pytorch模型保存与加载中的一些问题实战记录
目录
- 前言
- 一、torch中模型保存和加载的方式
- 1、模型参数和模型结构保存和加载
- 2、只保存模型的参数和加载——这种方式比较安全,但是比较稍微麻烦一点点
- 二、torch中模型保存和加载出现的问题
- 1、单卡模型下保存模型结构和参数后加载出现的问题
- 2、多卡机器单卡训练模型保存后在单卡机器上加载会报错
- 3、多卡训练模型保存模型结构和参数后加载出现的问题
- 三、正确的保存模型和加载的方法
- 总结
前言
最近使用pytorch训练模型,保存模型后再次加载使用出现了一些问题。记录一下解决方案!
一、torch中模型保存和加载的方式
1、模型参数和模型结构保存和加载
torch.save(model,path) torch.load(path)
2、只保存模型的参数和加载——这种方式比较安全,但是比较稍微麻烦一点点
torch.save(model.state_dict(),path) model_state_dic = torch.load(path) model.load_state_dic(model_state_dic)
二、torch中模型保存和加载出现的问题
1、单卡模型下保存模型结构和参数后加载出现的问题
模型保存的时候会把模型结构定义文件路径记录下来,加载的时候就会根据路径解析它然后装载参数;当把模型定义文件路径修改以后,使用torch.load(path)就会报错。
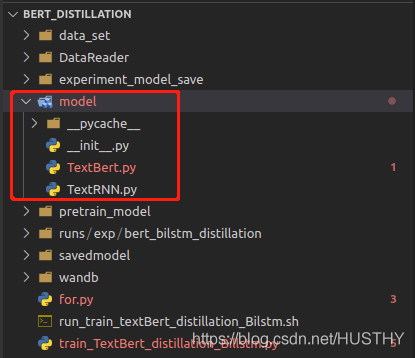
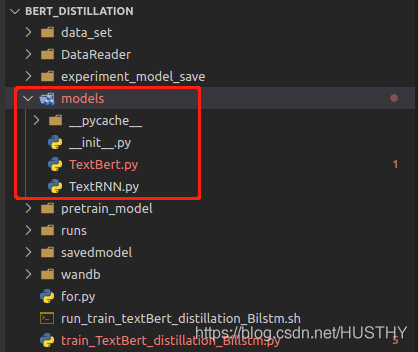

把model文件夹修改为models后,再加载就会报错。
import torch
from model.TextRNN import TextRNN
load_model = torch.load('experiment_model_save/textRNN.bin')
print('load_model',load_model)
这种保存完整模型结构和参数的方式,一定不要改动模型定义文件路径。
2、多卡机器单卡训练模型保存后在单卡机器上加载会报错
在多卡机器上有多张显卡0号开始,现在模型在n>=1上的显卡训练保存后,拷贝在单卡机器上加载
import torch
from model.TextRNN import TextRNN
load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin')
print('load_model',load_model)
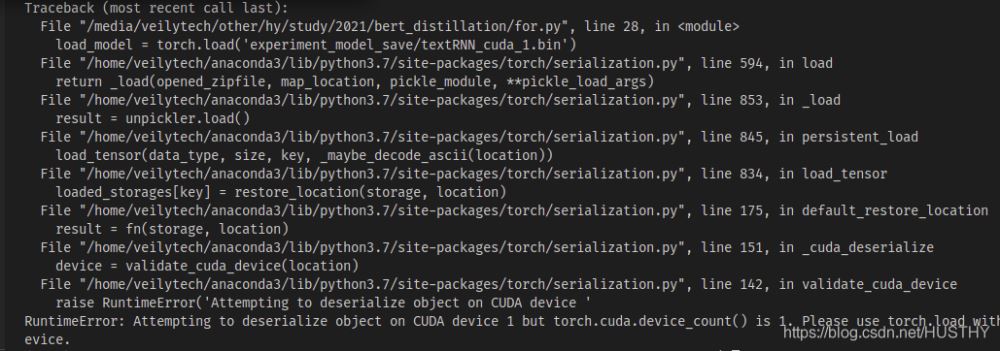
会出现cuda device不匹配的问题——你保存的模代码段 小部件型是使用的cuda1,那么采用torch.load()打开的时候,会默认的去寻找cuda1,然后把模型加载到该设备上。这个时候可以直接使用map_location来解决,把模型加载到CPU上即可。
load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin',map_location=torch.device('cpu'))
3、多卡训练模型保存模型结构和参数后加载出现的问题
当用多GPU同时训练模型之后,不管是采用模型结构和参数一起保存还是单独保存模型参数,然后在单卡下加载都会出现问题
a、模型结构和参数一起保然后在加载

torch.distributed.init_process_group(backend='nccl')
模型训练的时候采用上述多进程的方式,所以你在加载的时候也要声明,不然就会报错。
b、单独保存模型参数
model = Transformer(num_encoder_layers=6,num_decoder_layers=6)
state_dict = torch.load('train_model/clip/experiment.pt')
model.load_state_dict(state_dict)
同样会出现问题,不过这里出现的问题是参数字典的key和模型定义的key不一样

