python读取csv文件指定行的2种方法详解
csv是Comma-Separated Values的缩写,是用文本文件形式储存的表格数据,比如如下的表格
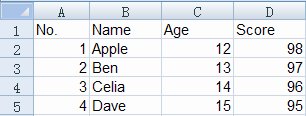
就可以存储为csv文件,文件内容是:
No.,Name,Age,Score
1,Apple,12,98
2,Ben,13,97
3,Celia,14,96
4,Dave,15,95
假设上述csv文件保存为"A.csv",如何用Python像操作Excel一样提取其中的一行,也就是一条记录,利用Python自带的csv模块,有2种方法可以实现:
方法一:reader
第一种方法使用reader函数,接收一个可迭代的对象(比如csv文件),能返回一个生成器,就可以从其中解析出csv的内容:比如下面的代码可以读取csv的全部内容,以行为单位:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.reader(csvfile)
rows = [row for row in reader]
print rows
得到:
[['No.', 'Name', 'Age', 'Score'],
['1', 'Apple', '12', '98'],
['2', 'Ben', '13', '97'],
['3', 'Celia', '14', '96'],
['4', 'Dave', '15', '95']]
要提取其中第二行,可以用下面的代码:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.reader(csvfile)
for i,rows in enumerate(reader):
if i == 2:
row = rows
print row
得到:
['2', 'Ben', '13', '97']
这种方法是通用的方法,要事先知道行号,比如Ben的记录在第2行,而不能根据'Ben'这个名字查询。这时可以采用第二种方法:
方法二:DictReader
第二种方法是使用DictReader,和reader函数类似,接收一个可迭代的对象,能返回一个生成器,但是返回的每一个单元格都放在一个字典的值内,而这个字典的键则是这个单元格的标题(即列头)。用下面的代码可以看到DictReader的结构:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.DictReader(csvfile)
rows = [row for row in reader]
print rows
得到:
[{'Age': '12', 'No.': '1', 'Score': '98', 'Name': 'Apple'},
{'Age': '13', 'No.': '2', 'Score': '97', 'Name': 'Ben'},
{'Age': '14', 'No.': '3', 'Score': '96', 'Name': 'Celia'},
{'Age': '15', 'No.': '4', 'Score': '95', 'Name': 'Dave'}]
如果我们想用DictReader读取csv的某一列,就可以用列的标题查询:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
if row['Name']=='Ben':
print row
就得到:
{'Age': '13', 'No.': '2', 'Score': '97', 'Name': 'Ben'}
可见,DictReader很适合读取csv的的行(记录)。
相关推荐
-
使用python的pandas库读取csv文件保存至mysql数据库
第一:pandas.read_csv读取本地csv文件为数据框形式 data=pd.read_csv('G:\data_operation\python_book\chapter5\\sales.csv') 第二:如果存在日期格式数据,利用pandas.to_datatime()改变类型 data.iloc[:,1]=pd.to_datetime(data.iloc[:,1]) 注意:=号,这样在原始的数据框中,改变了列的类型 第三:查看列类型 print(data.dtypes) 第四:方法一
-

Python读取csv文件实例解析
这篇文章主要介绍了Python读取csv文件实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 创建一个csv文件,命名为data.csv,文本内容如下: root,123456,login successfully root,wrong,wrong password wrong,123456,nonexistent username ,123456,username is null root,,password is null 使用Exc
-
Python读取csv文件分隔符设置方法
Windows下的分隔符默认的是逗号,而MAC的分隔符是分号.拿到一份用分号分割的CSV文件,在Win下是无法正确读取的,因为CSV模块默认调用的是Excel的规则. 所以我们在读取文件的时候需要添加分割符变量. import csv import os cwd = os.getcwd() print ("Current folder is %s" % (cwd) ) csvfile = open( cwd + '\data\eclipse\change-metrics.csv','r
-
python3读取csv文件任意行列代码实例
这篇文章主要介绍了python3读取csv文件任意行列代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 读取每一行 reader = csv.reader(f) 此时reader返回的值是csv文件中每行的列表,将每行读取的值作为列表返回 #读取每一行 filename='D:\\file_information1.csv' import csv with open(filename,newline = '',encoding = 'ut
-
使用python读取csv文件快速插入数据库的实例
如下所示: # -*- coding:utf-8 -*- # auth:ckf # date:20170703 import pandas as pd import cStringIO import warnings from sqlalchemy import create_engine import sys reload(sys) sys.setdefaultencoding('utf8') warnings.filterwarnings('ignore') engine = create_
-
Python Pandas批量读取csv文件到dataframe的方法
PYTHON Pandas批量读取csv文件到DATAFRAME 首先使用glob.glob获得文件路径.然后定义一个列表,读取文件后再使用concat合并读取到的数据. #读取数据 import pandas as pd import numpy as np import glob,os path=r'e:\tj\month\fx1806' file=glob.glob(os.path.join(path, "zq*.xls")) print(file) dl= [] for f i
-
python读取csv文件并把文件放入一个list中的实例讲解
如下所示: #coding=utf8 ''' 读取CSV文件,把csv文件放在一份list中. ''' import csv class readCSV(object): def __init__(self,path="Demo.csv"): #创建一个属性用来保存要操作CSV的文件 self.path=path try: #打开一个csv文件,并赋予读的权限 self.csvHand=open(self.path,"r") #调用csv的reader函数读取csv
-
python读取csv文件示例(python操作csv)
复制代码 代码如下: import csvfor line in open("test.csv"):name,age,birthday = line.split(",")name = name.strip(' \t\r\n');age = age.strip(' \t\r\n');birthday = birthday.strip(' \t\r\n'); print (name + '\t' + age + '\t' + birthday) csv文件 复制代码 代
-
python读取csv文件指定行的2种方法详解
csv是Comma-Separated Values的缩写,是用文本文件形式储存的表格数据,比如如下的表格 就可以存储为csv文件,文件内容是: No.,Name,Age,Score 1,Apple,12,98 2,Ben,13,97 3,Celia,14,96 4,Dave,15,95 假设上述csv文件保存为"A.csv",如何用Python像操作Excel一样提取其中的一行,也就是一条记录,利用Python自带的csv模块,有2种方法可以实现: 方法一:reader 第一种方法使
-
python3读取文件指定行的三种方法
行遍历实现 在python中如果要将一个文件完全加载到内存中,通过file.readlines()即可,但是在文件占用较高时,我们是无法完整的将文件加载到内存中的,这时候就需要用到python的file.readline()进行迭代式的逐行读取: filename = 'hello.txt' with open(filename, 'r') as file: line = file.readline() counts = 1 while line: if counts >= 50000000:
-
Python实现从文件中加载数据的方法详解
前几篇都是手动录入或随机函数产生的数据.实际有许多类型的文件,以及许多方法,用它们从文件中提取数据来图形化. 比如之前python基础(12)介绍打开文件的方式,可直接读取文件中的数据,扩大了我们的数据来源.下面,将展示几种方法. 我们将使用内置的 csv 模块加载CSV文件 CSV文件是一种特殊的文本文件,文件中的数据以逗号作为分隔符,很适合进行数据的解析.先用excle建立如下表格和数据,另存为csv格式文件,放到代码目录下. 包含在Python标准库中自带CSV 模块,我们只需要impor
-
Python读取CSV文件并进行数据可视化绘图
介绍:文件 sitka_weather_07-2018_simple.csv是阿拉斯加州锡特卡2018年1月1日的天气数据,其中包含当天的最高温度和最低温度.数据文件存储与data文件夹下,接下来用Python读取该文件数据,再基于数据进行可视化绘图.(详细细节请看代码注释) sitka_highs.py import csv # 导入csv模块 from datetime import datetime import matplotlib.pyplot as plt filename = 'd
-
Python如何获取文件指定行的内容
linecache, 可以用它方便地获取某一文件某一行的内容.而且它也被 traceback 模块用来获取相关源码信息来展示. 用法很简单: >>> import linecache >>> linecache.getline('/etc/passwd', 4) 'sys:x:3:3:sys:/dev:/bin/sh\n' linecache.getline 第一参数是文件名,第二个参数是行编号.如果文件名不能直接找到的话,会从 sys.path 里找. 如果请求的行数
-
利用Python读取CSV文件并计算某一列的均值和方差
近日需要对excel的csv文件进行处理,求取某银行历年股价的均值方差等一系列数据 文件的构成很简单,部分如下所示 总共有接近七千行数据,主要的工作就是将其中的股价数据提取出来,放入一个数组之中,然后利用numpy模块即可求出需要的数据. 这里利用了csv模块来对文件进行处理,最终实现的代码如下: import csv import numpy as np with open('pingan_stock.csv') as csv_file: row = csv.reader(csv_file,
-
Python读取csv文件做K-means分析详情
目录 1.运行环境及数据 2.基于时间序列的分析2D 2.1 2000行数据结果展示 2.2 6950行数据结果展示 2.3 300M,约105万行数据结果展示 3.经纬度高程三维坐标分类显示3D-空间点聚类 3.1 2000行数据结果显示 3.2 300M的CSV数据计算显示效果 1.运行环境及数据 Python3.7.PyCharm Community Edition 2021.1.1,win10系统. 使用的库:matplotlib.numpy.sklearn.pandas等 数据:CSV
-
Python读取CSV文件并计算某一列的均值和方差
近日需要对excel的csv文件进行处理,求取某银行历年股价的均值方差等一系列数据 文件的构成很简单,部分如下所示 总共有接近七千行数据,主要的工作就是将其中的股价数据提取出来,放入一个数组之中,然后利用numpy模块即可求出需要的数据. 这里利用了csv模块来对文件进行处理,最终实现的代码如下: import csv import numpy as np with open('pingan_stock.csv') as csv_file: row = csv.reader(csv_file,
-
python 读取.csv文件数据到数组(矩阵)的实例讲解
利用numpy库 (缺点:有缺失值就无法读取) 读: import numpy my_matrix = numpy.loadtxt(open("1.csv","rb"),delimiter=",",skiprows=0) 写: numpy.savetxt('2.csv', my_matrix, delimiter = ',') 可能遇到的问题: SyntaxError: (unicode error) 'unicodeescape' codec