轻松入门正则表达式之非贪婪匹配篇详解
非贪婪匹配 (.*?)
import re
a = '456qwe789rty123abc'
re=re.findall('456(.*?)789',a)
print(re)
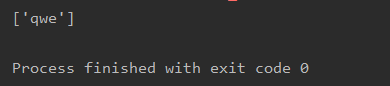
通常情况,满足匹配规则“456(.*?)789”的内容通常不止一个,那么findall()函数会从字符串的起始位置开始寻找文本A,找到后开始寻找文本B,当找到第一个文本B后,暂时停止寻找,将文本A和文本B之间的内容存入列表;然后继续寻找文本A,并重复之前的步骤,直到到达字符串的结束位置,并将所有匹配到的内容存入列表。
import re
a = '456qwe789rty123456kkk789abc456xiaowang789'
re=re.findall('456(.*?)789',a)
print(re)

贪婪模式的话就会寻找最长的
import re
a = '456qwe789rty123456kkk789abc456xiaowang789'
re=re.findall('456(.*)789',a)
print(re)

非贪婪匹配 .*?
import re
a='<a href="https://blog.csdn.net/weixin_42403632/article/details/120825546" rel="external nofollow" target="_blank" data-report-click="{"spm":"3001.5501"}" data-report-query="spm=3001.5501" data-v-6fe2b6a7="">'
re=re.findall('<a href="(.*?)" rel="external nofollow" rel="external nofollow" .*?',a)
print(re)

" 和 url后面的html代码用.*?代表,需要提取的是<a href="后的内容,用“(.*?)”代表
实战爬取博客专栏url
import re,requests
url='https://blog.csdn.net/weixin_42403632/category_11076268.html'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
html=requests.get(url,headers=headers).text
re=re.findall('<a href="(.*?)" rel="external nofollow" rel="external nofollow" .*?rel="noopener">',html)
for i in re:
print(i)

到此这篇关于轻松入门正则表达式之非贪婪匹配篇详解的文章就介绍到这了,更多相关正则表达式 非贪婪匹配内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