原因是多GPU训练下,使用分布式训练的时候会给模型进行一个包装,代码如下:
model = torch.load('train_model/clip/Vtransformers_bert_6_layers_encoder_clip.bin')
print(model)
model.cuda(args.local_rank)
。。。。。。
model = nn.parallel.DistributedDataParallel(model,device_ids=[args.local_rank],find_unused_parameters=True)
print('model',model)
包装前的模型结构:
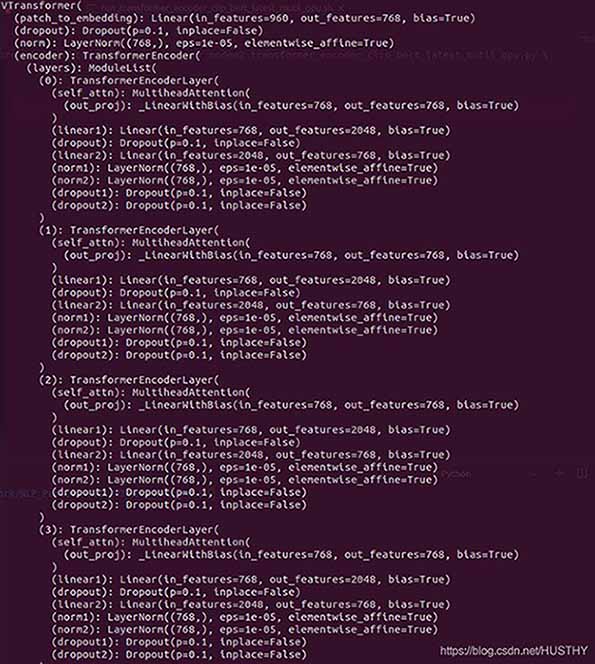
包装后的模型
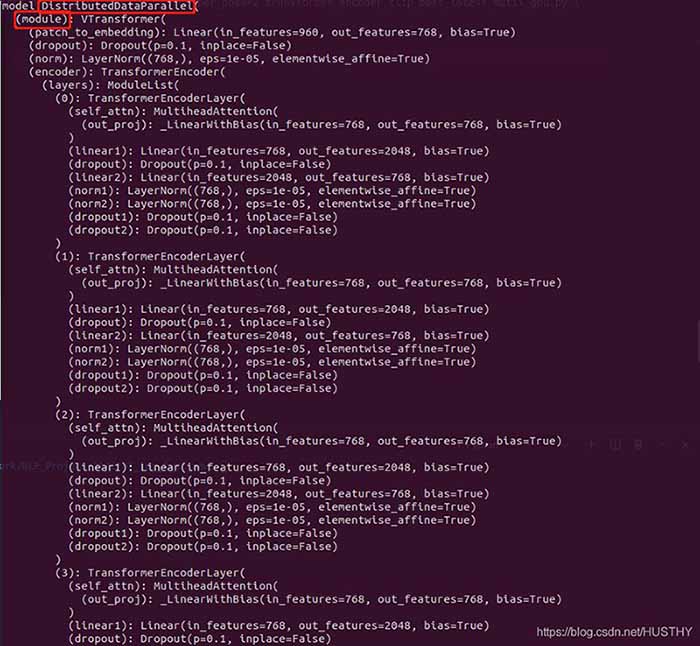
在外层多了DistributedDataParallel以及module,所以才会导致在单卡环境下加载模型权重的时候出现权重的keys不一致。
三、正确的保存模型和加载的方法
if gpu_count > 1:
torch.save(model.module.state_dict(),save_path)
else:
torch.save(model.state_dict(),save_path)
model = Transformer(num_encoder_layers=6,num_decoder_layers=6)
state_dict = torch.load(save_path)
model.load_state_dict(state_dict)
这样就是比较好的范式,加载不会出错。
总结
到此这篇关于pytorch模型保存与加载中的一些问题的文章就介绍到这了,更多相关pytorch模型保存与加载内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pytorch加载部分预训练模型的参数实例
前言 自从从深度学习框架caffe转到Pytorch之后,感觉Pytorch的优点妙不可言,各种设计简洁,方便研究网络结构修改,容易上手,比TensorFlow的臃肿好多了.对于深度学习的初学者,Pytorch值得推荐.今天主要主要谈谈Pytorch是如何加载预训练模型的参数以及代码的实现过程. 直接加载预选脸模型 如果我们使用的模型和预训练模型完全一样,那么我们就可以直接加载别人的模型,还有一种情况,我们在训练自己模型的过程中,突然中断了,但只要我们保存了之前的模型的参数也可以使用下面的代码直
-

PyTorch深度学习模型的保存和加载流程详解
一.模型参数的保存和加载 torch.save(module.state_dict(), path):使用module.state_dict()函数获取各层已经训练好的参数和缓冲区,然后将参数和缓冲区保存到path所指定的文件存放路径(常用文件格式为.pt..pth或.pkl). torch.nn.Module.load_state_dict(state_dict):从state_dict中加载参数和缓冲区到Module及其子类中 . torch.nn.Module.state_dict()函数
-
PyTorch 多GPU下模型的保存与加载(踩坑笔记)
这几天在一机多卡的环境下,用pytorch训练模型,遇到很多问题.现总结一个实用的做实验方式: 多GPU下训练,创建模型代码通常如下: os.environ['CUDA_VISIBLE_DEVICES'] = args.cuda model = MyModel(args) if torch.cuda.is_available() and args.use_gpu: model = torch.nn.DataParallel(model).cuda() 官方建议的模型保存方式,只保存参数: tor
-
PyTorch模型保存与加载实例详解
