python实现余弦相似度文本比较的示例
向量空间模型VSM:
VSM的介绍:
一个文档可以由文档中的一系列关键词组成,而VSM则是用这些关键词的向量组成一篇文档,其中的每个分量代表词项在文档中的相对重要性。
VSM的例子:
比如说,一个文档有分词和去停用词之后,有N个关键词(或许去重后就有M个关键词),文档关键词相应的表示为(d1,d2,d3,...,dn),而每个关键词都有一个对应的权重(w1,w1,...,wn)。对于一篇文档来说,或许所含的关键词项比较少,文档向量化后的向量维度可能不是很大。而对于多个文档(2篇文档或两篇文档以上),则需要合并所有文档的关键词(关键词不能重复),形成一个不重复的关键词集合,这个关键词集合的个数就是每个文档向量化后的向量的维度。打个比方说,总共有2篇文档A和B,其中A有5个不重复的关键词(a1,a2,a3,a4,a5),B有6个关键词(b1,b2,b3,b4,b5,b6),而且假设b1和a3重复,则可以形成一个简单的关键词集(a1,a2,a3,a4,a5,,b2,b3,b4,b5,b6),则A文档的向量可以表示为(ta1,ta2,ta3,ta4,ta5,0,0,0,0,0),B文档可以表示为(0,0,tb1,0,0,tb2,tb3,tb4,tb5,tb6),其中的tb表示的对应的词汇的权重。
最后,关键词的权重一般都是有TF-IDF来表示,这样的表示更加科学,更能反映出关键词在文档中的重要性,而如果仅仅是为数不大的文档进行比较并且关键词集也不是特别大,则可以采用词项的词频来表示其权重(这种表示方法其实不怎么科学)。
TF-IDF权重计算:
TF的由来:
以前在文档搜索的时候,我们只考虑词项在不在文档中,在就是1,不在就是0。其实这并不科学,因为那些出现了很多次的词项和只出现了一次的词项会处于等同的地位,就是大家都是1.按照常理来说,文档中词项出现的频率越高,那么就意味着这个词项在文档中的地位就越高,相应的权重就越大。而这个权重就是词项出现的次数,这样的权重计算结果被称为词频(term frequency),用TF来表示。
IDF的出现:
在用TF来表示权重的时候,会出现一个严重的问题:就是所有 的词项都被认为是一样重要的。但在实际中,某些词项对文本相关性的计算来说毫无意义,举个例子,所有的文档都含有汽车这个词汇,那么这个词汇就没有区分能力。解决这个问题的直接办法就是让那些在文档集合中出现频率较高的词项获得一个比较低的权重,而那些文档出现频率较低的词项应该获得一个较高的权重。
为了获得出现词项T的所有的文档的数目,我们需要引进一个文档频率df。由于df一般都比较大,为了便于计算,需要把它映射成一个较小的范围。我们假设一个文档集里的所有的文档的数目是N,而词项的逆文档频率(IDF)。计算的表达式如下所示:
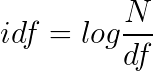
通过这个idf,我们就可以实现罕见词的idf比较高,高频词的idf比较低。
TF-IDF的计算:
TF-IDF = TF * IDF
有了这个公式,我们就可以对文档向量化后的每个词给予一个权重,若不含这个词,则权重为0。
余弦相似度的计算:
有了上面的基础知识,我们可以将每个分好词和去停用词的文档进行文档向量化,并计算出每一个词项的权重,而且每个文档的向量的维度都是一样的,我们比较两篇文档的相似性就可以通过计算这两个向量之间的cos夹角来得出。下面给出cos的计算公式:

分母是每篇文档向量的模的乘积,分子是两个向量的乘积,cos值越趋向于1,则说明两篇文档越相似,反之越不相似。
文本比较实例:
对文本进行去停用词和分词:
文本未分词前,如下图所示:
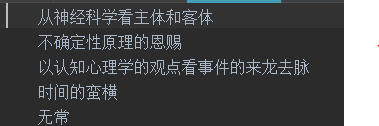
文本分词和去停用词后,如下图所示:

词频统计和文档向量化
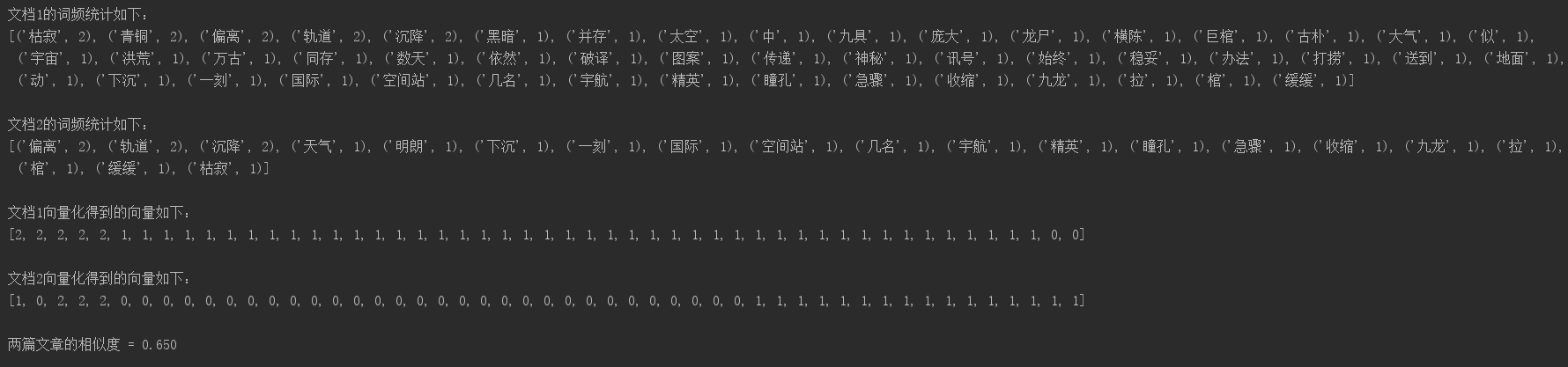
对经过上一步处理过的文档,我们可以统计每个文档中的词项的词频,并且将其向量化,下面我直接给出文档向量化之后的结果。注意:在这里由于只是比较两篇文档的相似性,所以我只用了tf来作为词项的权重,并未使用tf-idf:

向量化后的结果是:
[1,1,1,1,1,1,1,1,1,1,1,1,1,1]
- 两篇文档进行相似度的计算,我会给出两篇文档的原文和最终计算的相似度:
文档原文如下所示:

文档A的内容

文档B的内容
余弦相似度代码实现:
import math # 两篇待比较的文档的路径 sourcefile = '1.txt' s2 = '2.txt' # 关键词统计和词频统计,以列表形式返回 def Count(resfile): t = {} infile = open(resfile, 'r', encoding='utf-8') f = infile.readlines() count = len(f) # print(count) infile.close() s = open(resfile, 'r', encoding='utf-8') i = 0 while i < count: line = s.readline() # 去换行符 line = line.rstrip('\n') # print(line) words = line.split(" ") # print(words) for word in words: if word != "" and t.__contains__(word): num = t[word] t[word] = num + 1 elif word != "": t[word] = 1 i = i + 1 # 字典按键值降序 dic = sorted(t.items(), key=lambda t: t[1], reverse=True) # print(dic) # print() s.close() return (dic) def MergeWord(T1,T2): MergeWord = [] duplicateWord = 0 for ch in range(len(T1)): MergeWord.append(T1[ch][0]) for ch in range(len(T2)): if T2[ch][0] in MergeWord: duplicateWord = duplicateWord + 1 else: MergeWord.append(T2[ch][0]) # print('重复次数 = ' + str(duplicateWord)) # 打印合并关键词 # print(MergeWord) return MergeWord # 得出文档向量 def CalVector(T1,MergeWord): TF1 = [0] * len(MergeWord) for ch in range(len(T1)): TermFrequence = T1[ch][1] word = T1[ch][0] i = 0 while i < len(MergeWord): if word == MergeWord[i]: TF1[i] = TermFrequence break else: i = i + 1 # print(TF1) return TF1 def CalConDis(v1,v2,lengthVector): # 计算出两个向量的乘积 B = 0 i = 0 while i < lengthVector: B = v1[i] * v2[i] + B i = i + 1 # print('乘积 = ' + str(B)) # 计算两个向量的模的乘积 A = 0 A1 = 0 A2 = 0 i = 0 while i < lengthVector: A1 = A1 + v1[i] * v1[i] i = i + 1 # print('A1 = ' + str(A1)) i = 0 while i < lengthVector: A2 = A2 + v2[i] * v2[i] i = i + 1 # print('A2 = ' + str(A2)) A = math.sqrt(A1) * math.sqrt(A2) print('两篇文章的相似度 = ' + format(float(B) / A,".3f")) T1 = Count(sourcefile) print("文档1的词频统计如下:") print(T1) print() T2 = Count(s2) print("文档2的词频统计如下:") print(T2) print() # 合并两篇文档的关键词 mergeword = MergeWord(T1,T2) # print(mergeword) # print(len(mergeword)) # 得出文档向量 v1 = CalVector(T1,mergeword) print("文档1向量化得到的向量如下:") print(v1) print() v2 = CalVector(T2,mergeword) print("文档2向量化得到的向量如下:") print(v2) print() # 计算余弦距离 CalConDis(v1,v2,len(v1))
到此这篇关于python实现余弦相似度文本比较的文章就介绍到这了,更多相关python余弦相似度内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python 求向量的余弦值操作
1.余弦相似度 余弦相似度衡量的是2个向量间的夹角大小,通过夹角的余弦值表示结果,因此2个向量的余弦相似度为: 余弦相似度的取值为[-1,1],值越大表示越相似. 向量夹角的余弦公式很简单,不在此赘述,直接上代码: def cosVector(x,y): if(len(x)!=len(y)): print('error input,x and y is not in the same space') return; result1=0.0; result2=0.0; result3=0.0; f
