Pandas groupby apply agg 的区别 运行自定义函数说明
agg 方法将一个函数使用在一个数列上,然后返回一个标量的值。也就是说agg每次传入的是一列数据,对其聚合后返回标量。
对一列使用三个函数:
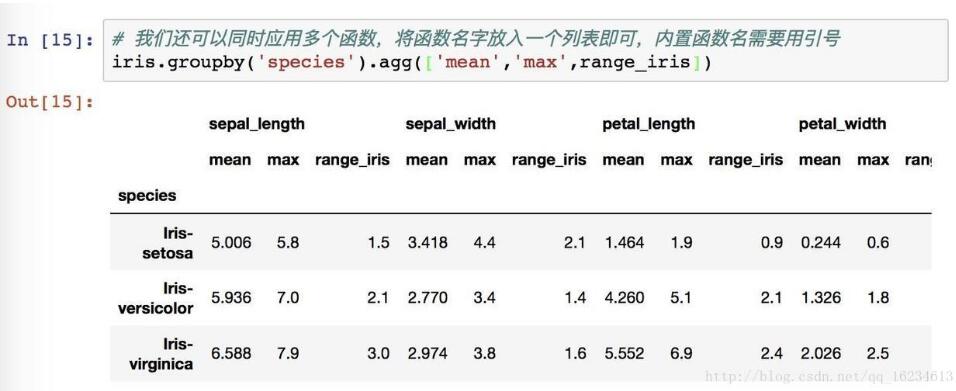
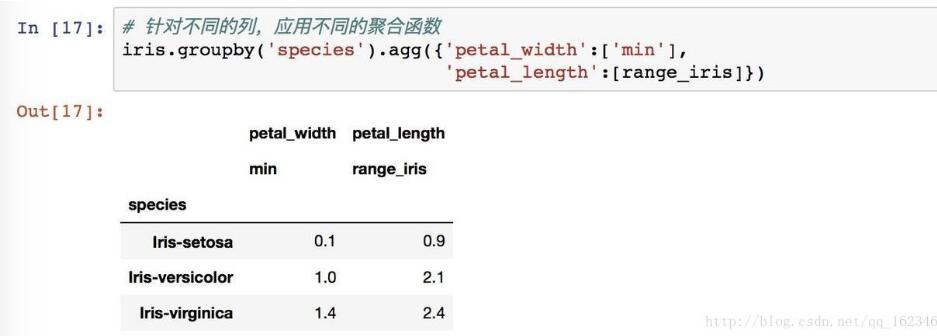
对不同列使用不同函数
apply 是一个更一般化的方法:将一个数据分拆-应用-汇总。而apply会将当前分组后的数据一起传入,可以返回多维数据。
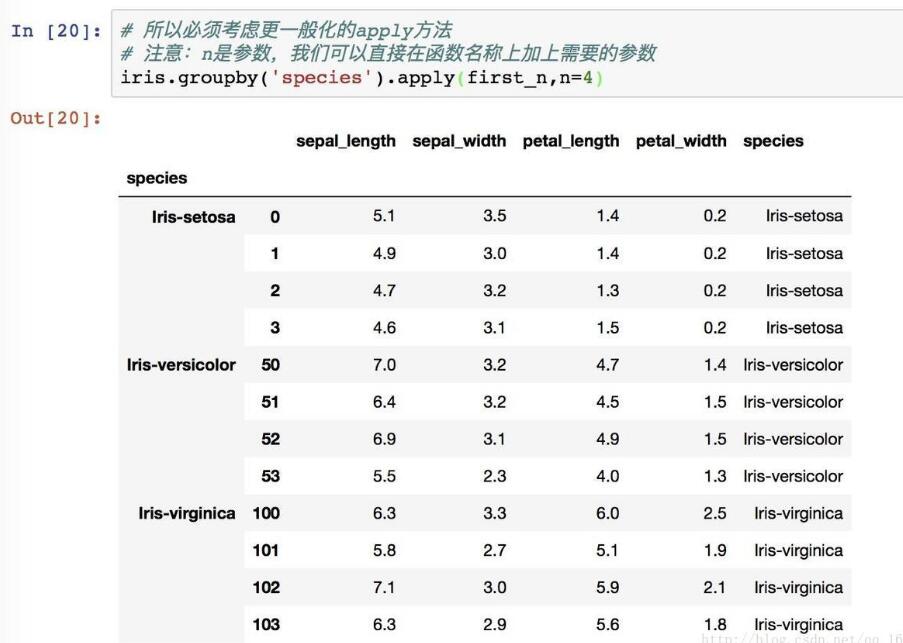
实例:
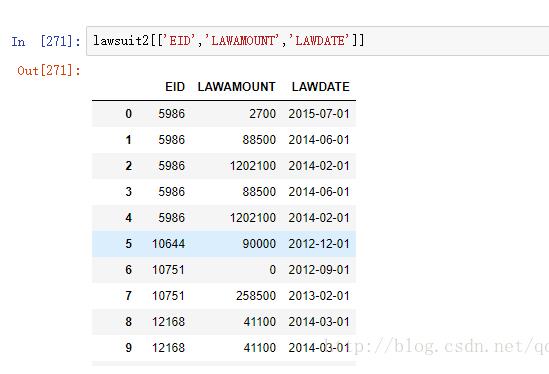
1、数据如下:
lawsuit2[['EID','LAWAMOUNT','LAWDATE']]
2、groupby后应用apply传入函数数据如下:
lawsuit2[['EID','LAWAMOUNT','LAWDATE']].groupby(['EID']).apply(lambda df:print(df))
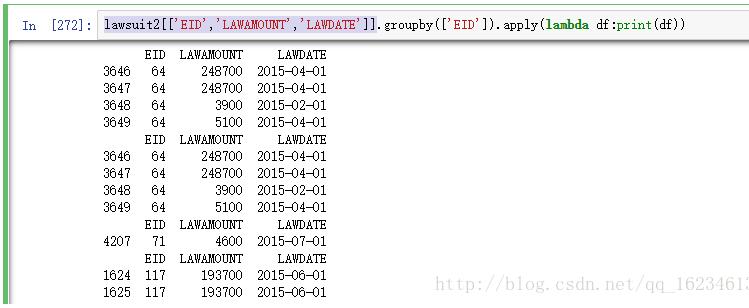
3、如果使用agg,对于两列可以处理,但对于上面的三列,打印数据如下:
lawsuit2[['EID','LAWAMOUNT','LAWDATE']].groupby(['EID']).agg(lambda df:print(df))
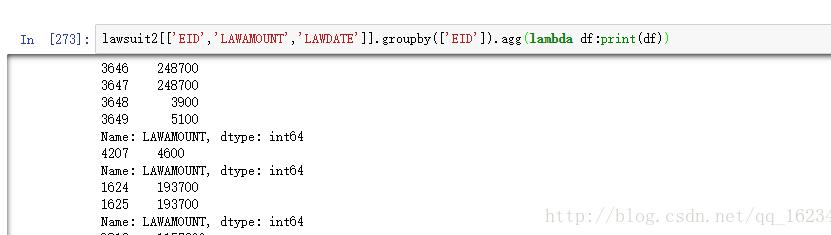
可以看到agg传入的只有一列数据,如果我们使用df加列下表强行取值也能取到,但是有时会出现各种keyError问题。
4、完整代码:
判断最近一次日期的花费是否是所有的花费中最大花费。
def handle(df):
# print(df)
# 找最大日期
maxdate = df['LAWDATE'].max()
# 找最大费用
left = df[ df['LAWDATE']==maxdate ]['LAWAMOUNT'].max()
# 取ID
EID = df['EID'].values[0]
# print(EID)
# 从已存在的表中根据EID找到最大费用
right = LAW_AMOUNT_MAX.loc[EID,'LAW_AMOUNT_MAX']
# 判断费用是否相等
if left==right:
return 1
else:
return 0
LAW_AMOUNT_MAX_IS_LAST = lawsuit2[['EID','LAWAMOUNT','LAWDATE']].groupby(['EID']).apply(handle)
其他注意点:
在groupby后使用apply,如果直接返回,会出现有多余的groupby索引问题,可以使用group_keys解决:
orgin = reviews_df.sort_values(["reviewerID","unixReviewTime"]).groupby("reviewerID",group_keys=False)
train = orgin.apply(lambda df: df[:-2])
train.head()
补充:pandas分组聚合运算groupby之agg,apply,transform
