详解springboot+atomikos+druid 数据库连接失效分析
目录
- 一、起因
- 二、Druid数据库连接池
- 三、Atomikos框架
- 四、分析与总结
一、起因
最近查看系统的后台日志,经常发现这样的报错信息:The last package successfully received from the server was 40802382 milliseconds ago,截图如下所示。


由于我们的系统都是在白天使用,夜里基本上没有用户使用,再加上以上的报错信息都是出现在早晨,结合错误日志初步分析,应该是数据库连接超时自动断开了。百度一番后,得知Mysql的默认连接时间是8小时,超过8小时没有操作后就会自动断开连接,但是已经使用了druid数据库连接池,按理说已经对数据库连接做了保护和检查,不应该出现这样的问题。要想彻底弄明白这个问题,就只能去研究druid数据库连接池框架了。
二、Druid数据库连接池
项目的数据库连接池基本配置信息如下所示

通过以上的配置分析得知,一个数据库连接从连接池中借出后经过21600s即6小时后会被强制回收,不会超过Mysql的默认8小时,而且也不存在这么长时间的事务,所以不太可能是因为数据库连接借出超时导致上面的错误,那么就是从数据库连接池中申请的连接已经超时了?似乎也不太可能,因为有检查机制,即每隔30s就会检查一次连接池中的连接是否超时,并且连接池中允许存在的空闲连接最大时间为540s。这就奇怪了,到底是什么原因导致上面的错误呢?这时注意到上述错误堆栈中的com.atomikos.datasource.pool.ConnectionPool.findOrWaitForAnAvailableConnection。是否问题的原因在于使用了Atomikos呢,带着这样的疑惑去阅读了Druid和Atomikos相关的源码。
由于Atomikos连接池是基于Druid连接池之上的,所以Atomikos新建和销毁数据库连接都是从Druid连接池中借出和归还数据库连接,而不是直接与数据库交互,那么我们就来看看Druid是如何维持数据库连接的。
public DruidPooledConnection getConnection(long maxWaitMillis) throws SQLException {
//初始化检查配置和后台线程
init();
if (filters.size() > 0) {
FilterChainImpl filterChain = new FilterChainImpl(this);
return filterChain.dataSource_connect(this, maxWaitMillis);
} else {
return getConnectionDirect(maxWaitMillis);
}
}
从Druid连接池中获取数据库连接,先调用init()方法进行初始化工作,然后调用getConnectionDirect()获取连接。
decrementPoolingCount(); DruidConnectionHolder last = connections[poolingCount]; connections[poolingCount] = null;
DruidPooledConnection poolalbeConnection = new DruidPooledConnection(holder);
public DruidPooledConnection(DruidConnectionHolder holder){
super(holder.getConnection());
this.conn = holder.getConnection();
this.holder = holder;
this.lock = holder.lock;
dupCloseLogEnable = holder.getDataSource().isDupCloseLogEnable();
ownerThread = Thread.currentThread();
connectedTimeMillis = System.currentTimeMillis();
}
上述是获取连接池中连接的关键代码,即获取connections数组中的最后一个元素,获取到Holder后还需要将其封装为DruidPooledConnection,这时该连接的connectedTimeMillis会被赋值为当前时间,这个时间在后续的分析中会非常重要。
因为配置了testWhileIdle为true,所以需要进行下面的有效性检查,获取该连接的上次活跃时间,得到空闲时间,如果超过30s则做有效性检查。
long idleMillis = currentTimeMillis - lastActiveTimeMillis;
long timeBetweenEvictionRunsMillis = this.timeBetweenEvictionRunsMillis;
if (timeBetweenEvictionRunsMillis <= 0) {
timeBetweenEvictionRunsMillis = DEFAULT_TIME_BETWEEN_EVICTION_RUNS_MILLIS;
}
if (idleMillis >= timeBetweenEvictionRunsMillis
|| idleMillis < 0 // unexcepted branch
