浅谈Python如何获取excel数据
目录
- 一、列操作
- 二、行操作
- 总结
准备导入的excel为:
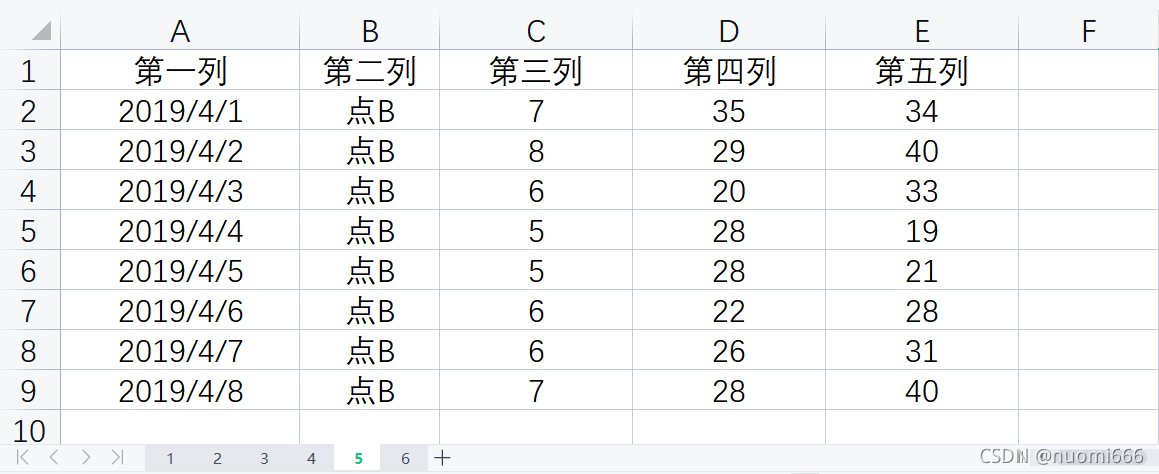
可以采用pandas的read_excel功能,具体代码如下:
import pandas as pd
getdata=pd.read_excel(r'C:/文件夹索引/文件名.xlsx',
sheet_name='工作表sheet的名字')
sheet_name不设置参数,就默认第一个工作表,同时也可设置工作表的位置,读取第5个工作表可以设置为=4。
一、列操作
如果对获取工作表其中的某列或者多列,可以使用usecols参数,比如读取第5个工作表的第2列到第5列,可以用下面的代码:
import pandas as pd
getdata=pd.read_excel(r'C:/文件夹索引/文件名.xlsx',
sheet_name='工作表sheet的名字',
sheet_name=4,
usecols=[i for i in range (1,6)])
usecols参数也可以设置成列的索引字母,比如usecols="B,D:E",可以获取第1和3到5列,同时设置参数index_col=1,把第二列当作索引,代码及输出结果为:
getdata=pd.read_excel(r'C:/文件夹索引/文件名.xlsx',
sheet_name='工作表sheet的名字',
sheet_name=4,
usecols="A,C:E",
index_col=1)
print(Getdata)
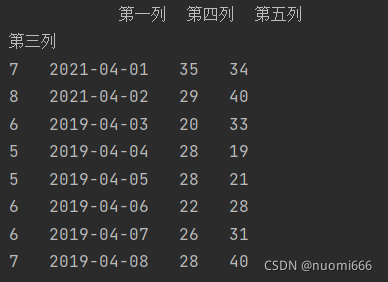
二、行操作
如果不想获取全部行数,如获取前5行可以设置参数nrows=5,同时跳过第2行到第4行,可以设置参数skiprows=[i for i in range(2,5)],或者skiprows=[2,3,4],代码及输出结果:
getdata=pd.read_excel(r'C:/文件夹索引/文件名.xlsx',
sheet_name='工作表sheet的名字',
skiprows=[2,3,4],
nrows=5)
print(Getdata)
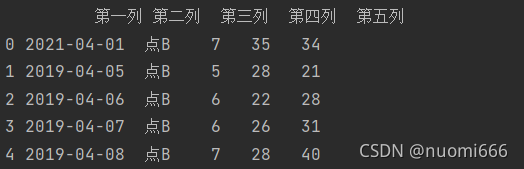
这里应当注意,设置的nrows是总共要获取多少行,如果设置skiprows跳过一定数量行后,将在之后行里继续获取,直到补足nrows所要获取的行数。
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

python pandas模糊匹配 读取Excel后 获取指定指标的操作
1.首先读取Excel文件 数据代表了各个城市店铺的装修和配置费用,要统计出装修和配置项的总费用并进行加和计算: 2.pandas实现过程 import pandas as pd #1.读取数据 df = pd.read_excel(r'./data/pfee.xlsx') print(df) cols = list(df.columns) print(cols) #2.获取含有装修 和 配置 字段的数据 zx_lists=[] pz_lists=[] for name in cols: if
-
Python爬虫获取豆瓣电影并写入excel
豆瓣电影排行榜前250 分为10页,第一页的url为https://movie.douban.com/top250,但实际上应该是https://movie.douban.com/top250?start=0 后面的参数0表示从第几个开始,如0表示从第一(肖申克的救赎)到第二十五(触不可及),https://movie.douban.com/top250?start=25表示从第二十六(蝙蝠侠:黑暗骑士)到第五十名(死亡诗社).等等, 所以可以用一个步长为25的range的for循环参数 复制代
-
Python获取excel内容及相关操作代码实例
