关于Python 解决Python3.9 pandas.read_excel(‘xxx.xlsx‘)报错的问题
问题描述
使用pandas库的read_excel()方法读取外部excel文件报错, 截图如下
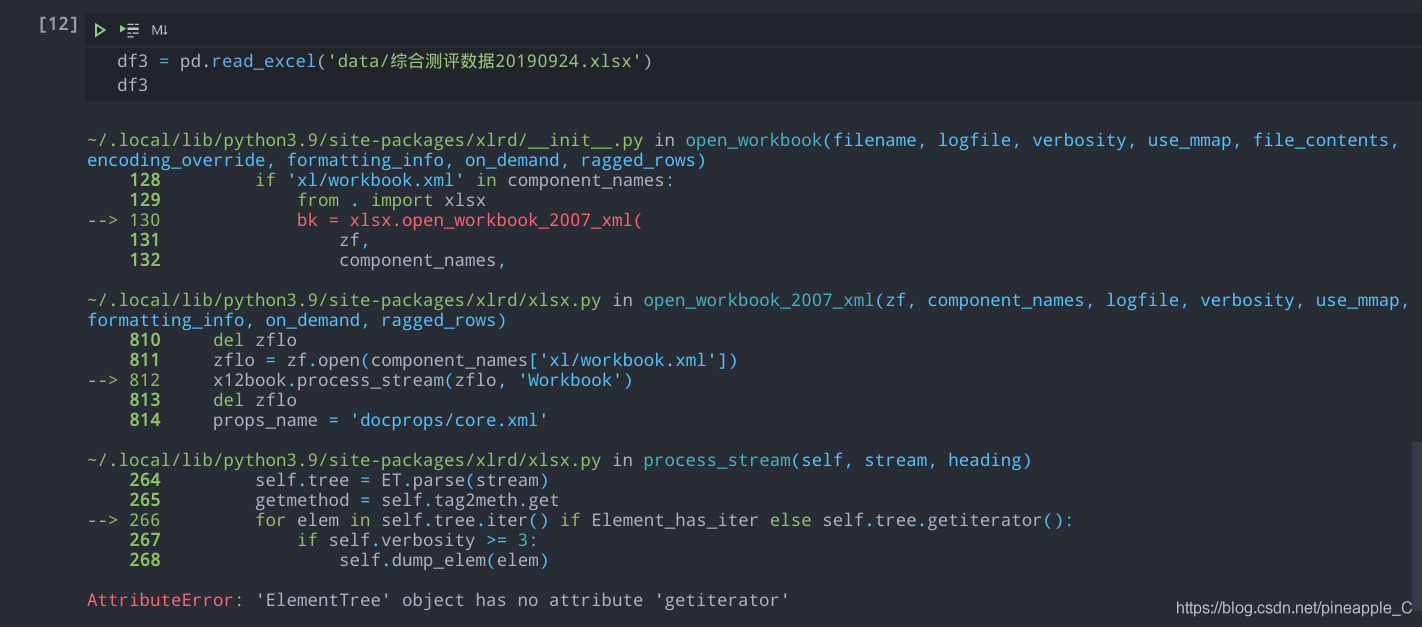
好像是缺少了什么方法的样子
问题分析
分析个啥, 水平有限, 直接面向stackoverflow编程
https://stackoverflow.com/questions/64264563/attributeerror-elementtree-object-has-no-attribute-getiterator-when-trying
我找到了下面的这几种说法


根据国外大神的指点, 我得出了这些结论:
pandas库读取excel文件是需要安装xlrd模块的, 也就是它默认是引擎engine是xlrd(之前已经手动pip3安装过), 使用Anaconda会把这些模块都安装上, 可是我没用Anaconda, 而是直接pip3 install pandas, 导致了很多其他模块需要自己安装. 但是安装了xlrd并不能解决问题, 因为我用的Python3.9, xlrd还没有对py3.9做相应的更新, 内部的getiterator方法在py3.9版本已经被移除, 需要将其替换成iter方法.
解决问题
方法一, 替换引擎
既然默认引擎xlrd出问题, 那干脆就直接换个, 指定engine为openpyxl

方法二, 修改源码
将已废弃掉的getiterator方法替换为iter方法
找到xlrd包下的xlsx.py, 进行替换!


到此这篇关于关于Python 解决Python3.9 pandas.read_excel(‘xxx.xlsx‘)报错的问题的文章就介绍到这了,更多相关Python3.9 pandas.read_excel内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现曲线拟合操作示例【基于numpy,scipy,matplotlib库】
本文实例讲述了Python实现曲线拟合操作.分享给大家供大家参考,具体如下: 这两天学习了用python来拟合曲线. 一.环境配置 本人比较比较懒,所以下载的全部是exe文件来安装,安装按照顺利来安装.自动会找到python的安装路径,一直点下一步就行.还有其他的两种安装方式:一种是解压,一种是pip.我没有尝试,就不乱说八道了. 没有ArcGIS 环境的,可以不看下面这段话了. 在配置环境时遇见一个小波折,就是原先电脑装过ArcGIS10.2 ,所以其会默认安装python2.7,而且pyth
-
python安装numpy&安装matplotlib& scipy的教程
numpy安装 下载地址:https://pypi.python.org/pypi/numpy(各取所需) copy安装目录.eg:鄙人的D:\python3.6.1\Scripts pip install :eg: win+R -----> CMD ----> pip install D:\python3.6.1\Scripts\numpy-1.13.0rc2-cp36-none-win_amd64.whl 安装成功: 同理: 安装matplotlib 安装scipy 以上这篇pyt
-
Python3.9最新版下载与安装图文教程详解(Windows系统为例)
首先进入python官网 https://www.python.org/ 通过Downloads选项,选择需要的版本进行下载, 此处我以 Windows系统为例,演示安装过程: 第1步:先勾选两个选项,再 Install Now 进行安装, 建议默认安装,如果想修改安装位置,则选择Customize installation进行自定义安装 接下来,等待安装完成, 安装完成,点击下方limit,设置MAX_PATH,同时授予管理员权限, 打开终端窗口,输入python命令,验证成果: 到此这篇关于
-
windows下python 3.9 Numpy scipy和matlabplot的安装教程详解
学习python过程中想使用python的matlabplot绘图功能,遇到了一大批问题,然后一路过关斩将,最终安装成功,实为不易,发帖留念. 1 首先打开cmd win+r 2 pip安装 pip3 install --user numpy scipy matplotlib –user 选项可以设置只安装在当前的用户下,而不是写入到系统目录.默认情况使用国外线路,国外太慢,我们使用清华的镜像就可以: pip3 install numpy scipy matplotlib -i https://
-
详解Python中的Numpy、SciPy、MatPlotLib安装与配置
用Python来编写机器学习方面的代码是相当简单的,因为Python下有很多关于机器学习的库.其中下面三个库numpy,scipy,matplotlib,scikit-learn是常用组合,分别是科学计算包,科学工具集,画图工具包,机器学习工具集. numpy :主要用来做一些科学运算,主要是矩阵的运算.NumPy为Python带来了真正的多维数组功能,并且提供了丰富的函数库处理这些数组.它将常用的数学函数都进行数组化,使得这些数学函数能够直接对数组进行操作,将本来需要在Python级别进行的循
-
Python在centos7.6上安装python3.9的详细教程(默认python版本为2.7.5)
# 查看下centos7.6上的python版本 [root@registry ~]# cat /etc/redhat-release Linux release 7.6.1810 (Core) [root@registry ~]# python --version Python 2.7.5 为什么要升级呢?因为要部署一些软件,需要python3的支持!!!不得不装啊!!! 部署python3.9,并进入到python3虚拟环境: python3.9.0下载地址:https://www.pyth
-
Python3.9新特性详解
本文主要介绍Python3.9的一些新特性,如:更快速的进程释放,性能的提升,简便的新字符串函数,字典并集运算符以及更兼容稳定的内部API,详细如下: 字典并集和可迭代更新 字符串方法 类型提示 新的数学函数 新的解析器 IPv6范围内的地址 新模块:区域信息 其他语言更改 1.字典并集和可迭代更新 Python 3.9 dict类.如果有两个字典a和b,则现在可以使用这些运算符进行合并和更新. 我们有合并运算符|: 使用Iterables进行字典更新 | =运算符的另一个很棒的性能是能够使用可
-
关于Python 解决Python3.9 pandas.read_excel(‘xxx.xlsx‘)报错的问题
问题描述 使用pandas库的read_excel()方法读取外部excel文件报错, 截图如下 好像是缺少了什么方法的样子 问题分析 分析个啥, 水平有限, 直接面向stackoverflow编程 https://stackoverflow.com/questions/64264563/attributeerror-elementtree-object-has-no-attribute-getiterator-when-trying 我找到了下面的这几种说法 根据国外大神的指点, 我得出了这些
-
解决python中import文件夹下面py文件报错问题
如下所示: 在需要导入的那个文件夹里面新建一个 __init__.py文件,哪怕这个文件是空的文件也可以. 补充知识:python中import其他目录下的文件出现问题的解决方法 在使用python进行编程的时候,import其他文件路径下的.py文件时报错 Traceback (most recent call last): File "download_and_convert_data.py", line 44, in <module> from .datasets i
-
python使用pip成功导入库后还是报错的解决方法(针对vscode)
目录 前言 分析产生问题的原因 重点解决第二个问题 补充的问题——python代码有黄色的波浪线(定期补充) 总结 前言 写在开始前:其实出现这样的问题,你需要知道的就是核心问题出在哪里,并非是要相同的编译器才是这样的解决办法,要学会举一反三.核心问题(我帮你分析一下): 首先你是确保已经安装好了这个库,但是就是很奇妙的报错,那么问题可以排除你没成功安装库,只是你的库不起作用,那么不妨回忆一下你以前和最近是否安装了很多版本的python,然后又没有卸载,导致编译器有许多的版本需要抉择,但是编译器
-
解决Tensorflow2.0 tf.keras.Model.load_weights() 报错处理问题
错误描述: 1.保存模型:model.save_weights('./model.h5') 2.脚本重启 3.加载模型:model.load_weights('./model.h5') 4.模型报错:ValueError: You are trying to load a weight file containing 12 layers into a model with 0 layers. 问题分析: 模型创建后还没有编译,一般是在模型加载前调用model.build(input_shape)
-
解决在for循环中remove list报错越界的问题
最近在搞一个购物车的功能,里面有一个批量删除的操作,采用的是ExpandableListView以及BaseExpandableListAdapter.视乎跟本篇无关紧要,主要是为了记录一个java基础.迭代器iterator的使用 一.错误代码(主要就是购物车的批量删除) /** * 删除选中的 */ public void delSelect() { int groupSize; if (mGropBeens != null) { groupSize = mGropBeens.size();
-
关于maven依赖 ${xxx.version}报错问题
目录 maven依赖 ${xxx.version}报错 在pom文件加入以下配置即可解决 maven依赖的版本号报错解决(玄学) 玄学解决 maven依赖 ${xxx.version}报错 pom.xml 引入依赖时,版本取<version>${xxx.version}</version>有时会报红, 在pom文件加入以下配置即可解决 <properties> <xxx.version>版本号</xxx.version> </propert
-
MySQL解决Navicat设置默认字符串时的报错问题
目录 简介 问题复现 原因分析 解决方案 简介 说明 本文介绍用Navicat添加字段(字符串类型)并设置默认值时的报错问题. 问题描述 在Java开发过程中,经常会遇到给已有的表添加字段的场景. 在插入新字段的时候,表里边可能已经有很多数据了,这时我们最好给新插入的字段设置一个默认值,这样MySQL就会将已经存在的数据的新加字段设置为默认值.设置默认值可以增加系统的可维护性. 但我在给已有的表插入新字段(字符串类型)的时候发现报错了,本文介绍如何解决这个问题. 报错信息 1064 - You
-
解决laravel5.4下的group by报错的问题
使用ORM查询数据显示这个错,这是因为laravel使用了开启了mysql的严格模式所以 如果要关闭的话,我们需要找到config/database.php这个文件,然后将 mysql下的这个改为false;就会关闭. 既然说严格模式那什么是样模式呢.据我所知在mysql在5.7有一个尿性 [报错:only_full_group_by],就是你group by的数据里面必须包含你查询的数据,意思就是如果你的sql是:select name,age from user group by name;
-
解决vue.js 数据渲染成功仍报错的问题
最近在做一个vue项目,用的是官方推荐的axios请求数据,数据结构是一级对象嵌套二级对象,发现一级对象数据渲染不报错,二级数据渲染报错.很是郁闷!data函数如下 export default { name: 'hello', data() { return { card:{} } } } 返回的数据如下: { "object":{ "subObject":"123", ... } } 报错的原因是在data函数return的card里没有二级
-
解决idea导入ssm项目启动tomcat报错404的问题
用idea写ssm项目,基于之前一直在用spring boot 对于idea如何运行ssm花费了一番功夫 启动Tom act一直在报404 我搜了网上各种解决办法都不行,花费一天多的时间解决不了 就是在pom中添加下面代码 <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin<