彻底搞懂 python 中文乱码问题(深入分析)
前言
曾几何时 Python 中文乱码的问题困扰了我很多很多年,每次出现中文乱码都要去网上搜索答案,虽然解决了当时遇到的问题但下次出现乱码的时候又会懵逼,究其原因还是知其然不知其所以然。现在有的小伙伴为了躲避中文乱码的问题甚至代码中不使用中文,注释和提示都用英文,我曾经也这样干过,但这并不是解决问题,而是逃避问题,今天我们一起彻底解决 Python 中文乱码的问题。
基础知识ASCII
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物。他们看到8个开关状态是好的,于是他们把这称为”字节“。再后来,他们又做了一些可以处理这些字节的机器,机器开动了,可以用字节来组合出很多状态,状态开始变来变去。他们看到这样是好的,于是它们就这机器称为”计算机“。开始计算机只在美国用。八位的字节一共可以组合出256(2的8次方)种不同的状态。 他们把其中的编号从0开始的32种状态分别规定了特殊的用途,一但终端、打印机遇上约定好的这些字节被传过来时,就要做一些约定的动作。遇上0×10, 终端就换行,遇上0×07, 终端就向人们嘟嘟叫,例好遇上0x1b, 打印机就打印反白的字,或者终端就用彩色显示字母。他们看到这样很好,于是就把这些0×20以下的字节状态称为”控制码”。他们又把所有的空 格、标点符号、数字、大小写字母分别用连续的字节状态表示,一直编到了第127号,这样计算机就可以用不同字节来存储英语的文字了。大家看到这样,都感觉很好,于是大家都把这个方案叫做 ANSI 的”Ascii”编码(American Standard Code for Information Interchange,美国信息互换标准代码)。当时世界上所有的计算机都用同样的ASCII方案来保存英文文字。
GB2312
后来,就像建造巴比伦塔一样,世界各地的都开始使用计算机,但是很多国家用的不是英文,他们的字母里有许多是ASCII里没有的,为了可以在计算机保存他们的文字,他们决定采用 127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用下到的横线、竖线、交叉等形状,一直把序号编到了最后一个状态255。从128 到255这一页的字符集被称”扩展字符集“。从此之后,贪婪的人类再没有新的状态可以用了,美帝国主义可能没有想到还有第三世界国家的人们也希望可以用到计算机吧!等中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存呢。
但是这难不倒智慧的中国人民,我们不客气地把那些127号之后的奇异符号们直接取消掉, 规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角”字符,而原来在127号以下的那些就叫”半角”字符了。 中国人民看到这样很不错,于是就把这种汉字方案叫做 “GB2312“。GB2312 是对 ASCII 的中文扩展。
GBK
但是中国的汉字太多了,我们很快就就发现有许多人的人名没有办法在这里打出来,特别是某些很会麻烦别人的国家领导人。于是我们不得不继续把 GB2312 没有用到的码位找出来老实不客气地用上。 后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。 后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族的字,GBK 扩成了 GB18030。
从此之后,中华民族的文化就可以在计算机时代中传承了。 中国的程序员们看到这一系列汉字编码的标准是好的,于是通称他们叫做 “DBCS“(Double Byte Charecter Set 双字节字符集)。在DBCS系列标准里,最大的特点是两字节长的汉字字符和一字节长的英文字符并存于同一套编码方案里,因此他们写的程序为了支持中处理,必须要注意字串里的每一个字节的值,如果这个值是大于127的,那么就认为一个双字节字符集里的字符出现了。那时候凡是受过加持,会编程的计算机僧侣们都要每天念下面这个咒语数百遍: “一个汉字算两个英文字符!一个汉字算两个英文字符……”
因为当时各个国家都像中国这样搞出一套自己的编码标准,结果互相之间谁也不懂谁的编码,谁也不支持别人的编码,连大陆和台湾这样只相隔了150海里,使用着同一种语言的兄弟地区,也分别采用了不同的 DBCS 编码方案——当时的中国人想让电脑显示汉字,就必须装上一个”汉字系统”,专门用来处理汉字的显示、输入的问题,但是那个台湾的愚昧封建人士写的算命程序就必须加装另一套支持 BIG5 编码的什么”倚天汉字系统”才可以用,装错了字符系统,显示就会乱了套!这怎么办?而且世界民族之林中还有那些一时用不上电脑的穷苦人民,他们的文字又怎么办? 真是计算机的巴比伦塔命题啊!
