python第三方库visdom的使用入门教程
概述
Visdom:一个灵活的可视化工具,可用来对于 实时,富数据的 创建,组织和共享。支持Torch和Numpy还有pytorch。
visdom
可以实现远程数据的可视化,对科学实验有很大帮助。我们可以远程的发送图片和数据,并进行在ui界面显示出来,检查实验结果,或者debug.
要用这个先要安装,对于python模块而言,安装都是蛮简单的:
pip install visdom
安装完每次要用直接输入代码打开:
python -m visdom.server
然后根据提示在浏览器中输入相应地址即可,默认地址为:http://localhost:8097/
使用示例
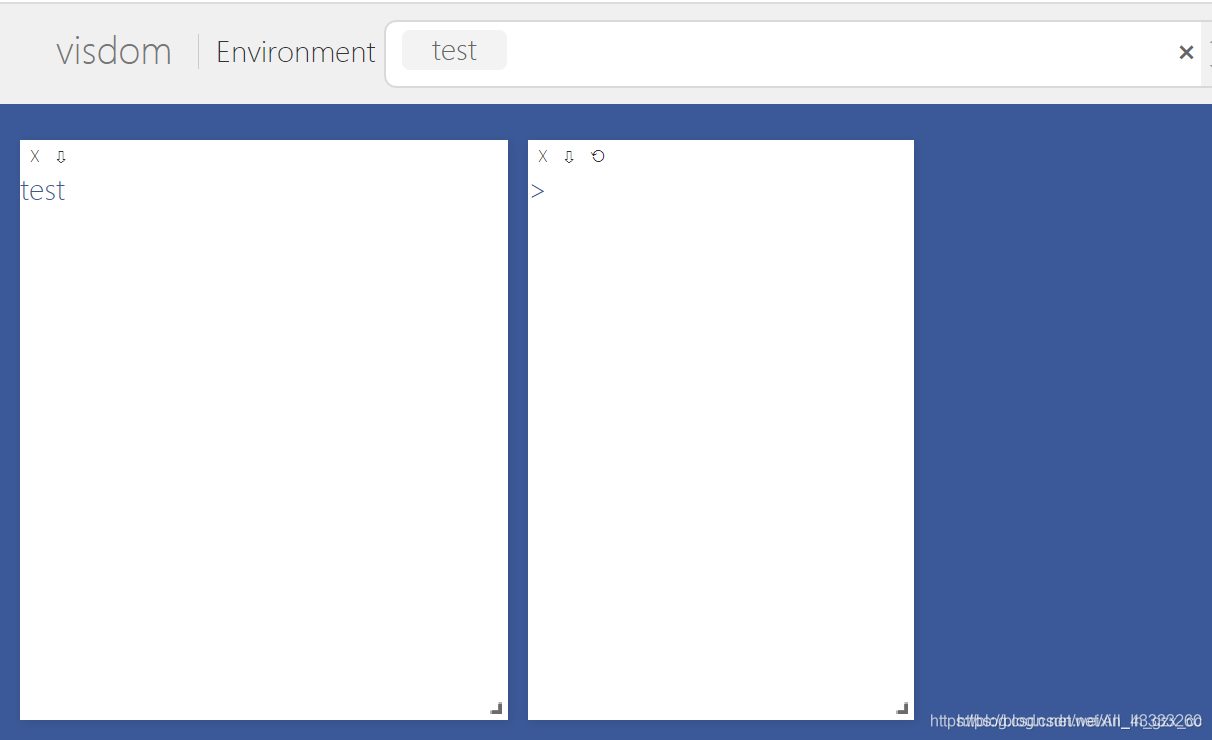
1. vis.text(), vis.image()
import visdom # 添加visdom库
import numpy as np # 添加numpy库
vis = visdom.Visdom(env='test') # 设置环境窗口的名称,如果不设置名称就默认为main
vis.text('test', win='main') # 使用文本输出
vis.image(np.ones((3, 100, 100))) # 绘制一幅尺寸为3 * 100 * 100的图片,图片的像素值全部为1
其中:
visdom.Visdom(env=‘命名新环境')
vis.text(‘文本', win=‘环境名')
vis.image(‘图片',win=‘环境名')
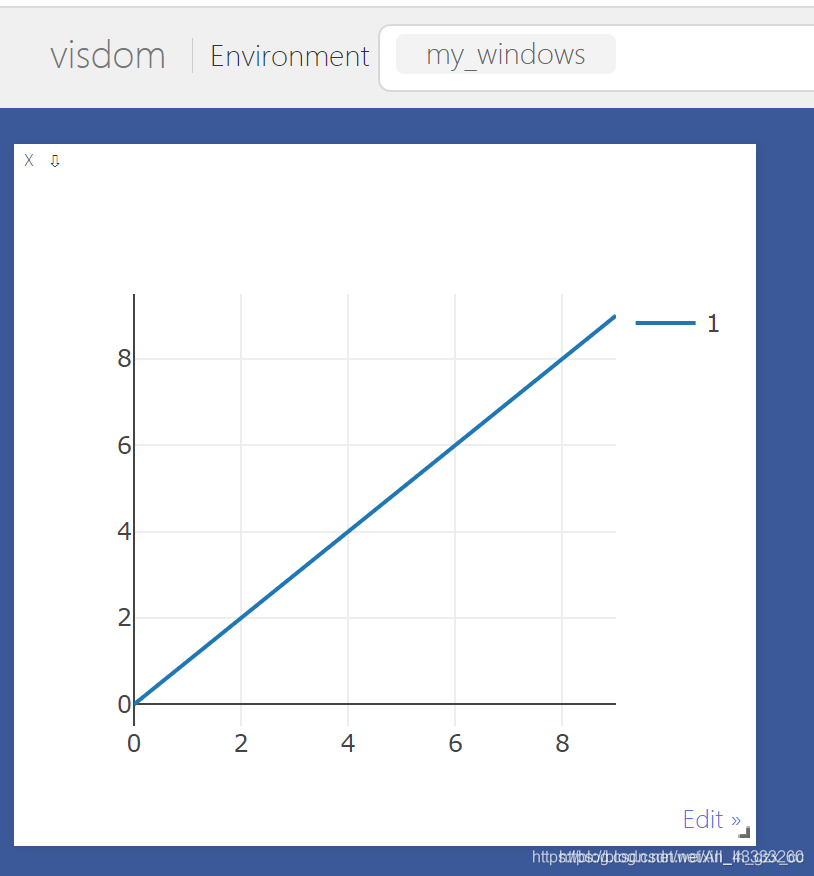
2. 画直线 .line() 一条
import visdom import numpy as np vis = visdom.Visdom(env='my_windows') # 设置环境窗口的名称,如果不设置名称就默认为main x = list(range(10)) y = list(range(10)) # 使用line函数绘制直线 并选择显示坐标轴 vis.line(X=np.array(x), Y=np.array(y), opts=dict(showlegend=True))
vis.line([x], [y], opts=dict(showlegend=True)[展示说明])
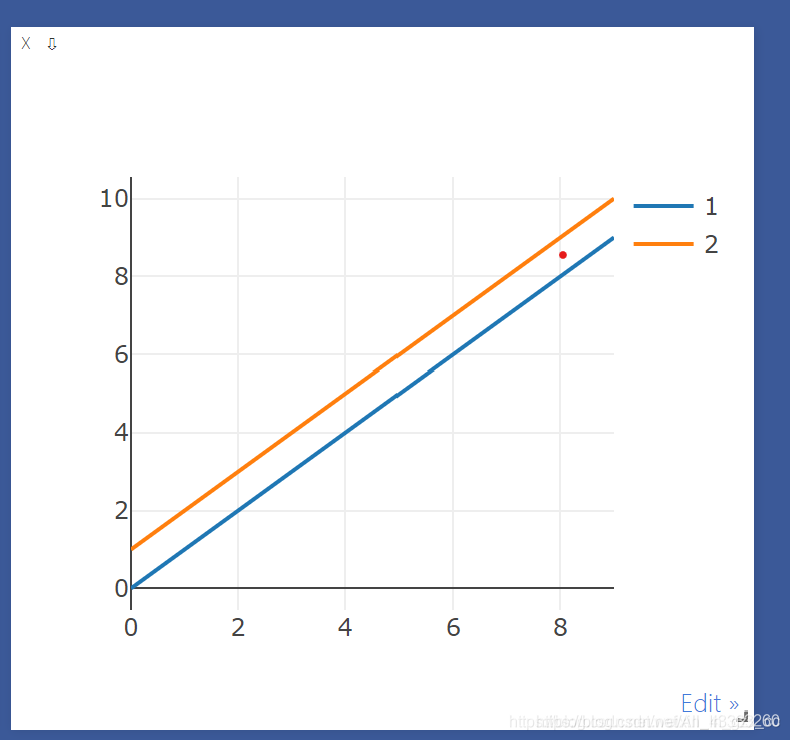
