用C语言开发的共享库方法实例
在helloworld工程中,编写了一个简单的两个数值相加的程序,编译成为共享库后,如何使用python对其进行调用呢? 使用ll命令列出当前目录下的共享库,其中共享库名为libhelloworld.so.0.0.0 复制代码 代码如下: ufo@ufo:~/helloworld/.libs$ ll 总用量 32 drwxr-xr-x 2 ufo ufo 4096 1月 29 14:54 ./ drwxr-xr-x 6 ufo ufo 4096 1月 29 16:08 ../ -rw-r--
-
linux使用gcc编译c语言共享库步骤
对任何程序员来说库都是必不可少的.所谓的库是指已经编译好的供你使用的代码.它们常常提供一些通用功能,例如链表和二叉树可以用来保存任何数据,或者是一个特定的功能例如一个数据库服务器的接口,就像MySQL. 大部分大型的软件项目都会包含若干组件,其中一些你发现可以用在其他项目中,又或者你仅仅出于组织目的将不同组件分离出来.当你有一套可复用的并且逻辑清晰的函数时,将其构建为一个库会十分有用,这样你就不将这些源代码拷贝到你的源代码中,而且每次都要再次编译它们.除此之外,你还可以保证你的程序各模块隔离,这
-
Go实现共享库的方法
目录 共享库 创建库 使用库 总结 Don't Repeat Yourself 不要重复自己,这是软件开发的一个基本原则,目的就是减少重复.但是在系统中不同的部分,可能会有不同的业务逻辑,若使用相同的功能来解决不同上下文中的问题,那应该使用公共方法来防止代码重复吗? 共享库 使用共享库可以协助我们管理代码重用的问题,但是需要考虑共享库依赖和变更控制的问题. 如果有几个服务都使用了一个共享库: 共享库发生变更,每个服务都需要使用新版本共享库.旧版本的共享库如果被弃用就会导致服务不可使用,所以在这种
-
Immer 功能最佳实践示例教程
目录 一.前言 二.学习前提 三.历史背景 四.immer 功能介绍 好处 更新模式 更新对象 更新数组 嵌套数据结构 异步 producers & createDraft createDraft 和 finishDraft 五.性能提示 预冻结数据 可以随时选择退出 对于性能消耗大的的搜索操作,从原始 state 读取,而不是 draft 将 produce 拉到尽可能远的地方 六.陷阱 不要重新分配 recipe 参数 Immer 只支持单向树 永远不要从 producer 那里显式返回 u
-
react后台系统最佳实践示例详解
目录 一.中后台系统的技术栈选型 1. 要做什么 2. 要求 3. 技术栈怎么选 二.hooks时代状态管理库的选型 context redux recoil zustand MobX 三.hooks的使用问题与解决方案 总结 一.中后台系统的技术栈选型 本文主要讲三块内容:中后台系统的技术栈选型.hooks时代状态管理库的选型以及hooks的使用问题与解决方案. 1. 要做什么 我们的目标是搭建一个适用于公司内部中后台系统的前端项目最佳实践. 2. 要求 由于业务需求比较多,一名开发人员需要负
-
linux生成(加载)动态库静态库和加载示例方法
动态库的生成: 1./*mysum.c*/ 复制代码 代码如下: #include <stdio.h>#include "src.h" int sum(int a,int b){return (a+b);} 2./*mysum.h*/ 复制代码 代码如下: #ifndef __SRC_H__#define __SRC_H__ int sum(int a,int b); #endif 3./*main.c*/ 复制代码 代码如下: #include <stdio.h&g
-
golang连接redis库及基本操作示例过程
目录 Redis介绍 Redis支持的数据结构 Redis应用场景 准备Redis环境 go-redis库 安装 连接 V8新版本相关 连接Redis哨兵模式 连接Redis集群 基本使用 HVals set/get示例 zset示例 根据前缀获取Key 执行自定义命令 按通配符删除key Pipeline 事务 Watch Redis介绍 Redis是一个开源的内存数据库,Redis提供了多种不同类型的数据结构,很多业务场景下的问题都可以很自然地映射到这些数据结构上.除此之外,通过复制.持久化
-
golang组件swagger生成接口文档实践示例
目录 swagger介绍 gin-swagger实战 第一步:添加注释 第二步:生成接口文档数据 第三步:引入gin-swagger渲染文档数据 swagger介绍 Swagger本质上是一种用于描述使用JSON表示的RESTful API的接口描述语言.Swagger与一组开源软件工具一起使用,以设计.构建.记录和使用RESTful Web服务.Swagger包括自动文档,代码生成和测试用例生成. 在前后端分离的项目开发过程中,如果后端同学能够提供一份清晰明了的接口文档,那么就能极大地提高大家
-
Python爬取视频时长场景实践示例
目录 简介: 获取视频时长的方式 安装 获取视频时长的3种方式对比 简介: 在视频相关测试场景下,例如:有时需要知道全部视频的汇总时长,显然一个个打开并且手工计算耗时耗力,我们可以通过编写脚本进行快速汇总. 获取视频时长的方式 1.通过subprocess进行获取. 2.通过moviepy库中VideoFileClip获取. 3.通过cv2库获取. 安装 1.subprocess:无需安装,Python内置. 2.moviepy:pip install moviepy. 3.cv2:pip in