用gpu训练好的神经网络,用tensorflow-cpu跑出错的原因及解决方案
训练的时候当然用gpu,速度快呀。
我想用cpu版的tensorflow跑一下,结果报错,这个错误不太容易看懂。

大概意思是没找到一些节点。
后来发现原因,用gpu和cpu保存的pb模型不太一样,但是checkpoints文件是通用的。
使用tensorflow-cpu再把checkpoints文件重新转换一下pb文件就可以了。
完美解决!
补充:tensflow-gpu版的无数坑坑坑!(tf坑大总结)
自己的小本本,之前预装有的pycharm+win10+anaconda3+python3的环境
2019/3/24重新安装发现:目前CUDA10.1安装不了tensorflow1.13,把CUDA改为10.0即可(记得对应的cudann呀)
如果刚入坑,建议先用tensorflw学会先跑几个demo,等什么时候接受不了cpu这乌龟般的速度之时,就要开始尝试让gpu来跑了。
cpu跑tensorflow只需要在anaconda3下载。
安装cpu跑的tensorflow:
我的小本本目前已经是gpu版本,cpu版本下红圈里那个版本就好了!
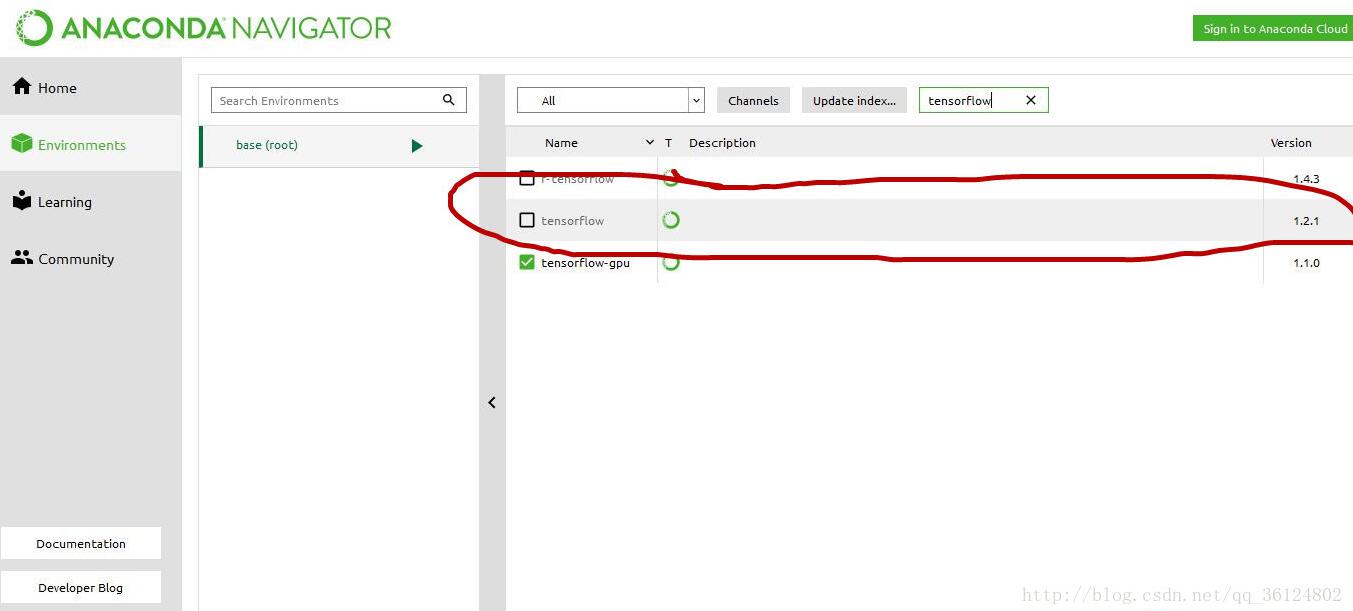
安装好了后直接在python命令中输入
import tensorflow as tf
如果不报错说明调用成功。
查看目前tensorflow调用的是cpu还是gpu运行:
import tensorflow as tf import numpy as np a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a') b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b') c = tf.matmul(a, b) sess = tf.Session(config=tf.ConfigProto(log_device_placement=True)) print(sess.run(c))
然后把这段代码粘贴到编译器中运行,
看一下运行的结果中,调用运行的是什么
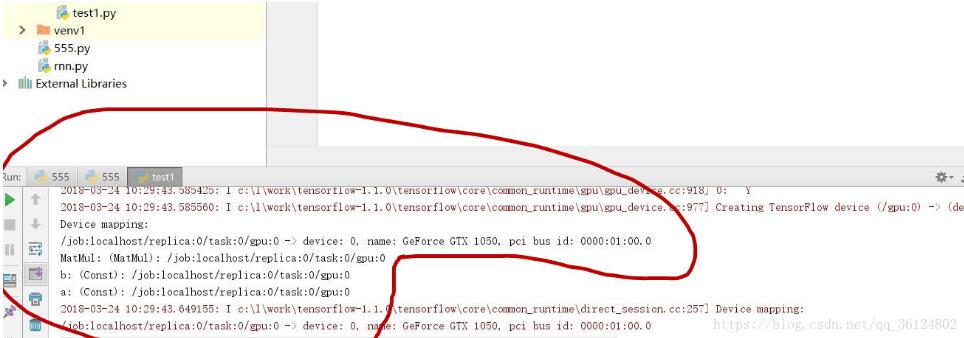
看给出的是gpu还是cpu就能判断目前运行的是哪一个了
安装gpu版本的tensorflow:
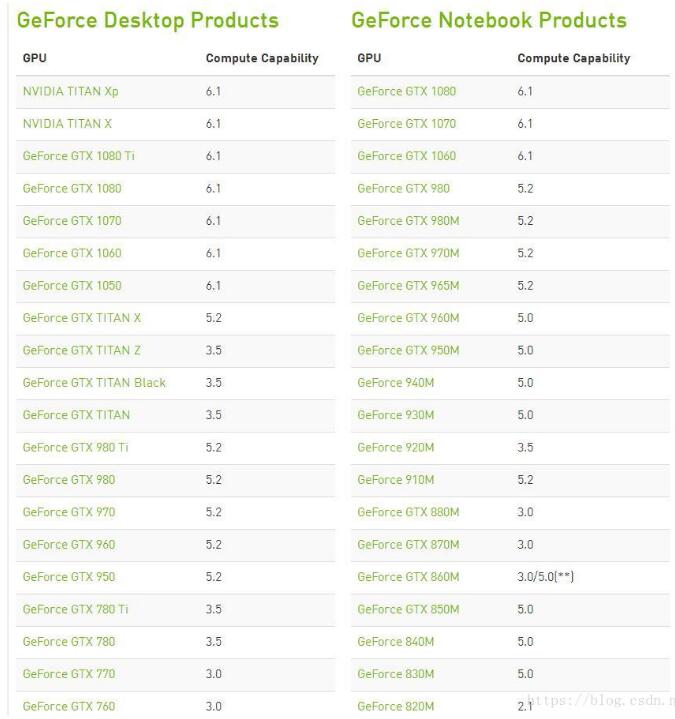
首先第一步要确定你的显卡是否为N卡,
然后上https://developer.nvidia.com/cuda-gpus去看看你的显卡是否被NVDIA允许跑机器学习
对于CUDA与cudann的安装:
需要到nvdia下载CUDA与cudann,这里最重要的是注意CUDA与cudann与tensorflow三者的搭配,
注意版本的搭配!!!
注意版本的搭配!!!
注意版本的搭配!!!
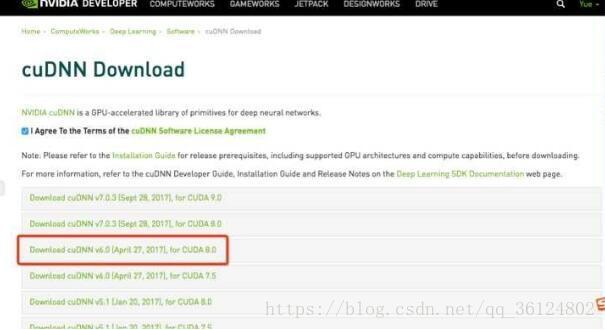
tensorflow在1.5版本以后才支持9.0以上的CUDA,所以如果CUDA版本过高,会造成找不到文件的错误。
在官网也可以看到CUDA搭配的cudann
在安装完了cudann时,需要把其三个文件复制到CUDA的目录下,并且添加3个新的path:
3个path,

当使用gpu版的tf时,就不再需要安装原来版本的tf,卸载了就好,安装tf-gpu版,
判断自己是否有安装tf包,对于pycharm用户,可以在setting那看看是否安装了tf-gpu
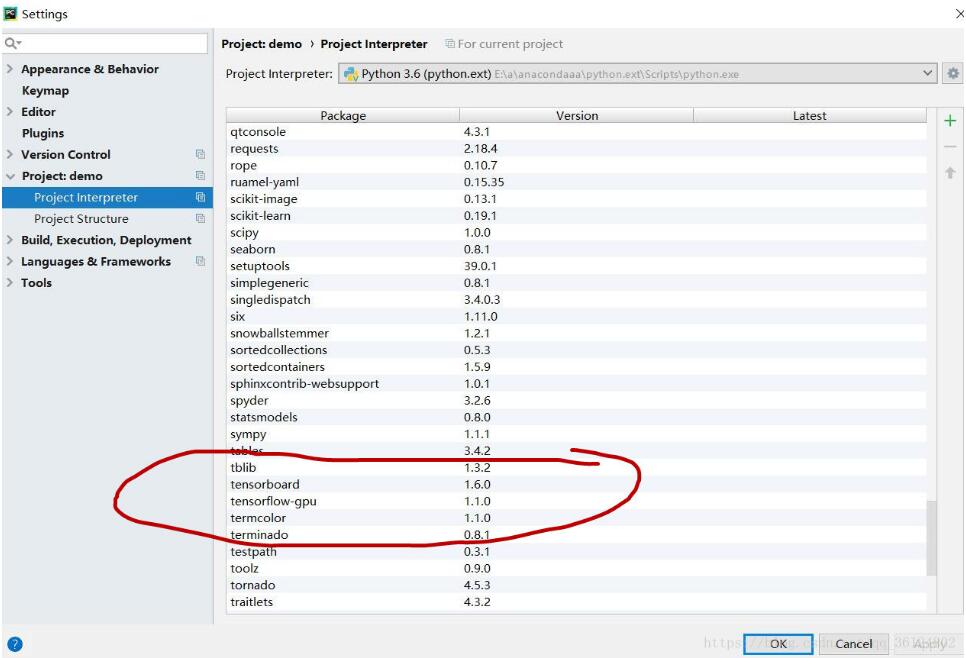
我使用的环境为:tf1.2+CUDA8.0+cudann5.1
当全部正确安装时
import tensorflow as tf 仍然出错
cudnn64_6.dll问题
关于导入TensorFlow找不到cudnn64_6.dll,其实下载的的是cudnn64_7.dll(版本不符合),把其修改过来就行了。
目录是在:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin下
对于不断尝试扔失败运行GPU版本,可以把tf先删除了重新下
import tensorflow as tf print(tf.__version__)
查询tensorflow安装路径为:
print(tf.__path__)
成功用GPU运行但运行自己的代码仍然报错:
如果报错原因是这个
ResourceExhaustedError (see above for traceback): OOM when allocating tensor with shape[10000,28,28,32]
最后关于这个报错是因为GPU的显存不够,此时你可以看看你的代码,是训练集加载过多还是测试集加载过多,将它一次只加载一部分即可。
对于训练集banch_xs,banch_ys = mnist.train.next_batch(1000) 改为
banch_xs,banch_ys = mnist.train.next_batch(100)即可,
而测试集呢print(compute_accuracy(mnist.test.images[:5000], mnist.test.labels[:5000])) 改为
print(compute_accuracy(mnist.test.images, mnist.test.labels))即可
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
解决TensorFlow程序无限制占用GPU的方法
今天遇到一个奇怪的现象,使用tensorflow-gpu的时候,出现内存超额~~如果我训练什么大型数据也就算了,关键我就写了一个y=W*x-显示如下图所示: 程序如下: import tensorflow as tf w = tf.Variable([[1.0,2.0]]) b = tf.Variable([[2.],[3.]]) y = tf.multiply(w,b) init_op = tf.global_variables_initializer() with tf.Session()
-
运行tensorflow python程序,限制对GPU和CPU的占用操作
一般情况下,运行tensorflow时,默认会占用可以看见的所有GPU,那么就会导致其它用户或程序无GPU可用,那么就需要限制程序对GPU的占用.并且,一般我们的程序也用不了所有的GPU资源,只是强行霸占着,大部分资源都不会用到,也不会提升运行速度. 使用nvidia-smi可以查看本机的GPU使用情况,如下图,这里可以看出,本机的GPU型号是K80,共有两个K80,四块可用(一个K80包括两块K40). 1.如果是只需要用某一块或某几块GPU,可以在运行程序时,利用如下命令运行:CUDA_VI
-
tensorflow-gpu安装的常见问题及解决方案
装tensorflow-gpu的时候经常遇到问题,自己装过几次,经常遇到相同或者类似的问题,所以打算记录一下,也希望对其他人有所帮助 基本信息 tensorflow-gpu pip安装(virtualenv等虚拟安装实质也是pip安装,只是建了个独立的环境,不会影响系统环境,查问题比较容易,最多重新再创建一个干净的环境再来) 安装完之后会用import tensorflow看是否安装成功,结果报错,主要有碰到下面两大类报错信息: 1.ImportError: DLL load failed: 找
-
基于Tensorflow使用CPU而不用GPU问题的解决
之前的文章讲过用Tensorflow的object detection api训练MobileNetV2-SSDLite,然后发现训练的时候没有利用到GPU,反而CPU占用率贼高(可能会有Could not dlopen library 'libcudart.so.10.0'之类的警告).经调查应该是Tensorflow的GPU版本跟服务器所用的cuda及cudnn版本不匹配引起的.知道问题所在之后就好办了. 检查cuda和cudnn版本 首先查看cuda版本: cat /usr/local/
-

用gpu训练好的神经网络,用tensorflow-cpu跑出错的原因及解决方案
训练的时候当然用gpu,速度快呀. 我想用cpu版的tensorflow跑一下,结果报错,这个错误不太容易看懂. 大概意思是没找到一些节点. 后来发现原因,用gpu和cpu保存的pb模型不太一样,但是checkpoints文件是通用的. 使用tensorflow-cpu再把checkpoints文件重新转换一下pb文件就可以了. 完美解决! 补充:tensflow-gpu版的无数坑坑坑!(tf坑大总结) 自己的小本本,之前预装有的pycharm+win10+anaconda3+python3的环
-
解决import tensorflow as tf 出错的原因
笔者在运行 import tensorflow as tf时出现下面的错误,但在运行import tensorflow时没有出错. >>> import tensorflow as tf RuntimeError: module compiled against API version 0xc but this version of numpy is 0xa ImportError: numpy.core.multiarray failed to import ImportError:
-
python神经网络使用tensorflow构建长短时记忆LSTM
目录 LSTM简介 1.RNN的梯度消失问题 2.LSTM的结构 tensorflow中LSTM的相关函数 tf.contrib.rnn.BasicLSTMCell tf.nn.dynamic_rnn 全部代码 LSTM简介 1.RNN的梯度消失问题 在过去的时间里我们学习了RNN循环神经网络,其结构示意图是这样的: 其存在的最大问题是,当w1.w2.w3这些值小于0时,如果一句话够长,那么其在神经网络进行反向传播与前向传播时,存在梯度消失的问题. 0.925=0.07,如果一句话有20到30个
-
python神经网络使用tensorflow实现自编码Autoencoder
目录 学习前言 antoencoder简介 1.为什么要降维 2.antoencoder的原理 3.python中encode的实现 全部代码 学习前言 当你发现数据的维度太多怎么办!没关系,我们给它降维!当你发现不会降维怎么办!没关系,来这里看看怎么autoencode antoencoder简介 1.为什么要降维 随着社会的发展,可以利用人工智能解决的越来越多,人工智能所需要处理的问题也越来越复杂,作为神经网络的输入量,维度也越来越大,也就出现了当前所面临的“维度灾难”与“信息丰富.知识贫乏
-
pytorch使用指定GPU训练的实例
本文适合多GPU的机器,并且每个用户需要单独使用GPU训练. 虽然pytorch提供了指定gpu的几种方式,但是使用不当的话会遇到out of memory的问题,主要是因为pytorch会在第0块gpu上初始化,并且会占用一定空间的显存.这种情况下,经常会出现指定的gpu明明是空闲的,但是因为第0块gpu被占满而无法运行,一直报out of memory错误. 解决方案如下: 指定环境变量,屏蔽第0块gpu CUDA_VISIBLE_DEVICES = 1 main.py 这句话表示只有第1块
-
关于pytorch多GPU训练实例与性能对比分析
以下实验是我在百度公司实习的时候做的,记录下来留个小经验. 多GPU训练 cifar10_97.23 使用 run.sh 文件开始训练 cifar10_97.50 使用 run.4GPU.sh 开始训练 在集群中改变GPU调用个数修改 run.sh 文件 nohup srun --job-name=cf23 $pt --gres=gpu:2 -n1 bash cluster_run.sh $cmd 2>&1 1>>log.cf50_2GPU & 修改 –gres=gpu:
-
pytorch 指定gpu训练与多gpu并行训练示例
一. 指定一个gpu训练的两种方法: 1.代码中指定 import torch torch.cuda.set_device(id) 2.终端中指定 CUDA_VISIBLE_DEVICES=1 python 你的程序 其中id就是你的gpu编号 二. 多gpu并行训练: torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0) 该函数实现了在module级别上的数据并行使用,注意batch size要大于G
-
解决pytorch多GPU训练保存的模型,在单GPU环境下加载出错问题
背景 在公司用多卡训练模型,得到权值文件后保存,然后回到实验室,没有多卡的环境,用单卡训练,加载模型时出错,因为单卡机器上,没有使用DataParallel来加载模型,所以会出现加载错误. 原因 DataParallel包装的模型在保存时,权值参数前面会带有module字符,然而自己在单卡环境下,没有用DataParallel包装的模型权值参数不带module.本质上保存的权值文件是一个有序字典. 解决方法 1.在单卡环境下,用DataParallel包装模型. 2.自己重写Load函数,灵活.
-
pytorch使用horovod多gpu训练的实现
pytorch在Horovod上训练步骤分为以下几步: import torch import horovod.torch as hvd # Initialize Horovod 初始化horovod hvd.init() # Pin GPU to be used to process local rank (one GPU per process) 分配到每个gpu上 torch.cuda.set_device(hvd.local_rank()) # Define dataset... 定义d
-
详解pytorch的多GPU训练的两种方式
目录 方法一:torch.nn.DataParallel 1. 原理 2. 常用的配套代码如下 3. 优缺点 方法二:torch.distributed 1. 代码说明 方法一:torch.nn.DataParallel 1. 原理 如下图所示:小朋友一个人做4份作业,假设1份需要60min,共需要240min. 这里的作业就是pytorch中要处理的data. 与此同时,他也可以先花3min把作业分配给3个同伙,大家一起60min做完.最后他再花3min把作业收起来,一共需要66min. 这个