两条
import visdom import numpy as np vis = visdom.Visdom(env='my_windows') x = list(range(10)) y = list(range(10)) z = list(range(1,11)) vis.line(X=np.array(x), Y=np.column_stack((np.array(y), np.array(z))), opts=dict(showlegend=True))
vis.line([x], [y=np.column_stack((np.array(y),np.array(z),np.array(还可以增加)))])
np.column_stack(a,b), 表示两个矩阵按列合并
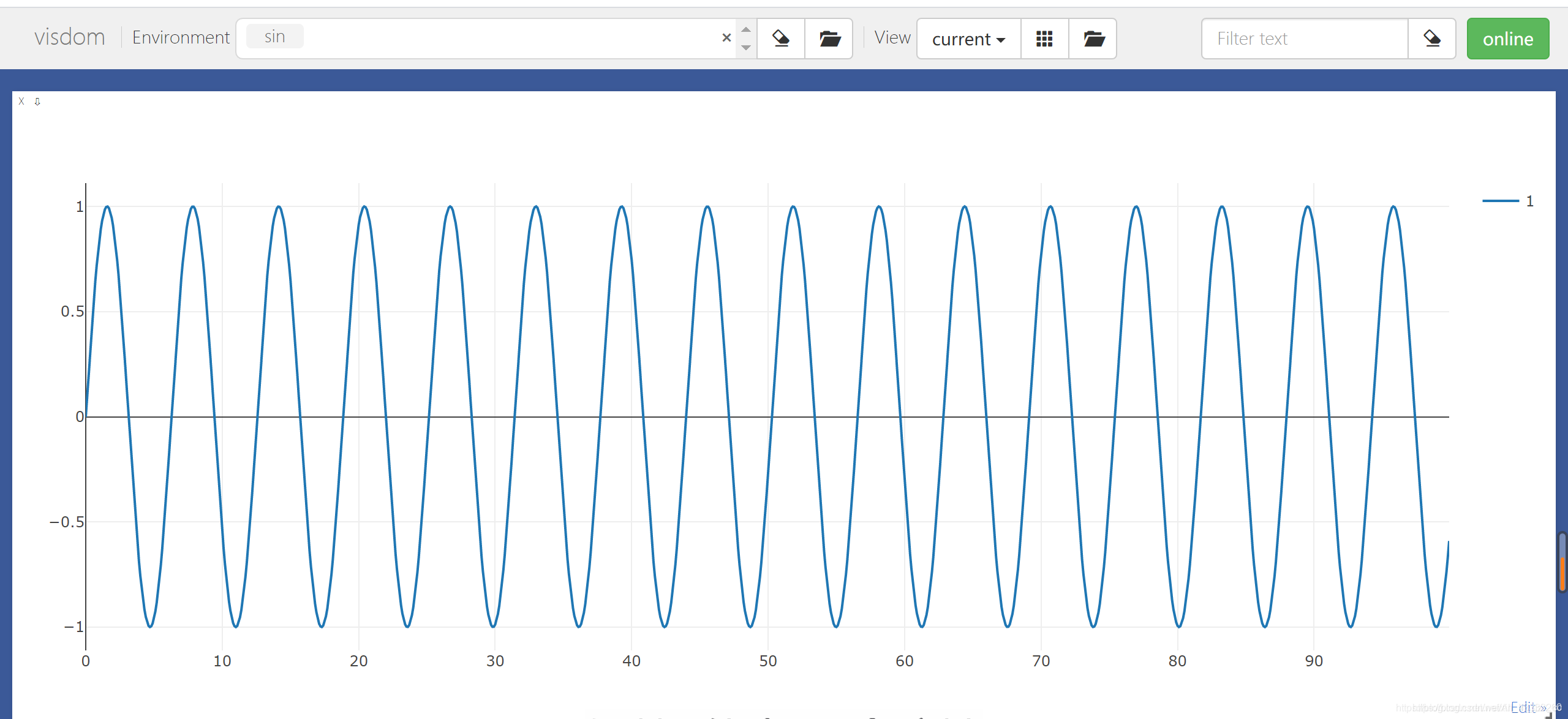
sin(x)曲线
import visdom import torch vis = visdom.Visdom(env='sin') x = torch.arange(0, 100, 0.1) y = torch.sin(x) vis.line(X=x,Y=y,win='sin(x)',opts=dict(showlegend=True))
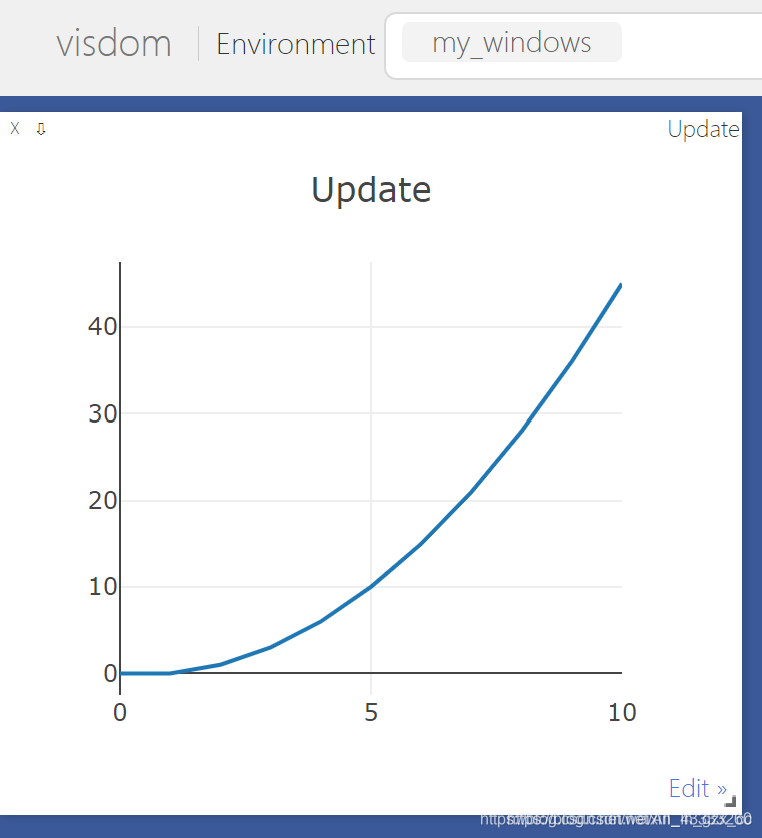
持续更新图表
import visdom
import numpy as np
vis = visdom.Visdom(env='my_windows')
# 利用update更新图像
x = 0
y = 0
my_win = vis.line(X=np.array([x]), Y=np.array([y]), opts=dict(title='Update'))
for i in range(10):
x += 1
y += i
vis.line(X=np.array([x]), Y=np.array([y]), win=my_win, update='append')
使用“append”追加数据,“replace”使用新数据,“remove”用于删除“name”中指定的跟踪。
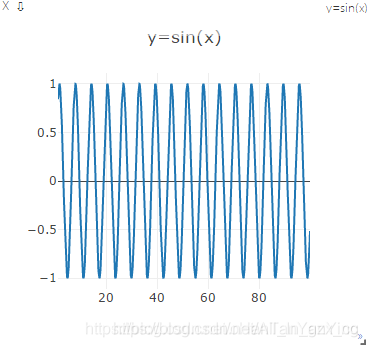
vis.images()
import visdom
import torch
