R语言中igraph包的用法(邻接矩阵)
先导入igraph包:
library(igraph)
graph包最简单的用法就是graph方法,两句代码就完成绘制如下所示,1的loop表示为(1,1),1和2之间有3条edge,表示为(1,2,1,2,1,2)
g <- graph(c(1,1,1,2,1,2,1,2,1,5,2,3,2,4,2,5,3,3,3,4,3,4,3,4,4,5),directed = FALSE) plot(g)
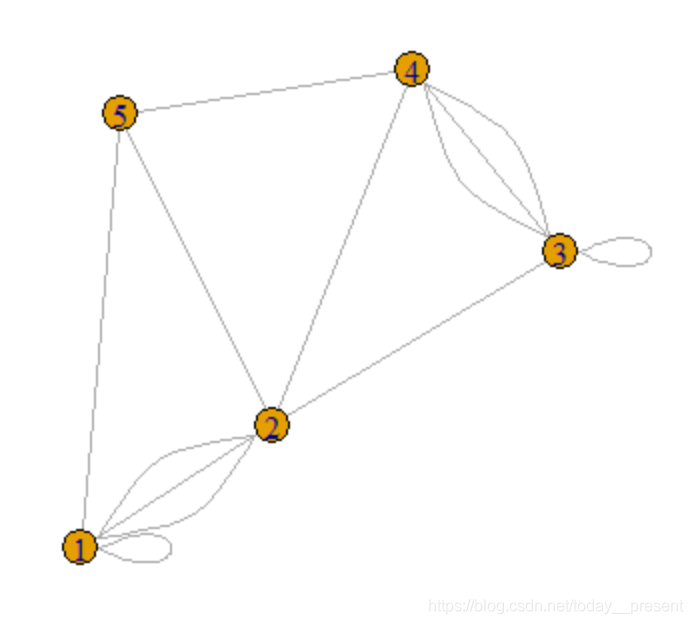
如果用顶点的邻接矩阵表示,仍以上图为例:
则对1,1有loop,与2有条edge,与5有一条edge,所以邻接矩阵的第一行为(1,3,0,0,1);
类似地,可以得出邻接矩阵的第2、3、4、5行;按列输入上述矩阵:
cell <- c(1,3,0,0,1,3,0,1,1,1,0,1,1,3,0,0,1,3,0,1,1,1,0,1,0) cell <- matrix(cell,5,5,byrow=T)
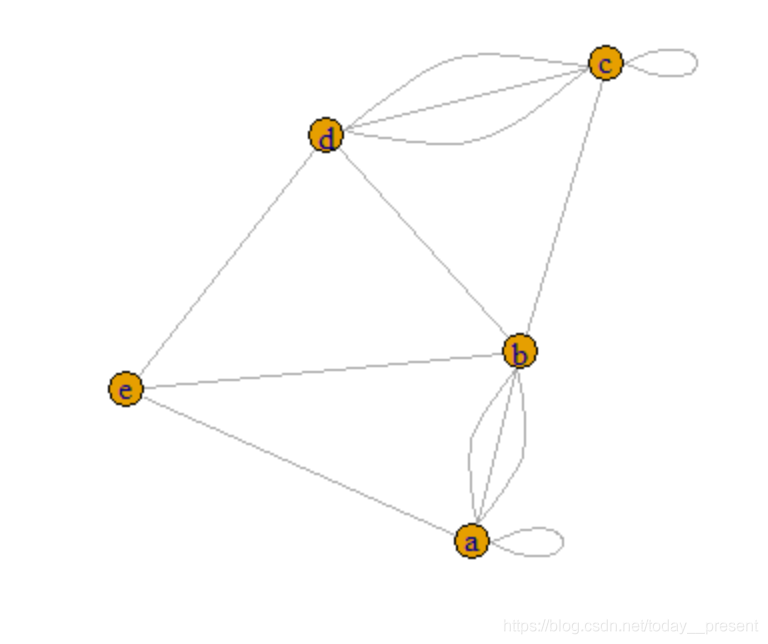
使用graph.adjacency方法:
cnames <- c('a','b','c','d','e')
g <- graph.adjacency(cell,mode="undirected")plot(g,vertex.label=cnames)#绘出图像
补充:R语言学习-提取igraph的节点和边
网络分析的时候,可能需要提取出网络中的节点或者边,igraph包中其实提供了很多可用的函数。
#创建网络方法之一:data.frame data<-data.frame(id1=c(1,1,2,3,4,4,5,5,6,6,7,8,8,9,10,5,15,6,7,16),id2=c(2,11,11,12,13,14,15,16,7,15,16,17,18,18,9,19,19,19,19,19)) g <- graph_from_data_frame(data, directed=FALSE) #directed 参数控制graph 有无方向 g IGRAPH UN-- 16 17 -- + attr: name (v/c) + edges (vertex names): [1] 1 --2 2 --3 3 --4 1 --4 5 --7 5 --6 5 --8 7 --6 7 --8 6 --8 9 --10 9 --13 11--10 11--12 12--13 14--15 1 --16 #图形显示 plot(g)

#V(g)和E(g)可以用来查看网络g的节点和边
V(g)
+ 16/16 vertices, named:
[1] 1 2 3 5 7 6 9 11 12 14 16 4 8 10 13 15
E(g)
+ 17/17 edges (vertex names):
[1] 1 --2 2 --3 3 --4 1 --4 5 --7 5 --6 5 --8 7 --6 7 --8 6 --8 9 --10 9 --13 11--10 11--12 12--13 14--15 1 --16
#但问题是怎么将里面的数据提取出来放到变量里面呢?
#节点提取有个函数get.vertex.attribute(g)
get.vertex.attribute(g)
$name
[1] "1" "2" "3" "5" "7" "6" "9" "11" "12" "14" "16" "4" "8" "10" "13" "15"
#查看类型可知是list
class(get.vertex.attribute(g))
[1] "list"
#剩下的就简单了
node<-get.vertex.attribute(g)[[1]]
node
[1] "1" "2" "3" "5" "7" "6" "9" "11" "12" "14" "16" "4" "8" "10" "13" "15"
#至于边呢?可以使用get.edgelist()
get.edgelist(g)
[,1] [,2]
[1,] "1" "2"
[2,] "2" "3"
[3,] "3" "4"
[4,] "1" "4"
[5,] "5" "7"
[6,] "5" "6"
[7,] "5" "8"
[8,] "7" "6"
[9,] "7" "8"
[10,] "6" "8"
[11,] "9" "10"
[12,] "9" "13"
[13,] "11" "10"
[14,] "11" "12"
[15,] "12" "13"
[16,] "14" "15"
[17,] "1" "16"
#类型是matrix矩阵可以直接使用
class(get.edgelist(g))
[1] "matrix"
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

R语言-实现按日期分组求皮尔森相关系数矩阵
R语言按日期分组求相关系数 前几天得到了3700+支股票一周内的波动率,想要计算每周各个股票之间的相关系数并将其可视化.最终结果保存在制定文件夹中. 部分数据如下: 先读取数据 data<-read.csv("D:/data/stock_day_close_price_week_series.csv", header = TRUE,blank.lines.skip = TRUE) 利用mice包处理缺失值: library(lattice) library(MASS) libra
-
R语言矩阵知识点总结及实例分析
矩阵是其中元素以二维矩形布局布置的R对象. 它们包含相同原子类型的元素. 虽然我们可以创建一个只包含字符或只包含逻辑值的矩阵,但它们没有太多用处. 我们使用包含数字元素的矩阵用于数学计算. 使用matrix()函数创建一个矩阵. 语法 在R语言中创建矩阵的基本语法是 matrix(data, nrow, ncol, byrow, dimnames) 以下是所使用的参数的说明 数据是成为矩阵的数据元素的输入向量. nrow是要创建的行数. ncol是要创建的列数. byrow是一个逻辑线索. 如果
-
R语言-如何将循环所得的矩阵组成一个矩阵
在矩阵合并中,常见的方法有cbind()和rbind() 其中,前者为按列合并,后者为按行合并. 但是这两个函数有个缺点,就是不能应用到循环之中.例如: A<-matrix(1:12,nrow = 4,byrow = T) B<-matrix(1:8,nrow = 4,byrow = T) C<-cbind(A,B) 得到的矩阵C为[按列合并两者行数必须相同]: 但是如果将这个方法应用在循环中,就无法取得预期效果: A<-matrix(1:12,nrow = 4,byrow = T
-
R语言-解决处理矩阵遇到内存不足的问题
如下: Error : cannot allocate vector of size X Gb 类似于这种问题的可能处理办法: 1. 可以用matrix尽量不要用data frame; 2. 可以用integer matrix尽量不要用 double matrix; 3. 对于大量运算后最好加上一个gc(), 强制R语言回收内存: 4. 对于大矩阵而言用bigmemory包,可以将大矩阵放到临时文件中,不占用内存. 补充:R语言之内存管理 在处理大型数据过程中,R语言的内存管理就显得十分重要,以
-
R语言 实现矩阵相乘100次
[D1 D2]2*1 [T1 T2]1*2 要求D1和D2随机的变动, 矩阵相乘100次 rm(list=ls()) gc() options(scipen = 2000) ##################写成函数###########3 #################定义TT矩阵(1*2) TT <- matrix(c(1,3),1,2) DD<- matrix(c(1,2),2,1) result1 <- DD %*% TT m1=result1 ##############
-