UNICODE
正在这时,大天使加百列及时出现了,一个叫 ISO(国际标谁化组织)的国际组织决定着手解决这个问题。他们采用的方法很简单:废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号的编码!他们打算叫它”Universal Multiple-Octet Coded Character Set”,简称 UCS, 俗称 “unicode“。unicode开始制订时,计算机的存储器容量极大地发展了,空间再也不成为问题了。于是 ISO 就直接规定必须用两个字节,也就是16位来统一表示所有的字符,对于ASCII里的那些“半角”字符,unicode 包持其原编码不变,只是将其长度由原来的8位扩展为16位,而其他文化和语言的字符则全部重新统一编码。
由于”半角”英文符号只需要用到低8位,所以其高8位永远是0,因此这种大气的方案在保存英文文本时会多浪费一倍的空间。这时候,从旧社会里走过来的程序员开始发现一个奇怪的现象:他们的 strlen 函数靠不住了,一个汉字不再是相当于两个字符了,而是一个!是的,从 unicode 开始,无论是半角的英文字母,还是全角的汉字,它们都是统一的”一个字符“!同时,也都是统一的”两个字节“,请注意”字符”和”字节”两个术语的不同,“字节”是一个8位的物理存贮单元,而“字符”则是一个文化相关的符号。在 unicode 中,一个字符就是两个字节。一个汉字算两个英文字符的时代已经快过去了。
unicode 同样也不完美,这里就有两个的问题,一个是,如何才能区别 unicode 和 ASCII?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储空间来说是极大的浪费,文本文件的大小会因此大出二三倍,这是难以接受的。
UTF-8
unicode 在很长一段时间内无法推广,直到互联网的出现,为解决 unicode 如何在网络上传输的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义,UTF-8就是每次8个位传输数据,而 UTF-16 就是每次16个位。UTF-8就是在互联网上使用最广的一种 unicode 的实现方式,这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在 ASCII 码的范围时,就用一个字节表示,保留了 ASCII 字符一个字节的编码做为它的一部分,注意的是 unicode 一个中文字符占2个字节,而UTF-8一个中文字符占3个字节)。从 unicode 到 uft-8 并不是直接的对应,而是要过一些算法和规则来转换。
看到这里你是彻底懵逼还是恍然大悟,如果是彻底懵逼建议你再多看几次,温故而知新,如果恍然大悟的话我们就接着往下看。
中文乱码实例讲解
介绍完了基础知识,我们来说说 Python 中是如何存储字符的,先来看一个乱码的例子。新建一个 demo.py 文件,文件存储格式为utf-8文件中内容如下。
s = "中文"
print s
在 cmd 中运行 python demo.py,什么,我只是想打印中文两个字居然给我报错,简直不可理喻啊!

赶紧打开 python 自带的 idle 试试看,一点问题都没有啊,这是为什么呢?
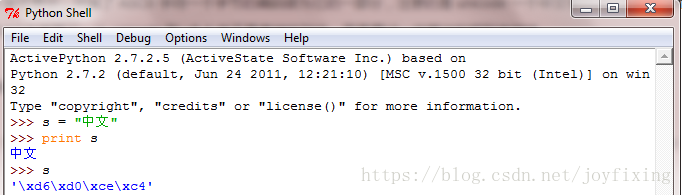
回头好好看看 cmd 下报的错误Non-ASCII character '\xe4' in file demo.py on line 1, but no encoding declared;,翻译过来就是 在 demo.py 文件的第 1 行有非 ASCII 字符 ‘\xe4',而且没有声明编码,从上面基础知识可知,ASCII 编码是不能表示汉字中文的,demo.py 文件第一行有中文两个汉字,而 demo.py 文件存储格式为utf-8,所以中文两个汉字在文件中存储的时候是以 utf-8编码存储的,查看 demo.py 文件 16 进制可以看到中文 存储的是 \xe4\xb8\xad\xe6\x96\x87。

16 进制查看用的是 notepad++ 自带的 HEX-Editor 插件,另外函数 repr也能显示原始字符串,如下。
# encoding:utf-8 import sys print sys.getdefaultencoding() s = "中文" print repr(s)
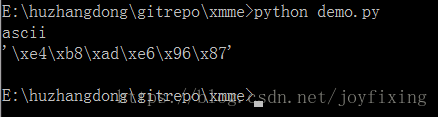
sys.getdefaultencoding()读取 python 默认编码是 ASCII,而 ASCII 是不认识 \xe4的,所以会报错Non-ASCII character '\xe4' in file demo.py on line 1, but no encoding declared;,此时只要在 demo.py 文件头加上 # encoding:utf-8就可以了,虽然是注释,但 python 看到这句话就知道了接下来应该用utf-8编码了,而 demo.py 存储时也是utf-8的,所以就正常了。
# encoding:utf-8 s = "中文" print s
编码声明注释写成# -*- coding: utf-8 -*-也是可以的,只要满足正则表达式^[ \t\v]*#.*?coding[:=][ \t]*([-_.a-zA-Z0-9]+)就OK。
我们再次在 cmd 下运行 python demo.py 试试看。

啥,啥,啥,说好的显示中文呢?这不是逗我吗?去 python idle 下试试看。

为什么同样的文件在 python idle 中却正常呢?肯定是 cmd 有问题,是的,我也是这样想的,那我试着在 cmd 下进入 python 交互模式输出中文看看,我去居然 cmd 下也是可以正常输出 中文的,相信看到这里小伙伴们都已经晕了。
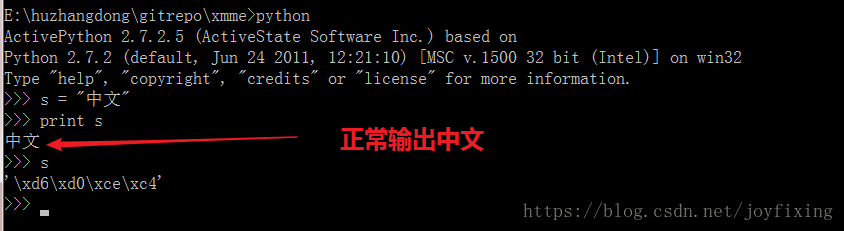
别急,听我慢慢分析。其实当在 cmd 或者 idle 中打印字符的时候已经和文件编码方式没有关系了,此时起作用的是输出环境也就是 cmd 或者 idle 的编码方式有关,查看 cmd 的编码命令是 chcp,返回 936,去网上查找可知 936 代表 GBK 编码,这下我们大概知道什么原因了,demo.py 文件存储和编码声明都是utf-8,但是 cmd 显示编码是 GBK,而将中文的utf-8 编码 \xe4\xb8\xad\xe6\x96\x87 强制转换为 GBK 就会乱码了,GBK 是两个字节存储一个中文字符,所以 \xe4\xb8\xad\xe6\x96\x87 会解码成三个字,很不幸这三个字涓枃不是常用字也不是我们想要的字符,所以就认为是乱码了。为什么在 cmd 下进入 Python 交互式命令行可以呢,这是因为当在 python 交互式命令行输入s = "中文"时,中文这两个汉字其实是以 GBK 编码存储的,cmd 默认编码是 GBK ,不信看s打印\xd6\xd0\xce\xc4,这就是GBK编码方式存储,而utf-8编码方式存储同样的中文为\xe4\xb8\xad\xe6\x96\x87。
下面告诉大家怎么解决在 cmd 下执行文件正确输出中文问题。
1、demo.py 文件和编码声明都为 GBK
这种方法比较笨,就是把 demo.py 文件改为 GBK 存储,而且编码声明也是GBK,个人不推荐。
# encoding:gbk s = "中文" print s print repr(s)

2、中文用 unicode 表示
只要在中文前面加上个小u标记,后面的中文就用 unicode 存储了。
# encoding:utf-8 s = u"中文" print s print repr(s)
cmd 下是可以打印 unicode 字符的,如下。

3、把中文强制转换为GBK或者unicode编码
强制转换为unicode编码,在 Python 中编码是可以互相转换的,比如从utf-8转换为gbk,不同编码之间不能直接转换,需要通过unicode字符集中间过渡下,从上面基础知识可知unicode是一种字符集,不属于编码,而utf-8是具体实现unicode思想的一种编码。utf-8转换为unicode是一种解码过程,通过decode可从utf-8解码成unicode。
# encoding:utf-8
s = "中文"
u = s.decode('utf-8')
print u
print type(u)
print repr(u)

强制转换为gbk编码,上一步已经从utf-8转换为unicode了,从unicode是编码的过程,通过encode实现。
# encoding:utf-8
s = "中文"
u = s.decode('utf-8')
g = u.encode('gbk')
print g
print type(g)
print repr(g)

总结
windows cmd 窗口下不支持utf-8,想要显示中文必须转换为gbk或者unicode,而 Python idle 中这三种编码都支持。中文乱码的出现都是由于编码不一致导致的,存储的是用utf-8,打印的时候用gbk就会乱码了,所有要保证不乱码尽量保持统一,建议全部使用unicode。
decode 解码
从其它编码变成unicode叫解码,解码用的方法是decode,第一个参数为被解码的字符串原始编码格式,如果写错了也会报错。比如 s 是utf-8,用gbk去解码就会报错。
# encoding:utf-8
s = "中文"
u = s.decode('gbk')
print u
print repr(u)

小提示
在 Python idle 和 cmd 下直接输入 s = "中文"会以 gbk 编码的,如果在文件中输入 s = "中文"且文件存储格式为utf-8,那么 s 是以utf-8编码存储的,有点不一样曾经踩过坑,及时 Python idle 成功了文件运行的时候也可能失败。
encode 编码
不可以直接从utf-8转换为gbk,必须经过unicode中间转换,这点很重要,被编码的原始字符串一定要为unicode,否则会报错。
raw_input
raw_input 是获取用户输入值的,获取到的用户输入值和当前运行环境编码有关,比如 cmd 下默认编码是 gbk,那么输入的汉字就是以gbk编码,而不管 demo.py 文件编码格式和编码声明。
# encoding:utf-8
s = raw_input("input something: ")
print s
print type(s)
print repr(s)
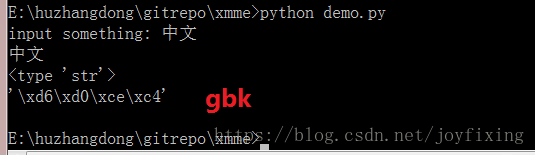
GBK 编码一个汉字两个字节,UTF-8 一个汉字通常3个字节。
细心的朋友已经注意了,raw_input的提示语我用的是英文,那改成中文看看,果真出现乱码了。
# encoding:utf-8
s = raw_input("请输入中文汉字:")
print s
print type(s)
print repr(s)
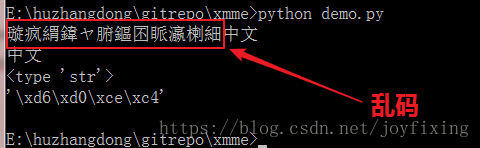
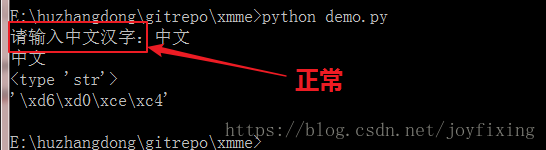
怎么办呢?把提示字符串强制为gbk编码就好,unicode和utf-8都不可以。
# encoding:utf-8
s = raw_input(u"请输入中文汉字:".encode('gbk'))
print s
print type(s)
print repr(s)
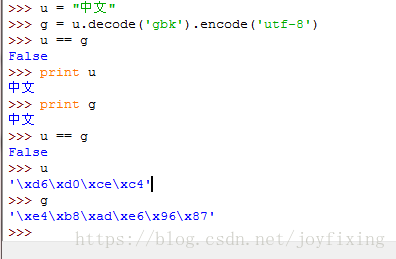
相等陷阱
“中文”这两个字符串用不同的编码存储是不一样的,utf-8编码和gbk编码存储的“中文”都不一样。
总结
一口气说了这么多,不知道你们看懂没?想要不乱码,记住以下5点法则就好。
1、文件存储为utf-8格式,编码声明为utf-8,# encoding:utf-8
2、出现汉字的地方前面加 u
3、不同编码之间不能直接转换,要经过unicode中间跳转
4、cmd 下不支持utf-8编码
5、raw_input提示字符串只能为gbk编码
以上就是彻底搞懂 python 中文乱码问题(深入分析)的详细内容,更多关于python 中文乱码的资料请关注我们其它相关文章!
