使用Python和百度语音识别生成视频字幕的实现
从视频中提取音频
安装 moviepy
pip install moviepy
相关代码:
audio_file = work_path + '\\out.wav' video = VideoFileClip(video_file) video.audio.write_audiofile(audio_file,ffmpeg_params=['-ar','16000','-ac','1'])
根据静音对音频分段
使用音频库 pydub,安装:
pip install pydub
第一种方法:
# 这里silence_thresh是认定小于-70dBFS以下的为silence,发现小于 sound.dBFS * 1.3 部分超过 700毫秒,就进行拆分。这样子分割成一段一段的。
sounds = split_on_silence(sound, min_silence_len = 500, silence_thresh= sound.dBFS * 1.3)
sec = 0
for i in range(len(sounds)):
s = len(sounds[i])
sec += s
print('split duration is ', sec)
print('dBFS: {0}, max_dBFS: {1}, duration: {2}, split: {3}'.format(round(sound.dBFS,2),round(sound.max_dBFS,2),sound.duration_seconds,len(sounds)))

感觉分割的时间不对,不好定位,我们换一种方法:
# 通过搜索静音的方法将音频分段
# 参考:https://wqian.net/blog/2018/1128-python-pydub-split-mp3-index.html
timestamp_list = detect_nonsilent(sound,500,sound.dBFS*1.3,1)
for i in range(len(timestamp_list)):
d = timestamp_list[i][1] - timestamp_list[i][0]
print("Section is :", timestamp_list[i], "duration is:", d)
print('dBFS: {0}, max_dBFS: {1}, duration: {2}, split: {3}'.format(round(sound.dBFS,2),round(sound.max_dBFS,2),sound.duration_seconds,len(timestamp_list)))
输出结果如下:
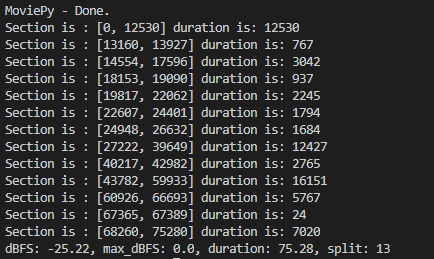
感觉这样好处理一些
使用百度语音识别
现在百度智能云平台创建一个应用,获取 API Key 和 Secret Key:

获取 Access Token
使用百度 AI 产品需要授权,一定量是免费的,生成字幕够用了。
'''
百度智能云获取 Access Token
'''
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode( 'utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req)
result_str = f.read()
except URLError as err:
print('token http response http code : ' + str(err.errno))
result_str = err.reason
if (IS_PY3):
result_str = result_str.decode()
print(result_str)
result = json.loads(result_str)
print(result)
if ('access_token' in result.keys() and 'scope' in result.keys()):
print(SCOPE)
if SCOPE and (not SCOPE in result['scope'].split(' ')): # SCOPE = False 忽略检查
raise DemoError('scope is not correct')
print('SUCCESS WITH TOKEN: %s EXPIRES IN SECONDS: %s' % (result['access_token'], result['expires_in']))
return result['access_token']
else:
raise DemoError('MAYBE API_KEY or SECRET_KEY not correct: access_token or scope not found in token response')
使用 Raw 数据进行合成
这里使用百度语音极速版来合成文字,因为官方介绍专有GPU服务集群,识别响应速度较标准版API提升2倍及识别准确率提升15%。适用于近场短语音交互,如手机语音搜索、聊天输入等场景。 支持上传完整的录音文件,录音文件时长不超过60秒。实时返回识别结果
def asr_raw(speech_data, token):
length = len(speech_data)
if length == 0:
# raise DemoError('file %s length read 0 bytes' % AUDIO_FILE)
raise DemoError('file length read 0 bytes')
params = {'cuid': CUID, 'token': token, 'dev_pid': DEV_PID}
#测试自训练平台需要打开以下信息
#params = {'cuid': CUID, 'token': token, 'dev_pid': DEV_PID, 'lm_id' : LM_ID}
params_query = urlencode(params)
headers = {
'Content-Type': 'audio/' + FORMAT + '; rate=' + str(RATE),
'Content-Length': length
}
url = ASR_URL + "?" + params_query
# print post_data
req = Request(ASR_URL + "?" + params_query, speech_data, headers)
try:
begin = timer()
f = urlopen(req)
result_str = f.read()
# print("Request time cost %f" % (timer() - begin))
except URLError as err:
# print('asr http response http code : ' + str(err.errno))
result_str = err.reason
if (IS_PY3):
result_str = str(result_str, 'utf-8')
return result_str
生成字幕
字幕格式: https://www.cnblogs.com/tocy/p/subtitle-format-srt.html
生成字幕其实就是语音识别的应用,将识别后的内容按照 srt 字幕格式组装起来就 OK 了。具体字幕格式的内容可以参考上面的文章,代码如下:
idx = 0
for i in range(len(timestamp_list)):
d = timestamp_list[i][1] - timestamp_list[i][0]
data = sound[timestamp_list[i][0]:timestamp_list[i][1]].raw_data
str_rst = asr_raw(data, token)
result = json.loads(str_rst)
# print("rst is ", result)
# print("rst is ", rst['err_no'][0])
if result['err_no'] == 0:
text.append('{0}\n{1} --> {2}\n'.format(idx, format_time(timestamp_list[i][0]/ 1000), format_time(timestamp_list[i][1]/ 1000)))
text.append( result['result'][0])
text.append('\n')
idx = idx + 1
print(format_time(timestamp_list[i][0]/ 1000), "txt is ", result['result'][0])
with open(srt_file,"r+") as f:
f.writelines(text)
总结
我在视频网站下载了一个视频来作测试,极速模式从速度和识别率来说都是最好的,感觉比网易见外平台还好用。
到此这篇关于使用Python和百度语音识别生成视频字幕的文章就介绍到这了,更多相关Python 百度语音识别生成视频字幕内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python语言实现百度语音识别API的使用实例
未来的一段时间,人工智能在市场上占有很重的位置,Python语言则是研究人工智能的最佳编程语言,下面,就让我们来感受一下它的魅力吧! 百度给的样例程序,不论C还是Java版,都分为method1和method2两种 前者称为隐式(post的是json串,音频数据编码到json里),后者称为显式(post的就是音频数据) 一开始考虑到pythonwave包处理的都是"字符串",担心跟C语言的数组不一致,所以选择低效但保险的method1, 即先将音频数据base64编码,再加上采样率.通
-