目录 一个简单的例子 保存/加载 state_dict(推荐) 保存/加载整个模型 保存加载用于推理的常规Checkpoint/或继续训练 保存多个模型到一个文件 使用其他模型来预热当前模型 跨设备保存与加载模型 总结 torch.save:保存序列化的对象到磁盘,使用了Python的pickle进行序列化,模型.张量.所有对象的字典. torch.load:使用了pickle的unpacking将pickled的对象反序列化到内存中. torch.nn.Module.load_state_di
-
PyTorch模型的保存与加载方法实例
目录 模型的保存与加载 保存和加载模型参数 保存和加载模型参数与结构 总结 模型的保存与加载 首先,需要导入两个包 import torch import torchvision.models as models 保存和加载模型参数 PyTorch模型将学习到的参数存储在一个内部状态字典中,叫做state_dict.这可以通过torch.save方法来实现.我们导入预训练好的VGG16模型,并将其保存.我们将state_dict字典保存在model_weights.pth文件中. model =
-
基于pytorch的保存和加载模型参数的方法
当我们花费大量的精力训练完网络,下次预测数据时不想再(有时也不必再)训练一次时,这时候torch.save(),torch.load()就要登场了. 保存和加载模型参数有两种方式: 方式一: torch.save(net.state_dict(),path): 功能:保存训练完的网络的各层参数(即weights和bias) 其中:net.state_dict()获取各层参数,path是文件存放路径(通常保存文件格式为.pt或.pth) net2.load_state_dict(torch.loa
-
pytorch模型的保存和加载、checkpoint操作
其实之前笔者写代码的时候用到模型的保存和加载,需要用的时候就去度娘搜一下大致代码,现在有时间就来整理下整个pytorch模型的保存和加载,开始学习把~ pytorch的模型和参数是分开的,可以分别保存或加载模型和参数.所以pytorch的保存和加载对应存在两种方式: 1. 直接保存加载模型 (1)保存和加载整个模型 # 保存模型 torch.save(model, 'model.pth\pkl\pt') #一般形式torch.save(net, PATH) # 加载模型 model = torc
-
pytorch 加载(.pth)格式的模型实例
有一些非常流行的网络如 resnet.squeezenet.densenet等在pytorch里面都有,包括网络结构和训练好的模型. pytorch自带模型网址:https://pytorch-cn.readthedocs.io/zh/latest/torchvision/torchvision-models/ 按官网加载预训练好的模型: import torchvision.models as models # pretrained=True就可以使用预训练的模型 resnet18 = mod
-
PyTorch加载预训练模型实例(pretrained)
使用预训练模型的代码如下: # 加载预训练模型 resNet50 = models.resnet50(pretrained=True) ResNet50 = ResNet(Bottleneck, [3, 4, 6, 3], num_classes=2) # 读取参数 pretrained_dict = resNet50.state_dict() model_dict = ResNet50.state_dict() # 将pretained_dict里不属于model_dict的键剔除掉 pret
-
pytorch模型保存与加载中的一些问题实战记录
目录 前言 一.torch中模型保存和加载的方式 1.模型参数和模型结构保存和加载 2.只保存模型的参数和加载——这种方式比较安全,但是比较稍微麻烦一点点 二.torch中模型保存和加载出现的问题 1.单卡模型下保存模型结构和参数后加载出现的问题 2.多卡机器单卡训练模型保存后在单卡机器上加载会报错 3.多卡训练模型保存模型结构和参数后加载出现的问题 三.正确的保存模型和加载的方法 总结 前言 最近使用pytorch训练模型,保存模型后再次加载使用出现了一些问题.记录一下解决方案! 一.torc