Python没有自带openyxl,需要安装: pip install openyxl 打开excel文档: openyxl.load_workbook(excel地址) - 打开现有excel文件 openyxl.Workbook() - 新建一个excel文件 返回一个工作博对象 import openpyxl wb = openpyxl.load_workbook("test.xlsx") print(type(wb)) # <class 'openpyxl.workboo
-
如何基于python操作excel并获取内容
这篇文章主要介绍了如何基于python操作excel并获取内容,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 背景:从excel表中获取请求url.请求数据.请求类型.预期结果 因此,需要学会如何使用python从excel获取这些信息 #coding=utf-8 import xlrd #创建对象时,获取对应excel 表格 #读取Excel行数 #获取单元格内容 class OperationExcel: def __init__(self
-
Python获取数据库数据并保存在excel表格中的方法
将数据库中的数据保存在excel文件中有很多种方法,这里主要介绍pyExcelerator的使用. 一.前期准备(不详细介绍MySQL) python包pyExcelerator和MySQLdb 导入方法:(以Pycharm为例) 在File->Settings中点击右上角绿色图标"+", 输入pyExcelerator,点击install package,导入成功之后点击OK,就完成了pyExcelerator的导入. 2.使用pyExcelerator对excel进行操作 #
-
浅谈Python如何获取excel数据
目录 一.列操作 二.行操作 总结 准备导入的excel为: 可以采用pandas的read_excel功能,具体代码如下: import pandas as pd getdata=pd.read_excel(r'C:/文件夹索引/文件名.xlsx', sheet_name='工作表sheet的名字') sheet_name不设置参数,就默认第一个工作表,同时也可设置工作表的位置,读取第5个工作表可以设置为=4. 一.列操作 如果对获取工作表其中的某列或者多列,可以使用usecols参数,比如读
-
浅谈Python数学建模之数据导入
目录 一.数据导入是所有数模编程的第一步 二.在程序中直接向变量赋值 2.1.为什么直接赋值? 2.2.直接赋值的问题与注意事项 三.Pandas 导入数据 3.1.Pandas 读取 Excel 文件 3.2.Pandas 读取 csv 文件 3.3.Pandas 读取文本文件 3.4.Pandas 读取其它文件格式 四.数据导入例程 一.数据导入是所有数模编程的第一步 编程求解一个数模问题,问题总会涉及一些数据. 有些数据是在题目的文字描述中给出的,有些数据是通过题目的附件文件下载或指定网址
-
浅谈Python xlwings 读取Excel文件的正确姿势
使用Python加载最新的Excel读取类库xlwings可以说是Excel数据处理的利器,但使用起来还是有一些注意事项,否则高大上的Python会跑的比老旧的VBA还要慢. 这里我们对比一下,用几种不同的方法,从一个Excel表格中读取一万行数据,然后计算结果,看看他们的耗时. 1. 处理要求: 一个Excel表格中包含了3万条记录,其中B,C两个列记录了某些计算值,读取前一万行记录,将这两个列的差值进行计算,然后汇总得出差的和. 文件是这个样子:Book300s.xlsx . 2. 处理方式
-
浅谈Python爬虫原理与数据抓取
通用爬虫和聚焦爬虫 根据使用场景,网络爬虫可分为通用爬虫和聚焦爬虫两种. 通用爬虫 通用网络爬虫 是 捜索引擎抓取系统(Baidu.Google.Yahoo等)的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 通用搜索引擎(Search Engine)工作原理 通用网络爬虫从互联网中搜集网页,采集信息,这些网页信息用于为搜索引擎建立索引从而提供支持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果. 第一步:抓取网页
