详解用Python调用百度地图正/逆地理编码API
一、背景
- (正)地理编码指的是:将地理位置名称转换成经纬度;
- 逆地理编码指的是:将经纬度转换成地理位置信息,如地名、所在的省份或城市等
百度地图提供了相应的API,可以方便调用。相应的说明文档如下:
具体API的参数可以查看相应的“服务文档”:
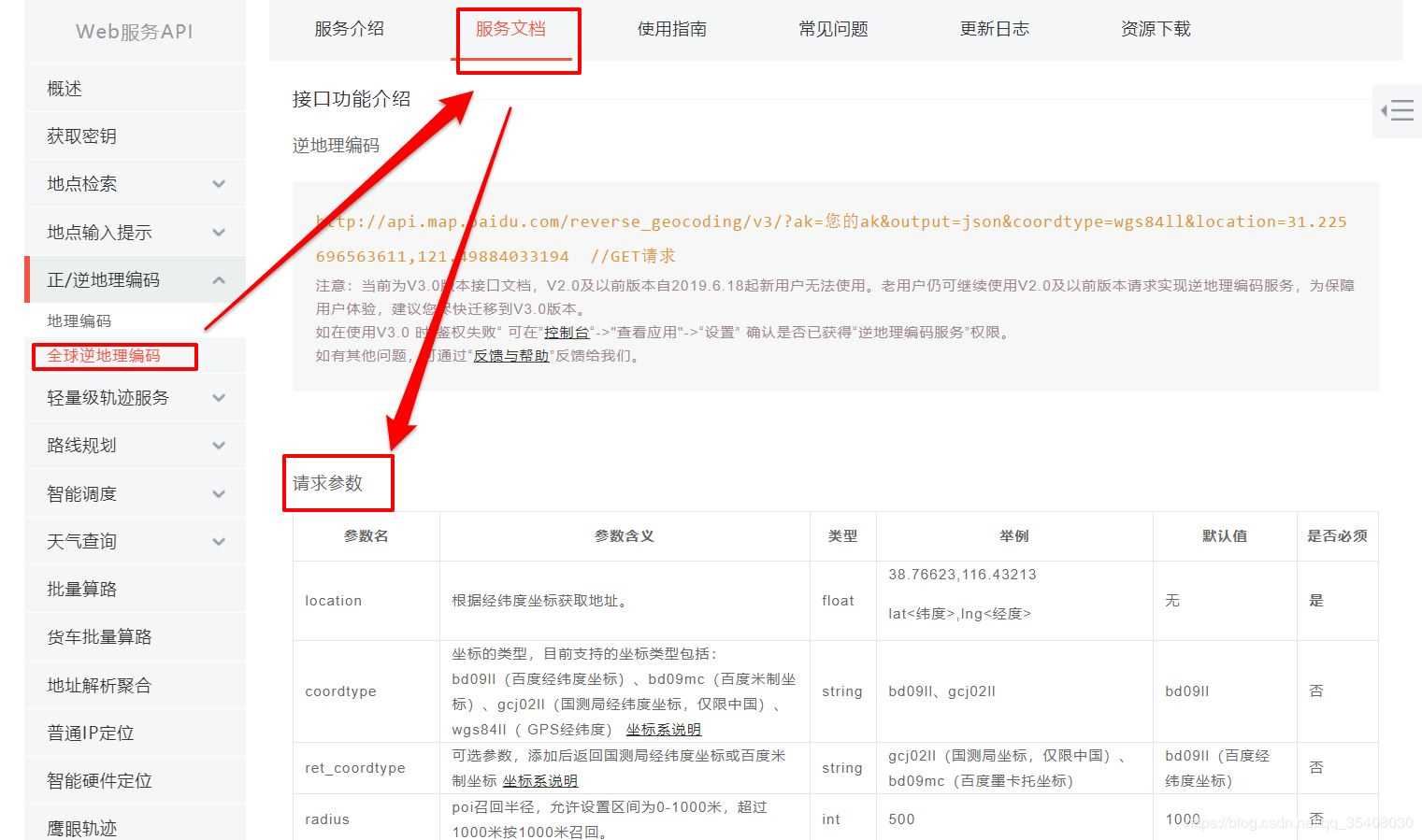
不过首次使用时需要申请,具体在控制台。申请AK的方式可参见其他文章。
二、源码
废话不多说,直接放源码。这里提供了Python调用这两个API的方法。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Author: Wild Orange
# @Email: jixuanfan_seu@163.com
# @Date: 2020-06-21 16:06:14
# @Last Modified time: 2020-07-01 19:35:28
import requests
AK='[这里填写自己申请的AK值]'
def Pos2Coord(name):
'''
@func: 通过百度地图API将地理名称转换成经纬度
@note: 官方文档 http://lbsyun.baidu.com/index.php?title=webapi/guide/webservice-geocoding
@output:
lng: 经度
lat: 纬度
conf: 打点绝对精度(即坐标点的误差范围)
comp: 描述地址理解程度。分值范围0-100,分值越大,服务对地址理解程度越高
level: 能精确理解的地址类型
'''
url = 'http://api.map.baidu.com/geocoding/v3/?address=%s&output=json&ak=%s'%(name,AK)
res = requests.get(url)
if res.status_code==200:
val=res.json()
if val['status']==0:
retVal={'lng':val['result']['location']['lng'],'lat':val['result']['location']['lat'],\
'conf':val['result']['confidence'],'comp':val['result']['comprehension'],'level':val['result']['level']}
