Spark SQL配置及使用教程
目录
- SparkSQL版本:
- SparkSQL DSL语法
- SparkSQL和Hive的集成
- Spark应用依赖第三方jar包文件解决方案
- SparkSQL的ThriftServer服务
- SparkSQL的ThriftServer服务测试
- Spark中beeline的使用
- 通过jdbc来访问spark的ThriftServer接口
- SparkSQL案例
- 案例一:SparkSQL读取HDFS上Json格式的文件
- 案例二:DataFrame和Dataset和RDD之间的互相转换
- SparkSQL的函数
XY个人记
SparkSQL是spark的一个模块,主入口是SparkSession,将SQL查询与Spark程序无缝混合。DataFrames和SQL提供了访问各种数据源(通过JDBC或ODBC连接)的常用方法包括Hive,Avro,Parquet,ORC,JSON和JDBC。您甚至可以跨这些来源加入数据。以相同方式连接到任何数据源。Spark SQL还支持HiveQL语法以及Hive SerDes和UDF,允许您访问现有的Hive仓库。
Spark SQL包括基于成本的优化器,列式存储和代码生成,以快速进行查询。同时,它使用Spark引擎扩展到数千个节点和多小时查询,该引擎提供完整的中间查询容错。不要担心使用不同的引擎来获取历史数据。

SparkSQL版本:
Spark2.0之前
入口:SQLContext和HiveContext
SQLContext:主要DataFrame的构建以及DataFrame的执行,SQLContext指的是spark中SQL模块的程序入口
HiveContext:是SQLContext的子类,专门用于与Hive的集成,比如读取Hive的元数据,数据存储到Hive表、Hive的窗口分析函数等
Spark2.0之后
入口:SparkSession(spark应用程序的一个整体入口),合并了SQLContext和HiveContext
SparkSQL核心抽象:DataFrame/Dataset type DataFrame = Dataset[Row] //type 给某个数据类型起个别名
SparkSQL DSL语法
SparkSQL除了支持直接的HQL语句的查询外,还支持通过DSL语句/API进行数 据的操作,主要DataFrame API列表如下:
select:类似于HQL语句中的select,获取需要的字段信息
where/filter:类似HQL语句中的where语句,根据给定条件过滤数据
sort/orderBy: 全局数据排序功能,类似Hive中的order by语句,按照给定字段进行全部 数据的排序
sortWithinPartitions:类似Hive的sort by语句,按照分区进行数据排序
groupBy:数据聚合操作
limit:获取前N条数据记录
SparkSQL和Hive的集成
集成步骤:
-1. namenode和datanode启动
-2. 将hive配置文件软连接或者复制到spark的conf目录下面
$ ln -s /opt/modules/apache/hive-1.2.1/conf/hive-site.xml or $ cp /opt/modules/apache/hive-1.2.1/conf/hive-site.xml ./
-3. 根据hive-site.xml中不同配置项,采用不同策略操作
根据hive.metastore.uris参数
-a. 当hive.metastore.uris参数为空的时候(默认值)
将Hive元数据库的驱动jar文件添加spark的classpath环境变量中即可完成SparkSQL到hive的集成
-b. 当hive.metastore.uris非空时候
-1. 启动hive的metastore服务
./bin/hive --service metastore &
-2. 完成SparkSQL与Hive集成工作
-4.启动spark-SQL($ bin/spark-sql)时候 发现报错:
java.lang.ClassNotFoundException: org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:270)
at org.apache.spark.util.Utils$.classForName(Utils.scala:228)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:693)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:185)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:210)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:124)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Failed to load main class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.
You need to build Spark with -Phive and -Phive-thriftserver.
解决办法:将spark源码中sql/hive-thriftserver/target/spark-hive-thriftserver_2.11-2.0.2.jar拷贝到spark的jars目录下
完成。(查看数据库 spark-sql (default)> show databases; ,它操作的都是Hive)

