SQL去重的3种实用方法总结
目录
- 1.distinct去重
- 2.group by去重
- 3.row_number() over (parttion by 分组列 order by 排序列)
- 补充:SQL根据某列或几列分组去重——row_number() over(partition by)的用法
- 总结
SQL去重的三种方法汇总
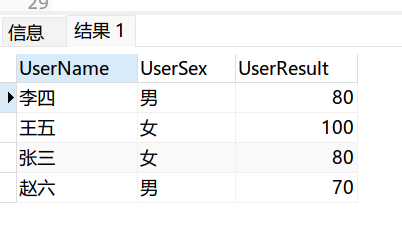
这里的去重是指:查询的时候, 不显示重复,并不是删除表中的重复项
1.distinct去重
注意的点:distinct
只能一列去重,当distinct后跟大于1个参数时,他们之间的关系是&&(逻辑与)关系,只有全部条件相同才会去重
弊端:当查询的字段比较多时,distinct会作用多个字段,导致去重条件增多
select distinct UserResult from Table1

2.group by去重
去重原理:将重复的行进行分组,相同的数据只显示第一行
弊端:使用group by后,所有查询字段都需要使用聚合函数,比较繁琐
select min(UserName)UserName,min(UserSex)UserSex,min(UserSubject)UserSubject,min(UserResult)UserResult from Table1 group by UserResult
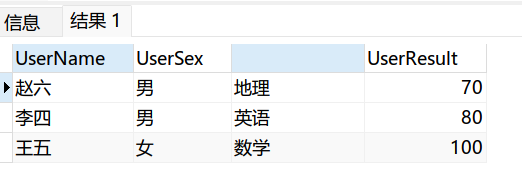
3.row_number() over (parttion by 分组列 order by 排序列)
弊端:小孟还不知道
去重原理:现根据重复列进行分组,分组后再进行排序,不同的组序号为1,相同的组序号为2,排除为2的就达到了去重效果
select *from ( --查询出重复行 select *,row_number() over (partition by UserResult order by UserResult desc)num from Table1 )A where A.num=1
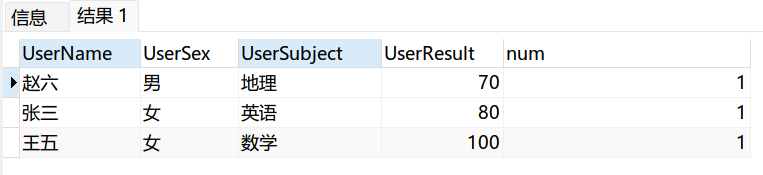
这里安利第三个,row_number(),稳一些!
补充:SQL根据某列或几列分组去重——row_number() over(partition by)的用法
有时利用SQL进行数据处理会发现,要根据某列或某几列选取信息,由于其他列不同而出现了多次,如运行程序1的结果图1:
程序1:
--程序1:要解决的问题
select a.*
from AShareEarningEst a
where a.S_INFO_WINDCODE in ('000650.SZ')
and a.REPORTING_PERIOD = 20181231
order by a.RESEARCH_INST_NAME,a.EST_DT
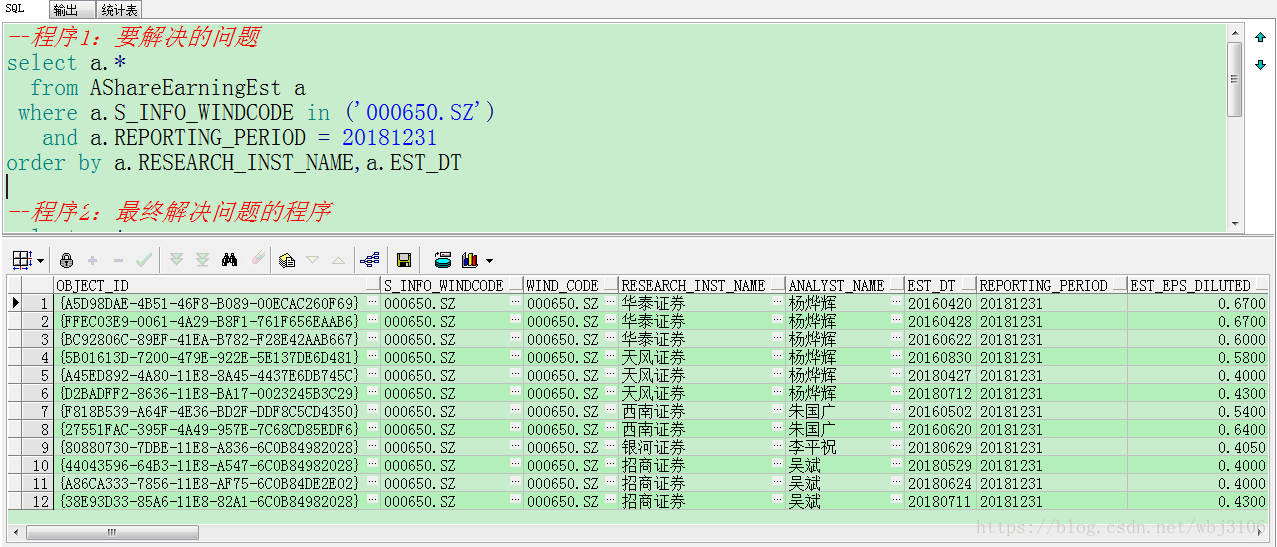
我们看到,在AShareEarningEst(中国A股盈利预测明细)表中,共有12人次的证券公司研究员,对000650.SZ(仁和药业)公司的20181231报告期进行预测。例:华泰证券的杨烨辉在20160420、20160428和20160622分别对000650.SZ(仁和药业)发布研究报告进行了预测。现在,我们只需要同一家证券公司的同一个研究员(此处假定同一家证券公司的研究员姓名相同时,即为同一个研究员)做出的最新预测数据,即根据证券公司名称、研究员姓名,同时根据估计日期进行筛选。
此时,可根据row_number() over(partition by)进行处理,运行程序2结果如图2:
程序2:
--程序2:最终解决问题的程序
select b.*
from (select row_number() over(partition by a.RESEARCH_INST_NAME,
a.ANALYST_NAME order by est_dt desc) as rn,
--根据RESEARCH_INST_NAME(证券公司名称)和ANALYST_NAME(研究员名字)进行分类,
--同时根据est_dt(估计日期)倒序排序,即最新日期排在同一分类的上方,此时构建出rn为
a.*
from wdzx.AShareEarningEst a
where a.S_INFO_WINDCODE in ('000650.SZ') --, '000951.SZ', '600006.SH', '600166.SH')
and a.REPORTING_PERIOD = 20181231) b --将分类后的程序构成表b。可以先运行b的程序观察结果
where b.rn = 1--运用表b的结果进行子查询,rn=1即为所需结果

此时,即主要利用了row_number() over(partition by)函数筛选出了去重后的结果。
总结
到此这篇关于SQL去重的3种实用方法的文章就介绍到这了,更多相关SQL去重内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL 数据查重、去重的实现语句
有一个表user,字段分别有id.nick_name.password.email.phone. 一.单字段(nick_name) 查出所有有重复记录的所有记录 select * from user where nick_name in (select nick_name from user group by nick_name having count(nick_name)>1); 查出有重复记录的各个记录组中id最大的记录 select * from user where id in (se
-
MySQL去重的方法整理
MySQL去重的方法整理 [初级]有极少的重复行 使用distinct查出来,然后手动一行一行删除. [中级]按照单个字段的重复去重 例如:对id字段去重 使用方法:获取id的重复字段的值,利用相同id字段所在的行中,比较出数据不同的字段,删除 除了最小(或最大)的字段所在的该行之外的所有重复的行.一般使用主键来比较,因为主键的值一定是唯一值,绝对不相同. id name 1 a 1 b 2 c 2 a 3 c 结果: id name 1 a 2 a 操作: delete from a_tmp
-

详解mysql数据去重的三种方式
目录 一.背景 二.数据去重三种方法使用 1.通过MySQL DISTINCT:去重(过滤重复数据) 2.group by 3.row_number窗口函数 三.总结 一.背景 最近在和系统模块做数据联调,其中有一个需求是将两个角色下的相关数据对比后将最新的数据返回出去,于是就想到了去重,再次做一个总结. 二.数据去重三种方法使用 1.通过MySQL DISTINCT:去重(过滤重复数据) 1.1.在使用 mysql SELECT 语句查询数据的时候返回的是所有匹配的行. SELECT
-
一条sql语句完成MySQL去重留一
前几天在做一个需求的时候,需要清理mysql中重复的记录,当时的想法是通过代码遍历写出来,然后觉得太复杂,心里想着应该可以通过一个sql语句来解决问题的.查了资料,请教了大佬之后得出了一个很便利的sql语句,这里分享下这段sql语句和思路. 需求分析 数据库中存在重复记录,删除保留其中一条(是否重复判断基准为多个字段) 解决方案 碰到这个需求的时候,心里大概是有思路的.最快想到的是可以通过一条sql语句来解决,无奈自己对于复杂sql语句的道行太浅,所以想找大佬帮忙. 找人帮忙 因为这个需求有点着
-
SQL学习笔记五去重,给新加字段赋值的方法
去掉数据重复 增加两个字段 alter TABLE T_Employee Add FSubCompany VARchar(20); ALTER TABLE T_Employee ADD FDepartment VARCHAR(20); 给新加的字段赋值 UPDATE T_Employee SET FSubCompany='Beijing',FDepartment='Development' where FNumber='DEV001'; UPDATE T_Employee SET FSubCom
-
SQL分组排序去重复的小实例
复制代码 代码如下: SELECT *FROM ( SELECT userid, classid, remark, ROW_NUMBER () OVER ( PARTITION BY userid, classid ORDER BY addtime DESC
-
浅谈sql数据库去重
关于sql去重,我简单谈一下自己的简介,如果各位有建议或有不明白的欢迎多多指出. 关于sql去重最常见的有两种方式:DISTINCT和ROW_NUMBER(),当然了ROW_NUMBER()除了去重还有很多其他比较重要的功能,一会我给大家简单说说我自己在实际中用到的. 假如有张UserInfo表,如下图: 现在我们要去掉完全重复的数据:SELECT DISTINCT * FROM dbo.UserInfo结果如下图: 但是现在有个新的需求,要把名字为'张三'的去重,也就是相同名字的只要一条数
-
SQL去重的3种实用方法总结
目录 1.distinct去重 2.group by去重 3.row_number() over (parttion by 分组列 order by 排序列) 补充:SQL根据某列或几列分组去重——row_number() over(partition by)的用法 总结 SQL去重的三种方法汇总 这里的去重是指:查询的时候, 不显示重复,并不是删除表中的重复项 1.distinct去重 注意的点:distinct 只能一列去重,当distinct后跟大于1个参数时,他们之间的关系是&&
-
js 数组去重的四种实用方法
面试前端必须准备的一个问题:怎样去掉Javascript的Array的重复项.据我所知,百度.腾讯.盛大等都在面试里出过这个题目.这个问题看起来简单,但是其实暗藏杀机. 考的不仅仅是实现这个功能,更能看出你对计算机程序执行的深入理解. 我总共想出了三种算法来实现这个目的: Array.prototype.unique1 = function() { var n = []; //一个新的临时数组 for(var i = 0; i < this.length; i++) //遍历当前数组 { //如
-
SQL查询语句优化的实用方法总结
查询语句的优化是SQL效率优化的一个方式,可以通过优化sql语句来尽量使用已有的索引,避免全表扫描,从而提高查询效率.最近在对项目中的一些sql进行优化,总结整理了一些方法. 1.在表中建立索引,优先考虑where.group by使用到的字段. 2.尽量避免使用select *,返回无用的字段会降低查询效率.如下: SELECT * FROM t 优化方式:使用具体的字段代替*,只返回使用到的字段. 3.尽量避免使用in 和not in,会导致数据库引擎放弃索引进行全表扫描.如下: SELEC
-
python列表去重的5种常见方法实例
目录 前言 一.使用for循环实现列表去重 二.使用列表推导式去重 三.使用集合转换函数set()实现列表去重 四.使用新建字典方式实现列表去重 五.删除列表中存在重复的数据 附:Python 二维数组元素去重 np.unique()函数的使用 总结 前言 列表去重在python实际运用中,十分常见,也是最基础的重点知识. 以下总结了5种常见的列表去重方法 一.使用for循环实现列表去重 此方法去重后,原顺序保持不变. # for循环实现列表去重 list1 = ['a', 'b', 1, 3,
