反向传播BP学习算法Gradient Descent的推导过程
目录
- 1.定义Loss Function
- 2.Gradient Descent
- 3.求偏微分
- 4.反向传播
- 5.总结
BP算法是适用于多层神经网络的一种算法,它是建立在梯度下降法的基础上的。本文着重推导怎样利用梯度下降法来minimise Loss Function。
给出多层神经网络的示意图:

1.定义Loss Function

每一个输出都对应一个损失函数L,将所有L加起来就是total loss。
那么每一个L该如何定义呢?这里还是采用了交叉熵,如下所示:


最终Total Loss的表达式如下:
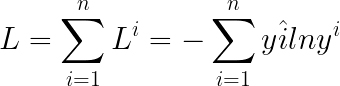
2.Gradient Descent
L对应了一个参数,即Network parameters θ(w1,w2…b1,b2…),那么Gradient Descent就是求出参数 θ∗来minimise Loss Function,即:

梯度下降的具体步骤为:

3.求偏微分
从上图可以看出,这里难点主要是求偏微分,由于L是所有损失之和,因此我们只需要对其中一个损失求偏微分,最后再求和即可。
先抽取一个简单的神经元来解释:




因为我们并不知道后面到底有多少层,也不知道情况到底有多复杂,我们不妨先取一种最简单的情况,如下所示:

4.反向传播

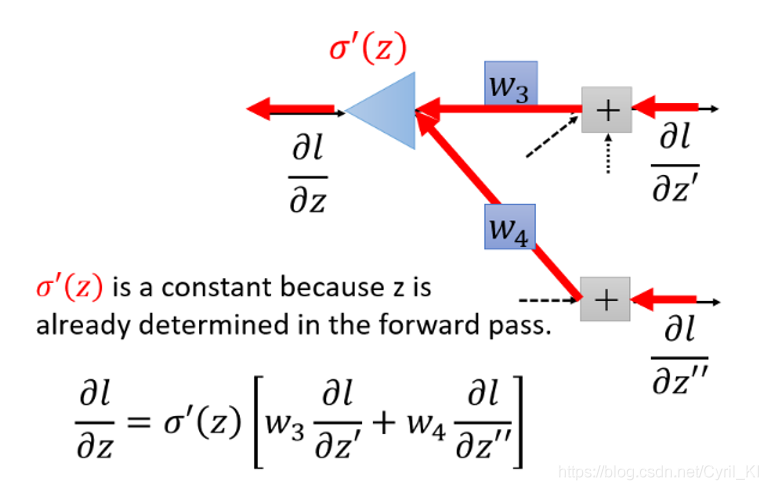
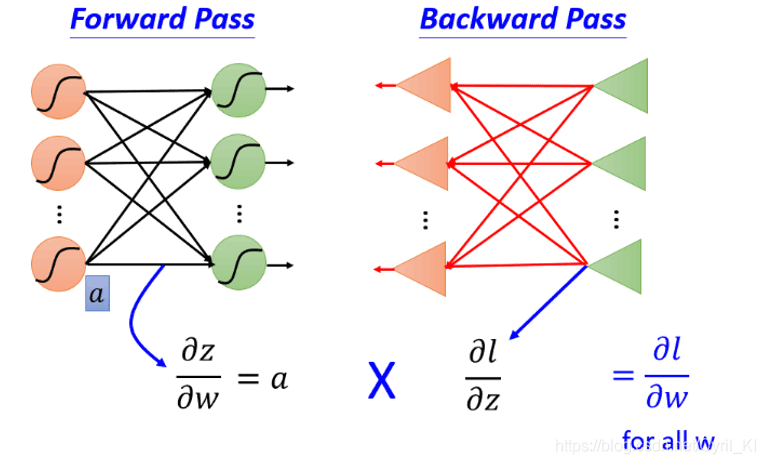
l对两个z的偏导我们假设是已知的,并且在这里是作为输入,三角形结构可以理解为一个乘法运算电路,其放大系数为 σ′(z)。但是在实际情况中,l对两个z的偏导是未知的。假设神经网络最终的结构就是如上图所示,那么我们的问题已经解决了:
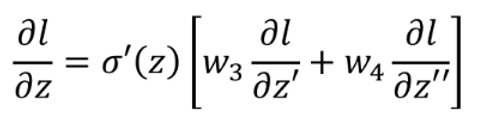
其中:

但是假如该神经元不是最后一层,我们又该如何呢?比如又多了一层,如下所示:
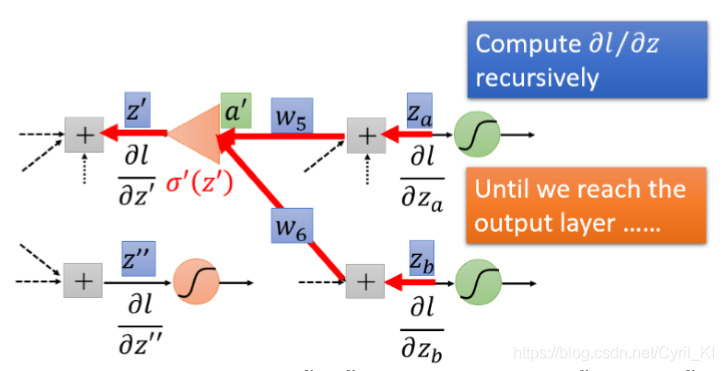

原理跟上面类似,如下所示:
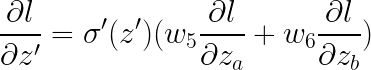

那假设我们再加一层呢?再加两层呢?再加三层呢?。。。,情况还是一样的,还是先求l对最后一层z的导数,乘以权重相加后最后再乘上 σ′(z′′,z′′′,...)即可。
最后给一个实例:
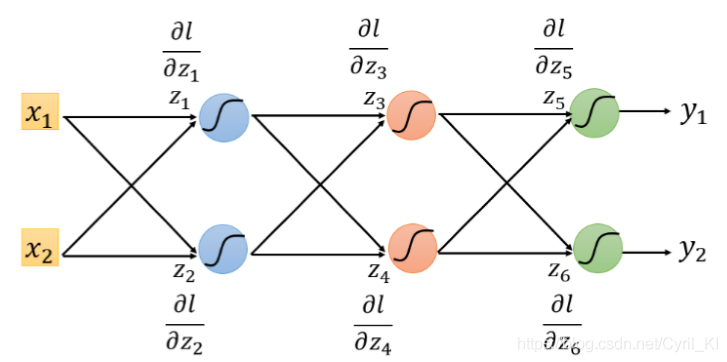
它的反向传播图长这样:
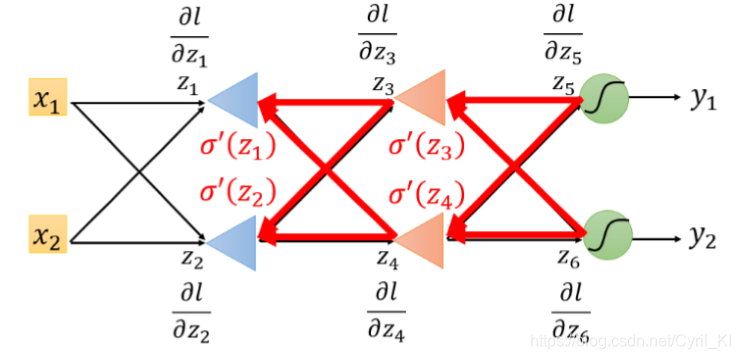

我们不难发现,这种计算方式很清楚明了地体现了“反向传播”四个字。好了,目标达成!!
5.总结

以上就是反向传播BP学习算法-Gradient Descent的推导过程的详细内容,更多关于BP反向传播Gradient Descent推导的资料请关注我们其它相关文章!
相关推荐
-

Python机器学习应用之基于BP神经网络的预测篇详解
目录 一.Introduction 1 BP神经网络的优点 2 BP神经网络的缺点 二.实现过程 1 Demo 2 基于BP神经网络的乳腺癌分类预测 三.Keys 一.Introduction 1 BP神经网络的优点 非线性映射能力:BP神经网络实质上实现了一个从输入到输出的映射功能,数学理论证明三层的神经网络就能够以任意精度逼近任何非线性连续函数.这使得其特别适合于求解内部机制复杂的问题,即BP神经网络具有较强的非线性映射能力. 自学习和自适应能力:BP神经网络在训练时,能够通过学习自动提取输
-
Python实现的三层BP神经网络算法示例
本文实例讲述了Python实现的三层BP神经网络算法.分享给大家供大家参考,具体如下: 这是一个非常漂亮的三层反向传播神经网络的python实现,下一步我准备试着将其修改为多层BP神经网络. 下面是运行演示函数的截图,你会发现预测的结果很惊人! 提示:运行演示函数的时候,可以尝试改变隐藏层的节点数,看节点数增加了,预测的精度会否提升 import math import random import string random.seed(0) # 生成区间[a, b)内的随机数 def rand(
-
神经网络(BP)算法Python实现及应用
本文实例为大家分享了Python实现神经网络算法及应用的具体代码,供大家参考,具体内容如下 首先用Python实现简单地神经网络算法: import numpy as np # 定义tanh函数 def tanh(x): return np.tanh(x) # tanh函数的导数 def tan_deriv(x): return 1.0 - np.tanh(x) * np.tan(x) # sigmoid函数 def logistic(x): return 1 / (1 + np.exp(-x)
-
BP神经网络原理及Python实现代码
本文主要讲如何不依赖TenserFlow等高级API实现一个简单的神经网络来做分类,所有的代码都在下面:在构造的数据(通过程序构造)上做了验证,经过1个小时的训练分类的准确率可以达到97%. 完整的结构化代码见于:链接地址 先来说说原理 网络构造 上面是一个简单的三层网络:输入层包含节点X1 , X2:隐层包含H1,H2:输出层包含O1. 输入节点的数量要等于输入数据的变量数目. 隐层节点的数量通过经验来确定. 如果只是做分类,输出层一般一个节点就够了. 从输入到输出的过程 1.输入节点的输出等
-
反向传播BP学习算法Gradient Descent的推导过程
目录 1.定义Loss Function 2.Gradient Descent 3.求偏微分 4.反向传播 5.总结 BP算法是适用于多层神经网络的一种算法,它是建立在梯度下降法的基础上的.本文着重推导怎样利用梯度下降法来minimise Loss Function. 给出多层神经网络的示意图: 1.定义Loss Function 每一个输出都对应一个损失函数L,将所有L加起来就是total loss. 那么每一个L该如何定义呢?这里还是采用了交叉熵,如下所示: 最终Total Loss的表达式
-
吴恩达机器学习练习:神经网络(反向传播)
1 Neural Networks 神经网络 1.1 Visualizing the data 可视化数据 这部分我们随机选取100个样本并可视化.训练集共有5000个训练样本,每个样本是20*20像素的数字的灰度图像.每个像素代表一个浮点数,表示该位置的灰度强度.20×20的像素网格被展开成一个400维的向量.在我们的数据矩阵X中,每一个样本都变成了一行,这给了我们一个5000×400矩阵X,每一行都是一个手写数字图像的训练样本. import numpy as np import matpl
-
python里反向传播算法详解
反向传播的目的是计算成本函数C对网络中任意w或b的偏导数.一旦我们有了这些偏导数,我们将通过一些常数 α的乘积和该数量相对于成本函数的偏导数来更新网络中的权重和偏差.这是流行的梯度下降算法.而偏导数给出了最大上升的方向.因此,关于反向传播算法,我们继续查看下文. 我们向相反的方向迈出了一小步--最大下降的方向,也就是将我们带到成本函数的局部最小值的方向. 图示演示: 反向传播算法中Sigmoid函数代码演示: # 实现 sigmoid 函数 return 1 / (1 + np.exp(-x))
-
Python实现的人工神经网络算法示例【基于反向传播算法】
本文实例讲述了Python实现的人工神经网络算法.分享给大家供大家参考,具体如下: 注意:本程序使用Python3编写,额外需要安装numpy工具包用于矩阵运算,未测试python2是否可以运行. 本程序实现了<机器学习>书中所述的反向传播算法训练人工神经网络,理论部分请参考我的读书笔记. 在本程序中,目标函数是由一个输入x和两个输出y组成, x是在范围[-3.14, 3.14]之间随机生成的实数,而两个y值分别对应 y1 = sin(x),y2 = 1. 随机生成一万份训练样例,经过网络的学
-
numpy实现神经网络反向传播算法的步骤
一.任务 实现一个4 层的全连接网络实现二分类任务,网络输入节点数为2,隐藏层的节点数设计为:25,50,25,输出层2 个节点,分别表示属于类别1 的概率和类别2 的概率,如图所示.我们并没有采用Softmax 函数将网络输出概率值之和进行约束,而是直接利用均方差误差函数计算与One-hot 编码的真实标签之间的误差,所有的网络激活函数全部采用Sigmoid 函数,这些设计都是为了能直接利用梯度推导公式. 二.数据集 通过scikit-learn 库提供的便捷工具生成2000 个线性不可分的2
-
PyTorch: 梯度下降及反向传播的实例详解
线性模型 线性模型介绍 线性模型是很常见的机器学习模型,通常通过线性的公式来拟合训练数据集.训练集包括(x,y),x为特征,y为目标.如下图: 将真实值和预测值用于构建损失函数,训练的目标是最小化这个函数,从而更新w.当损失函数达到最小时(理想上,实际情况可能会陷入局部最优),此时的模型为最优模型,线性模型常见的的损失函数: 线性模型例子 下面通过一个例子可以观察不同权重(w)对模型损失函数的影响. #author:yuquanle #data:2018.2.5 #Study of Linear
-
TensorFlow如何实现反向传播
使用TensorFlow的一个优势是,它可以维护操作状态和基于反向传播自动地更新模型变量. TensorFlow通过计算图来更新变量和最小化损失函数来反向传播误差的.这步将通过声明优化函数(optimization function)来实现.一旦声明好优化函数,TensorFlow将通过它在所有的计算图中解决反向传播的项.当我们传入数据,最小化损失函数,TensorFlow会在计算图中根据状态相应的调节变量. 回归算法的例子从均值为1.标准差为0.1的正态分布中抽样随机数,然后乘以变量A,损失函
-
pytorch .detach() .detach_() 和 .data用于切断反向传播的实现
当我们再训练网络的时候可能希望保持一部分的网络参数不变,只对其中一部分的参数进行调整:或者值训练部分分支网络,并不让其梯度对主网络的梯度造成影响,这时候我们就需要使用detach()函数来切断一些分支的反向传播 1 detach()[source] 返回一个新的Variable,从当前计算图中分离下来的,但是仍指向原变量的存放位置,不同之处只是requires_grad为false,得到的这个Variable永远不需要计算其梯度,不具有grad. 即使之后重新将它的requires_grad
-
pytorch loss反向传播出错的解决方案
今天在使用pytorch进行训练,在运行 loss.backward() 误差反向传播时出错 : RuntimeError: grad can be implicitly created only for scalar outputs File "train.py", line 143, in train loss.backward() File "/usr/local/lib/python3.6/dist-packages/torch/tensor.py", li