编写两个简单的SQL
spark-sql (default)> select * from emp;
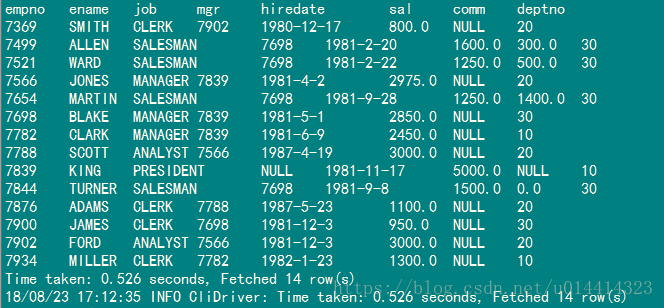
也可以做两张变的jion
spark-sql (default)> select a.*,b.* from emp a left join dept b on a.deptno = b.deptno;

可以对表进行一个缓存操作3
> cache table emp; #缓存操作 > uncache table dept; #清除缓存操作 > explain select * from emp; #执行计划
我们可以看到相应的Storage信息,执行完清除缓存操作后下面的Stages操作消失


启动一个Spark Shell,可以直接在shell里面编写SQL语句
$ bin/spark-shell
#可以在shell里面写sql
scala> spark.sql("show databases").show
scala> spark.sql("use common").show
scala> spark.sql("select * from emp a join dept b on a.deptno = b.deptno").show


用一个变量名称接收DataFrame
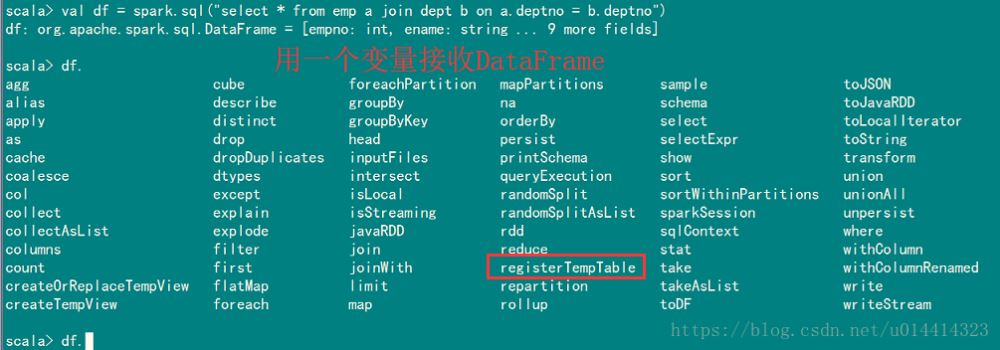
比如使用registerTempTable注册一个临时表。注:临时表是所有数据库公有的不需要指定数据库
scala> df.registerTempTable("table_regis01")

Spark应用依赖第三方jar包文件解决方案
在我们的4040页面Environment节点下的Classpath Entries节点里可以看到我们服务所依赖的jar包。http://hadoop01.com:4040/environment/

1.直接添加驱动jar到${SPARK_HOME}/jars
2. 使用参数--jars 添加本地jar包
./bin/spark-shell --jars jars/mysql-connector-java-5.1.27-bin.jar,/opt/modules/hive-1.2.1/lib/servlet-api-2.5.jar
添加多个本地jar的话,用逗号隔开
./bin/spark-shell --jars jars/mysql-connector-java-5.1.27-bin.jar,/opt/modules/hive-1.2.1/lib/*
注意:不能使用*去添加jar包,如果想要添加多个依赖jar,只能一个一个去添加
3. 使用参数--packages添加maven中的第三方jar文件
. bin/spark-shell --packages mysql:mysql-connector-java:5.1.28
可以使用逗号隔开给定多个,格式(groupId:artifactId:version)
(底层执行原理先从maven中央库下载本地没有的第三方jar文件到本地,jar文件会先下载到本地的/home/ijeffrey/.ivy2/jars目录下,最后通过spark.jars来控制添加classpath中)
--exclude-packages 去掉不需要的包
--repositories maven源,指定URL连接
4. 使用SPARK_CLASSPATH环境变量给定jar文件路径
编辑spark-env.sh文件
SPARK_CLASSPATH=/opt/modules/apache/spark-2.0.2/external_jars/* 外部jar的路径
5. 将第三方jar文件打包到最终的jar文件中
在IDEA中添加依赖jar到最终的需要运行的spark应用的jar中
SparkSQL的ThriftServer服务
ThriftServer底层就是Hive的HiveServer2服务,下面是客户端连接Hive Server2 方法的相关连接
https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients#HiveServer2Clients-JDBC
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics #hiveserver2的配置
https://cwiki.apache.org/confluence/display/Hive/Setting+Up+HiveServer2
配置:
-1. ThriftServer服务运行的Spark环境必须完成SparkSQL和Hive的集成
-2. hive-site.xml中配置hiveserver2服务的相关参数
<!-- 监听的端口号 --> <property> <name>hive.server2.thrift.bind.port</name> <value>10000</value> </property> <!-- 监听的主机名 --> <property> <name>hive.server2.thrift.bind.host</name> <value>hadoop01.com</value> </property>
-3. 启动hive的元数据服务
$ ./bin/hive --service metastore &
-4. 启动spark的thriftserver服务,也是一个SparkSubmit服务
$ sbin/start-thriftserver.sh