-
SQL注入的四种防御方法总结
目录 前言 限制数据类型 正则表达式匹配传入参数 函数过滤转义 预编译语句 总结 前言 最近了解到安全公司的面试中都问到了很多关于SQL注入的一些原理和注入类型的问题,甚至是SQL注入的防御方法.SQL注入真的算是web漏洞中的元老了,著名且危害性极大.下面这里就简单的分享一下我总结的四种SQL注入防御手段,加深理解,方便下次遇到这种问题时可以直接拿来使用.(主要是怕面试中脑壳打铁,这种情况太常见了) SQL注入占我们渗透学习中极大地一部分,拥有这很重要的地位.随着防御手段的不段深入,市面上存在
-
k8s查看pod日志的几种实用方法汇总
目录 通过kubectl 通过rancher rancher 2.5 rancher 2.6 总结 通过kubectl kubectl logs [-f] [-p] (POD | TYPE/NAME) [-c CONTAINER] 参数 简写 默认值 说明 container c 打印指定容器的日志 all-containers false 获取pod中所有容器的日志. selector l 通过标签筛选pod,支持 ‘=’.‘==’ 和 ‘!=’.例如 -l key1=value1
-
PHP中将ip地址转成十进制数的两种实用方法
PHP中如何将ip地址转成十进制数呢?现在PHP中有很多时候都会用到ip地址,但是这个ip地址获取的时候都不是10进制的.那么PHP中如何将ip地址转成十进制数就是我们比较头疼的事情了,下面两种方法是我整理处理来相对比较简单的IP地址转成十进制数的方法.希望能对大家有所帮助. 方法一: 复制代码 代码如下: public function ipToLong(){ $ip = $_SERVER['REMOTE_ADDR']; $ip = explode('.', $ip); $ip = array
-
js实现跨域的4种实用方法原理分析
什么是js跨域呐? js跨域是指通过js在不同的域之间进行数据传输或通信,比如用ajax向一个不同的域请求数据,或者通过js获取页面中不同域的框架中(iframe)的数据.只要协议.域名.端口有任何一个不同,都被当作是不同的域. 要解决跨域的问题,我们可以使用以下几种方法: 一.通过jsonp跨域 在js中,我们直接用XMLHttpRequest请求不同域上的数据时,是不可以的.但是,在页面上引入不同域上的js脚本文件却是可以的,jsonp正是利用这个特性来实现的. 比如,有个a.html页面,
-
JS判断数组中是否有重复值得三种实用方法
方法一: 复制代码 代码如下: var ary = new Array("111","22","33","111"); var s = ary.join(",")+","; for(var i=0;i<ary.length;i++) { if(s.replace(ary[i]+",","").indexOf(ary[i]+",&qu
-
js去除空格的12种实用方法
实现1 String.prototype.trim = function() { return this.replace(/^\s\s*/, '').replace(/\s\s*$/, ''); } 看起来不怎么样, 动用了两次正则替换,实际速度非常惊人,主要得益于浏览器的内部优化.一个著名的例子字符串拼接,直接相加比用Array做成的StringBuffer 还快.base2类库使用这种实现. 实现2 String.prototype.trim = function() { return th