-
浅谈python对象数据的读写权限
面向对象的编程语言在写大型程序的的时候,往往比面向过程的语言用起来更方便,安全.其中原因之一在于:类机制. 类,对众多的数据进行分类,封装,让一个数据对象成为一个完整的个体,贴近现实生活,高度抽象化.但是,python对类的封装并不好,因为所有的属性和方法都是公开的,你可以随意访问或者写入,你可以在类的外部对类的属性进行修改,甚至添加属性.这的确让人感到不安. 下面就来总结一下学习后的解决方案. 1,使用2个下划线前缀隐藏属性或者方法. __xxx #!/usr/bin/python3 #-*-
-
浅谈python 读excel数值为浮点型的问题
如下所示: #读入no data = xlrd.open_workbook("no.xlsx") #打开excel table = data.sheet_by_name("Sheet1") #读sheet nrows = table.nrows cols = table.ncols nos = [] for i in range(1,nrows): #指定从1开始,到最后一列,跳过表头 for j in range(cols): ctype = table.cell
-
浅谈Python中的异常和JSON读写数据的实现
异常可以防止出现一些不友好的信息返回给用户,有助于提升程序的可用性,在java中通过try ... catch ... finally来处理异常,在Python中通过try ... except ... else来处理异常 一.以ZeroDivisionError为例,处理分母为0的除法异常 def division(numerator,denominator): result=numerator/denominator return result ret1=division(1,5) prin
-
浅谈python中常用的excel模块库
openpyxl openpyxl是⼀个Python库,用于读取/写⼊Excel 2010 xlsx / xlsm / xltx / xltm⽂件. 它的诞⽣是因为缺少可从Python本地读取/写⼊Office Open XML格式的库. 如何安装: 使用pip安装openpyxl $ pip install openpyxl 使用效果之⼀: 比如可以直接读取表格数据后综合输出写⼊到后⾯的⼀列中 xlwings xlwings是BSD许可的Python库,可轻松从Excel调用Python,同样
-
浅谈laravel-admin form中的数据,在提交后,保存前,获取并进行编辑
有一个这样的需求: 当商品设置为立即上架时,通过审核就进入上架状态,当设置为保存时,通过审核就进入未上架状态. 所以,需要在保存前根据提交的审核状态和设置的方式得到商品状态再保存,而通过$form->model()->attribute_name只能获取提交后的值,不能更改. Google之后发现了已经有解决方案:可以修改提交表单时的逻辑吗 #375 在模型中添加如下方法: public static function boot() { parent::boot(); static::savi
-
浅谈python已知元素,获取元素索引(numpy,pandas)
目前搜索到的方法有: np.where('元素') 还有就是pandas的方法: df.index('元素') 但是第二个方法的问题就是会报错,嗯,这就比较尴尬了,查询了网上的解决方案,有这样的: 此外使用 df[df['列名'].isin([相应的值])] 这个命令会输出等于该值的行. 此外如果想快速找到dataframe最后几行的话,可以使用的方法是tail,可以获取若干行的值 以上这篇浅谈python已知元素,获取元素索引(numpy,pandas)就是小编分享给大家的全部内容了,希望能给