Keras官方中文文档:性能评估Metrices详解
能评估
使用方法
性能评估模块提供了一系列用于模型性能评估的函数,这些函数在模型编译时由metrics关键字设置
性能评估函数类似与目标函数, 只不过该性能的评估结果讲不会用于训练.
可以通过字符串来使用域定义的性能评估函数
model.compile(loss='mean_squared_error',
optimizer='sgd',
metrics=['mae', 'acc'])
也可以自定义一个Theano/TensorFlow函数并使用之
from keras import metrics
model.compile(loss='mean_squared_error',
optimizer='sgd',
metrics=[metrics.mae, metrics.categorical_accuracy])
参数
y_true:真实标签,theano/tensorflow张量
y_pred:预测值, 与y_true形式相同的theano/tensorflow张量
返回值
单个用以代表输出各个数据点上均值的值
可用预定义张量
除fbeta_score额外拥有默认参数beta=1外,其他各个性能指标的参数均为y_true和y_pred
binary_accuracy: 对二分类问题,计算在所有预测值上的平均正确率
categorical_accuracy:对多分类问题,计算再所有预测值上的平均正确率
sparse_categorical_accuracy:与categorical_accuracy相同,在对稀疏的目标值预测时有用
top_k_categorical_accracy: 计算top-k正确率,当预测值的前k个值中存在目标类别即认为预测正确
sparse_top_k_categorical_accuracy:与top_k_categorical_accracy作用相同,但适用于稀疏情况
定制评估函数
定制的评估函数可以在模型编译时传入,该函数应该以(y_true, y_pred)为参数,并返回单个张量,或从metric_name映射到metric_value的字典,下面是一个示例:
(y_true, y_pred) as arguments and return a single tensor value.
import keras.backend as K
def mean_pred(y_true, y_pred):
return K.mean(y_pred)
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy', mean_pred])
补充知识:Keras.metrics中的accuracy总结
1. 背景
Accuracy(准确率)是机器学习中最简单的一种评价模型好坏的指标,每一个从事机器学习工作的人一定都使用过这个指标。没从事过机器学习的人大都也知道这个指标,比如你去向别人推销一款自己做出来的字符识别软件,人家一定会问你准确率是多少。准确率听起来简单,但不是所有人都能理解得透彻,本文将介绍Keras中accuracy(也适用于Tensorflow)的几个新“玩法”。
2. Keras中的accuracy介绍
Keras.metrics中总共给出了6种accuracy,如下图所示:
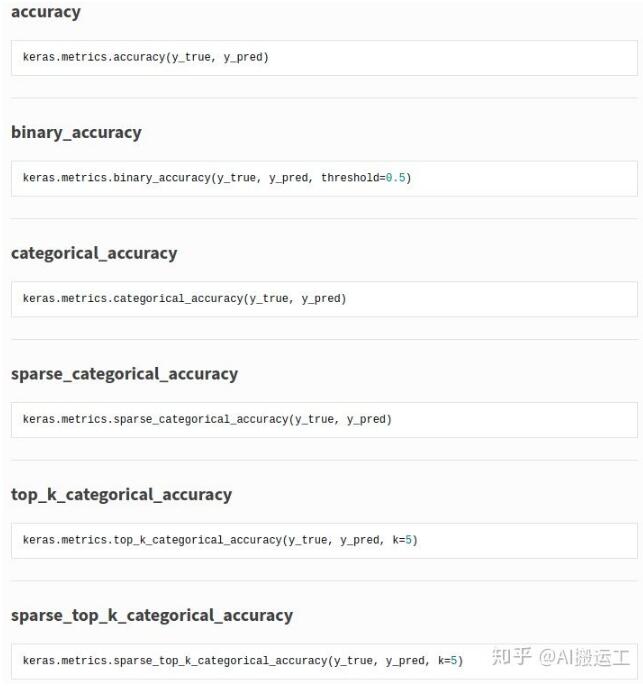
接下来将对这些accuracy进行逐个介绍。
1) accuracy
该accuracy就是大家熟知的最朴素的accuracy。比如我们有6个样本,其真实标签y_true为[0, 1, 3, 3, 4, 2],但被一个模型预测为了[0, 1, 3, 4, 4, 4],即y_pred=[0, 1, 3, 4, 4, 4],那么该模型的accuracy=4/6=66.67%。
2) binary_accuracy
binary_accuracy和accuracy最大的不同就是,它适用于2分类的情况。从上图中可以看到binary_accuracy的计算除了y_true和y_pred外,还有一个threshold参数,该参数默认为0.5。比如有6个样本,其y_true为[0, 0, 0, 1, 1, 0],y_pred为[0.2, 0.3, 0.6, 0.7, 0.8, 0.1],那么其binary_accuracy=5/6=87.5%。具体计算方法为:1)将y_pred中的每个预测值和threshold对比,大于threshold的设为1,小于等于threshold的设为0,得到y_pred_new=[0, 0, 1, 1, 1, 0];2)将y_true和y_pred_new代入到2.1中计算得到最终的binary_accuracy=87.5%。
3) categorical_accuracy
categorical_accuracy和accuracy也很像。不同的是accuracy针对的是y_true和y_pred都为具体标签的情况,而categorical_accuracy针对的是y_true为onehot标签,y_pred为向量的情况。比如有4个样本,其y_true为[[0, 0, 1], [0, 1, 0], [0, 1, 0], [1, 0, 0]],y_pred为[[0.1, 0.6, 0.3], [0.2, 0.7, 0.1], [0.3, 0.6, 0.1], [0.9, 0, 0.1]],则其categorical_accuracy为75%。具体计算方法为:1)将y_true转为非onehot的形式,即y_true_new=[2, 1, 1, 0];2)根据y_pred中的每个样本预测的分数得到y_pred_new=[1, 1, 1, 0];3)将y_true_new和y_pred_new代入到2.1中计算得到最终的categorical_accuracy=75%。
4) sparse_categorical_accuracy
和categorical_accuracy功能一样,只是其y_true为非onehot的形式。比如有4个样本,其y_true为[2, 1, 1, 0],y_pred为[[0.1, 0.6, 0.3], [0.2, 0.7, 0.1], [0.3, 0.6, 0.1], [0.9, 0, 0.1]],则其categorical_accuracy为75%。具体计算方法为:1)根据y_pred中的每个样本预测的分数得到y_pred_new=[1, 1, 1, 0];2)将y_true和y_pred_new代入到2.1中计算得到最终的categorical_accuracy=75%。
5) top_k_categorical_accuracy
在categorical_accuracy的基础上加上top_k。categorical_accuracy要求样本在真值类别上的预测分数是在所有类别上预测分数的最大值,才算预测对,而top_k_categorical_accuracy只要求样本在真值类别上的预测分数排在其在所有类别上的预测分数的前k名就行。比如有4个样本,其y_true为[[0, 0, 1], [0, 1, 0], [0, 1, 0], [1, 0, 0]],y_pred为[[0.3, 0.6, 0.1], [0.5, 0.4, 0.1], [0.3, 0.6, 0.1], [0.9, 0, 0.1]],根据前面知识我们可以计算得到其categorical_accuracy=50%,但是其top_k_categorical_accuracy是多少呢?答案跟k息息相关。如果k大于或等于3,其top_k_categorical_accuracy毫无疑问是100%,因为总共就3个类别。如果k小于3,那就要计算了,比如k=2,那么top_k_categorical_accuracy=75%。具体计算方法为:1)将y_true转为非onehot的形式,即y_true_new=[2, 1, 1, 0];2)计算y_pred的top_k的label,比如k=2时,y_pred_new = [[0, 1], [0, 1], [0, 1], [0, 2]];3)根据每个样本的真实标签是否在预测标签的top_k内来统计准确率,上述4个样本为例,2不在[0, 1]内,1在[0, 1]内,1在[0, 1]内,0在[0, 2]内,4个样本总共预测对了3个,因此k=2时top_k_categorical_accuracy=75%。说明一下,Keras中计算top_k_categorical_accuracy时默认的k值为5。
6) sparse_top_k_categorical_accuracy
和top_k_categorical_accuracy功能一样,只是其y_true为非onehot的形式。比如有4个样本,其y_true为[2, 1, 1, 0],y_pred为[[0.3, 0.6, 0.1], [0.5, 0.4, 0.1], [0.3, 0.6, 0.1], [0.9, 0, 0.1]]。计算sparse_top_k_categorical_accuracy的步骤如下:1)计算y_pred的top_k的label,比如k=2时,y_pred_new = [[0, 1], [0, 1], [0, 1], [0, 2]];2)根据每个样本的真实标签是否在预测标签的top_k内来统计准确率,上述4个样本为例,2不在[0, 1]内,1在[0, 1]内,1在[0, 1]内,0在[0, 2]内,4个样本总共预测对了3个,因此k=2时top_k_categorical_accuracy=75%。
3. 总结
综上,keras中的accuracy metric用法很多,大家可以根据自己的实际情况选择合适的accuracy metric。以下是几个比较常见的用法:
1) 当你的标签和预测值都是具体的label index(如y_true=[1, 2, 1], y_pred=[0, 1, 1])时,用keras.metrics.accuracy。
