在python中使用pyspark读写Hive数据操作
1、读Hive表数据
pyspark读取hive数据非常简单,因为它有专门的接口来读取,完全不需要像hbase那样,需要做很多配置,pyspark提供的操作hive的接口,使得程序可以直接使用SQL语句从hive里面查询需要的数据,代码如下:
from pyspark.sql import HiveContext,SparkSession
_SPARK_HOST = "spark://spark-master:7077"
_APP_NAME = "test"
spark_session = SparkSession.builder.master(_SPARK_HOST).appName(_APP_NAME).getOrCreate()
hive_context= HiveContext(spark_session )
# 生成查询的SQL语句,这个跟hive的查询语句一样,所以也可以加where等条件语句
hive_database = "database1"
hive_table = "test"
hive_read = "select * from {}.{}".format(hive_database, hive_table)
# 通过SQL语句在hive中查询的数据直接是dataframe的形式
read_df = hive_context.sql(hive_read)
2 、将数据写入hive表
pyspark写hive表有两种方式:
(1)通过SQL语句生成表
from pyspark.sql import SparkSession, HiveContext
_SPARK_HOST = "spark://spark-master:7077"
_APP_NAME = "test"
spark = SparkSession.builder.master(_SPARK_HOST).appName(_APP_NAME).getOrCreate()
data = [
(1,"3","145"),
(1,"4","146"),
(1,"5","25"),
(1,"6","26"),
(2,"32","32"),
(2,"8","134"),
(2,"8","134"),
(2,"9","137")
]
df = spark.createDataFrame(data, ['id', "test_id", 'camera_id'])
# method one,default是默认数据库的名字,write_test 是要写到default中数据表的名字
df.registerTempTable('test_hive')
sqlContext.sql("create table default.write_test select * from test_hive")
(2)saveastable的方式
# method two
# "overwrite"是重写表的模式,如果表存在,就覆盖掉原始数据,如果不存在就重新生成一张表
# mode("append")是在原有表的基础上进行添加数据
df.write.format("hive").mode("overwrite").saveAsTable('default.write_test')
tips:
spark用上面几种方式读写hive时,需要在提交任务时加上相应的配置,不然会报错:
spark-submit --conf spark.sql.catalogImplementation=hive test.py
补充知识:PySpark基于SHC框架读取HBase数据并转成DataFrame
一、首先需要将HBase目录lib下的jar包以及SHC的jar包复制到所有节点的Spark目录lib下
二、修改spark-defaults.conf 在spark.driver.extraClassPath和spark.executor.extraClassPath把上述jar包所在路径加进去
三、重启集群
四、代码
#/usr/bin/python
#-*- coding:utf-8 –*-
from pyspark import SparkContext
from pyspark.sql import SQLContext,HiveContext,SparkSession
from pyspark.sql.types import Row,StringType,StructField,StringType,IntegerType
from pyspark.sql.dataframe import DataFrame
sc = SparkContext(appName="pyspark_hbase")
sql_sc = SQLContext(sc)
dep = "org.apache.spark.sql.execution.datasources.hbase"
#定义schema
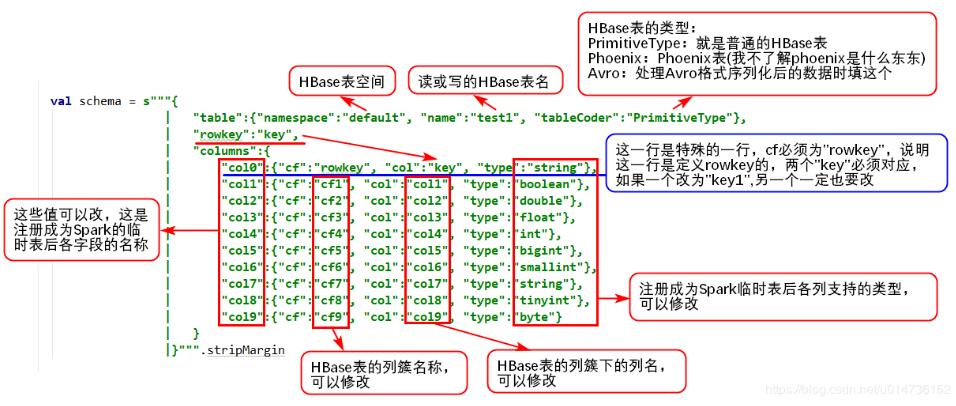
catalog = """{
"table":{"namespace":"default", "name":"teacher"},
"rowkey":"key",
"columns":{
"id":{"cf":"rowkey", "col":"key", "type":"string"},
"name":{"cf":"teacherInfo", "col":"name", "type":"string"},
"age":{"cf":"teacherInfo", "col":"age", "type":"string"},
"gender":{"cf":"teacherInfo", "col":"gender","type":"string"},
"cat":{"cf":"teacherInfo", "col":"cat","type":"string"},
"tag":{"cf":"teacherInfo", "col":"tag", "type":"string"},
"level":{"cf":"teacherInfo", "col":"level","type":"string"} }
}"""
df = sql_sc.read.options(catalog = catalog).format(dep).load()
print ('***************************************************************')
print ('***************************************************************')
print ('***************************************************************')
df.show()
print ('***************************************************************')
print ('***************************************************************')
print ('***************************************************************')
sc.stop()
五、解释
数据来源参考请本人之前的文章,在此不做赘述
schema定义参考如图:
六、结果
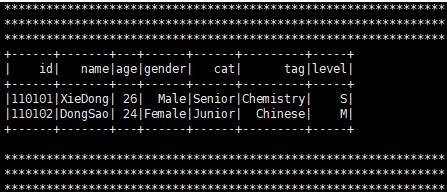
以上这篇在python中使用pyspark读写Hive数据操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
如何将PySpark导入Python的放实现(2种)
方法一 使用findspark 使用pip安装findspark: pip install findspark 在py文件中引入findspark: >>> import findspark >>> findspark.init() 导入你要使用的pyspark库 >>> from pyspark import * 优点:简单快捷 缺点:治标不治本,每次写一个新的Application都要加载一遍findspark 方法二 把预编译包中的Python库
-
Python pandas 列转行操作详解(类似hive中explode方法)
最近在工作上用到Python的pandas库来处理excel文件,遇到列转行的问题.找了一番资料后成功了,记录一下. 1. 如果需要爆炸的只有一列: df=pd.DataFrame({'A':[1,2],'B':[[1,2],[1,2]]}) df Out[1]: A B 0 1 [1, 2] 1 2 [1, 2] 如果要爆炸B这一列,可以直接用explode方法(前提是你的pandas的版本要高于或等于0.25) df.explode('B') A B 0 1 1 1 1 2 2 2 1 3
-
Python使用pyodbc访问数据库操作方法详解
本文实例讲述了Python使用pyodbc访问数据库操作方法. 数据库连接 数据库连接网上大致有两种方法,一种是使用pyodbc,另一种是使用win32com.client,测试了很多遍,最终只有pyodbc成功,而且比较好用,所以这里只介绍这种方法 工具库安装 在此基础上安装pyodbc工具库,在cmd窗口执行如下语句安装 pip install pyodbc 如果安装了anaconda也可以使用conda install pyodbc 分享给大家供大家参考,具体如下: 检验是否可以正常连接数
-
python3.6.5基于kerberos认证的hive和hdfs连接调用方式
1. Kerberos是一种计算机网络授权协议,用来在非安全网络中,对个人通信以安全的手段进行身份认证.具体请查阅官网 2. 需要安装的包(基于centos) yum install libsasl2-dev yum install gcc-c++ python-devel.x86_64 cyrus-sasl-devel.x86_64 yum install python-devel yum install krb5-devel yum install python-krbV pip insta
-
在python中使用pyspark读写Hive数据操作
1.读Hive表数据 pyspark读取hive数据非常简单,因为它有专门的接口来读取,完全不需要像hbase那样,需要做很多配置,pyspark提供的操作hive的接口,使得程序可以直接使用SQL语句从hive里面查询需要的数据,代码如下: from pyspark.sql import HiveContext,SparkSession _SPARK_HOST = "spark://spark-master:7077" _APP_NAME = "test" spa
-
python中for语句简单遍历数据的方法
本文实例讲述了python中for语句简单遍历数据的方法.分享给大家供大家参考.具体如下: 复制代码 代码如下: for name in ["kak", "John", "Mani", "Matt"]: print(name) 运行结果如下: 复制代码 代码如下: kak John Mani Matt 希望本文所述对大家的Python程序设计有所帮助.
-
Python中elasticsearch插入和更新数据的实现方法
首先,我的索引结构是酱紫的. 存储以name_id为主键的索引,待插入或更新数据为: 一般会有有两种操作: 以下图片为个人见解,我没试过能不能直接运行,但形式上没错. 数据不存在,我需要插入地址为空字符串. 单条插入: 批量插入: 该数据存在,我需要更新地址字段为空字符串. 单条更新: 批量更新: 总结 以上所述是小编给大家介绍的Python中elasticsearch插入和更新数据的实现方法,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的! 您可能感兴趣的文章: 使用
-

Python中的正则表达式与JSON数据交换格式
一.初识正则表达式 正则表达式 是一个特殊的字符序列,一个字符串是否与我们所设定的这样的字符序列,相匹配快速检索文本.实现替换文本的操作 json(xml) 轻量级 web 数据交换格式 import re a='C|C++|Java|C#||Python|Javascript' r= re.findall('Python',a) print(r) if len(r) > 0: print('字符串中包含Python') else: print('No') ['Python'] 字符串中包含Py
-
Python 中pandas索引切片读取数据缺失数据处理问题
引入 numpy已经能够帮助我们处理数据,能够结合matplotlib解决我们数据分析的问题,那么pandas学习的目的在什么地方呢? numpy能够帮我们处理处理数值型数据,但是这还不够 很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等 比如:我们通过爬虫获取到了存储在数据库中的数据 比如:之前youtube的例子中除了数值之外还有国家的信息,视频的分类(tag)信息,标题信息等 所以,numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我
-
python mongo 向数据中的数组类型新增数据操作
我就废话不多说了,大家还是直接看图吧~ 补充知识:pymongo插入数据时更新和不更新的使用 (1)update的setOnInsert 当该key不存在的时候执行插入操作,当存在的时候则不管,可以使用setOnInsert db.test.update({'_id': 'id'}, {'$setOnInsert': {'a': 'a'}, true) 当id存在的时候,忽略setOnInsert. (2)update的set 当key不存在的时候执行插入操作,当存在的时候更新除key以外的se
-
Python中使用matplotlib绘制mqtt数据实时图像功能
目录 效果图 mqtt发布 mqtt订阅 matplotlib绘制动态图 matplotlib绘制mqtt数据实时图像 效果图 mqtt发布 本代码中publish是一个死循环,数据一直往外发送. import random import time from paho.mqtt import client as mqtt_client import json from datetime import datetime broker = 'broker.emqx.io' port = 1883 t
-
Python中ini配置文件读写的实现
导入模块 import configparser # py3 写入 config = configparser.ConfigParser() config["DEFAULT"] = { 'ServerAliveInterval': '45', 'Compression': 'yes', 'CompressionLevel': '9' } config['bitbucket.org'] = {} config['bitbucket.org']['User'
-
详解Python中四种关系图数据可视化的效果对比
python关系图的可视化主要就是用来分析一堆数据中,每一条数据的节点之间的连接关系从而更好的分析出人物或其他场景中存在的关联关系. 这里使用的是networkx的python非标准库来测试效果展示,通过模拟出一组DataFrame数据实现四种关系图可视化. 其余还包含了pandas的数据分析模块以及matplotlib的画图模块. 若是没有安装这三个相关的非标准库使用pip的方式安装一下即可. pip install pandas -i https://pypi.tuna.tsinghua.e
-
Python中文件的读取和写入操作
从文件中读取数据 读取整个文件 这里假设在当前目录下有一个文件名为'pi_digits.txt'的文本文件,里面的数据如下: 3.1415926535 8979323846 2643383279 with open('pi_digits.txt') as f: # 默认模式为'r',只读模式 contents = f.read() # 读取文件全部内容 print contents # 输出时在最后会多出一行(read()函数到达文件末会返回一个空字符,显示出空字符就是一个空行) print '