也可以看到相应的WEBUI界面,比之前的多了一个JDBC/ODBC Server

注意:如果需要启动Spark ThriftServer 服务,需要关闭hiveserver2 服务
SparkSQL的ThriftServer服务测试
-1. 查看进程是否存在
jps -ml | grep HiveThriftServer2
-2. 查看WEB界面是否正常
有JDBC/ODBC Server这个选项就是正常的
-3. 通过spark自带的beeline命令
./bin/beeline
-4. 通过jdbc来访问spark的ThriftServer接口
Spark中beeline的使用
$ bin/beeline #启动beeline #可以使用!help查看相应的命令 beeline> !help #如connect beeline> !connect Usage: connect <url> <username> <password> [driver] #这样可以多个用户连接 beeline> !connect jdbc:hive2://hadoop01.com:10000 #退出 beeline> !quit

连接成功,在4040 页面也可以看到我们连接的hive


注:如果报错
No known driver to handle "jdbc:hive2://hadoop01.com:10000"
说明缺少了hive的驱动jar,在我们编译好的源码中hive-jdbc-1.2.1.spark2.jar 找到并copy到spark的jars中
通过jdbc来访问spark的ThriftServer接口
向我们java连接mysql一样,我们使用scala来连接ThriftServer
package com.jeffrey
import java.sql.DriverManager
object SparkJDBCThriftServerDemo {
def main(args: Array[String]): Unit = {
//1 添加驱动
val driver = "org.apache.hive.jdbc.HiveDriver"
Class.forName(driver)
//2 构建连接对象
val url = "jdbc:hive2://hadoop01.com:10000"
val conn = DriverManager.getConnection(url,"ijeffrey","123456")
//3 sql 语句执行
conn.prepareStatement("use common").execute()
var pstmt = conn.prepareStatement("select empno,ename,sal from emp")
var rs = pstmt.executeQuery()
while (rs.next()){
println(s"empno = ${rs.getInt("empno")} " +
s"ename=${rs.getString("ename")} " +
s" sal=${rs.getDouble("sal")}")
}
println("---------------------------------------------------------------------------")
pstmt = conn.prepareStatement("select empno,ename,sal from emp where sal > ? and ename = ?")
pstmt.setDouble(1,3000)
pstmt.setString(2,"KING")
rs = pstmt.executeQuery()
while (rs.next()){
println(s"empno = ${rs.getInt("empno")} " +
s"ename=${rs.getString("ename")} " +
s" sal=${rs.getDouble("sal")}")
}
rs.close()
pstmt.close()
conn.close()
}
}
执行结果:
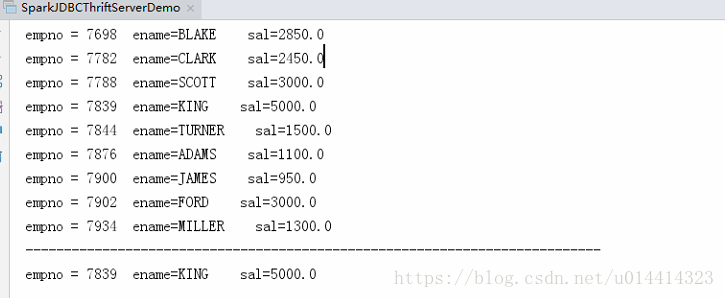
SparkSQL案例
案例一:SparkSQL读取HDFS上Json格式的文件
1. 将案例数据上传到HDFS上
样例数据在${SPARK_HOME}/examples/src/main/resources/*
2. 编写SparkSQL程序
启动一个spark-shell进行编写
scala> val path = "/spark/data/people.json"
scala> val df = spark.read.json(path)
scala> df.registerTempTable("tmp04") //通过DataFrame注册一个临时表
scala> spark.sql("show tables").show //通过SQL语句进行操作
scala> spark.sql("select * from tmp04").show
#saveAsTable 使用之前 先要use table
scala> spark.sql("select * from tmp04").write.saveAsTable("test01")
#overwrite 覆盖 append 拼接 ignore 忽略
scala> spark.sql("select * from tmp01").write.mode("overwrite").saveAsTable("test01")
scala> spark.sql("select * from tmp01").write.mode("append").saveAsTable("test01")
scala> spark.sql("select * from tmp01").write.mode("ignore").saveAsTable("test01")
saveAsTable("test01")默认保存到一张不存在的表中(test01不是临时表),如果表存在的话就会报错
SaveMode四种情况:
Append:拼接
Overwrite: 重写
ErrorIfExists:如果表已经存在,则报错,默认就是这一种,存在即报错
Ignore:如果表已经存在了,则忽略这一步操作
除了spark.read.json的方式去读取数据外,还可以使用spark.sql的方式直接读取数据