2) 当你的标签是具体的label index,而prediction是向量形式(如y_true=[1, 2, 1], y_pred=[[0.2, 0.3, 0.5], [0.9, 0.1, 0], [0, 0.4, 0.6]])时,用keras.metrics.sparse_categorical_accuracy。
3)当你的标签是onehot形式,而prediction是向量形式(如y_true=[[0, 1, 0], [0, 0, 1], [0, 1, 0]], y_pred=[[0.2, 0.3, 0.5], [0.9, 0.1, 0], [0, 0.4, 0.6]])时,用keras.metrics.categorical_accuracy。
当然,还有其他更高级的用法,比如对每个类别的accuracy求平均,或者对每个类别的accuracy进行加权,或者对每个样本的accuracy进行加权等,不在本文的讨论范围,大家有兴趣可以去参考Tensorflow或者Keras的官方文档。
以上这篇Keras官方中文文档:性能评估Metrices详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
浅谈cv2.imread()和keras.preprocessing中的image.load_img()区别
1.image.load_img() from keras.preprocessing import image img_keras = image.load_img('./original/dog/880.jpg') print(img_keras) img_keras = image.img_to_array(img_keras) print(img_keras[:,1,1]) 效果如下: <PIL.JpegImagePlugin.JpegImageFile image mode=RGB s
-
Python实现Keras搭建神经网络训练分类模型教程
我就废话不多说了,大家还是直接看代码吧~ 注释讲解版: # Classifier example import numpy as np # for reproducibility np.random.seed(1337) # from keras.datasets import mnist from keras.utils import np_utils from keras.models import Sequential from keras.layers import Dense, Act
-
升级keras解决load_weights()中的未定义skip_mismatch关键字问题
1.问题描述 在用yolov3训练自己的数据集时,尝试加载预训练的权重,在冻结前154层的基础上,利用自己的数据集finetune. 出现如下错误: load_weights(),got an unexpected keyword argument skip_mismatch 2.解决方法 因为keras旧版本没有这一定义,在新的版本中有这一关键字的定义,因此,更新keras版本至2.1.5即可解决. source activate env pip uninstall keras pip ins
-
keras 读取多标签图像数据方式
我所接触的多标签数据,主要包括两类: 1.一张图片属于多个标签,比如,data:一件蓝色的上衣图片.jpg,label:蓝色,上衣.其中label包括两类标签,label1第一类:上衣,裤子,外套.label2第二类,蓝色,黑色,红色.这样两个输出label1,label2都是是分类,我们可以直接把label1和label2整合为一个label,直接编码,比如[蓝色,上衣]编码为[011011].这样模型的输出也只需要一个输出.实现了多分类. 2.一张图片属于多个标签,但是几个标签不全是分类.比
-
Keras官方中文文档:性能评估Metrices详解
能评估 使用方法 性能评估模块提供了一系列用于模型性能评估的函数,这些函数在模型编译时由metrics关键字设置 性能评估函数类似与目标函数, 只不过该性能的评估结果讲不会用于训练. 可以通过字符串来使用域定义的性能评估函数 model.compile(loss='mean_squared_error', optimizer='sgd', metrics=['mae', 'acc']) 也可以自定义一个Theano/TensorFlow函数并使用之 from keras import metri
-
使用Python3内置文档高效学习以及官方中文文档
概述 从前面的对Python基础知识方法介绍中,我们几乎是围绕Python内置方法进行探索实践,比如字符串.列表.字典等数据结构的内置方法,和大量内置的标准库,诸如functools.time.threading等等,而我们怎么快速学习掌握并学会使用这个Python的工具集呢? 我们可以利用Python的内置文档大量资源既可以掌握许多关于Python工具集的基本使用. dir函数 Python中内置的dir函数用于提取某对象内所有属性的方法,,诸如对象的方法及属性 L = [1, 2, 3, 4