groupby函数是pandas中用以分组的函数,可以通过指定列来进行分组,并返回一个GroupBy对象。对于GroupBy对象的聚合运算,其有经过优化的较为常用的sum,mean等函数,但是如果我们需要用自定义的函数进行聚合运算,那么就需要通过agg,apply,transform来实现。
agg,apply和transform三者之间的区别在于:1、agg和transform之间的区别为:前者经过聚合后,只会在该组单列中返回一个标量值,而transform则会将该标量值在该组单列内进行广播,保持原DataFrame的索引不变;2、agg和transform中的函数参数是以分组后的单列(Series)为操作对象的,即传入agg和transform的函数的参数是列,而apply中的函数参数是分组后整个的DataFrame。下面分别对这两点进行说明。
一、agg和transform
如下代码所示,构造一个df,agg和transform中lambda函数的input都为单列,但是agg返回的索引是分组的key的唯一值,而transform返回的索引和原df一样,但是相比于agg返回的结果,发现transform只是在d行处的值进行了重复的广播,这个目的就是维持原df的索引不变,且被拿来分组的列会被剔除。
df
Out[1]:
index a b c
0 d 0 1 2
1 d 3 4 5
2 e 6 7 8
df.groupby(by='index').agg(lambda x:x.shape)
Out[2]:
a b c
index
d (2,) (2,) (2,)
e (1,) (1,) (1,)
df.groupby(by='index').transform(lambda x:x.shape)
Out[3]:
a b c
0 (2,) (2,) (2,)
1 (2,) (2,) (2,)
2 (1,) (1,) (1,)
二、agg和apply
下面的是apply的结果,相比于上面agg的结果,可以发现,实际上lambda函数的input不再是一个Series,而是分组后的整个DataFrame。
dd.groupby(by='index').apply(lambda x:x.shape) Out[4]: index d (2, 4) e (1, 4)
三、其他注意点
对于agg函数,其不仅可以传入一个函数对每列执行相同的操作,还可以传入一个字典{'col_name':func},来对不同的列做不同的操作,也可以将func替换为由多个不同的函数组成的list,实现对同一列做多个不同的操作,这是agg函数最为灵活的地方。
这三个函数,参数形式都为(func, *args,**kwargs),所以可以通过位置参数和关键字参数给func传递额外的参数。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

pandas数据分组groupby()和统计函数agg()的使用
数据分组 使用 groupby() 方法进行分组 group.size()查看分组后每组的数量 group.groups 查看分组情况 group.get_group('名字') 根据分组后的名字选择分组数据 准备数据 # 一个Series其实就是一条数据,Series方法的第一个参数是data,第二个参数是index(索引),如果没有传值会使用默认值(0-N) # index参数是我们自定义的索引值,注意:参数值的个数一定要相同. # 在创建Series时数据并不一定要是列表,也可以将一个字典
-
浅谈pandas用groupby后对层级索引levels的处理方法
层及索引levels,刚开始学习pandas的时候没有太多的操作关于groupby,仅仅是简单的count.sum.size等等,没有更深入的利用groupby后的数据进行处理.近来数据处理的时候有遇到这类问题花了一点时间,所以这里记录以及复习一下:(以下皆是个人实践后的理解) 我使用一个实例来讲解下面的问题:一张数据表中有三列(动物物种.物种品种.品种价格),选出每个物种从大到小品种的前两种,最后只需要品种和价格这两列. 以上这张表是我们后面需要处理的数据表 (物种 品种 价格) levels
-
pandas之分组groupby()的使用整理与总结
前言 在使用pandas的时候,有些场景需要对数据内部进行分组处理,如一组全校学生成绩的数据,我们想通过班级进行分组,或者再对班级分组后的性别进行分组来进行分析,这时通过pandas下的groupby()函数就可以解决.在使用pandas进行数据分析时,groupby()函数将会是一个数据分析辅助的利器. groupby的作用可以参考 超好用的 pandas 之 groupby 中作者的插图进行直观的理解: 准备 读入的数据是一段学生信息的数据,下面将以这个数据为例进行整理grouby()函数的
-
pandas获取groupby分组里最大值所在的行方法
pandas获取groupby分组里最大值所在的行方法 如下面这个DataFrame,按照Mt分组,取出Count最大的那行 import pandas as pd df = pd.DataFrame({'Sp':['a','b','c','d','e','f'], 'Mt':['s1', 's1', 's2','s2','s2','s3'], 'Value':[1,2,3,4,5,6], 'Count':[3,2,5,10,10,6]}) df Count Mt Sp Value 0 3 s1
-
利用Pandas和Numpy按时间戳将数据以Groupby方式分组
首先说一下需求,我需要将数据以分钟为单位进行分组,然后每一分钟内的数据作为一行输出,因为不同时间的数据量不一样,所以所有数据按照最长的那组数据为准,不足的数据以各自的最后一个数据进行补足. 之后要介绍一下我的数据源,之前没用的数据列已经去除,我只留下要用到的数据data列和时间戳time列,时间戳是以秒计的,可以看到一共是407454行. data time 0 6522.50 1.530668e+09 1 6522.66 1.530668e+09 2 6523.79 1.530668e+09
-
Pandas之groupby( )用法笔记小结
groupby官方解释 DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs) Group series using mapper (dict or key function, apply given function to group, return result as series) or by a series of
-
pandas groupby分组对象的组内排序解决方案
问题: 根据数据某列进行分组,选择其中另一列大小top-K的的所在行数据 解析: 求解思路很清晰,即先用groupby对数据进行分组,然后再根据分组后的某一列进行排序,选择排序结果后的top-K结果 案例: 取一下dataframe中B列各对象中C值最高所在的行 df = pd.DataFrame({"A": [2, 3, 5, 4], "B": ['a', 'b', 'b', 'a'], "C": [200801, 200902, 200704
-
Pandas GroupBy对象 索引与迭代方法
如下所示: import pandas as pd df = pd.DataFrame({'性别' : ['男', '女', '男', '女', '男', '女', '男', '男'], '成绩' : ['优秀', '优秀', '及格', '差', '及格', '及格', '优秀', '差'], '年龄' : [15,14,15,12,13,14,15,16]}) GroupBy=df.groupby("性别") GroupBy.iter() GroupBy对象是一个迭代对象,每次迭代
-
pandas groupby + unstack的使用说明
概述 groupby()可以根据DataFrame中的某一列或者多列内容进行分组聚合,当DataFrame聚合后为两列索引时,可以使用unstack()将聚合的两列中一列值调整为行索引,另一列的值调整为列索引. 代码说明 test_df = pd.DataFrame({ 'col_1':['a', 'a', 'b', 'a', 'a', 'b', 'c', 'a', 'c'], 'col_2':['d', 'd', 'd', 'e', 'f', 'e', 'd', 'f', 'f'], 'col
-
Pandas groupby apply agg 的区别 运行自定义函数说明
agg 方法将一个函数使用在一个数列上,然后返回一个标量的值.也就是说agg每次传入的是一列数据,对其聚合后返回标量. 对一列使用三个函数: 对不同列使用不同函数 apply 是一个更一般化的方法:将一个数据分拆-应用-汇总.而apply会将当前分组后的数据一起传入,可以返回多维数据. 实例: 1.数据如下: lawsuit2[['EID','LAWAMOUNT','LAWDATE']] 2.groupby后应用apply传入函数数据如下: lawsuit2[['EID','LAWAMOUNT'
-
pandas中apply和transform方法的性能比较及区别介绍
1. apply与transform 首先讲一下apply() 与transform()的相同点与不同点 相同点: 都能针对dataframe完成特征的计算,并且常常与groupby()方法一起使用. 不同点: apply()里面可以跟自定义的函数,包括简单的求和函数以及复杂的特征间的差值函数等(注:apply不能直接使用agg()方法 / transform()中的python内置函数,例如sum.max.min.'count'等方法) transform() 里面不能跟自定义的特征交互函数,
-
pandas map(),apply(),applymap()区别解析
基础 以下操作基于python 3.6 windows 10 环境下 通过 将通过实例来演示三者的区别 toward_dict = {1: '东', 2: '南', 3: '西', 4: '北'} df = pd.DataFrame({'house' : list('AABCEFG'), 'price' : [100, 90, '', 50, 120, 150, 200], 'toward' : ['1','1','2','3','','3','2']}) df map()方法 通过df.(ta
-
Python pandas自定义函数的使用方法示例