R语言中常见的几种创建矩阵形式总结
矩阵概述 R语言的实质实质上是与matlab差不多的,都是以矩阵为基础的 在R语言中,矩阵(matrix)是将数据按行和列组织数据的一种数据对象,相当于二维数组,可以用于描述二维的数据.与向量相似,矩阵的每个元素都拥有相同的数据类型.通常用列来表示来自不同变量的数据,用行来表示相同的数据. R中创建矩阵的语法格式 在R语言中可以使用matrix()函数来创建矩阵,其语法格式如下: matrix(data=NA, nrow = 1, ncol = 1, byrow = FALSE, dimname
-
R语言实现导出矩阵
程序实在是调不出来了,我决定破釜沉舟,直接把所有表格都打印出来,看看数据到底哪儿有问题. 然后就开始了闹心的矩阵导出... 首先,百度了一下,数据导出的代码为: write.table (x, file ="", sep ="", row.names =TRUE, col.names =TRUE, quote =TRUE) 其中: x:需要导出的数据 file:导出的文件路径 sep:分隔符,默认为空格(" "),也就是以空格为分割列 row.n
-
R语言中矩阵matrix和数据框data.frame的使用详解
本文主要介绍了R语言中矩阵matrix和数据框data.frame的一些使用,分享给大家,具体如下: "一,矩阵matrix" "创建向量" x_1=c(1,2,3) x_1=c(1:3) x_2=1:3 typeof(x_1)==typeof(x_2)#查看目标类型 x_3=seq(1,6,length=3)#将1--6分为3个数 a<-rep(1:3,each=3) #1到3依次重复 c<-rep(1:3,times=3) #1到3重复3次 d<
-
R语言中igraph包的用法(邻接矩阵)
先导入igraph包: library(igraph) graph包最简单的用法就是graph方法,两句代码就完成绘制如下所示,1的loop表示为(1,1),1和2之间有3条edge,表示为(1,2,1,2,1,2) g <- graph(c(1,1,1,2,1,2,1,2,1,5,2,3,2,4,2,5,3,3,3,4,3,4,3,4,4,5),directed = FALSE) plot(g) 如果用顶点的邻接矩阵表示,仍以上图为例: 则对1,1有loop,与2有条edge,与5有一条edg
-
R语言中cut()函数的用法说明
R语言cut()函数使用 cut()切割将x的范围划分为时间间隔,并根据其所处的时间间隔对x中的值进行编码. 参数:breaks:两个或更多个唯一切割点或单个数字(大于或等于2)的数字向量,给出x被切割的间隔的个数. breaks采用fivenum():返回五个数据:最小值.下四分位数.中位数.上四分位数.最大值. labels为区间数,打标签 ordered_result 逻辑结果应该是一个有序的因素吗? 先用fivenum求出5个数,再用labels为每两个数之间,贴标签,采用(]的区间,
-
R语言中quantile()函数的用法说明
在R语言中取百分位比用quantile()函数,下面举几个简单的示例: 1.求某个百分位比 > data <- c(1,2,3,4,5,6,7,8,9,10) > quantile(data,0.5) 50% 5.5 > quantile(data,c(0.25,0.75)) 25% 75% 3.25 7.75 2.产生一个序列百分位比值 > quantile(data,seq(0.1,1,0.1)) 10% 20% 30% 40% 50% 60% 70% 80% 90% 1
-
go语言中strings包的用法汇总
strings 包中的函数和方法 // strings.go ------------------------------------------------------------ // Count 计算字符串 sep 在 s 中的非重叠个数 // 如果 sep 为空字符串,则返回 s 中的字符(非字节)个数 + 1 // 使用 Rabin-Karp 算法实现 func Count(s, sep string) int func main() { s := "Hello,世界!!!!!&quo
-
R语言中qplot()函数的用法说明
ggplot2()函数 ggplot2是一个强大的作图工具,它可以让你不受现有图形类型的限制,创造出任何有助于解决你所遇到问题的图形. qplot() qplot()属于ggplot2(),可以理解成是它的简化版本. qplot 即"快速作图"(quick plot),顾名思义,能快速对数据进行可视化分析.它的用法和R base包的plot函数很相似. qplot() 参数 qplot(x, y = NULL, ..., data, facets = NULL, margins = F
-
浅析R语言中map(映射)与reduce(规约)
map(映射)与reduce(规约)操作在数据处理中非常常见,R语言的核心是向量化操作,自带的apply系列函数完成了数据框的向量化计算,而purrr包中的map与reduce系列函数很好的拓展了向量化计算,使R语言处理数据更加优雅流畅. purrr包是tidyverse系列中的包,开发者是大名鼎鼎的Hadley Wickham.purrr包中的函数很多,使用最多的是map与reduce系列函数. 安装包 install.packages('purrr') map map表示映射,可以在一个或多
-
golang语言中for循环语句用法实例
本文实例讲述了golang语言中for循环语句用法.分享给大家供大家参考.具体分析如下: for循环是用来遍历数组或数字的.用for循环遍历字符串时,也有 byte 和 rune 两种方式.第一种为byte,第二种rune. 复制代码 代码如下: package main import ( "fmt" ) func main() { s := "abc汉字" for i := 0; i < len(s); i++ { fmt.Printf("%c,&
-
C++语言中std::array的用法小结(神器用法)
摘要:在这篇文章里,将从各个角度介绍下std::array的用法,希望能带来一些启发. td::array是在C++11标准中增加的STL容器,它的设计目的是提供与原生数组类似的功能与性能.也正因此,使得std::array有很多与其他容器不同的特殊之处,比如:std::array的元素是直接存放在实例内部,而不是在堆上分配空间:std::array的大小必须在编译期确定:std::array的构造函数.析构函数和赋值操作符都是编译器隐式声明的--这让很多用惯了std::vector这类容器的程
-
详解R语言中的PCA分析与可视化
1. 常用术语 (1)标准化(Scale) 如果不对数据进行scale处理,本身数值大的基因对主成分的贡献会大.如果关注的是变量的相对大小对样品分类的贡献,则应SCALE,以防数值高的变量导入的大方差引入的偏见.但是定标(scale)可能会有一些负面效果,因为定标后变量之间的权重就是变得相同.如果我们的变量中有噪音的话,我们就在无形中把噪音和信息的权重变得相同,但PCA本身无法区分信号和噪音.在这样的情形下,我们就不必做定标. (2)特征值 (eigen value) 特征值与特征向量均为矩阵分
-
R语言中的vector(向量),array(数组)使用总结
对于那些有一点编程经验的人来说,vector,matrix,array,list,data.frame就相当于编程语言中的容器,因为只是将R看做数据处理工具所以它们的底层是靠什么实现的,内存怎么处理的具体也不要深究. R语言很奇怪的是它是面向对象的语言,所以经常会调用系统的方法,而且更奇怪的是总是调用"谓语"的方法,用起来像是写句子一样,记起来真是让人费解.比如is.vector(),read.table(),as.vector().. 直接开始吧:(由于习惯,大部分用"=&