-
详解vue axios中文文档
axios中文文档 在用Vue做开发的时候,官方推荐的前后端通信插件是axios,Github上axios的文档虽然详细,但是却是英文版.现在发现有个axios的中文文档,于是就转载过来了! 原文地址 : https://github.com/mzabriskie/axios 简介 版本:v0.16.1 基于http客户端的promise,面向浏览器和nodejs 特色 浏览器端发起XMLHttpRequests请求 node端发起http请求 支持Promise API 拦截请求和返回 转化请
-
详解Chai.js断言库API中文文档
Chai.js断言库API中文文档 基于chai.js官方API文档翻译.仅列出BDD风格的expect/should API.TDD风格的Assert API由于不打算使用,暂时不放,后续可能会更新. BDD expect和should是BDD风格的,二者使用相同的链式语言来组织断言,但不同在于他们初始化断言的方式:expect使用构造函数来创建断言对象实例,而should通过为Object.prototype新增方法来实现断言(所以should不支持IE):expect直接指向chai.ex
-
three.js中文文档学习之如何本地运行详解
前言 本文属于系列问题,需要的朋友们开始之前可以参考以下的两篇文章: 1.three.js中文文档学习之创建场景 2.three.js中文文档学习之通过模块导入 如果你只是使用程序化的几何体,不需要加载任何材质,网页应该直接从文件系统加载,只需要双击文件管理器中 HTML 文件,应该在你的浏览器能够运行(地址栏长这样子:file:///yourFile.html) 从外部文件加载内容 如果你从外部文件下载模块和材质,由于浏览器的 同源政策 的安全限制,会引发安全异常而加载失败. 有两种解决办法:
-
基于python-pptx库中文文档及使用详解
个人使用样例及部分翻译自官方文档,并详细介绍chart的使用 一:基础应用 1.创建pptx文档类并插入一页幻灯片 from pptx import Presentation prs = Presentation() slide = prs.slides.add_slide(prs.slide_layouts[1]) # 对ppt的修改 prs.save('python-pptx.pptx') prs.slide_layouts中一共预存有1-48种,采用第六种为空白幻灯片 例slide_lay
-
对tensorflow中cifar-10文档的Read操作详解
前言 在tensorflow的官方文档中得卷积神经网络一章,有一个使用cifar-10图片数据集的实验,搭建卷积神经网络倒不难,但是那个cifar10_input文件着实让我费了一番心思.配合着官方文档也算看的七七八八,但是中间还是有一些不太明白,不明白的mark一下,这次记下一些已经明白的. 研究 cifar10_input.py文件的read操作,主要的就是下面的代码: if not eval_data: filenames = [os.path.join(data_dir, 'data_b
-
java 中maven pom.xml文件教程详解
maven pom.xml文件教程详解,具体内容如下所示: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.x
-
在vue-cli中引入lodash.js并使用详解
lodash 是一个一致性.模块化.高性能的 JavaScript 实用工具库. 在vue官方文档中使用了lodash中的debounce函数对操作频率做限制.其引入的方式是直接引入了js <script src="https://cdn.jsdelivr.net/npm/lodash@4.13.1/lodash.min.js"></script> 而现在我们使用vue-cli脚手架搭建的项目在这样使用,明显会很不合适.所以我们需要通过npm来安装 $ npm
-

Java中Exception和Error的区别详解
世界上存在永远不会出错的程序吗?也许这只会出现在程序员的梦中.随着编程语言和软件的诞生,异常情况就如影随形地纠缠着我们,只有正确的处理好意外情况,才能保证程序的可靠性. java语言在设计之初就提供了相对完善的异常处理机制,这也是java得以大行其道的原因之一,因为这种机制大大降低了编写和维护可靠程序的门槛.如今,异常处理机制已经成为现代编程语言的标配. 今天我要问你的问题是,请对比Exception和Error,另外,运行时异常与一般异常有什么区别? 典型回答 Exception和Error都