# 新建一个连接客户端
# 指定env = 'test1',默认是'main',注意在浏览器界面做环境的切换
vis = visdom.Visdom(env='test1')
# 绘制正弦函数
x = torch.arange(1, 100, 0.01)
y = torch.sin(x)
vis.line(X=x,Y=y, win='sinx',opts={'title':'y=sin(x)'})
# 绘制36张图片随机的彩色图片
vis.images(torch.randn(36,3,64,64).numpy(),nrow=6, win='imgs',opts={'title':'imgs'})

绘制loss函数的变化趋势
#绘制loss变化趋势,参数一为Y轴的值,参数二为X轴的值,参数三为窗体名称,参数四为表格名称,参数五为更新选项,从第二个点开始可以更新
vis.line(Y=np.array([totalloss.item()]), X=np.array([traintime]),
win=('train_loss'),
opts=dict(title='train_loss'),
update=None if traintime == 0 else 'append'
)
对于Visdom更详细的代码示例详见 链接1
更多介绍详见 链接2
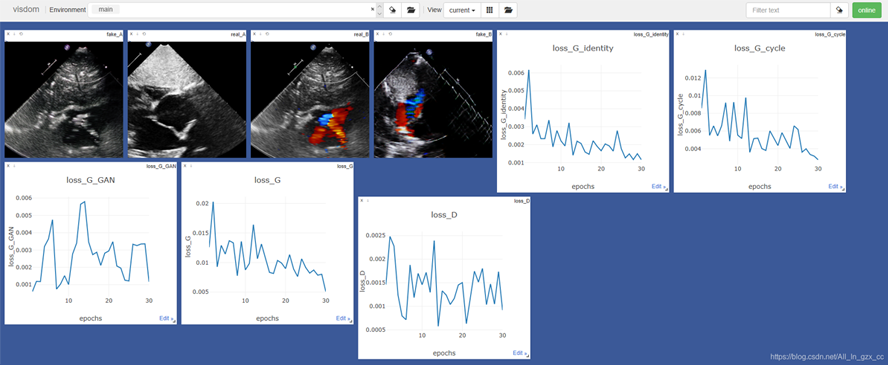
实际代码
此代码出自CycleGAN的 utils.py 里一个实现
# 记录训练日志,显示生成图,画loss曲线 的类
class Logger():
def __init__(self, n_epochs, batches_epoch):
'''
:param n_epochs: 跑多少个epochs
:param batches_epoch: 一个epoch有几个batches
'''
self.viz = Visdom() # 默认env是main函数
self.n_epochs = n_epochs
self.batches_epoch = batches_epoch
self.epoch = 1 # 当前epoch数
self.batch = 1 # 当前batch数
self.prev_time = time.time()
self.mean_period = 0
self.losses = {}
self.loss_windows = {} # 保存loss图的字典集合