scala> spark.sql("select * from json.`/spark/data/people.json` where age is not null").show
+---+------+
|age| name|
+---+------+
| 30| Andy|
| 19|Justin|
+---+------+
# hdfs上的路径使用`(反票号)引起来
案例二:DataFrame和Dataset和RDD之间的互相转换
在IDEA中集成Hive的话,需要将hive-site.xml文件放到resources目录下面
package com.jeffrey.sql
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object HiveJoinMySQLDemo {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir","D:\\hadoop-2.7.3")
// 1.构建SparkSession
val warehouseLocation = "/user/hive/warehouse"
val spark = SparkSession
.builder()
.master("local") //如果放到集群运行需要注释掉
.appName("RDD 2 DataFrame")
.config("spark.sql.warehouse.dir",warehouseLocation)
.enableHiveSupport()
.getOrCreate()
import spark.implicits._
import spark.sql
val url = "jdbc:mysql://hadoop01.com:3306/test"
val table = "tb_dept"
val props = new Properties()
props.put("user","root")
props.put("password","123456")
// 1.Hive表数据导入到MySQL中 在shell中可以使用paste写多行
spark.read.table("common.dept")
.write
.mode(SaveMode.Overwrite)
.jdbc(url,table,props)
// 2.Hive和MySQL的join操作
//2.1 读取MySQL的数据
val df: DataFrame = spark
.read
.jdbc(url,table,props)
df.createOrReplaceTempView("tmp_tb_dept")
//2.1 数据聚合
spark.sql(
"""
|select a.*,b.dname,b.loc
|from common.emp a
|join tmp_tb_dept b on a.deptno = b.deptno
""".stripMargin).createOrReplaceTempView("tmp_emp_join_dept_result")
spark.sql("select * from tmp_emp_join_dept_result").show()
// 对表进行缓存的方法
spark.read.table("tmp_emp_join_dept_result").cache()
spark.catalog.cacheTable("tmp_emp_join_dept_result")
//输出到HDFS上
// 方法一
/*spark
.read
.table("tmp_emp_join_dept_result")
.write.parquet("/spark/sql/hive_join_mysql")*/
// 方法二
spark
.read
.table("tmp_emp_join_dept_result")
.write
.format("parquet")
.save(s"hdfs://hadoop01.com:8020/spark/sql/hive_join_mysql/${System.currentTimeMillis()}")
//输出到Hive中,并且是parquet格式 按照deptno分区
spark
.read
.table("tmp_emp_join_dept_result")
.write
.format("parquet")
.partitionBy("deptno")
.mode(SaveMode.Overwrite)
.saveAsTable("hive_emp_dept")
println("------------------------------------------------------------")
spark.sql("show tables").show()
//清空缓存
spark.catalog.uncacheTable("tmp_emp_join_dept_result")
}
}
可以打成jar文件放在集群上执行
bin/spark-submit \ --class com.jeffrey.sql.HiveJoinMySQLDemo \ --master yarn \ --deploy-mode client \ /opt/datas/jar/hivejoinmysql.jar bin/spark-submit \ --class com.jeffrey.sql.HiveJoinMySQLDemo \ --master yarn \ --deploy-mode cluster \ /opt/datas/logAnalyze.jar
以上即使Spark SQL的基本使用。
SparkSQL的函数
HIve支持的函数,SparkSQL基本都是支持的,SparkSQL支持两种自定义函数,分别是:UDF和UDAF,两种函数都是通过SparkSession的udf属性进行函数的注册使用的;SparkSQL不支持UDTF函数的 自定义使用。
☆ UDF:一条数据输入,一条数据输出,一对一的函数,即普通函数
☆ UDAF:多条数据输入,一条数据输出,多对一的函数,即聚合函数
下一篇会写一下SparkSQL自定义函数的案例以及其关于SparkSQL其他的案例 ^_^
到此这篇关于Spark SQL配置及使用的文章就介绍到这了,更多相关Spark SQL配置内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