十分钟上手正则表达式 下篇
目录 一.正则表达式常用符号 1.1 问号[?] 1.2 加号[+] 1.3 花括号{} 1.4 管道符号[|] 1.5 小括号() 二.正则表达式实战示例 示例1: 示例2: 前面,我们就正则表达式一些常用的基本方法做了详细的介绍,本篇会讲解一些拓展性的知识,主要的就是常见的ERE模式符号以及shell脚本中常见的一些正则表达式例子. 快速学习正则表达式,不用死记硬背,示例让你通透(上篇) 一.正则表达式常用符号 本章示例着重于在gawk程序脚本中的较常见的ERE模式符号. 1.1 问号[?]
-
正则表达式常见的4种匹配模式小结
目录 0.写在前面 1.不区分大小写模式 2.点号通配模式 3.多行匹配模式 4.注释模式 5.写在最后 0.写在前面 今天一起来学习下正则中的匹配模式,所谓的匹配模式,就是指正则中的一些 改变元字符匹配行为 的方式,比如匹配时不区分英文字母的大小写. 还记得我们在第二篇文章中学过的贪婪模式.非贪婪模式和独占模式吗,这些模式会改变正则中量词的匹配行为,今天来看一些和量词无关的匹配模式,一共有4种,分别是不区分大小写模式.点号通配模式.多行匹配模式.注释模式. 1.不区分大小写模式 顾名思义,不区
-
深入浅出正则表达式中的边界\b和\B
目录 边界 单词 \b 单词边界 \B 非单词边界 举列 总结 正则表达式中: \b 表示单词边界 \B 表示非单词边界,应理解为(非单词)边界,而不是非(单词边界),它仍然匹配的是边界 边界 我将正则中的位置分为 字符的占位 和 字符的间隙. 字符的占位是显式的位置. 以 I'm iron man 为例. 肉眼可见的字母 符号 空格都是可以占位的字符,也就是可以用下标获取到字符的位置. 字符的间隙是隐式的位置. 即显示位置之间的位置,比如I和'之间的位置,字符串开头和I之间的位置等. 边界 指
-
十分钟上手正则表达式 上篇
目录 一.正则表达式的定义: 二.正则表达式的类型 三.定义 BRE 模式 3.1 纯文本 3.2 特殊字符 3.3 锚字符 3.3.1 锁定在行首 3.3.2 锁定在行尾 3.3.3 组合锚点 3.4 点号字符 3.5 字符组 3.6 排除型字符组 3.7 区间 3.8 特殊的字符组 3.9 星号[*] 一.正则表达式的定义: 正则表达式是你所定义的 模式模板 ( pattern template ), Linux 工具可以用它来过滤文本. Linux工具(比如sed 编辑器或 gawk 程序
-
Python正则表达式保姆式教学详细教程
目录 一.re模块 1.导入re模块 2.findall()的语法: 二.正则表达式 1.普通字符 2.元字符 (二)正则的使用 1.编译正则 2.正则对象的使用方法 3.Match object 的操作方法 4.re模块的函数 正则作为处理字符串的一个实用工具,在Python中经常会用到,比如爬虫爬取数据时常用正则来检索字符串等等.正则表达式已经内嵌在Python中,通过导入re模块就可以使用,作为刚学Python的新手大多数都听说"正则"这个术语. 今天来给大家分享一份关于比较详细
-
轻松入门正则表达式之非贪婪匹配篇详解
非贪婪匹配 (.*?) import re a = '456qwe789rty123abc' re=re.findall('456(.*?)789',a) print(re) 通常情况,满足匹配规则"456(.*?)789"的内容通常不止一个,那么findall()函数会从字符串的起始位置开始寻找文本A,找到后开始寻找文本B,当找到第一个文本B后,暂时停止寻找,将文本A和文本B之间的内容存入列表:然后继续寻找文本A,并重复之前的步骤,直到到达字符串的结束位置,并将所有匹配到的内容存入列
-
正则表达式量词与贪婪的使用详解
目录 0.写在前面 1.量词 2.贪婪模式前传 2.1 使用 a+ 进行匹配 2.2 使用 a* 进行匹配 3.贪婪模式 4.非贪婪模式 5.独占模式 5.1 贪婪匹配过程 5.2 非贪婪匹配过程 5.3 独占匹配过程 6.写在最后 0.写在前面 在上一篇文章中,我们学习了正则的一些基础元字符,相信大家都已经忘却的差不多了,可以点击上面的链接再温习下. 今天我们一起来学习下正则中量词的三种匹配模式,贪婪模式.非贪婪模式.独占模式,这些模式会改变正则中量词的匹配行为,是每次贪婪的匹配到更多呢,还是
-
JavaScript正则表达式的贪婪匹配和非贪婪匹配
所谓贪婪匹配就是匹配重复字符是尽可能多的匹配,比如: "aaaaa".match(/a+/); //["aaaaa", index: 0, input: "aaaaa"] 非贪婪匹配就是尽可能少的匹配,用法就是在量词后面加上一个"?",比如: "aaaaa".match(/a+?/); //["a", index: 0, input: "aaaaa"] 但是非贪婪匹配
-
python中如何使用正则表达式的非贪婪模式示例
前言 本文主要给大家介绍了关于python使用正则表达式的非贪婪模式的相关内容,分享出来供大家参考学习,下面话不多说了,来一起详细的介绍吧. 在正则表达式里,什么是正则表达式的贪婪与非贪婪匹配 如:String str="abcaxc"; Patter p="ab*c"; 贪婪匹配:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配.如上面使用模式p匹配字符串str,结果就是匹配到:abcaxc(ab*c). 非贪婪匹配:就是匹配到结果就好,就少的匹配字符.如上
-
正则表达式中两个反斜杠的匹配规则详解
关于正则表达式raw的\匹配规则 这是我在学习中获得到的一个例子,第一表达式中匹配到的是none.于是乎我就在思考,为什么会匹配不到,假设\t被转义成一个\t,那么也应该匹配到\tsanle,而不是none. 为了验证这个问题,我做了如下的实验: 那为什么一个会出现这样的结果呢,在正则表达式中,需要查找的字符串,会进行两次转义,先是传入的字符串进行第一层转换,例如:\\t --> \t .然后传到re解析器里进行第二层转换,\t -->tab键.而需要匹配的字符串\\\t -->两个反斜
-
java正则表达式之Pattern与Matcher类详解
Pattern.split方法详解 /** * 测试Pattern.split方法 */ @Test public void testPatternSplit() { String str = "{0x40, 0x11, 0x00, 0x00}"; // 分割符为:逗号, {,}, 空白符 String regex = "[,\\{\\}\\s]"; Pattern pattern = Pattern.compile(regex); /* * 1. split 方法
-
正则表达式中问号(?)的正确用法详解
目录 1.直接跟随在子表达式后面 2.非贪婪匹配 3.非获取匹配 4.断言 参考资料: 正则表达式中“?”的用法大概有以下几种 1.直接跟随在子表达式后面 这种方式是最常用的用法,具体表示匹配前面的一次或者0次,类似于{0,1},如:abc(d)?可匹配abc和abcd 2.非贪婪匹配 关于贪婪和非贪婪,贪婪匹配的意思是,在同一个匹配项中,尽量匹配更多所搜索的字符,非贪婪则相反.正则匹配的默认模式是贪婪模式,当?号跟在如下限制符后面时,使用非贪婪模式(*,+,?,{n},{n,},{n,m})
-
正则表达式问号的四种用法详解
原文符号 因为?在正则表达式中有特殊的含义,所以如果想匹配?本身,则需要转义,\? 有无量词 问号可以表示重复前面内容的0次或一次,也就是要么不出现,要么出现一次. 非贪婪匹配 贪婪匹配 在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配 string pattern1 = @"a.*c"; // greedy match Regex regex = new Regex(pattern1); regex.Match("abcabc"); // return
-
C++中函数匹配机制详解
首先,编译器会确定候选函数然后确定可行函数可行函数,再从可行函数中进一步挑选 候选函数:重载函数集中的函数 可行函数:可以调用的函数 最后进行寻找最佳匹配 有以下几种规则 1.该函数的每个实参的匹配都不劣于其他可行函数 2.至少有一个实参的匹配优于其他可行函数的匹配 3.满足上面两种要求的函数有且只有一个 如果上面三个要求都没满足,则出现二义性 一些演示 各有一个精确匹配的实参,编译器报错,不满足条件3 error void func(int a,int b) { cout << "
-
SpringBatch从入门到精通之StepScope作用域和用法详解
目录 1.StepSope 是一种scope 2.StepSope 是一种自定义step 3.如何使用.@Value是支持spel表达式的 3.1 大部分场景是Spel 表达式.在底层reader/process/writer 中使用@Value获取jobParamter/stepContext/jobContext 3.2 SpEL引用bean 3.3 系统属性 3.4 运算符号 4.可能遇到问题 5.StepScope原理 6.自定义一个scope 1.StepSope 是一种scope 在