python调用百度语音识别api
最近在处理语音检索相关的事. 其中用到语音识别,调用的是讯飞与百度的api,前者使用js是实现,后者用python3实现(因为自己使用python) 环境: python3.5 centos 7 流程 整个百度语音识别rest api 使用分为三部分: 1 (申请操作)创建应用,获取应用的 API Key 以及 Secret Key. 2 (程序实现)通过已知的 应用的 API Key 以及 Secret Key, 发送post 请求到 https://openapi.baidu.com/oau
-
python实现百度语音识别api
本文实例为大家分享了ython实现百度语音识别的具体代码,供大家参考,具体内容如下 详细百度语音识别api文档 先下载python用SDK,可以用python setup.py install安装 # 引入Speech SDK from aip import AipSpeech # 定义常量 APP_ID = '你的 App ID' API_KEY = '你的 API Key' SECRET_KEY = '你的 Secret Key' # 初始化AipSpeech对象 aipSpeech = A
-
python版百度语音识别功能
本文实例为大家分享了python版百度语音识别功能的具体代码,供大家参考,具体内容如下 环境:使用的IDE是Pycharm 1.新建工程 2.配置百度语音识别环境 "File"--"Settings"打开设置面板,"Project"标签下添加Project Interpreter,点击右侧"+" 输入"baidu-aip",进行安装 新建测试文件 from aip import AipSpeech &quo
-
python调用百度语音识别实现大音频文件语音识别功能
本文为大家分享了python实现大音频文件语音识别功能的具体代码,供大家参考,具体内容如下 实现思路:先用ffmpeg将其他非wav格式的音频转换为wav格式,并转换音频的声道(百度支持声道为1),采样率(值为8000),格式转换完成后,再用ffmpeg将音频切成百度. 支持的时长(30秒和60秒2种,本程序用的是30秒). # coding: utf-8 import json import time import base64 from inc import rtysdb import ur
-
使用Python和百度语音识别生成视频字幕的实现
从视频中提取音频 安装 moviepy pip install moviepy 相关代码: audio_file = work_path + '\\out.wav' video = VideoFileClip(video_file) video.audio.write_audiofile(audio_file,ffmpeg_params=['-ar','16000','-ac','1']) 根据静音对音频分段 使用音频库 pydub,安装: pip install pydub 第一种方法: #
-
对Python+opencv将图片生成视频的实例详解
如下所示: import cv2 fps = 16 size = (width,height) videowriter = cv2.VideoWriter("a.avi",cv2.VideoWriter_fourcc('M','J','P','G'),fps,size) for i in range(1,200): img = cv2.imread('%d'.jpg % i) videowriter.write(img) 以上这篇对Python+opencv将图片生成视频的实例详解就是
-
Python结合百度语音识别实现实时翻译软件的实现
一.所需库安装 pip install PyAudio pip install SpeechRecognition pip install baidu-aip pip install Wave pip install Wheel pip install Pyinstaller 二.百度官网申请服务 三.源代码分享 import pyaudio import wave from aip import AipSpeech import time # 用Pyaudio库录制音频 # out_file:
-
基于python实现百度语音识别和图灵对话
图例如下 https://github.com/Dongvdong/python_Smartvoice 上电后,只要周围声音超过 2000,开始录音5S 录音上传百度识别,并返回结果文字输出 继续等待,周围声音是否超过2000,没有就等待. 点用电脑API语音交互 代码如下 # -*- coding: utf-8 -*- # 树莓派 from pyaudio import PyAudio, paInt16 import numpy as np from datetime import datet
-
python如何将图片生成视频MP4
目录 python图片生成视频MP4 python图片与视频互转(亲测有效) 图片转视频 总结 python图片生成视频MP4 import os import cv2 # 要被合成的多张图片所在文件夹 # 路径分隔符最好使用"/",而不是"\","\"本身有转义的意思:或者"\\"也可以. # 因为是文件夹,所以最后还要有一个"/" file_dir = 'C:/Users/YUXIAOYANG/Desk
-
python调用百度语音REST API
本文实例为大家分享了python调用百度语音REST API的具体代码,供大家参考,具体内容如下 (百度的rest接口的部分网址发生了一定的变化,相关代码已更新) 百度通过 REST API 的方式给开发者提供一个通用的 HTTP 接口,基于该接口,开发者可以轻松的获得语音合成与语音识别能力.SDK中只提供了PHP.C和JAVA的相关样例,使用python也可以灵活的对端口进行调用,本文描述了简单使用Python调用百度语音识别服务 REST API 的简单样例. 1.语音识别与语音合成的调用