SparkSQl简介及运行原理
目录 一:什么是SparkSQL? (一)SparkSQL简介 (二)SparkSQL运行原理 (三)SparkSQL特点 二:DataFrame (一)什么是DataFrame? 补充:Spark中的RDD.DataFrame和DataSet讲解 (一)Spark中的模块 (二)RDD和DataFrame的区别 三:SparkSession (一)SparkSession简介 (二)SparkSession实质 (三)SparkSession特点 四:通过RDD创建DataFrame (一)通
-
SparkSQL使用快速入门
目录 一.SparkSQL的进化之路 二.认识SparkSQL 2.1 什么是SparkSQL? 2.2 SparkSQL的作用 2.3 运行原理 2.4 特点 2.5 SparkSession 2.6 DataFrames 三.RDD转换成为DataFrame 3.1通过case class创建DataFrames(反射) 3.2通过structType创建DataFrames(编程接口) 3.3通过 json 文件创建DataFrames 四.DataFrame的read和save和save
-
IDEA 开发配置SparkSQL及简单使用案例代码
1.添加依赖 在idea项目的pom.xml中添加依赖. <!--spark sql依赖,注意版本号--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.0.0</version> </dependency> 2.案例代码 package com.
-
Spark-Sql入门程序示例详解
SparkSQL运行架构 Spark SQL对SQL语句的处理,首先会将SQL语句进行解析(Parse),然后形成一个Tree,在后续的如绑定.优化等处理过程都是对Tree的操作,而操作的方法是采用Rule,通过模式匹配,对不同类型的节点采用不同的操作. spark-sql是用来处理结构化数据的模块,是入门spark的首要模块. 技术的学习无非就是去了解它的API,但是Spark有点难,因为它的例子和网上能搜到的基本都是Scala写的.我们这里使用Java. 入门例子 数据处理的第一个例子通常都
-
Spark SQL配置及使用教程
目录 SparkSQL版本: SparkSQL DSL语法 SparkSQL和Hive的集成 Spark应用依赖第三方jar包文件解决方案 SparkSQL的ThriftServer服务 SparkSQL的ThriftServer服务测试 Spark中beeline的使用 通过jdbc来访问spark的ThriftServer接口 SparkSQL案例 案例一:SparkSQL读取HDFS上Json格式的文件 案例二:DataFrame和Dataset和RDD之间的互相转换
-
Spark SQL配置及使用教程
目录 SparkSQL版本: SparkSQL DSL语法 SparkSQL和Hive的集成 Spark应用依赖第三方jar包文件解决方案 SparkSQL的ThriftServer服务 SparkSQL的ThriftServer服务测试 Spark中beeline的使用 通过jdbc来访问spark的ThriftServer接口 SparkSQL案例 案例一:SparkSQL读取HDFS上Json格式的文件 案例二:DataFrame和Dataset和RDD之间的互相转换
-
centOS7下Spark安装配置教程详解
环境说明: 操作系统: centos7 64位 3台 centos7-1 192.168.190.130 master centos7-2 192.168.190.129 slave1 centos7-3 192.168.190.131 slave2 安装spark需要同时安装如下内容: jdk scale 1.安装jdk,配置jdk环境变量 这里不讲如何安装配置jdk,自行百度. 2.安装scala 下载scala安装包,https://www
-
mysql 5.7.13 安装配置方法图文教程(win10 64位)