本文实例讲述了Python pandas自定义函数的使用方法.分享给大家供大家参考,具体如下: 自定义函数的使用 import numpy as np import pandas as pd # todo 将自定义的函数作用到dataframe的行和列 或者Serise的行上 ser1 = pd.Series(np.random.randint(-10,10,5),index=list('abcde')) df1 = pd.DataFrame(np.random.randint(-10,10,(
-
python pandas中的agg函数用法
目录 pandas中的agg函数 pandas详解 聚合运算agg() 1. 创建DataFrame对象 2. 单列聚合 3. 多列聚合 4. 多种聚合运算 5. 多种聚合运算并更改列名 6. 不同的列运用不同的聚合函数 7. 使用自定义的聚合函数 8. 方便的descibe pandas中的agg函数 python中的agg函数通常用于调用groupby()函数之后,对数据做一些聚合操作,包括sum,min,max以及其他一些聚合函数 如下所示: >>> df = pd.read_ex
-
Python pandas中apply函数简介以及用法详解
目录 1.基本信息 2.语法结构 3.使用案例 3.1 DataFrame使用apply 3.2 Series使用apply 3.3 其他案例 4.总结 参考链接: 1.基本信息 Pandas 的 apply() 方法是用来调用一个函数(Python method),让此函数对数据对象进行批量处理.Pandas 的很多对象都可以使用 apply() 来调用函数,如 Dataframe.Series.分组对象.各种时间序列等. 2.语法结构 apply() 使用时,通常放入一个 lambd
-
对pandas中apply函数的用法详解
最近在使用apply函数,总结一下用法. apply函数可以对DataFrame对象进行操作,既可以作用于一行或者一列的元素,也可以作用于单个元素. 例:列元素 行元素 列 行 以上这篇对pandas中apply函数的用法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: 浅谈Pandas中map, applymap and apply的区别
-
JavaScript中call和apply方法的区别实例分析
本文实例分析了JavaScript中call和apply方法的区别.分享给大家供大家参考,具体如下: 这两个方法不经常用,但是在某些特殊场合中是非常有用的,下面主要说下它们的区别: 1.首先,JavaScript是一门面向对象的语言,也就是说它有this的概念.而且JavaScript是一门动态类型语言,为什么说它是动态类型语言呢?因为JavaScript在编译时没有类型检查的过程,不会去检查创建的对象类型,也不会去检查传递的参数类型,所以它的变量类型在运行期间是可以改变的. 2.要知道call
-
pandas groupby 用法实例详解
目录 1.分组groupby 2.groupby的数据结构 4.transform的用法 项目github地址:bitcarmanlee easy-algorithm-interview-and-practice欢迎大家star,留言,一起学习进步 1.分组groupby 在日常数据分析过程中,经常有分组的需求.具体来说,就是根据一个或者多个字段,将数据划分为不同的组,然后进行进一步分析,比如求分组的数量,分组内的最大值最小值平均值等.在sql中,就是大名鼎鼎的groupby操作.pandas中