else:
retVal=None
return retVal
else:
print('无法获取%s经纬度'%name)
def Coord2Pos(lng,lat,town='true'):
'''
@func: 通过百度地图API将经纬度转换成地理名称
@input:
lng: 经度
lat: 纬度
town: 是否获取乡镇级地理位置信息,默认获取。可选参数(true/false)
@output:
address:解析后的地理位置名称
province:省份名称
city:城市名
district:县级行政区划名
town: 乡镇级行政区划
adcode: 县级行政区划编码
town_code: 镇级行政区划编码
'''
url='http://api.map.baidu.com/reverse_geocoding/v3/?output=json&ak=%s&location=%s,%s&extensions_town=%s'%(AK,lat,lng,town)
res=requests.get(url)
if res.status_code==200:
val=res.json()
if val['status']==0:
val=val['result']
retVal={'address':val['formatted_address'],'province':val['addressComponent']['province'],\
'city':val['addressComponent']['city'],'district':val['addressComponent']['district'],\
'town':val['addressComponent']['town'],'adcode':val['addressComponent']['adcode'],
'town_code':val['addressComponent']['town_code']}
else:
retVal=None
return retVal
else:
print('无法获取(%s,%s)的地理信息!'%(lat,lng))
注意:
函数只返回一些较为常用的地理位置信息。之前提到的官网中的说明文档是最全的,如果确实有需要,可以修改程序代码。
三、使用方法
(1)正地理编码
比如获取学校的经纬度:
val=Pos2Coord('江苏省南京市江宁区秣陵街道东南大学九龙湖校区')
print(val)
输出结果:
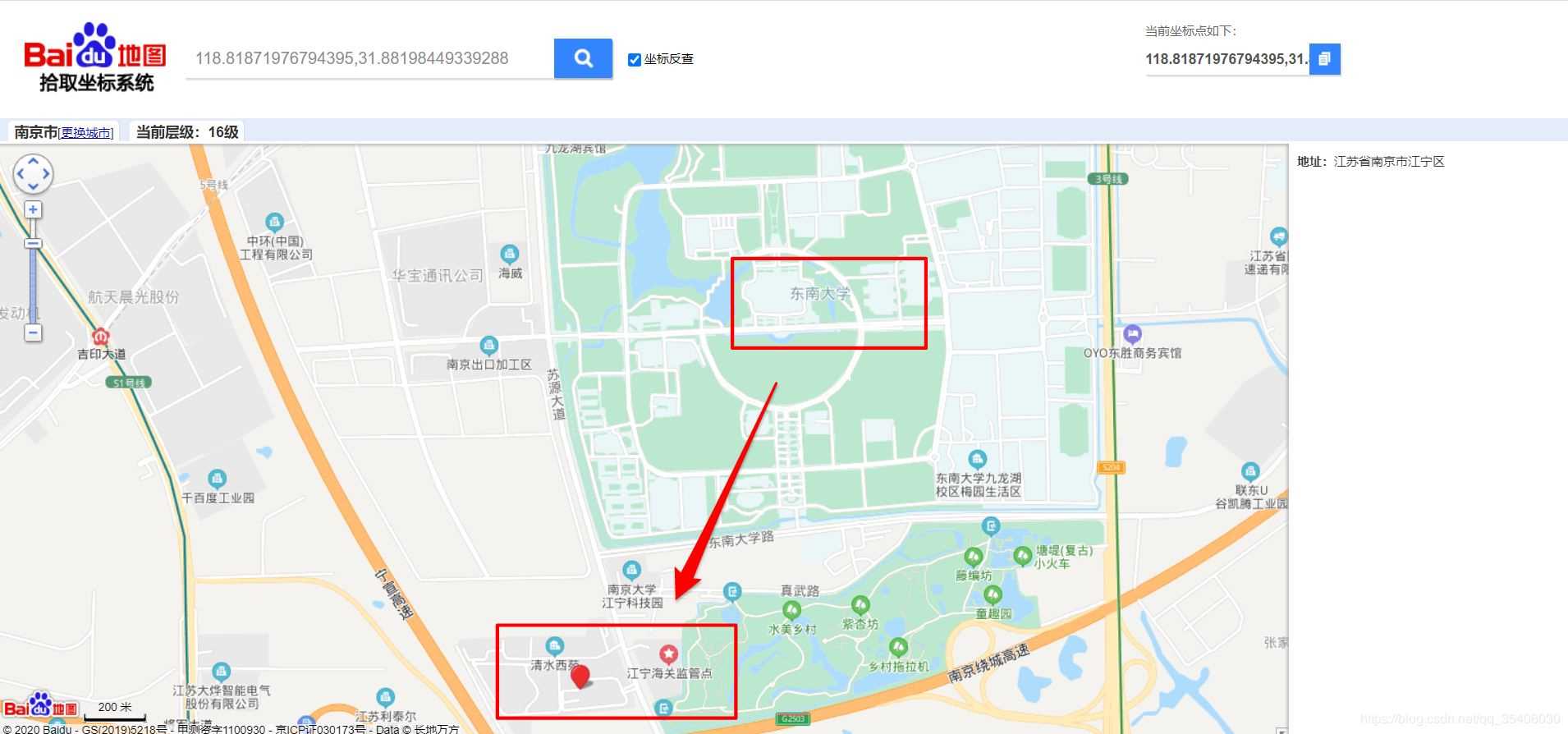
{'lng': 118.81871976794395, 'lat': 31.88198449339288, 'conf': 80, 'comp': 57, 'level': '餐饮'}
可以看出,结果存在一定偏差。竟然把学校标记成了餐馆。。。我们可以具体到百度拾取坐标系统中看一下。结果定位到了学校西南角。
(2)逆地理编码
反过来,我们也可以根据经纬度查询地理位置信息。
val=Coord2Pos(118.81871976794395,31.88198449339288) print(val)
输出结果:
{'address': '江苏省南京市江宁区苏源大道', 'province': '江苏省', 'city': '南京市', 'district': '江宁区', 'town': '秣陵街道', 'adcode': '320115', 'town_code': '320115011'}
解析出的地理位置信息是准确的,可以精确到乡镇级行政区划。
(3)一个有意思的例子
之前也看到了,在正地理编码中,如果提供的地理位置信息不精确,则返回的经纬度很可能存在较大偏差。有这样的需求:根据企业名称,获取其地理位置(经纬度),以及所在的省份、地级市、县级市等信息。
一种直接的思路是:直接将企业名称作为地理位置传给正地理编码API,获取其经纬度;再依据经纬度,利用逆地理编码,获取其所在的省份、地级市、县级市。
随便举个栗子,比如“金华银行股份有限公司”。
val=Pos2Coord('金华银行股份有限公司')
print(val)
结果:
{'lng': 119.65923457293306, 'lat': 29.10738796331567, 'conf': 70, 'comp': 100, 'level': '金融'}
我们看看定位到哪里了:
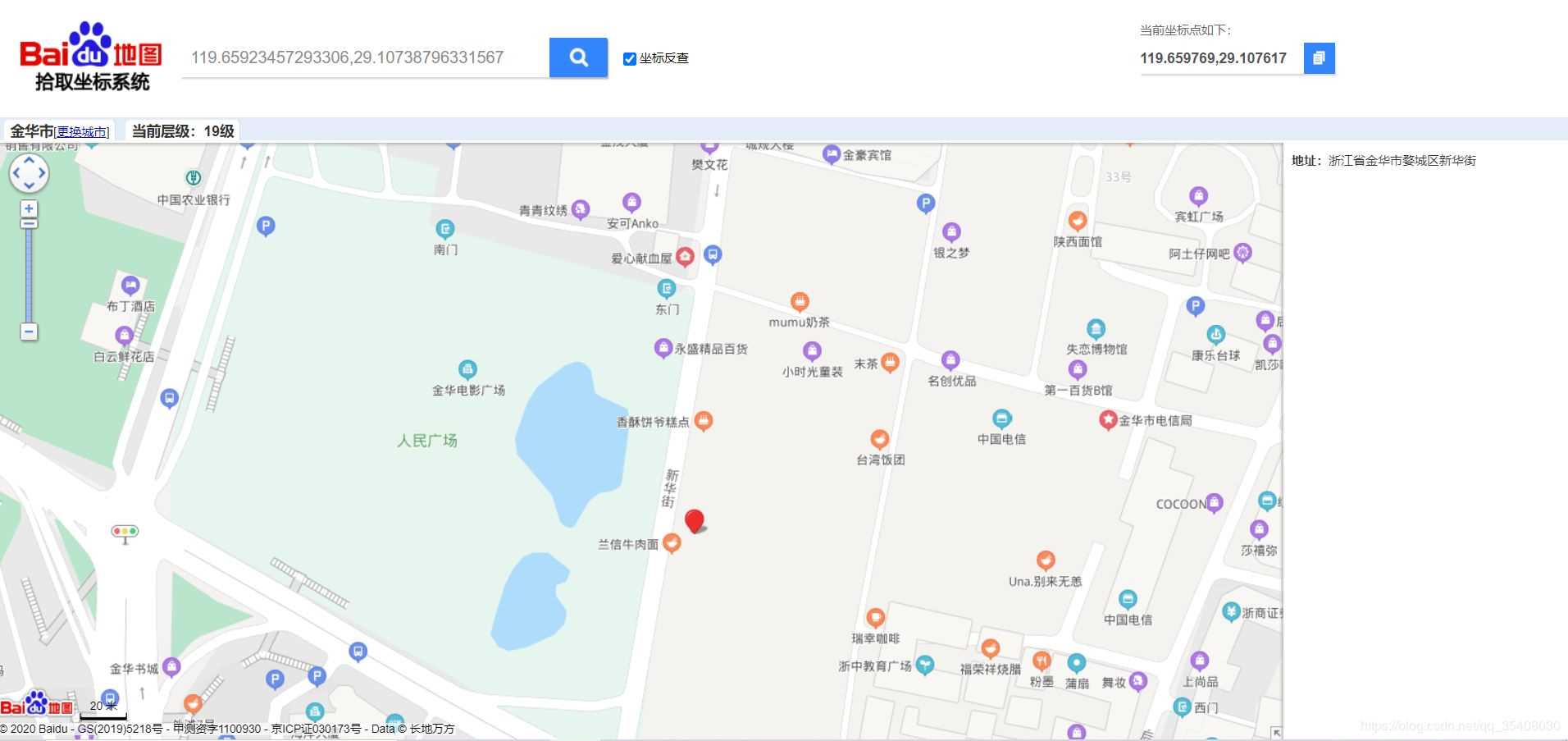
emm… 定位到一个广场的旁边。不过大致的位置还是准确的,毕竟还是在金华市内。如果精度要求不高,这个结果还是可以接受的。
那如果精度要求比较高呢?我们就需要获取非常准确的企业位置信息。百度企业信用提供了企业基本信息的查询。
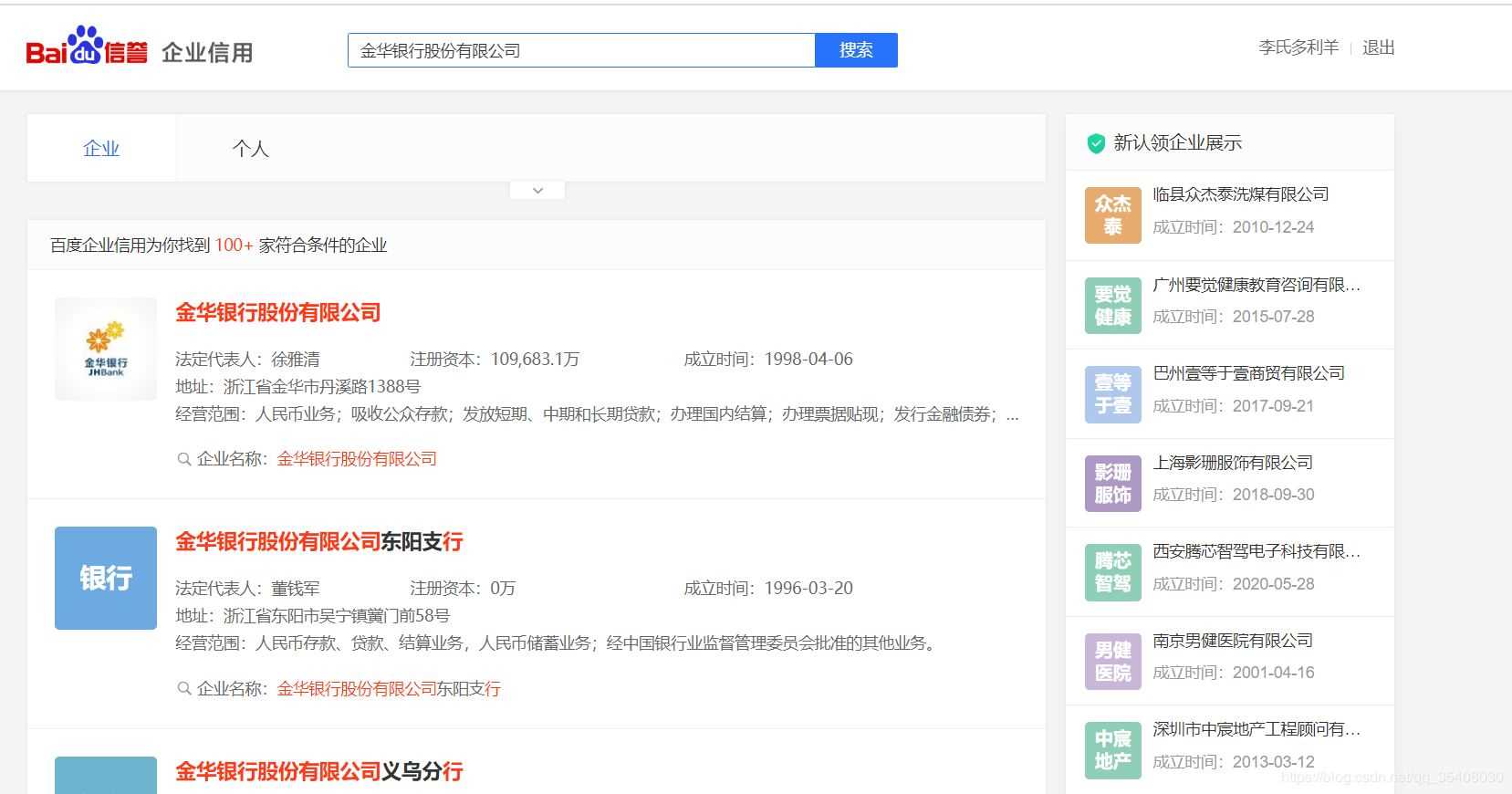
可以看到,企业的地址为:浙江省金华市丹溪路1388号。
我们把这个地址代入API:
Pos2Coord('浙江省金华市丹溪路1388号')
得到结果:
{'lng': 119.65161604390546, 'lat': 29.083163015462144, 'conf': 80, 'comp': 100, 'level': '门址'}
再看看定位到了哪里:

emm…好像看不出来。。我对这里也不熟。。直接到百度地图中看一下:

放到最大后,可以看到,坐标恰好落在“金华银行”上面。Perfect!
人工获取企业具体的地理位置似乎太麻烦了。有没有简单方法呢?可以查看我之前写的一篇文章:用Python爬虫获取百度企业信用中企业基本信息
最后通过逆地理编码获取省份、地级市、县级市信息。
Coord2Pos(119.65161604390546,29.083163015462144)
输出结果:
{'address': '浙江省金华市婺城区双龙南街680号', 'province': '浙江省', 'city': '金华市', 'district': '婺城区', 'town': '西关街道', 'adcode': '330702', 'town_code': '330702007'}
到此这篇关于详解用Python调用百度地图正/逆地理编码API的文章就介绍到这了,更多相关Python调用百度地图正/逆地理编码 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
使用python批量转换文件编码为UTF-8的实现
由于这两天换了IDE,在导入以前的工程的时候发现了一个大问题,由于以前脑残的我不知道改编码方式,导致出现了大量的GBK,这就很难受,要是一个两个还好说,可是这么多要是一个一个的改我会觉得现在的我比以前还脑残,于是乎,我就想用python批量的修改一下,然后就产生了这篇文章,其中好多不足的地方还请大佬指导 本来一开始的思路还是比较清晰,觉得也比较简单,天真的认为用GBK的方式读取出文件内容,然后UTF8写入就好了,可是在实际的操作中我发现我就是太天真了,出现了大量的问题,比如说: 怎么查看文件的编
-
Python利用 utf-8-sig 编码格式解决写入 csv 文件乱码问题
先举个例子,分别以不指定编码.指定编码为 utf-8.指定编码为 utf-8-sig 三种方式来做比较,再将写入 csv 文件和 txt 文件来做个对比 一.不指定编码方式,直接存入 csv 文件 import csv with open('test.csv', 'w') as fp: writer = csv.writer(fp) writer.writerow(['汉语', '俄语', '韩语', '日语', '英语']) writer.writerow(['爱你', 'люблю тебя