本文实例为大家分享了mysql 5.7.13 winx64安装配置方法图文教程,供大家参考,具体内容如下 (1) 下载MySQL程序,您可以从MySQL官网上下载,或者点击这里下载 (2) 解压mysql-5.7.13-winx64.zip文件到你想安装的目录,我的例子是 D:\program\mysql-5.7.13-winx64.其中的目录结构如下: 文件夹:bin docs include lib share 文件: COPYING README my-default.ini (3) 拷贝
-
mysql 5.7.15 安装配置方法图文教程(windows)
因本人需要需要安装MySQL,现将安装过程记录如下,在自己记录的同时,希望对有疑问的人有所帮助. 一.下载软件 1. 进入mysql官网,登陆自己的oracle账号(没有账号的自己注册一个),下载Mysql-5.7.15,下载地址:http://dev.mysql.com/downloads/mysql/ 2.将下载好的文件解压到指定目录,笔者解压在D:\mysql-5.7.15-winx64 二. 安装过程 1.首先配置环境变量path,将D:\mysql-5.7.15-winx64\bin配
-
springboot配置内存数据库H2教程详解
业务背景:因soa系统要供外网访问,处于安全考虑用springboot做了个前置模块,用来转发外网调用的请求和soa返回的应答.其中外网的请求接口地址在DB2数据库中对应专门的一张表来维护,要是springboot直接访问数据库,还要专门申请权限等,比较麻烦,而一张表用内置的H2数据库维护也比较简单,就可以作为替代的办法. 环境:springboot+maven3.3+jdk1.7 1.springboot的Maven工程结构 说明一下,resource下的templates文件夹没啥用.我忘记
-
Windows下mysql5.7.10安装配置方法图文教程
MySQL针对不同的用户提供了2种不同的版本: MySQL Community Server:社区版.由MySQL开源社区开发者和爱好者提供技术支持,对开发者开放源代码并提供免费下载.MySQL Enterprise Server:企业版.包括最全面的高级功能和管理工具,不过对用户收费. 下面讲到的MySQL安装都是以免费开源的社区版为基础.打开MySQL数据库官网的下载地址,上面提供了两种安装文件,一种是直接安装的MSI安装文件,另一种是需要解压并配置的压缩包文件.我这里用的是5.7.10版本
-
Spark SQL常见4种数据源详解
通用load/write方法 手动指定选项 Spark SQL的DataFrame接口支持多种数据源的操作.一个DataFrame可以进行RDDs方式的操作,也可以被注册为临时表.把DataFrame注册为临时表之后,就可以对该DataFrame执行SQL查询. Spark SQL的默认数据源为Parquet格式.数据源为Parquet文件时,Spark SQL可以方便的执行所有的操作. 修改配置项spark.sql.sources.default,可修改默认数据源格式. scala> val
-
springcloud alibaba nacos linux配置的详细教程
首先从github上下载nacos的压缩包:https://github.com/alibaba/nacos/releases 下载完成之后,通过WinSCP把文件传到linux服务器上 接着通过tar -zxvf命令将此压缩包解压 解压完成之后,进入conf目录下的 clusmter.conf文件打开并在里面加上 通过:wq命令保存退出 接着通过vim命令进入startup.sh 此处修改完成之后,找到这个文件最下面的位置 添加红框中的相关配置,保存退出 接着进入nginx的conf文件中 找
-
postgresql安装及配置超详细教程
1. 安装 根据业务需求选择版本,官网下载 yum install https://download.postgresql.org/pub/repos/yum/9.6/redhat/rhel-7-x86_64/pgdg-centos96-9.6-3.noarch.rpm yum install postgresql96 postgresql96-server rpm -qa|grep postgre 初始化数据库 执行完初始化任务之后,postgresql 会自动创建和生成两个用户和一个数据库: