Pytorch中Softmax与LogSigmoid的对比分析
Pytorch中Softmax与LogSigmoid的对比
torch.nn.Softmax
作用:
1、将Softmax函数应用于输入的n维Tensor,重新改变它们的规格,使n维输出张量的元素位于[0,1]范围内,并求和为1。
2、返回的Tensor与原Tensor大小相同,值在[0,1]之间。
3、不建议将其与NLLLoss一起使用,可以使用LogSoftmax代替之。
4、Softmax的公式:

参数:
维度,待使用softmax计算的维度。
例子:
# 随机初始化一个tensor
a = torch.randn(2, 3)
print(a) # 输出tensor
# 初始化一个Softmax计算对象,在输入tensor的第2个维度上进行此操作
m = nn.Softmax(dim=1)
# 将a进行softmax操作
output = m(a)
print(output) # 输出tensor
tensor([[ 0.5283, 0.3922, -0.0484],
[-1.6257, -0.4775, 0.5645]])
tensor([[0.4108, 0.3585, 0.2307],
[0.0764, 0.2408, 0.6828]])
可以看见的是,无论输入的tensor中的值为正或为负,输出的tensor中的值均为正值,且加和为1。
当m的参数dim=1时,输出的tensor将原tensor按照行进行softmax操作;当m的参数为dim=0时,输出的tensor将原tensor按照列进行softmax操作。
深度学习拓展:
一般来说,Softmax函数会用于分类问题上。例如,在VGG等深度神经网络中,图像经过一系列卷积、池化操作后,我们可以得到它的特征向量,为了进一步判断此图像中的物体属于哪个类别,我们会将该特征向量变为:类别数 * 各类别得分 的形式,为了将得分转换为概率值,我们会将该向量再经过一层Softmax处理。
torch.nn.LogSigmoid
公式:

函数图:

可以见得,函数值在[0, -]之间,输入值越大函数值距离0越近,在一定程度上解决了梯度消失问题。
例子:
a = [[ 0.5283, 0.3922, -0.0484],
[-1.6257, -0.4775, 0.5645]]
a = torch.tensor(a)
lg = nn.LogSigmoid()
lgoutput = lg(a)
print(lgoutput)
tensor([[-0.4635, -0.5162, -0.7176],
[-1.8053, -0.9601, -0.4502]])
二者比较:
import torch
import torch.nn as nn
# 设置a为 2*3 的tensor
a = [[ 0.5283, 0.3922, -0.0484],
[-1.6257, -0.4775, 0.5645]]
a = torch.tensor(a)
print(a)
print('a.mean:', a.mean(1, True)) # 输出a的 行平均值
m = nn.Softmax(dim=1) # 定义Softmax函数,dim=1表示为按行计算
lg = nn.LogSigmoid() # 定义LogSigmoid函数
output = m(a)
print(output)
# 输出a经过Softmax的结果的行平均值
print('output.mean:', output.mean(1, True))
lg_output = lg(a)
print(lg_output)
# 输出a经过LogSigmoid的结果的行平均值
print('lgouput.mean:', lg_output.mean(1, True))
# 结果:
tensor([[ 0.5283, 0.3922, -0.0484],
[-1.6257, -0.4775, 0.5645]])
a.mean: tensor(-0.1111)
tensor([[0.4108, 0.3585, 0.2307],
[0.0764, 0.2408, 0.6828]])
output.mean: tensor([[0.3333], [0.3333]]) # 经过Softmax的结果的行平均值
tensor([[-0.4635, -0.5162, -0.7176],
[-1.8053, -0.9601, -0.4502]])
lgouput.mean: tensor([[-0.5658], [-1.0719]]) # 经过LogSigmoid的结果的行平均值
由上可知,继续考虑分类问题,相同的数据,经过Softmax和LogSigmoid处理后,若取最大概率值对应类别作为分类结果,那么:
1、第一行数据经过Softmax后,会选择第一个类别;经过LogSigmoid后,会选择第一个。
2、第二行数据经过Softmax后,会选择第三个类别;经过LogSigmoid后,会选择第三个。
3、一般来说,二者在一定程度上区别不是很大,由于sigmoid函数存在梯度消失问题,所以被使用的场景不多。
4、但是在多分类问题上,可以尝试选择Sigmoid函数来作为分类函数,因为Softmax在处理多分类问题上,会更容易出现各项得分十分相近的情况。瓶颈值可以根据实际情况定。
nn.Softmax()与nn.LogSoftmax()
nn.Softmax()计算出来的值,其和为1,也就是输出的是概率分布,具体公式如下:

这保证输出值都大于0,在0,1范围内。
而nn.LogSoftmax()公式如下:

由于softmax输出都是0-1之间的,因此logsofmax输出的是小于0的数,
softmax求导:

logsofmax求导:
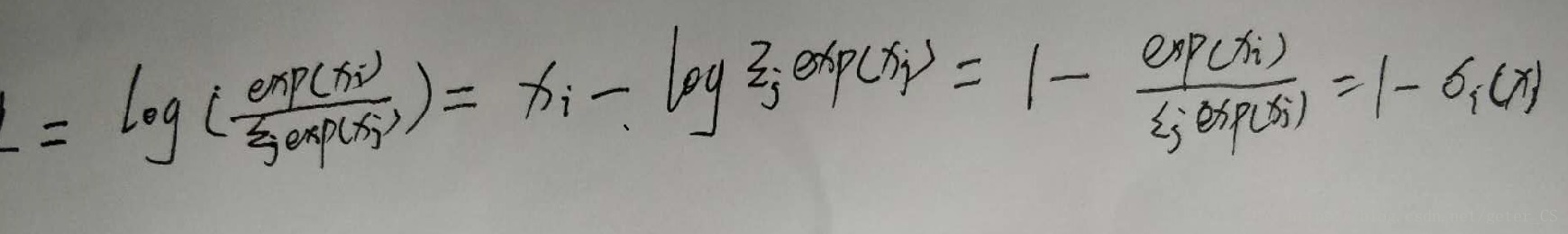
例子:
import torch.nn as nn import torch import numpy as np
layer1=nn.Softmax()
layer2=nn.LogSoftmax()
input=np.asarray([2,3])
input=Variable(torch.Tensor(input))
output1=layer1(input)
output2=layer2(input)
print('output1:',output1)
print('output2:',output2)
输出:
output1: Variable containing:
0.2689
0.7311
[torch.FloatTensor of size 2]output2: Variable containing:
-1.3133
-0.3133
[torch.FloatTensor of size 2]
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
PyTorch: Softmax多分类实战操作
多分类一种比较常用的做法是在最后一层加softmax归一化,值最大的维度所对应的位置则作为该样本对应的类.本文采用PyTorch框架,选用经典图像数据集mnist学习一波多分类. MNIST数据集 MNIST 数据集(手写数字数据集)来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口
-
浅谈pytorch中torch.max和F.softmax函数的维度解释
在利用torch.max函数和F.Ssoftmax函数时,对应该设置什么维度,总是有点懵,遂总结一下: 首先看看二维tensor的函数的例子: import torch import torch.nn.functional as F input = torch.randn(3,4) print(input) tensor([[-0.5526, -0.0194, 2.1469, -0.2567], [-0.3337, -0.9229, 0.0376, -0.0801], [ 1.4721, 0.1
-
PyTorch的SoftMax交叉熵损失和梯度用法
在PyTorch中可以方便的验证SoftMax交叉熵损失和对输入梯度的计算 关于softmax_cross_entropy求导的过程,可以参考HERE 示例: # -*- coding: utf-8 -*- import torch import torch.autograd as autograd from torch.autograd import Variable import torch.nn.functional as F import torch.nn as nn import nu
-

Pytorch中Softmax与LogSigmoid的对比分析
Pytorch中Softmax与LogSigmoid的对比 torch.nn.Softmax 作用: 1.将Softmax函数应用于输入的n维Tensor,重新改变它们的规格,使n维输出张量的元素位于[0,1]范围内,并求和为1. 2.返回的Tensor与原Tensor大小相同,值在[0,1]之间. 3.不建议将其与NLLLoss一起使用,可以使用LogSoftmax代替之. 4.Softmax的公式: 参数: 维度,待使用softmax计算的维度. 例子: # 随机初始化一个tensor a
-
详解Django中的FBV和CBV对比分析
在学习Django过程中在views.py进行逻辑处理时接触到了两种视图的书写风格,FBV和CBV FBV 指 function based views,即基于函数的视图 CBV 指 class based views,即基于类的视图 基于类的视图相较于基于函数的视图可以更加便利的实现类的继承封装等.在日常使用的时候,二者的区别主要在于对于request的请求方法的处理方式 FBV 我们通过函数传入的request的method来判断客户端发起的是什么请求,并进行相应的操作,返回相应的数据. d
-
Java集合中contains方法的效率对比分析
最近让部门技术大佬帮忙代码review的时候,他给我指出了一个小的技术细节,就是对于集合的contains方法尽量选用Set而不是List,平时没怎么注意,仔细看了下源码,大佬就是大佬,技术细节也把握的死死的. Java集合List.Set中均有对集合中元素是否存在的判断方法contains(Object o):Map中有对key及value是否存在的判断方法containsKey(Object key)和containsValue(Object value). 1.ArrayList 在Arr
-
Perl中use和require用法对比分析
Perl use和require用法对比 对比(一)说明:这两个函数都是一个意思,加载和引用Perl的模块,或者是子程序, 区别在于Perl use是在当前默认的里面去寻找,一旦模块不在指定的区域内的化,用Perl use是不可以引入的 第一.Perl use引入的名称不需要后缀名,而require需要第二.Perl use语句是编译时引入的,require是运行时引入的第三,Perl use引入模块的同时,也引入了模块的子模块.而require则不能引入,要在重新声明 Perl use my
-
Pytorch中Softmax和LogSoftmax的使用详解
一.函数解释 1.Softmax函数常用的用法是指定参数dim就可以: (1)dim=0:对每一列的所有元素进行softmax运算,并使得每一列所有元素和为1. (2)dim=1:对每一行的所有元素进行softmax运算,并使得每一行所有元素和为1. class Softmax(Module): r"""Applies the Softmax function to an n-dimensional input Tensor rescaling them so that th
-
关于pytorch多GPU训练实例与性能对比分析
以下实验是我在百度公司实习的时候做的,记录下来留个小经验. 多GPU训练 cifar10_97.23 使用 run.sh 文件开始训练 cifar10_97.50 使用 run.4GPU.sh 开始训练 在集群中改变GPU调用个数修改 run.sh 文件 nohup srun --job-name=cf23 $pt --gres=gpu:2 -n1 bash cluster_run.sh $cmd 2>&1 1>>log.cf50_2GPU & 修改 –gres=gpu:
-
php中随机函数mt_rand()与rand()性能对比分析
本文实例对比分析了php中随机函数mt_rand()与rand()性能问题.分享给大家供大家参考.具体分析如下: 在php中mt_rand()和rand()函数都是可以随机生成一个纯数字的,他们都是需要我们设置好种子数据然后生成,那么mt_rand()和rand()那个性能会好一些呢,下面我们带着疑问来测试一下. 例子1. mt_rand() 范例,代码如下: 复制代码 代码如下: <?php echo mt_rand() . "n"; echo mt_rand() . &quo
-
python中lambda与def用法对比实例分析
本文实例对比分析了python中lambda与def的用法.分享给大家供大家参考.具体分析如下: 1.lambda用来创建匿名函数,不同于def(def创建的函数都是有名字的). 2.lambda不会将结果赋给一个标识符,而def会将函数结果赋给一个标识符. 3.lambda是一个表达式,而def是一个语句 示例程序: >>> f1 = lambda x,y,z: x*2+y+z # lambda带有多个参数 >>> print f1(3,2,1) 9 >>
-
Python判断值是否在list或set中的性能对比分析
本文实例对比分析了Python判断值是否在list或set中的执行性能.分享给大家供大家参考,具体如下: 判断值是否在set集合中的速度明显要比list快的多, 因为查找set用到了hash,时间在O(1)级别. 假设listA有100w个元素,setA=set(listA)即setA为listA转换之后的集合. 以下做个简单的对比: for i in xrange(0, 5000000): if i in listA: pass for i in xrange(0, 5000000): if
-
Javascript中的几种继承方式对比分析
开篇 从'严格'意义上说,javascript并不是一门真正的面向对象语言.这种说法原因一般都是觉得javascript作为一门弱类型语言与类似java或c#之类的强型语言的继承方式有很大的区别,因而默认它就是非主流的面向对象方式,甚至竟有很多书将其描述为'非完全面向对象'语言.其实个人觉得,什么方式并不重要,重要的是是否具有面向对象的思想,说javascript不是面向对象语言的,往往都可能没有深入研究过javascript的继承方式,故特撰此文以供交流. 为何需要利用javascript实现