self.image_windows = {} # 保存生成图的字典集合
def log(self, losses=None, images=None):
self.mean_period += (time.time() - self.prev_time)
self.prev_time = time.time()
sys.stdout.write('\rEpoch %03d/%03d [%04d/%04d] -- ' % (self.epoch, self.n_epochs, self.batch, self.batches_epoch))
for i, loss_name in enumerate(losses.keys()):
if loss_name not in self.losses:
self.losses[loss_name] = losses[loss_name].data.item() #这里losses[loss_name].data是个tensor(包在值外面的数据结构),要用item方法取值
else:
self.losses[loss_name] = losses[loss_name].data.item()
if (i + 1) == len(losses.keys()):
sys.stdout.write('%s: %.4f -- ' % (loss_name, self.losses[loss_name]/self.batch))
else:
sys.stdout.write('%s: %.4f | ' % (loss_name, self.losses[loss_name]/self.batch))
batches_done = self.batches_epoch * (self.epoch - 1) + self.batch
batches_left = self.batches_epoch * (self.n_epochs - self.epoch) + self.batches_epoch - self.batch
sys.stdout.write('ETA: %s' % (datetime.timedelta(seconds=batches_left*self.mean_period/batches_done)))
# 显示生成图
for image_name, tensor in images.items(): # 字典.items()是以list形式返回键值对
if image_name not in self.image_windows:
self.image_windows[image_name] = self.viz.image(tensor2image(tensor.data), opts={'title':image_name})
else:
self.viz.image(tensor2image(tensor.data), win=self.image_windows[image_name], opts={'title':image_name})
# End of each epoch
if (self.batch % self.batches_epoch) == 0: # 一个epoch结束时
# 绘制loss曲线图
for loss_name, loss in self.losses.items():
if loss_name not in self.loss_windows:
self.loss_windows[loss_name] = self.viz.line(X=np.array([self.epoch]), Y=np.array([loss/self.batch]),
opts={'xlabel':'epochs', 'ylabel':loss_name, 'title':loss_name})
else:
self.viz.line(X=np.array([self.epoch]), Y=np.array([loss/self.batch]), win=self.loss_windows[loss_name], update='append') #update='append'可以使loss图不断更新
# 每个epoch重置一次loss
self.losses[loss_name] = 0.0
# 跑完一个epoch,更新一下下面参数
self.epoch += 1
self.batch = 1
sys.stdout.write('\n')
else:
self.batch += 1
train.py中调用代码是
# 绘画Loss图
logger = Logger(opt.n_epochs, len(dataloader))
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
......