-
Python 忽略文件名编码的方法
问题 你想使用原始文件名执行文件的I/O操作,也就是说文件名并没有经过系统默认编码去解码或编码过. 解决方案 默认情况下,所有的文件名都会根据 sys.getfilesystemencoding() 返回的文本编码来编码或解码.比如: >>> sys.getfilesystemencoding() 'utf-8' >>> 如果因为某种原因你想忽略这种编码,可以使用一个原始字节字符串来指定一个文件名即可.比如: >>> # Wrte a file usi
-

Python字符编码转码之GBK,UTF8互转
一.Python字符编码介绍 1.须知: 在python 2中默认编码是 ASCII,而在python 3中默认编码是 unicode unicode 分为utf-32 (占4个字节),utf-16(占两个字节),utf-8(占1-4个字节),所以utf-16 是最常用的unicode版本,但是在文件里存的还是utf-8,因为utf8省空间 在python 3,encode编码的同时会把stringl变成bytes类型,decode解码的同时会把bytes类型变成string类型 在unicod
-
Python爬虫基于lxml解决数据编码乱码问题
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高 XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索 XPath的选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串.数值.时间的匹配以及节点.序列的处理等,几乎所有我们想要定位的节点,都可以用XPath来选择 XPath
-
Python3 解决读取中文文件txt编码的问题
问题描述 尝试用Python写一个Wordcloud的时候,出现了编码问题. 照着网上某些博客的说法添添改改后,结果是变成了"UnicodeDecodeError: 'utf-8' codec can't decode byte-"这个错误. 捣鼓了一天啊,TXT(此处为本人现下内心表情).最后,干脆写个最简单的文件读取,竟然还是报错.于是就考虑是不是txt的编码问题,因为读取的txt文件是在Mac上面新建的纯文本文件,一时没找到在哪里查看编码,最后拷贝到Windows系统上,查看了t
-
浅谈Python2获取中文文件名的编码问题
问题: Python2获取包含中文的文件名是如果不转码会出现乱码. 这里假设要测试的文件夹名为test,文件夹下有5个文件名包含中文的文件分别为: Python性能分析与优化.pdf Python数据分析与挖掘实战.pdf Python编程实战:运用设计模式.并发和程序库创建高质量程序.pdf 流畅的Python.pdf 编写高质量Python代码的59个有效方法.pdf 我们先不转码直接打印获取到的文件名,代码如下: import os for file in os.listdir('./te
-
Python打印特殊符号及对应编码解析
1.调用字符映射表输入特殊符号 在键盘上按win+R,在打开的对话框中输入"charmap",会出现字符映射表: 2.利用字符编码输入特殊符号 #打印Σ print(chr(931)) #打印← print(chr(8592)) #打印→ print(chr(8594)) #打印↑ print(chr(8593)) #打印↓ print(chr(8595)) #打印❋ print(chr(10059)) 结果: Σ ← → ↑ ↓ ❋ 特殊字符对应编码: 以上就是本文的全部内容,希望对
-
详解用Python调用百度地图正/逆地理编码API
一.背景 (正)地理编码指的是:将地理位置名称转换成经纬度: 逆地理编码指的是:将经纬度转换成地理位置信息,如地名.所在的省份或城市等 百度地图提供了相应的API,可以方便调用.相应的说明文档如下: 正地理编码 逆地理编码 具体API的参数可以查看相应的"服务文档": 不过首次使用时需要申请,具体在控制台.申请AK的方式可参见其他文章. 二.源码 废话不多说,直接放源码.这里提供了Python调用这两个API的方法. #!/usr/bin/env python # -*- coding
-
python调用百度地图WEB服务API获取地点对应坐标值
本篇博客介绍如何使用Python调用百度地图WEB服务API获取地点对应坐标值,现有一系列结构化地址数据(如:北京市海淀区上地十街十号),目的是获取对应坐标值. 百度地图开发者平台路线规划使用说明网址 最终结果是写入了txt文件,所以需要在循环遇到错误的时候写入对应的可识别的值(看到这个值就知道这个结果是错误的,可以写对应数量的NA或者0值),方便后续分析. # -*- coding: utf-8 -*- """ Created on Fri Aug 15 10:06:16
-
利用python和百度地图API实现数据地图标注的方法
如题,先上效果图: 主要分为两大步骤 使用python语句,通过百度地图API,对已知的地名抓取经纬度 使用百度地图API官网的html例程,修改数据部分,实现呈现效果 一.使用python语句,通过百度地图API,获取经纬度读取文件信息 import pandas as pd data = pd.read_excel('test_baidu.xlsx') data 图中可以看出,原始数据并没有经纬度. 2. 构建抓取经纬度函数 import json from urllib.request i
-
Python调用百度api实现语音识别详解
最近在学习python,做一些python练习题 github上几年前的练习题 有一题是这样的: 使用 Python 实现:对着电脑吼一声,自动打开浏览器中的默认网站. 例如,对着笔记本电脑吼一声"百度",浏览器自动打开百度首页. 然后开始search相应的功能需要的模块(windows10),理一下思路: 本地录音 上传录音,获得返回结果 组一个map,根据结果打开相应的网页 所需模块: PyAudio:录音接口 wave:打开录音文件并设置音频参数 requests:GET/POS
-
Python调用百度AI实现人像分割详解
目录 一.原始视频截图 二.提取人像 三.和背景图合并 四.合成视频 一.原始视频截图 import cv2 cap=cv2.VideoCapture(r"[小仙若]shake it !冬日也要活力满满! (P1. shake it).mp4") ret,frame=cap.read() i =0 timeF=3 j=0 num=0 while 1: i=i+1 if (i%timeF==0): j=j+1 cv2.imwrite("./pictures/"+str
-
python通过百度地图API获取某地址的经纬度详解
前言 这几天比较空闲,就接触了下百度地图的API(开发者中心链接地址:http://developer.baidu.com),发现调用还是挺方便的,本文将给大家详细的介绍关于python通过百度地图API获取某地址的经纬度的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 申请百度API 1.打开网页 http://lbsyun.baidu.com/index.php?title=首页 选择功能与服务中的地图,点击左边的获取密匙,然后按照要求申请即可,需要手机和百度账号