) {
boolean validate = testConnectionInternal(poolableConnection.holder, poolableConnection.conn);
if (!validate) {
if (LOG.isDebugEnabled()) {
LOG.debug("skip not validate connection.");
}
discardConnection(poolableConnection.holder);
continue;
}
}
long timeMillis = (currrentNanos - pooledConnection.getConnectedTimeNano()) / (1000 * 1000);
if (timeMillis >= removeAbandonedTimeoutMillis) {
iter.remove();
pooledConnection.setTraceEnable(false);
abandonedList.add(pooledConnection);
}
同时,由于配置了removeAbandoned为true,所以需要检查活跃连接是否超时,如果超时就断开物理连接。下面看一下连接池的回收方法recycle的关键代码
if (phyTimeoutMillis > 0) {
long phyConnectTimeMillis = currentTimeMillis - holder.connectTimeMillis;
if (phyConnectTimeMillis > phyTimeoutMillis) {
discardConnection(holder);
return;
}
}
lock.lock();
try {
if (holder.active) {
activeCount--;
holder.active = false;
}
closeCount++;
result = putLast(holder, currentTimeMillis);
recycleCount++;
} finally {
lock.unlock();
}
在对数据库连接进行回收时,如果连接时间超过了数据库的物理连接时间(默认8小时)则需要断开物理连接,否则就调用putLast方法将该连接回收到连接池。
boolean putLast(DruidConnectionHolder e, long lastActiveTimeMillis) {
if (poolingCount >= maxActive || e.discard) {
return false;
}
e.lastActiveTimeMillis = lastActiveTimeMillis;
connections[poolingCount] = e;
incrementPoolingCount();
if (poolingCount > poolingPeak) {
poolingPeak = poolingCount;
poolingPeakTime = lastActiveTimeMillis;
}
notEmpty.signal();
notEmptySignalCount++;
return true;
}
注意上述标红的地方,回收的这个连接的lastActiveTimeMillis被刷新为当前时间,这个时间也是非常重要的,在后续分析中会用到。
三、Atomikos框架
项目关于Atomikos的配置信息,如下所示
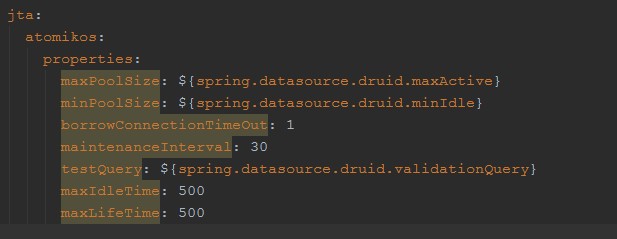
从上面的配置可以看出,atomikos连接池的最大连接数是25个,最小连接数是10个,连接最大的存活时间是500s,下面来看一下atomikos的源码。
private void init() throws ConnectionPoolException
{
if ( LOGGER.isTraceEnabled() ) LOGGER.logTrace ( this + ": initializing..." ); //如果连接池最小连接数没有达到就新增数据库连接
addConnectionsIfMinPoolSizeNotReached(); //开启维持连接池平衡的线程
launchMaintenanceTimer();
}
以上是Atomikos初始化的部分,先补充数据库连接池达到最小连接数,然后开启后台线程维持连接池的平衡。
private void launchMaintenanceTimer() {
int maintenanceInterval = properties.getMaintenanceInterval();
if ( maintenanceInterval <= 0 ) {
if ( LOGGER.isTraceEnabled() ) LOGGER.logTrace ( this + ": using default maintenance interval..." );
maintenanceInterval = DEFAULT_MAINTENANCE_INTERVAL;
}
maintenanceTimer = new PooledAlarmTimer ( maintenanceInterval * 1000 );
maintenanceTimer.addAlarmTimerListener(new AlarmTimerListener() {