-
tensorflow模型保存、加载之变量重命名实例
话不多说,干就完了. 变量重命名的用处? 简单定义:简单来说就是将模型A中的参数parameter_A赋给模型B中的parameter_B 使用场景:当需要使用已经训练好的模型参数,尤其是使用别人训练好的模型参数时,往往别人模型中的参数命名方式与自己当前的命名方式不同,所以在加载模型参数时需要对参数进行重命名,使得代码更简洁易懂. 实现方法: 1).模型保存 import os import tensorflow as tf weights = tf.Variable(initial_value
-
python使用tensorflow保存、加载和使用模型的方法
使用Tensorflow进行深度学习训练的时候,需要对训练好的网络模型和各种参数进行保存,以便在此基础上继续训练或者使用.介绍这方面的博客有很多,我发现写的最好的是这一篇官方英文介绍: http://cv-tricks.com/tensorflow-tutorial/save-restore-tensorflow-models-quick-complete-tutorial/ 我对这篇文章进行了整理和汇总. 首先是模型的保存.直接上代码: #!/usr/bin/env python #-*- c
-
pytorch实现从本地加载 .pth 格式模型
可以从官网加载预训练好的模型: import torchvision.models as models model = models.vgg16(pretrained = True) print(model) 但是经常会出现因为下载速度太慢而出现requests.exceptions.ConnectionError: ('Connection aborted.', TimeoutError(10060, '由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败.', None, 1
-
Tensorflow之MNIST CNN实现并保存、加载模型
本文实例为大家分享了Tensorflow之MNIST CNN实现并保存.加载模型的具体代码,供大家参考,具体内容如下 废话不说,直接上代码 # TensorFlow and tf.keras import tensorflow as tf from tensorflow import keras # Helper libraries import numpy as np import matplotlib.pyplot as plt import os #download the data mn
-
Adnroid 自定义ProgressDialog加载中(加载圈)
前两天在做项目的时候发现有时候在访问网络数据的时候由于后台要做的工作较多,给我们返回数据的时间较长,所以老大叫我加了一个加载中的logo图用来提高用户体验. 于是就在网上找了许多大神写的案例,再结合自己的情况完成了一个Loading工具类 效果: ok,现在来说说怎么做的 先自定义一个类继承ProgressDialog public class Loading_view extends ProgressDialog { public Loading_view(Context context) {
-
android调用H5显示加载中效果的示例代码
我们在看有些应用在引入h5的时候经常会有一个进度条在转,显示加载的意思,那么这个东西其实一般是我们android端做的事(不要把所有的事都推给h5~~~),其实实现起来很简单, ok 废话不多说,上代码吧 wv.setWebViewClient(new WebViewClient() { @Override public void onPageStarted(WebView view, String url, Bitmap favicon) { super.onPageStarted(view,