-
详解vue项目中调用百度地图API使用方法
步骤一:申请百度地图密钥: JavaScript API v1.4以及以前的版本无序申请秘钥(ak),自v1.5版本开始需要先申请秘钥(ak),才可以使用,如需获取更高的配额,需要申请 认证企业用户.百度地图API 链接地址:http://lbsyun.baidu.com/apiconsole/key 步骤二:在index.html中添加百度地图JavaScript API接口: <script src="http://api.map.baidu.com/api?v=1.4"
-
详解用Python爬虫获取百度企业信用中企业基本信息
一.背景 希望根据企业名称查询其经纬度,所在的省份.城市等信息.直接将企业名称传给百度地图提供的API,得到的经纬度是非常不准确的,因此希望获取企业完整的地理位置,这样传给API后结果会更加准确. 百度企业信用提供了企业基本信息查询的功能.希望通过Python爬虫获取企业基本信息.目前已基本实现了这一需求. 本文最后会提供具体的代码.代码仅供学习参考,希望不要恶意爬取数据! 二.分析 以苏宁为例.输入"江苏苏宁"后,查询结果如下: 经过分析,这里列示的企业信息是用JavaScript动
-
详解基于python的全局与局部序列比对的实现(DNA)
程序能实现什么 a.完成gap值的自定义输入以及两条需比对序列的输入 b.完成得分矩阵的计算及输出 c.输出序列比对结果 d.使用matplotlib对得分矩阵路径的绘制 一.实现步骤 1.用户输入步骤 a.输入自定义的gap值 b.输入需要比对的碱基序列1(A,T,C,G)换行表示输入完成 b.输入需要比对的碱基序列2(A,T,C,G)换行表示输入完成 输入(示例): 2.代码实现步骤 1.获取到用户输入的gap,s以及t 2.调用构建得分矩阵函数,得到得分矩阵以及方向矩阵 3.将得到的得分矩
-
详解基于python的图像Gabor变换及特征提取
1.前言 在深度学习出来之前,图像识别领域北有"Gabor帮主",南有"SIFT慕容小哥".目前,深度学习技术可以利用CNN网络和大数据样本搞事情,从而取替"Gabor帮主"和"SIFT慕容小哥"的江湖地位.但,在没有大数据和算力支撑的"乡村小镇"地带,或是对付"刁民小辈","Gabor帮主"可以大显身手,具有不可撼动的地位.IT武林中,有基于C++和OpenCV,或