# 记录训练日志
# Progress report (http://localhost:8097) 显示visdom画图的网址
logger.log({'loss_G': loss_G, 'loss_G_identity': (loss_identity_A + loss_identity_B),
'loss_G_GAN': (loss_GAN_A2B + loss_GAN_B2A),
'loss_G_cycle': (loss_cycle_ABA + loss_cycle_BAB), 'loss_D': (loss_D_A + loss_D_B)},
images={'real_A': real_A, 'real_B': real_B, 'fake_A': fake_A, 'fake_B': fake_B})
到此这篇关于python第三方库visdom的使用入门教程的文章就介绍到这了,更多相关python visdom使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python自然语言处理之词干,词形与最大匹配算法代码详解
本文主要对词干提取及词形还原以及最大匹配算法进行了介绍和代码示例,Python实现,下面我们一起看看具体内容. 自然语言处理中一个很重要的操作就是所谓的stemming和lemmatization,二者非常类似.它们是词形规范化的两类重要方式,都能够达到有效归并词形的目的,二者既有联系也有区别. 1.词干提取(stemming) 定义:Stemmingistheprocessforreducinginflected(orsometimesderived)wordstotheirstem,base
-
Python自然语言处理 NLTK 库用法入门教程【经典】
本文实例讲述了Python自然语言处理 NLTK 库用法.分享给大家供大家参考,具体如下: 在这篇文章中,我们将基于 Python 讨论自然语言处理(NLP).本教程将会使用 Python NLTK 库.NLTK 是一个当下流行的,用于自然语言处理的 Python 库. 那么 NLP 到底是什么?学习 NLP 能带来什么好处? 简单的说,自然语言处理( NLP )就是开发能够理解人类语言的应用程序和服务. 我们生活中经常会接触的自然语言处理的应用,包括语音识别,语音翻译,理解句意,理解特定词语的
-

python自然语言处理之字典树知识总结
一.什么是字典树 在自然语言处理中,字符串集合常用字典树存储,这是一种字符串上的树形数据结构.字典树中每条边都对应一个字,从根节点往下的路径构成一个个字符串. 字典树并不直接在节点上存储字符串,而是将词语视作根节点到某节点之间的一条路径,并在终点节点上做个标记(表明到该节点就结束了). 要查询一个单词,指需要顺着这条路径从根节点往下走.如果能走到标记的节点,则说明该字符串在集合中,否则说明不在.下图为字典树结构示例: 如上图所示,每条路径都是一个词汇,且没有子节点就可以判定该条路径结尾了.具体可
-
python爬虫请求库httpx和parsel解析库的使用测评
Python网络爬虫领域两个最新的比较火的工具莫过于httpx和parsel了.httpx号称下一代的新一代的网络请求库,不仅支持requests库的所有操作,还能发送异步请求,为编写异步爬虫提供了便利.parsel最初集成在著名Python爬虫框架Scrapy中,后独立出来成立一个单独的模块,支持XPath选择器, CSS选择器和正则表达式等多种解析提取方式, 据说相比于BeautifulSoup,parsel的解析效率更高. 今天我们就以爬取链家网上的二手房在售房产信息为例,来测评下http
-
能让你轻松的实现自然语言处理的5个Python库
一.前言 自然语言是指人类相互交流的语言,而自然语言处理是将数据以可理解的形式进行预处理,使计算机能够理解的一种方法.简单地说,自然语言处理(NLP)是帮助计算机用自己的语言与人类交流的过程. 自然语言处理是最广泛的研究领域之一.许多大公司在这个领域投资很大.NLP为公司提供了机会,让他们能够根据消费者的情绪和文本很好地了解他们.NLP的一些最佳用例是检测假电子邮件.对假新闻进行分类.情感分析.预测你的下一个单词.自动更正.聊天机器人.个人助理等等. 解决任何NLP任务前要知道的7个术语 标记:
-
用Python进行一些简单的自然语言处理的教程
本月的每月挑战会主题是NLP,我们会在本文帮你开启一种可能:使用pandas和python的自然语言工具包分析你Gmail邮箱中的内容. NLP-风格的项目充满无限可能: 情感分析是对诸如在线评论.社交媒体等情感内容的测度.举例来说,关于某个话题的tweets趋向于正面还是负面的意见?一个新闻网站涵盖的主题,是使用了更正面/负面的词语,还是经常与某些情绪相关的词语?这个"正面"的Yelp点评不是很讽刺么?(祝最后去的那位好运!) 分析语言在文学中的使用,进而衡量词汇或者写作风格随时间/
-
Python编程使用NLTK进行自然语言处理详解
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向.自然语言工具箱(NLTK,NaturalLanguageToolkit)是一个基于Python语言的类库,它也是当前最为流行的自然语言编程与开发工具.在进行自然语言处理研究和应用时,恰当利用NLTK中提供的函数可以大幅度地提高效率.本文就将通过一些实例来向读者介绍NLTK的使用. NLTK NaturalLanguageToolkit,自然语言处理工具包,在NLP领域中,最常使用的一个Python库. NLTK是一个开源的项目,包含:P
-
Python自动安装第三方库的小技巧(pip使用详解)
大家好,我是才哥. 最近周末也加班了,害- 有刚接触python的粉丝同学在运行此前<>的完整代码遇到以下问题,然后- 好吧,今天我们就专门介绍一下Python安装第三方库的一些小技巧,其中还包含自动安装的方法哈. 1. pip在线安装 在cmd命令行模式下,通过pip install 第三方库名称的形式,直接进行第三方库的安装. 我们以安装plotly为例,安装表现如下: pip install plotly 如果需要安装的第三方库已经存在,我们执行安装命令的时候会提示其存在且展示库安装的位
-
Python自然语言处理之切分算法详解
一.前言 我们需要分析某句话,就必须检测该条语句中的词语. 一般来说,一句话肯定包含多个词语,它们互相重叠,具体输出哪一个由自然语言的切分算法决定.常用的切分算法有完全切分.正向最长匹配.逆向最长匹配以及双向最长匹配. 本篇博文将一一介绍这些常用的切分算法. 二.完全切分 完全切分是指,找出一段文本中的所有单词. 不考虑效率的话,完全切分算法其实非常简单.只要遍历文本中的连续序列,查询该序列是否在词典中即可.上一篇我们获取了词典的所有词语dic,这里我们直接用代码遍历某段文本,完全切分出所有的词
-
Python文件名的匹配之clob库
一.前言 既然在Pathlib库中提到了glob()函数,那么我们就专门用一篇内容讲解文件名的匹配.其实我们有专门的一个文件名匹配库就叫:glob. 不过,glob库的API非常小,但是仅仅应用于文件名的匹配绰绰有余.只要是在实际的项目中需要过滤,或者匹配一组文件,都可以使用该库进行操作. 二.通配符 星号(*) 话不多说,下面我们使用通配符来匹配文件名,示例如下: import glob for name in sorted(glob.glob('text/*')): print(name)
-
Python的文本常量与字符串模板string库
一.前言 在程序中,有很多高效率的字符串处理方式,如果开发者能够完全掌握这些高效的字符串处理,往往在开发者也能事半功倍.比如针对于字符串的处理,也是自然语言处理的基础知识. 而python3中,处理字符串的库为:string.本篇将详细介绍各种字符串的高效处理方式. 二.首字母大写 对于英文单词组成的字符串来说,很多时候,我们需要对英文的首字母进行大写的变更.如果没有了解其高效率的函数,一般我们都通过循环,判断空格,取空格后一位的字母,判断其在ASCII中的编码后,取其大写替换掉该位置的字符串.