Python使用read_csv读数据遇到分隔符问题的2种解决方式
目录
- 1.更改read_csv函数中的传参“sep”
- 1.1缺省sep参数
- 1.2不缺省sep参数
- 1.2.1要读入的文档中分隔符为一位字符
- 1.2.2要读入的文档中分隔符为多位字符
- 2.利用记事本功能进行分隔符替换
- 2.1利用txt中的“编辑”—>“替换”操作
- 2.2小tips
- 补充:Python read_csv 报错:‘gbk‘ codec can‘t decode byte 0xb4 in position 8: illegal multibyte sequence
- 总结
用read_csv读数据遇到分隔符问题的两种解决方式
import pandas as pd
1.更改read_csv函数中的传参“sep”
1.1缺省sep参数
默认分隔符为‘,’
1.2不缺省sep参数
1.2.1要读入的文档中分隔符为一位字符
用单引号括起文本中的分隔符
例:sep = '|'
1.2.2要读入的文档中分隔符为多位字符
多位字符在python中被识别为正则式
此时可用为sep = ‘\s+’(不论多位分隔符有什么组成,比如几个空格、\r\t)
此时,python将用自己的语法分析器来对多位字符进行识别
2.利用记事本功能进行分隔符替换
因为自己在编程的时候用正则表达式出现了一些问题,故找到了另一种更改文本中分隔符,以便于设定sep参数的方法,现记录如下。
2.1利用txt中的“编辑”—>“替换”操作
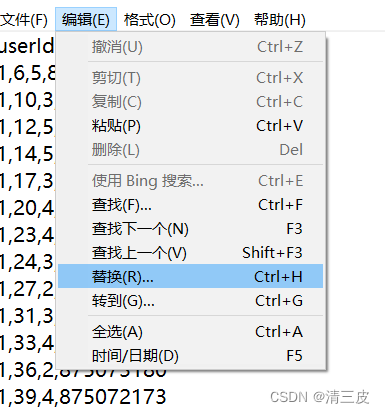
当前分隔符为‘,’

替换为‘ | ’,并单击全部替换
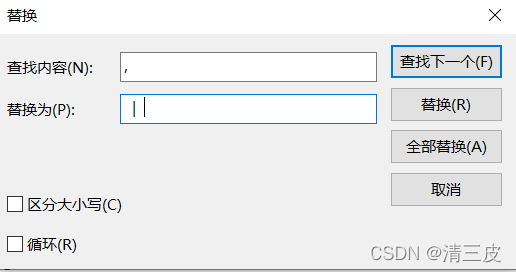
替换后,分隔符为‘ | ’
2.2小tips
选择分隔符的时候有可能面临
“这么大空挡是几个空格?”
“这个逗号是中文的还是英文的?”
…
所以建议直接用鼠标拉着两个数据之间的分割区域,复制,然后粘贴填入要替换的框中。(像我这种手残眼花的人就喜欢这种方式。。。)
补充:Python read_csv 报错:‘gbk‘ codec can‘t decode byte 0xb4 in position 8: illegal multibyte sequence
在我们使用pandas.read_csv()读取文件时 经常会遇到UnicodeDecodeError 的错误
我遇到的主要有两种:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xb4 in position 8: illegal multibyte sequence
或者
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 2: invalid start byte
尝试过改encoding="gbk",encoding="utf-8"或者GB2312、gbk、ISO-8859-1的方法,有时候能够起效果,有时候不行
介绍一种最有效的方法:
1.找到csv文件–>右键–>打开方式–>记事本
2.打开记事本之后,在右下角可以看到文件的默认编码格式为ANSI,选择头部菜单的“文件–>另存为”,
3.选择编码下拉框,选择需要的编码格式UTF-8,重新保存即可
4.使用 read_csv('./test.csv', encoding="utf-8") 即可
下面我遇到过错误可以尝试的解决办法如下(推荐使用上面的,下面的有时候也不行):
1. csvdata = pd.read_csv(file, keep_default_na=False, encoding="gbk")
报错:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xb4 in position 8: illegal multibyte sequence
解决:将 encoding="gbk" 改为encoding="utf-8" 或者删掉
2. csvdata = pd.read_csv(file, keep_default_na=False)
报错:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 2: invalid start byte
解决:加上 encoding="gbk" 试试看
总结
到此这篇关于Python使用read_csv读数据遇到分隔符问题的2种解决方式的文章就介绍到这了,更多相关Python read_csv读数据分隔符问题内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
快速解决pandas.read_csv()乱码的问题
pandas.read_csv()遇到读进来乱码问题 1.设置encoding='gbk'或者encoding='utf-8'.pandas.read_csv('data.csv',encoding='gbk') 2.如果设置encoding直接报错的话 解决方法是:用记事本打开csv文件,另存为设置编码为utf-8,然后重新读取文件设置encoding='utf-8'就好了. 以上这篇快速解决pandas.read_csv()乱码的问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希
-
pandas.read_csv参数详解(小结)
pandas.read_csv参数整理 读取CSV(逗号分割)文件到DataFrame 也支持文件的部分导入和选择迭代 更多帮助参见:http://pandas.pydata.org/pandas-docs/stable/io.html 参数: filepath_or_buffer : str,pathlib.str, pathlib.Path, py._path.local.LocalPath or any object with a read() method (such as a file
-
解决pandas使用read_csv()读取文件遇到的问题
如下: 数据文件: 上海机场 (sh600009) 24.11 3.58 东风汽车 (sh600006) 74.25 1.74 中国国贸 (sh600007) 26.38 2.66 包钢股份 (sh600010) 61.01 2.35 武钢股份 (sh600005) 75.85 1.3 浦发银行 (sh600000) 6.65 0.96 在使用read_csv() API读取CSV文件时求取某一列数据比较大小时, df=pd.read_csv(output_file,encoding='gb23
-
Pandas的read_csv函数参数分析详解
函数原型 复制代码 代码如下: pd.read_csv(filepath_or_buffer, sep=',', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_va
-

Python使用read_csv读数据遇到分隔符问题的2种解决方式
目录 1.更改read_csv函数中的传参“sep” 1.1缺省sep参数 1.2不缺省sep参数 1.2.1要读入的文档中分隔符为一位字符 1.2.2要读入的文档中分隔符为多位字符 2.利用记事本功能进行分隔符替换 2.1利用txt中的“编辑”—>“替换”操作 2.2小tips 补充:Python read_csv 报错:‘gbk‘ codec can‘t decode byte 0xb4 in position 8: illegal multibyte sequence 总结 用read_c
-
Python开发时报TypeError: ‘int‘ object is not iterable错误的解决方式
目录 前言 错误原因 案例1: 案例2: 错误解决方案 案例1解决方案: 案例2解决方案: 结论 前言 当我们编写任何程序时,都会遇到一些错误,会让我们有挫败感,所以我有一个解决方案给你. 今天在这篇文章中,我们将讨论错误类型error: 'int' object is not iterable. 我们将讨论为什么会出现此错误以及此错误的一些可能解决方案.请务必阅读到最后,以节省大量调试此错误的时间. 首先,让我们了解“iterable”(可迭代)一词的含义? 可迭代是我们可以从中获取值并相应地
-
怎么处理Python分割字符串时有多个分隔符
在使用 Python 处理字符串的时候,有时候会需要分割字符. 分隔符比如下划线 "_",比如 "."之类的. 一个分隔符 比如对于文件名 20191022_log.zip,我们想要获取前面的日期. 如果日期格式固定,对于这样的字符串我们当然可以使用索引进行切割. 当然也可以使用字符串的内建函数 split(). 结果返回的是一个列表. 如果分隔符不在字符串之列,那么返回的也是一个列表,不过元素只有一个,那就是这个字符串自身: 多个分隔符 还是上面那个例子,如果
-
python里读写excel等数据文件的6种常用方式(小结)
下面整理下python有哪些方式可以读取数据文件. 1. python内置方法(read.readline.readlines) read() : 一次性读取整个文件内容.推荐使用read(size)方法,size越大运行时间越长 readline() :每次读取一行内容.内存不够时使用,一般不太用 readlines() :一次性读取整个文件内容,并按行返回到list,方便我们遍历 2. 内置模块(csv) python内置了csv模块用于读写csv文件,csv是一种逗号分隔符文件,是数据科学
-
Python下载网络文本数据到本地内存的四种实现方法示例
本文实例讲述了Python下载网络文本数据到本地内存的四种实现方法.分享给大家供大家参考,具体如下: import urllib.request import requests from io import StringIO import numpy as np import pandas as pd ''' 下载网络文件,并导入CSV文件作为numpy的矩阵 ''' # 网络数据文件地址 url = "http://archive.ics.uci.edu/ml/machine-learning
-
python 读写文件包含多种编码格式的解决方式
今天写一个脚本文件,需要将多个文件中的内容汇总到一个txt文件中,由于多个文件有三种不同的编码方式,读写出现错误,先将解决方法记录如下: # -*- coding: utf-8 -*- import wave import pylab as pl import numpy as np import pandas as pd import os import time import datetime import arrow import chardet import sys reload(sys
-
基于python的docx模块处理word和WPS的docx格式文件方式
Python docx module for Word or WPS processing 本文是通过docx把word中的表格中的某些已填好的内容提取出来,存入excel表格. 首先安装docx的python模块: pip install python-docx 由于处理的为中文和符号,改成utf-8编码格式 import sys reload(sys) sys.setdefaultencoding('utf-8') from docx import Document import panda
-
Python加载数据的5种不同方式(收藏)
数据是数据科学家的基础,因此了解许多加载数据进行分析的方法至关重要.在这里,我们将介绍五种Python数据输入技术,并提供代码示例供您参考. 作为初学者,您可能只知道一种使用p andas.read_csv函数读取数据的方式(通常以CSV格式).它是最成熟,功能最强大的功能之一,但其他方法很有帮助,有时肯定会派上用场. 我要讨论的方法是: Manual 函数 loadtxt 函数 genfromtxtf 函数 read_csv 函数 Pickle 我们将用于加载数据的数据集可以在此处找到 .它被
-
Python selenium 三种等待方式详解(必会)
很多人在群里问,这个下拉框定位不到.那个弹出框定位不到-各种定位不到,其实大多数情况下就是两种问题:1 有frame,2 没有加等待.殊不知,你的代码运行速度是什么量级的,而浏览器加载渲染速度又是什么量级的,就好比闪电侠和凹凸曼约好去打怪兽,然后闪电侠打完回来之后问凹凸曼你为啥还在穿鞋没出门?凹凸曼分分中内心一万只羊驼飞过,欺负哥速度慢,哥不跟你玩了,抛个异常撂挑子了. 那么怎么才能照顾到凹凸曼缓慢的加载速度呢?只有一个办法,那就是等喽.说到等,又有三种等法,且听博主一一道来: 1. 强制等待
-
Python判断文件或文件夹是否存在的三种方法
常在读写文件之前,需要判断文件或目录是否存在,不然某些处理方法可能会使程序出错.所以最好在做任何操作之前,先判断文件是否存在. 这里将介绍三种判断文件或文件夹是否存在的方法,分别使用os模块.Try语句.pathlib模块. 1.使用os模块 os模块中的os.path.exists()方法用于检验文件是否存在. 判断文件是否存在 import os os.path.exists(test_file.txt) #True os.path.exists(no_exist_file.txt) #Fa