SQL中where和having的区别详解
概念
where
where是一个约束声明,在查询数据库的结果返回之前对数据库中的查询条件进行约束,再返回结果前起作用,并且where后不能使用“聚合函数”。
聚合函数
对一组值执行计算,并返回单个值,也被称为组函数,经常与 SELECT 语句的 GROUP BY 子句的HAVING一同使用。例如
AVG 返回指定组中的平均值COUNT 返回指定组中项目的数量MAX 返回指定数据的最大值。MIN 返回指定数据的最小值。SUM 返回指定数据的和,只能用于数字列,空值被忽略。
having
having是一个过滤声明,是在查询数据库结果返回之后进行过滤,即在结果返回值后起作用,与聚合函数共同使用。
区别
使用group by进行过滤,则只能使用having。
执行顺序:where>聚合函数(sum,min,max,avg,count)>having,故where不使用聚合函数。
举个例子
职员表
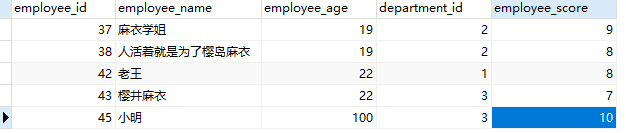
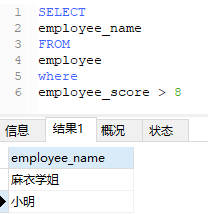
1、成绩大于8的有哪些?
使用where
使用having
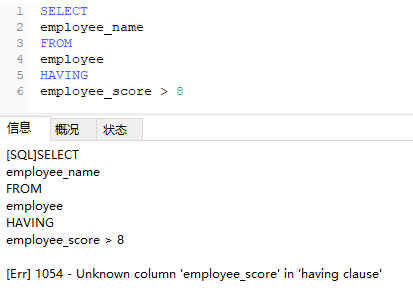
报错,因为having是对已过滤后的结果,进行筛选,但是筛选出没有employee_score这个值,所以报错,如果加上则可以查出。

故where和having很多时候不能随意替代,主要是过滤对象不同。
2、每个部门年龄大于20的最高最低成绩?
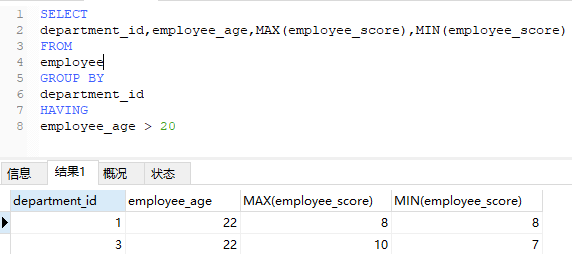
使用where也可以

但是需要注意执行顺序
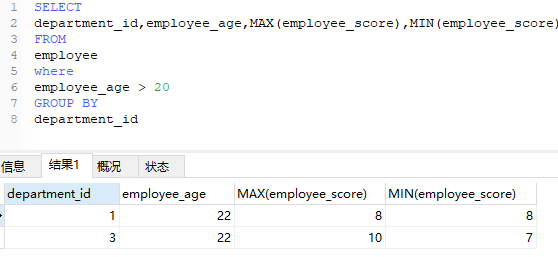
注意事项
在编写sql语句时,要注意where和group by的执行顺序,where应在前执行,group by 在后,否则会报错。
总结
到此这篇关于SQL中where和having的区别的文章就介绍到这了,更多相关SQL where和having区别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
sql中的 where 、group by 和 having 用法解析
废话不多说了,直接给大家贴代码了,具体代码如下所示: --sql中的 where .group by 和 having 用法解析 --如果要用到group by 一般用到的就是"每这个字" 例如说明现在有一个这样的表:每个部门有多少人 就要用到分组的技术 select DepartmentID as '部门名称',COUNT(*) as '个数' from BasicDepartment group by DepartmentID --这个就是使用了group by +字段 进行了分组
-
SQL中Having与Where的区别及注意
区别介绍: where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行. having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组. 注意: 1.HAVING子句必须位于GROUP BY之后ORDER BY之前. 2.WHERE语句在GROUP BY语句之前:SQL会在分组之前计算WHE
-
SQL 中having 和where的区别分析
在select语句中可以使用groupby子句将行划分成较小的组,然后,使用聚组函数返回每一个组的汇总信息,另外,可以使用having子句限制返回的结果集.groupby子句可以将查询结果分组,并返回行的汇总信息Oracle按照groupby子句中指定的表达式的值分组查询结果. 在带有groupby子句的查询语句中,在select列表中指定的列要么是groupby子句中指定的列,要么包含聚组函数 复制代码 代码如下: selectmax(sal),jobempgroupbyjob; (注意max
-
数据库SQL中having和where的用法区别
"Where" 是一个约束声明,使用Where来约束来之数据库的数据,Where是在结果返回之前起作用的,且Where中不能使用聚合函数. "Having"是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作,在Having中可以使用聚合函数. 聚合函数,SQL基本函数,聚合函数对一组值执行计算,并返回单个值.除了 COUNT 以外,聚合函数都会忽略空值. 聚合函数经常与 SELECT 语句的 GROUP BY 子句一起使用. Transact-SQL编程
-
SQL中Having与Where的区别
含义 where 在分组之前就进行选择操作 having having在分组操作之后才进行选择操作,所以having可以选择聚合函数 eg: // 下面这句是可以的 SELECT COUNT(*) FROM A WHERE A.a1>0 GROUP BY a2: //但是下面就不行 SELECT COUNT(*) FROM A WHERE A.a1>0 and count(*)>1 GROUP BY a2: //必须要改为having SELECT COUNT(*) FROM A WHE
-
sql语句中where和having的区别
HAVING是先分组再筛选记录,WHERE在聚合前先筛选记录.也就是说作用在GROUP BY 子句和HAVING子句前:而 HAVING子句在聚合后对组记录进行筛选. 作用的对象不同.WHERE 子句作用于表和视图,HAVING 子句作用于组.WHERE 在分组和聚集计算之前选取输入行(因此,它控制哪些行进入聚集计算), 而 HAVING 在分组和聚集之后选取分组的行.因此,WHERE 子句不能包含聚集函数: 因为试图用聚集函数判断那些行输入给聚集运算是没有意义的. 相反,HAVING 子句总是
-
SQL中where子句与having子句的区别小结
前言: Where和Having都是对查询结果的一种筛选,说的书面点就是设定条件的语句.下面这篇文章就来给大家介绍下SQL中where子句与having子句的区别,下面话不多说了,来一起看看详细的介绍吧 1.where 不能放在GROUP BY 后面 2.HAVING 是跟GROUP BY 连在一起用的,放在GROUP BY 后面,此时的作用相当于WHERE 3.WHERE 后面的条件中不能有聚集函数,比如SUM(),AVG()等,而HAVING 可以 Where和Having都是对查询结果的一
-

SQL中where和having的区别详解
概念 where where是一个约束声明,在查询数据库的结果返回之前对数据库中的查询条件进行约束,再返回结果前起作用,并且where后不能使用"聚合函数". 聚合函数 对一组值执行计算,并返回单个值,也被称为组函数,经常与 SELECT 语句的 GROUP BY 子句的HAVING一同使用.例如 AVG 返回指定组中的平均值COUNT 返回指定组中项目的数量MAX 返回指定数据的最大值.MIN 返回指定数据的最小值.SUM 返回指定数据的和,只能用于数字列,空值被忽略. having
-
MyBatis中resultMap和resultType的区别详解
总结 基本映射 :(resultType)使用resultType进行输出映射,只有查询出来的列名和pojo中的属性名一致,该列才可以映射成功.(数据库,实体,查询字段,这些全部都得一一对应)高级映射 :(resultMap) 如果查询出来的列名和pojo的属性名不一致,通过定义一个resultMap对列名和pojo属性名之间作一个映射关系.(高级映射,字段名称可以不一致,通过映射来实现 resultType和resultMap功能类似 ,都是返回对象信息 ,但是resultMap要更强大一些
-
MySQL中replace into与replace区别详解
目录 0.故事的背景 1.replace into 的使用方法 2.有唯一索引时—replace into & 与replace 效果 3.没有唯一索引时—replace into 与 replace 1).replace函数的具体情况 2).replace into 函数的具体情况 4.replace的用法 本篇为抛砖引玉篇,之前没关注过replace into 与replace 的区别.经过多个场景测试,居然没找到在插入数据的时候两者有什么本质的区别?如果了解详情的伙伴们,请告知留言告知一二
-
基于python中staticmethod和classmethod的区别(详解)
例子 class A(object): def foo(self,x): print "executing foo(%s,%s)"%(self,x) @classmethod def class_foo(cls,x): print "executing class_foo(%s,%s)"%(cls,x) @staticmethod def static_foo(x): print "executing static_foo(%s)"%x a=A(
-
node.js中grunt和gulp的区别详解
node.js中grunt和gulp的区别详解 自nodeJS登上前端舞台,自动化构建变得越来越流行.目前最流行的当属grunt和gulp,这两个光看名字挺像,功能也差不多,不过gulp能在grunt这位大哥如日中天的境况下开辟出自己的一片天地,有着她独到的优点. 易用 Gulp相比Grunt更简洁,而且遵循代码优于配置策略,维护Gulp更像是写代码. 高效 Gulp相比Grunt更有设计感,核心设计基于Unix流的概念,通过管道连接,不需要写中间文件. 高质量 Gulp的每个插件只完成一个功能
-
基于js中this和event 的区别(详解)
今天在看javascript入门经典-事件一章中看到了 this 和 event 两种传参形式.因为作为一个初级的前端开发人员平时只用过 this传参,so很想弄清楚,this和event的区别是什么,什么情况下用什么比较合适. onclick = changeImg(this) vs onclick = changeImg(event) <img src='usa.gif' onclick="changeImg(event)" /> <scrip
-
iOS中setValue和setObject的区别详解
网上关于setValue和setObject的区别的文章很多,说的并不准确,首先我们得知道: setObject:ForKey: 是NSMutableDictionary特有的:setValue:ForKey:是KVC的主要方法 话不多说,上代码: - (void)viewDidLoad { [super viewDidLoad]; //setObject和setvalue的区别 NSMutableDictionary *dic = [NSMutableDictionary dictionary
-
python中import reload __import__的区别详解
import 作用:导入/引入一个python标准模块,其中包括.py文件.带有__init__.py文件的目录(自定义模块). import module_name[,module1,...] from module import *|child[,child1,...] 注意:多次重复使用import语句时,不会重新加载被指定的模块,只是把对该模块的内存地址给引用到本地变量环境. 实例: pythontab.py #!/usr/bin/env python #encoding: utf-8
-
JavaScript中object和Object的区别(详解)
JavaScript中object和Object有什么区别,为什么用typeof检测对象,返回object,而用instanceof 必须要接Object呢 这个问题和我之前遇到的问题非常相似,我认为这里有两个问题需要解决,一个是运算符new的作用机制,一个是function关键字和Funtion内置对象之间的区别.看了一些前辈的博客和标准,这里帮提问者总结一下. 1.new new运算符的作用是创建一个对象实例.这个对象可以是用户自定义的,也可以是带构造函数的一些系统自带的对象.如果 new
-
Android中asset和raw的区别详解
*res/raw和assets的相同点: 1.两者目录下的文件在打包后会原封不动的保存在apk包中,不会被编译成二进制. *res/raw和assets的不同点: 1.res/raw中的文件会被映射到R.java文件中,访问的时候直接使用资源ID即R.id.filename:assets文件夹下的文件不会被映射到 R.java中,访问的时候需要AssetManager类. 2.res/raw不可以有目录结构,而assets则可以有目录结构,也就是assets目录下可以再建立文件夹 *读取文件资源