public void alarm(AlarmTimer timer) {
reapPool(); //如果达到了最大的存活时间就移除该连接
removeConnectionsThatExceededMaxLifetime(); //如果没有满足最小连接数就新增连接
addConnectionsIfMinPoolSizeNotReached(); //移除超过最小连接数以外的连接
removeIdleConnectionsIfMinPoolSizeExceeded();
}
});
TaskManager.SINGLETON.executeTask ( maintenanceTimer );
}
在配置中,maintenanceInterval的值为30,即每个30秒执行一次上述的四个方法,主要看一下removeConnectionsThatExceededMaxLifetime()这个方法。
private synchronized void removeConnectionsThatExceededMaxLifetime()
{
long maxLifetime = properties.getMaxLifetime();
if ( connections == null || maxLifetime <= 0 ) return;
if ( LOGGER.isTraceEnabled() ) LOGGER.logTrace ( this + ": closing connections that exceeded maxLifetime" );
Iterator<XPooledConnection> it = connections.iterator();
while ( it.hasNext() ) {
XPooledConnection xpc = it.next();
long creationTime = xpc.getCreationTime();
long now = System.currentTimeMillis();
if ( xpc.isAvailable() && ( (now - creationTime) >= (maxLifetime * 1000L) ) ) {
if ( LOGGER.isTraceEnabled() ) LOGGER.logTrace ( this + ": connection in use for more than " + maxLifetime + "s, destroying it: " + xpc ); //如果超过最大的存活时间就销毁该连接
destroyPooledConnection(xpc);
it.remove();
}
}
logCurrentPoolSize();
}
上述方法遍历数据库连接池中的所有连接,如果存活时间超过maxLifetime即500s就销毁该连接,这时由于连接池中的连接数就小于minPoolSize,所以会立即补充新的连接到连接池中。那么,系统在夜间没有用户使用时,Atomikos连接池的运行状态为:维持最小的连接数10个数据库连接,当这10个连接超过500s时就会销毁,再重新创建10个新的数据库连接,不断重复这样的操作。
四、分析与总结
下面我们开始分析产生错误日志的原因,当没有用户使用系统时,Druid连接池应该有10个空闲的连接,Atomikos连接池也有10个空闲的连接,这时Atomikos的10个连接达到了最大的生存时间500s,就需要销毁这些连接,对于Druid来说就是回收连接,调用recycle方法。由于这10个连接应该是500s之前从Druid连接池借出的,所以它们的connectTimeMillis也是500s之前的时间,即物理连接时间肯定小于8小时,可以成功回收到Druid连接池中,同时lastActiveTimeMillis也更新为当前时间,放在connections数组的末尾。
与此同时,Atomikos还需要重新生成10个新的连接,即从Druid连接池获取10个连接,调用getConnection方法,这时会进行有效性的检查,又因为lastActiveTimeMillis基本上为当前时间,所以idleMillis肯定比30s小,不需要进行select 1的连接数据库操作,这样即使该连接已经失效了还是会借出给Atomikos。每隔500s不断循环上述操作,并且期间没有用户的操作,一旦超过8个小时的Mysql连接时间,Atomikos在使用数据库连接时就会产生上述日志中的错误了。

综上所述,导致报错的原因其实是使用了两层数据库连接池,这样Druid连接池借出的数据库连接并没有被实际使用,这才导致这些数据库连接成功躲避了Druid本身的检查机制。
到此这篇关于springboot+atomikos+druid 数据库连接失效分析的文章就介绍到这了,更多相关springboot+atomikos+druid 数据库连接失效分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

如何在SpringBoot 中使用 Druid 数据库连接池
Druid是阿里开源的一款数据库连接池,除了常规的连接池功能外,它还提供了强大的监控和扩展功能.这对没有做数据库监控的小项目有很大的吸引力. 下列步骤可以让你无脑式的在SpringBoot2.x中使用Druid. 1.Maven中的pom文件 <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.14</ve
-
springboot 整合druid数据库密码加密功能的实现代码
在之前给大家介绍过Springboot Druid 自定义加密数据库密码的几种方案,感兴趣的朋友可以点击查看下,今天通过本文给大家介绍springboot 整合druid数据库密码加密功能,具体内容如下所示: 1.依赖引入 <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1
-
SpringBoot开发案例之配置Druid数据库连接池的示例
前言 好久没有更新Spring Boot系列文章,你说忙么?也可能是,前段时间的关注点也许在其他方面了,最近项目中需要开发小程序,正好采用Spring Boot实现一个后端服务,后面会把相关的代码案例分享出来,不至于大家做小程序后端服务的时候一头雾水. 在Spring Boot下默认提供了若干种可用的连接池(dbcp,dbcp2, tomcat, hikari),当然并不支持Druid,Druid来自于阿里系的一个开源连接池,它提供了非常优秀的监控功能,下面跟大家分享一下如何与Spring Bo
-
Springboot2 集成 druid 加密数据库密码的配置方法
一:环境 springboot 2.x druid 1.1.21 二:druid加密数据库密码 本地下载druid-1.1.21.jar包,运行cmd,输入命令 java -cp jar包路径 com.alibaba.druid.filter.config.ConfigTools 数据库密码 java -cp druid-1.1.21.jar com.alibaba.druid.filter.config.ConfigTools 数据库密码 运行成功输出 privateKey:MIIBVAIBA
-
springboot项目整合druid数据库连接池的实现
Druid连接池是阿里巴巴开源的数据库连接池项目,后来贡献给Apache开源: Druid的作用是负责分配.管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个: Druid连接池内置强大的监控功能,其中的StatFilter功能,能采集非常完备的连接池执行信息,方便进行监控,而监控特性不影响性能. Druid连接池内置了一个监控页面,提供了非常完备的监控信息,可以快速诊断系统的瓶颈. SpringBoot 1.x版本默认使用的的tomcat的jdbc连接池,由
-
Springboot Druid 自定义加密数据库密码的几种方案
前言 开发过程中,配置的数据库密码通常是明文形式,这样首先第一个安全性不好(相对来说),不符合一个开发规范(如项目中不能出现明文账号密码),其实就是当出现特殊需求时,比如要对非运维人员开方服务器部分权限,但是又涉及项目部署的目录时,容易泄漏数据库密码,虽然一般生产环境中,数据库往往放入内网,访问只能通过内网访问,但是不管怎么说账号密码直接让人知道总归不好,甚至有些项目需要部署到客户环境中,但是可能共用一个公共数据库(数据库只向指定服务器开放外网端口或组建内网环境),这样的情况下,如果数据库密码再
-
SpringBoot整合Druid数据库连接池的方法
一,Druid是什么? Druid是Java语言中最好的数据库连接池.Druid能够提供强大的监控和扩展功能. 二, 在哪里下载druid maven中央仓库: http://central.maven.org/maven2/com/alibaba/druid/ 三, 怎么获取Druid的源码 Druid是一个开源项目,源码托管在github上,源代码仓库地址是 https://github.com/alibaba/druid.同时每次Druid发布正式版本和快照的时候,都会把源码打包,你可以从
-
springboot 中 druid+jpa+MYSQL数据库配置过程
Druid来自于阿里的一个开源连接池能够提供强大的监控和扩展功能,Spring Boot默认不支持Druid和jpa,需要引入依赖. 1.引入依赖包 <!--druid--> <!-- https://mvnrepository.com/artifact/com.alibaba/druid --> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</art
-
详解springboot+atomikos+druid 数据库连接失效分析
目录 一.起因 二.Druid数据库连接池 三.Atomikos框架 四.分析与总结 一.起因 最近查看系统的后台日志,经常发现这样的报错信息:The last package successfully received from the server was 40802382 milliseconds ago,截图如下所示. 由于我们的系统都是在白天使用,夜里基本上没有用户使用,再加上以上的报错信息都是出现在早晨,结合错误日志初步分析,应该是数据库连接超时自动断开了.百度一番后,得知Mysql
-
详解springboot 使用c3p0数据库连接池的方法
使用springboot开发时,默认使用内置的tomcat数据库连接池,经常碰到这种情况:运行时间一长,数据库连接中断了.所以使用c3p0连接池吧. 引入的maven依赖: <dependency> <groupId>c3p0</groupId> <artifactId>c3p0</artifactId> <version>0.9.1.2</version> </dependency> c3p0的配置信息,写到
-
详解SpringBoot简化配置分析总结
在SpringBoot启动类中,该主类被@SpringBootApplication所修饰,跟踪该注解类,除元注解外,该注解类被如下自定注解修饰. @SpringBootConfiguration @EnableAutoConfiguration @ComponentScan 让我们简单叙述下它们各自的功能: @ComponentScan:扫描需要被IoC容器管理下需要管理的Bean,默认当前根目录下的 @EnableAutoConfiguration:装载所有第三方的Bean @SpringB
-
详解springboot+mybatis-plue实现内置的CRUD使用详情
mybatis-plus的特性 无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑 损耗小:启动即会自动注入基本CURD,性能基本无损耗,直接面向对象操作 强大的 CRUD操作:内置通用 Mapper.通用Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求 支持 Lambda形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错 支持主键自动生成:支持多达 4种主键策略(内含分布式唯一 ID 生成器
-
详解SpringBoot如何使用Redis和Redis缓存
目录 一.配置环境 二.Redis的基本操作 三.使用redis作缓存 一.配置环境 首先,先创建一个SpringBoot项目,并且导入Redis依赖,使用Jedis进行连接测试. 本人的Redis装在虚拟机里,直接切换到虚拟机中的安装目录,启动redis服务,打开redis-cli,如果你设置了密码,还要先输入密码. cd redis安装目录 #启动redis redis-server /etc/redis.conf #进入redis redis-cli #如果你设置了密码 auth 密码 在
-
详解springboot整合ehcache实现缓存机制
EhCache 是一个纯Java的进程内缓存框架,具有快速.精干等特点,是Hibernate中默认的CacheProvider. ehcache提供了多种缓存策略,主要分为内存和磁盘两级,所以无需担心容量问题. spring-boot是一个快速的集成框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置. 由于spring-boot无需任何样板化的配置文件,所以spring-boot集成一些其他框架时会有略微的
-
详解SpringBoot中的tomcat优化和修改
项目背景 在做项目的时候,把SpringBoot的项目打包成安装包了,在客户上面安装运行,一切都是那么的完美,可是发生了意外,对方突然说导出导入的文件都不行了.我急急忙忙的查看日志,发现报了一个错误 java.io.IOException: The temporary upload location [C:\Windows\Temp\tomcat.1351070438015228346.8884\work\Tomcat\localhost\ROOT] is not valid at org.ap
-
详解SpringBoot中添加@ResponseBody注解会发生什么
SpringBoot版本2.2.4.RELEASE. [1]SpringBoot接收到请求 ① springboot接收到一个请求返回json格式的列表,方法参数为JSONObject 格式,使用了注解@RequestBody 为什么这里要说明返回格式.方法参数.参数注解?因为方法参数与参数注解会影响你使用不同的参数解析器与后置处理器!通常使用WebDataBinder进行参数数据绑定结果也不同. 将要调用的目标方法如下: @ApiOperation(value="分页查询") @Re
-
详解SpringBoot基于Dubbo和Seata的分布式事务解决方案
1. 分布式事务初探 一般来说,目前市面上的数据库都支持本地事务,也就是在你的应用程序中,在一个数据库连接下的操作,可以很容易的实现事务的操作. 但是目前,基于SOA的思想,大部分项目都采用微服务架构后,就会出现了跨服务间的事务需求,这就称为分布式事务. 本文假设你已经了解了事务的运行机制,如果你不了解事务,那么我建议先去看下事务相关的文章,再来阅读本文. 1.1 什么是分布式事务 对于传统的单体应用而言,实现本地事务可以依赖Spring的@Transactional注解标识方法,实现事务非常简
-
详解SpringBoot启动类的扫描注解的用法及冲突原则
背景 SpringBoot 启动类上,配置扫描包路径有三种方式,最近看到一个应用上三种注解都用上了,代码如下: @SpringBootApplication(scanBasePackages ={"a","b"}) @ComponentScan(basePackages = {"a","b","c"}) @MapperScan({"XXX"}) public class XXApplic