相关推荐
-
python查询mysql中文乱码问题
问题: python2.7 查询或者插入中文数据在mysql中的时候出现中文乱码 --- 可能情况: 1.mysql数据库各项没有设置编码,默认为'latin' 2.使用MySQL.connect的时候没有设置默认编码 3.没有设置python的编码,python2.7默认为'ascii' 4.没有解码 --- 解决方法: 1.设置mysql的编码 ubuntu执行下列语句: ** sudo vim /etc/mysql/my.cnf ** 然后在里面插入语句: [client] default
-

python中Pycharm 输出中文或打印中文乱码现象的解决办法
1. 确保文件开头加上以下代码: # -*- coding:utf-8 -*- 还可以加上 import sys reload(sys) sys.setdefaultencoding('utf-8') 确保以下. 如果还是没有解决中文乱码,那么进行方法2. 2. 进入setting 单击打开,单击 修改完成后,结果如下 单击"ok". 成功. 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们.
-
解决python2.7 查询mysql时出现中文乱码
问题: python2.7 查询或者插入中文数据在mysql中的时候出现中文乱码 --- 可能情况: 1.mysql数据库各项没有设置编码,默认为'latin' 2.使用MySQL.connect的时候没有设置默认编码 3.没有设置python的编码,python2.7默认为'ascii' 4.没有解码 --- 解决方法: 1.设置mysql的编码 ubuntu执行下列语句: ** sudo vim /etc/mysql/my.cnf ** 然后在里面插入语句: [client] default
-
解决vscode python print 输出窗口中文乱码的问题
一.搭建 python 环境 在 VSC 中点击 F1 键,弹出控制台,输入 ext install 界面左侧弹出扩展窗格,输入python,确认,开始搜索 下载发布者为Don Jayamanne 的 Python 插件 (下载过程中不要切换窗口,不要做其他任何操作,否则会中断下载,下载时间略长,耐心等待) 安装完毕 "文件"-"首选项"-"用户设置",打开用户配置文件settings.json,再其中大括号内输入计算机中 python.exe
-
python 采集中文乱码问题的完美解决方法
近几日遇到采集某网页的时候大部分网页OK,少部分网页出现乱码的问题,调试了几日,终于发现了是含有一些非法字符造成的..特此记录 1. 在正常情况下..可以用 import chardet thischarset = chardet.detect(strs)["encoding"] 来获取该文件或页面的编码方式 或直接抓取页面的charset = xxxx 来获取 2. 遇到内容中有特殊字符时指定的编码一样会造成乱码..即内容中非法字符造成的,可以采用编码忽略非法字符的方式来处理. st
-
解决Python2.7读写文件中的中文乱码问题
Python2.7对于中文编码的问题处理的并不好,这几天在爬数据的时候经常会遇到中文的编码问题.但是本人对编码原理不了解,也没时间深究其中的原理.在此仅从应用的角度做一下总结, 1.设置默认编码 在Python代码中的任何地方出现中文,编译时都会报错,这时可以在代码的首行添加相应说明,明确utf-8编码格式,可以解决一般情况下的中文报错.当然,编程中遇到具体问题还需具体分析啦. #encoding:utf-8 或者 # -*- coding: utf-8 -*- import sys reloa
-
Python中matplotlib中文乱码解决办法
Matplotlib是Python的一个很好的绘图包,但是其本身并不支持中文(貌似其默认配置中没有中文字体),所以如果绘图中出现了中文,就会出现乱码. matplotlib绘制图像有中文标注时会有乱码问题. 实例代码: import matplotlib import matplotlib.pyplot as plt #定义文本框和箭头格式 decisionNode =dict(boxstyle="sawtooth",fc="0.8") leafNode=dict(
-
wxPython窗口中文乱码解决方法
本文实例讲述了wxPython窗口中文乱码解决方法,分享给大家供大家参考.具体方法如下: 文件保存为 utf-8 文件开头添加 # -*- coding: utf-8 -*- 在有中文字符串前加u或U,例如:u"我的网站:http://www.jb51.net" 示例如下: 复制代码 代码如下: # -*- coding: utf-8 -*- import wx class App(wx.App): def OnInit(self): frame = wx.
-
python 中文乱码问题深入分析
在本文中,以'哈'来解释作示例解释所有的问题,"哈"的各种编码如下: 1. UNICODE (UTF8-16),C854: 2. UTF-8,E59388: 3. GBK,B9FE. 一.python中的str和unicode 一直以来,python中的中文编码就是一个极为头大的问题,经常抛出编码转换的异常,python中的str和unicode到底是一个什么东西呢? 在python中提到unicode,一般指的是unicode对象,例如'哈哈'的unicode对象为 u'\u54c8
-
python中文乱码的解决方法
乱码原因:源码文件的编码格式为utf-8,但是window的本地默认编码是gbk,所以在控制台直接打印utf-8的字符串当然是乱码了! 解决方法:1.print mystr.decode('utf-8').encode('gbk')2.比较通用的方法: 复制代码 代码如下: import systype = sys.getfilesystemencoding()print mystr.decode('utf-8').encode(type)
-
python sqlobject(mysql)中文乱码解决方法
UnicodeEncodeError: 'latin-1' codec can't encode characters in position: 找了一天终于搞明白了,默认情况下,mysql连接的编码是latin-1,你需要指定使用什么编码方式: connectionForURI(mysql://user:password@localhost:3306/eflow?use_unicode=1&charset=utf8) Python mysql 中文乱码 的解决方法,有需要的朋友不妨看看. 先来
-
解决Python网页爬虫之中文乱码问题
Python是个好工具,但是也有其固有的一些缺点.最近在学习网页爬虫时就遇到了这样一种问题,中文网站爬取下来的内容往往中文显示乱码.看过我之前博客的同学可能知道,之前爬取的一个学校网页就出现了这个问题,但是当时并没有解决,这着实成了我一个心病.这不,刚刚一解决就将这个方法公布与众,大家一同分享. 首先,我说一下Python中文乱码的原因,Python中文乱码是由于Python在解析网页时默认用Unicode去解析,而大多数网站是utf-8格式的,并且解析出来之后,python竟然再以Unicod
-
Python实现的json文件读取及中文乱码显示问题解决方法
本文实例讲述了Python实现的json文件读取及中文乱码显示问题解决方法.分享给大家供大家参考,具体如下: city.json文件的内容如下: { "cities": [ { "city": "北京", "cityid": "101010100" }, { "city": "上海", "cityid": "101020100"
-
解决python使用open打开文件中文乱码的问题
代码如下: 先在D盘下新建一个html文档,然后在里面输入含有中文的Html字符如下图,然后我们首先使用中文格式对读取的字符进行解码再用utf-8的模式对字符进行进行编码,然后就能正确输出中文字符 # -*- coding: UTF-8 -*- file1 = open("D:/1.html", mode='rb+') data = file1.read().decode('gbk').encode('utf-8') print data 以上这篇解决python使用open打开文件中
-
Python2.x中文乱码问题解决方法
Python中乱码问题是一个很头痛的问题. 在Python3中,对中文进行了全面的支持,但在Python2.x中需要进行相关的设置才能使用中文.否则会出现乱码 [问题原因] 在Python2.x中主要是字符编码的问题,处理不好的话,会导致乱码.Python默认采取的ASCII编码,字母.标点和其他字符只使用一个字节来表示,但对于中文字符来说,一个字节满足不了需求. 复制代码 代码如下: >>> import sys >>> sys.getdefaultencoding
-
解决Python pandas plot输出图形中显示中文乱码问题
解决方式一: import matplotlib #1. 获取matplotlibrc文件所在路径 matplotlib.matplotlib_fname() #Out[3]: u'd:\\Anaconda2\\lib\\site-packages\\matplotlib\\mpl-data\\matplotlibrc' #修改此配置文件,一劳永逸,不用在每个脚本中写代码解决中文显示问题 修改 'font.sans-serif' 的配置,在最前面加你本地电脑已有的字体family. 参看方式二.
-
Python BeautifulSoup中文乱码问题的2种解决方法
解决方法一: 使用python的BeautifulSoup来抓取网页然后输出网页标题,但是输出的总是乱码,找了好久找到解决办法,下面分享给大家首先是代码 复制代码 代码如下: from bs4 import BeautifulSoupimport urllib2 url = 'http://www.jb51.net/'page = urllib2.urlopen(url) soup = BeautifulSoup(page,from_encoding="utf8")print soup
-
python3 中文乱码与默认编码格式设定方法
python默认编码格式是utf-8.在python2.7中,可以通过sys.setdefaultencoding('gbk')设定默认编码格式,而在python3.3中sys.setdefaultencoding()这个函数已经没有了.在python3.3中该如何设置内置的默认编码格式啊!急求!!! (类似于"#coding:gbk"这种就不必来说了.能让import sys print(sys.getdefaultencoding())输出"gbk"的大神请进!