-
python代码如何实现余弦相似性计算
这篇文章主要介绍了python代码如何实现余弦相似性计算,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 A:西米喜欢健身 B:超超不爱健身,喜欢打游戏 step1:分词 A:西米/喜欢/健身 B:超超/不/喜欢/健身,喜欢/打/游戏 step2:列出两个句子的并集 西米/喜欢/健身/超超/不/打/游戏 step3:计算词频向量 A:[1,1,1,0,0,0,0] B:[0,1,1,1,1,1,1] step4:计算余弦值 余弦值越大,证明夹角越
-
Python 余弦相似度与皮尔逊相关系数 计算实例
夹角余弦(Cosine) 也可以叫余弦相似度. 几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异. (1)在二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式: (2) 两个n维样本点a(x11,x12,-,x1n)和b(x21,x22,-,x2n)的夹角余弦 类似的,对于两个n维样本点a(x11,x12,-,x1n)和b(x21,x22,-,x2n),可以使用类似于夹角余弦的概念来衡量它们间的相似程度. 即: 余弦取值范围为[-1,1]
-
Python绘制正余弦函数图像的方法
今天打算通过绘制正弦和余弦函数,从默认的设置开始,一步一步地调整改进,让它变得好看,变成我们初高中学习过的图象那样.通过这个过程来学习如何进行对图表的一些元素的进行调整. 01. 简单绘图 matplotlib有一套允许定制各种属性的默认设置.你可以几乎控制matplotlib中的每一个默认属性:图像大小,每英寸点数,线宽,色彩和样式,子图(axes),坐标轴和网格属性,文字和字体属性,等等. 安装 pip install matplotlib 虽然matplotlib的默认设置在大多数情况下相
-
余弦相似性计算及python代码实现过程解析
A:西米喜欢健身 B:超超不爱健身,喜欢打游戏 step1:分词 A:西米/喜欢/健身 B:超超/不/喜欢/健身,喜欢/打/游戏 step2:列出两个句子的并集 西米/喜欢/健身/超超/不/打/游戏 step3:计算词频向量 A:[1,1,1,0,0,0,0] B:[0,1,1,1,1,1,1] step4:计算余弦值 余弦值越大,证明夹角越小,两个向量越相似. step5:python代码实现 import jieba import jieba.analyse def words2vec(wo
-
Python使用matplotlib绘制余弦的散点图示例
本文实例讲述了Python使用matplotlib绘制余弦的散点图.分享给大家供大家参考,具体如下: 一 代码 import numpy as np import pylab as pl a = np.arange(0,2.0*np.pi,0.1) b = np.cos(a) #绘制散点图 pl.scatter(a,b) pl.show() 二 运行结果 三 修改散点符号代码 import numpy as np import pylab as pl a = np.arange(0,2.0*np
-
Python使用matplotlib绘制正弦和余弦曲线的方法示例
本文实例讲述了Python使用matplotlib绘制正弦和余弦曲线的方法.分享给大家供大家参考,具体如下: 一 介绍 关键词:绘图库 官网:http://matplotlib.org 二 代码 import numpy as np import matplotlib.pyplot as plt #line x=np.linspace(-np.pi,np.pi,256,endpoint=True) #定义余弦函数正弦函数 c,s=np.cos(x),np.sin(x) plt.figure(1)
-
python实现余弦相似度文本比较的示例
向量空间模型VSM: VSM的介绍: 一个文档可以由文档中的一系列关键词组成,而VSM则是用这些关键词的向量组成一篇文档,其中的每个分量代表词项在文档中的相对重要性. VSM的例子: 比如说,一个文档有分词和去停用词之后,有N个关键词(或许去重后就有M个关键词),文档关键词相应的表示为(d1,d2,d3,...,dn),而每个关键词都有一个对应的权重(w1,w1,...,wn).对于一篇文档来说,或许所含的关键词项比较少,文档向量化后的向量维度可能不是很大.而对于多个文档(2篇文档或两篇文档以上
-
python 实现图片旋转 上下左右 180度旋转的示例
如下所示: #首先建好一个数据_ud文件夹 import PIL.Image as img import os path_old = "C:/Users/49691/Desktop/数据/" path_new = "C:/Users/49691/Desktop/数据_ud/" filelist = os.listdir(path_old) total_num = len(filelist) print(total_num) for i in range(total_
-
python 比较2张图片的相似度的方法示例
本文介绍了python 比较2张图片的相似度的方法示例,分享给大家,具体如下: #!/usr/bin/python # -*- coding: UTF-8 -*- import cv2 import numpy as np #均值哈希算法 def aHash(img): #缩放为8*8 img=cv2.resize(img,(8,8),interpolation=cv2.INTER_CUBIC) #转换为灰度图 gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
-
PHP数据分析引擎计算余弦相似度算法示例
本文实例讲述了PHP数据分析引擎计算余弦相似度算法.分享给大家供大家参考,具体如下: 关于余弦相似度的相关介绍可参考百度百科:余弦相似度 <?php /** * 数据分析引擎 * 分析向量的元素 必须和基准向量的元素一致,取最大个数,分析向量不足元素以0填补. * 求出分析向量与基准向量的余弦值 * @author yu.guo@okhqb.com */ /** * 获得向量的模 * @param unknown_type $array 传入分析数据的基准点的N维向量.|eg:array(1,1
-
Java实现的计算稀疏矩阵余弦相似度示例
本文实例讲述了Java实现的计算稀疏矩阵余弦相似度功能.分享给大家供大家参考,具体如下: import java.util.HashMap; public class MyUDF{ /** * UDF Evaluate接口 * * UDF在记录层面上是一对一,字段上是一对一或多对一. Evaluate方法在每条记录上被调用一次,输入为一个或多个字段,输出为一个字段 */ public Double evaluate(String a, String b) { // TODO: 请按需要修改参数和
-
python文本数据相似度的度量
编辑距离 编辑距离,又称为Levenshtein距离,是用于计算一个字符串转换为另一个字符串时,插入.删除和替换的次数.例如,将'dad'转换为'bad'需要一次替换操作,编辑距离为1. nltk.metrics.distance.edit_distance函数实现了编辑距离. from nltk.metrics.distance import edit_distance str1 = 'bad' str2 = 'dad' print(edit_distance(str1, str2)) N元语
-
python机器学习创建基于规则聊天机器人过程示例详解
目录 聊天机器人 基于规则的聊天机器人 创建语料库 创建一个聊天机器人 总结 还记得这个价值一个亿的AI核心代码? while True: AI = input('我:') print(AI.replace("吗", " ").replace('?','!').replace('?','!')) 以上这段代码就是我们今天的主题,基于规则的聊天机器人 聊天机器人 聊天机器人本身是一种机器或软件,它通过文本或句子模仿人类交互. 简而言之,可以使用类似于与人类对话的软件进
-
python使用matplotlib绘制折线图的示例代码
示例代码如下: #!/usr/bin/python #-*- coding: utf-8 -*- import matplotlib.pyplot as plt # figsize - 图像尺寸(figsize=(10,10)) # facecolor - 背景色(facecolor="blue") # dpi - 分辨率(dpi=72) fig = plt.figure(figsize=(10,10),facecolor="blue") #figsize默认为4,
-
Python 实现图片转字符画的示例(静态图片,gif皆可)
字符画是一种由字母.标点或其他字符组成的图画,它产生于互联网时代,在聊天软件中使用较多,本文我们看一下如何将自己喜欢的图片转成字符画. 静态图片 首先,我们来演示将静态图片转为字符画,功能实现主要用到的 Python 库为 OpenCV,安装使用 pip install opencv-python 命令即可. 功能实现的基本思路为:利用聚类将像素信息聚为 3 或 5 类,颜色最深的一类用数字密集度表示,阴影的一类用横杠(-)表示,明亮部分用空白表示. 主要代码实现如下: def img2stri