C语言零基础彻底掌握预处理下篇
目录
- 1、条件编译
- 1.1 条件编译如何使用
- 1.2 用 #if 模拟 #ifdef
- 1.3 为何要有条件编译
- 2、文件包含
- 2.1 #include 究竟干了什么
- 2.2 防止头文件重复包含的条件编译是如何做到的
- 3、选学内容
- 3.1 #error 预处理
- 3.2 #line 预处理
- 3.3 #pragma 预处理
- 3.3.1 #pragma message
- 3.3.2 #pragma once
- 3.3.3 #pragma warning
- 3.3.4 #pragma pack
- 3.4 # 和 ##
1、条件编译
1.1 条件编译如何使用
C语言提供的条件编译的功能可以让我们按照不同的条件去编译不同的程序部分,从而产生不同目标代码文件。
第一种形式:
#ifdef 标识符
程序段1
#else
程序段2
#endif
它的功能是,如果标识符已经被 #define 定义了,则只会对程序段1进行编译,不会对程序段2进行编译,如果没有被定义则反之,如果我们不需要程序段2,也可以省去 #else 和他对应的程序段。

第二种形式:
#ifndef 标识符
程序段1
#else
程序段2
#endif
第二种形式与第一种形式的区别是将 ifdef 改为 ifndef,它的功能是,如果标识符没有被 #dfine 定义,则对程序段1进行编译,不会对程序段2进行编译,如果被定义了则反之,如果我们不需要程序段2,也可以省去 #else 和他对应的程序段。

第三种形式:
#if 常量表达式
程序段1
#else
程序段2
#endif
第三种形式的功能是:如果常量表达式的值为真(非0),则对程序段1进行编译,否则对程序段2进行编译,因此可以使程序在不同条件下,完成不同的功能。
至于里面还可以添加 #elif 命令,意义与 else if 相同,形成一个 if else 阶梯状语句,可进行多种编译选择。

注意:如果定义空宏则会报错,因为 #if 后面必须要更常量表达式!
1.2 用 #if 模拟 #ifdef

此代码的意思是,如果 PRINT 宏被定义了,则执行第一个打印函数,否则执行第二个打印函数,同时我们也可以模拟 #ifndef,只需前面加个逻辑非就可以 ' ! ',例如:#if (!defined(PRINT))
就这样完了吗?其实并没有,在更复杂的项目中,往往会出现两个或多个宏需要同时定义才能满足需求,我举一个很简单的例子,如果我定义了 C 宏和 CPP 宏,我才可以编译所对应的代码:

如上代码就需要两个宏都被定义才能编译下面的程序段,相信学习过逻辑与的小伙伴应该很容易理解吧,那么我们如果需要两个都未定义才能编译下面的程序段呢?如何写?
两个都未定义才编译: #if (!defined(C) && !defined(CPP))前面分别加逻辑非就可以 ' ! '
或者:#if (!(defined(C) || defined(CPP)))本代码中逻辑或只要有一个被定义,就为真,然后执行逻辑非,这样也能保证两个都未定义才进行编译!
至于最后用不用大括号给括起来,我的建议是括起来,这样我们阅读代码会更直观!
既然出现了逻辑与,是不是也可以出现逻辑或呢?当然上面已经有例子了,但是这里我就不一一演示了,感兴趣的可以下来自己去尝试一下。
条件编译支持嵌套:

这里其实和我们平常用的 if 嵌套式是似的,也很容易理解,这里我们就不细说,有一点要注意的就是,条件编译每个 #if 都需要有对应的 #endif 来结束
1.3 为何要有条件编译
我们先对我们上面2小节的内容做一个总结:条件编译本质上是让编译器对代码进行裁剪!
本质认识:条件编译,其实就是编译器根据实际情况,对代码进行裁剪,而这里 “实际情况” ,取决于代码平台,代码本身的业务逻辑。
- 可以只保留当前最需要的代码逻辑,其他去掉,可以减少生成代码的大小
- 可以写出跨平台的代码,让一个具体业务,在不同平台编译的时候,可以有同样的表现
条件编译都用在哪些地方呢?
张三有个公司,公司有个项目,项目对应的软件又有专业版,免费版,精简版等等...
难道每个版本都对应着不同的代码吗?不是的,这样维护起来太麻烦了,其实所谓不同的版本,本质就是功能上的有和无,所以在技术层面上,为了更好的维护,当然可以使用条件编译,需要哪个版本,就是用条件编译裁剪就行。
著名的 Linux 内核,功能上,其实也是用条件编译进行功能裁剪的,用来满足不同平台的软件。
2、文件包含
2.1 #include 究竟干了什么
我相信 #include 对于每个编程小伙伴来说都不陌生,很多人写 C 语言第一件事就是写上 #include <stdio.h> 可能老师会告诉你们这是包含标准输入输出头文件,至于如何包含的,可能不会跟你讲。那今天我们就来通过预处理来看一看到底是如何包含的:
我们来写上一小段代码:

前面说过,预处理会将头文件展开,去注释,宏替换,条件编译等等
在 Linux 环境下我们可以执行命令:gcc -E test.c -o test.i保留预处理之后的文件并命名为 test.i
为了更好的对比,我们执行 vim 命令模式下的 vs 指令:vs/sur/include/tdio.h 也就是打开标准输入输出的头文件:
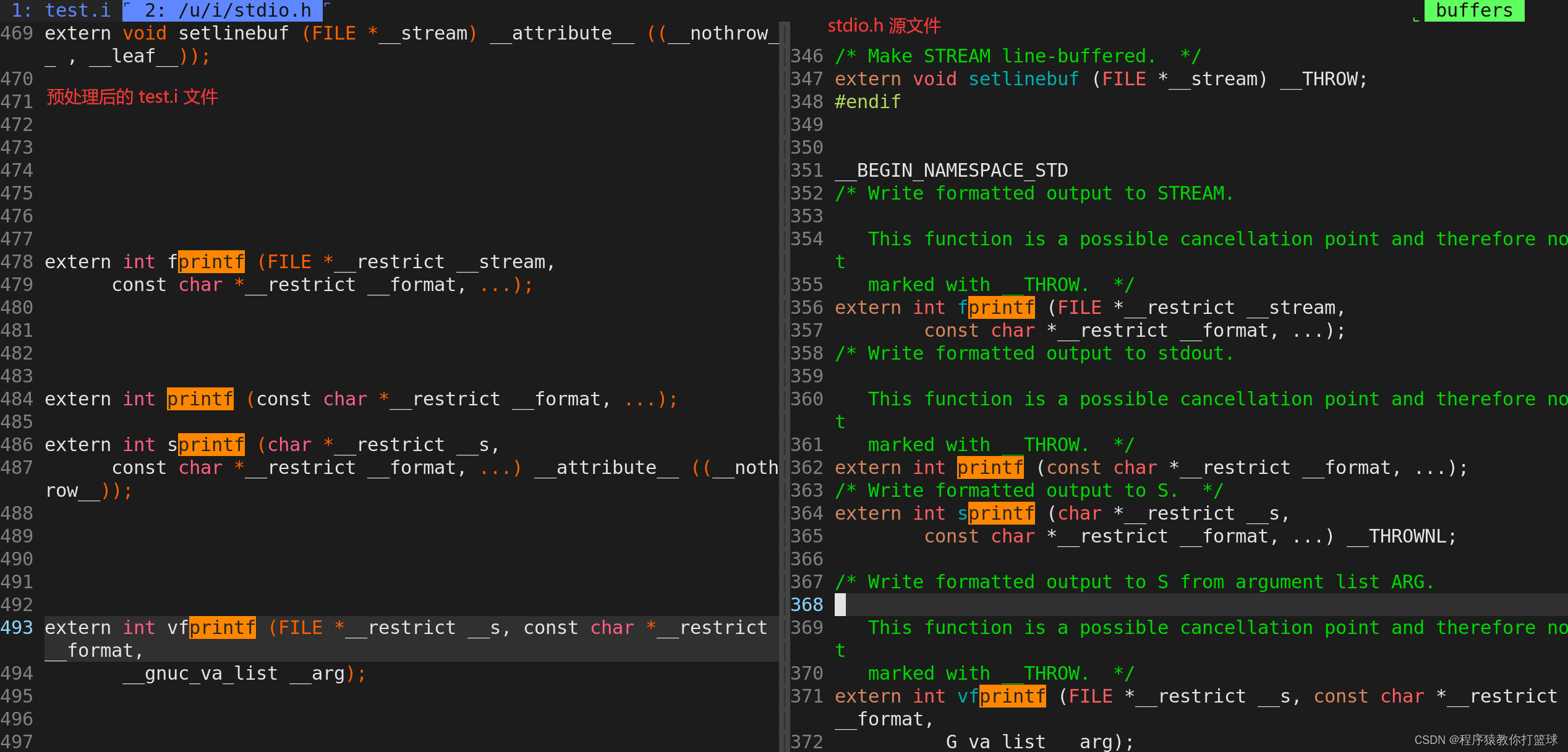
看到预处理的结果之后,发现文件大小比我们实际代码要大得多!
结论:#include 本质是把头文件相关内容,拷贝到源文件中。
2.2 防止头文件重复包含的条件编译是如何做到的
既然我们会包含头文件,那有没有可能存在头文件重复被包含的可能性呢?导致我们头文件被重复拷贝?
这里可能会有很多老师也教过,同学们啊,我们写头文件的时候一定要写如下代码啊,这是防止头文件重复包含的啊:
#ifndef _TEST_H_ #define _TEST_H_ #include <stdio.h> #define MAX 999 int g_val = 10; extern void Print(); ... #endif
如上代码很多小伙伴都知道在#ifndef _TEST_H_ 和 #endif 之间写的头文件包含,宏定义,全局变量,函数声明,都不会被重复拷贝,为什么呢?他是如何做到的?我们实验证明 (如下两张图最右边是预处理之后的结果) :
如下代码是没有带上条件编译防止头文件重复包含,但在源文件已经重复包含的例子:

我们加上#ifndef _TEST_H_ 和 #endif在来看重复包含的效果:

已经没有重复拷贝的情况了,看来确实有防止头文件重复包含的效果!
那么这条语句是如何做到的呢?
我们前面学过 #ifndef 如果没有定义这个宏,则执行后续语句,当第一次我们头文件展开的时候,确实没有定义_TEST_H_ 这个宏,所以会执行后续的语句,但是在第一次展开的时候我们立马定义了_TEST_H_ 宏,所以我们重复包含头文件第二次展开的时候,这个宏已经被定义了,所以也就不会去执行#ifndef后续语句了!
结论:所有头文件都得带上条件编译,防止头文件重复包含!当然也可以直接 #pragma once
重复包含的一定会报错吗?显然是不会的,但是会引起多次拷贝,会影响编译效率。
3、选学内容
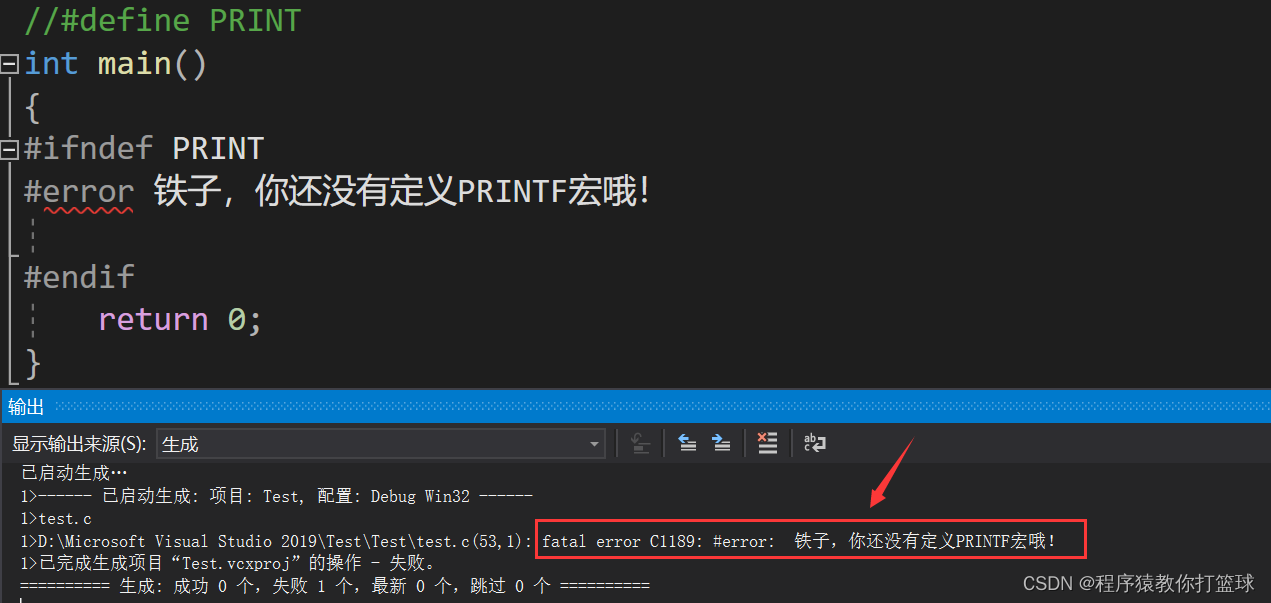
3.1 #error 预处理
#error 预处理指令的作用是:编译程序时,只要遇到 #error 就会生成一个编译错误提示消息,并停止编译:
3.2 #line 预处理
#line 的作用时改变当前行数和文件名称,他们是在编译程序中预先定义的标识符。这里我就不给你们看运行结果了,感兴趣的可以复制代码下去自行了解下哦:
int main()
{
printf("%s, %d\n", __FILE__, __LINE__); //C预定义符号,代表当前文件名和代码行号
#line 60 "hehe.h" //定制化完成
printf("%s, %d\n", __FILE__, __LINE__);
return 0;
}
本质其实是可以定制化你的文件名称和代码行号,很少使用!
3.3 #pragma 预处理
3.3.1 #pragma message
message 参数他能在编译信息输出窗口中输出相应的信息,这对于源代码信息的控制是非常重要的。
#define TEST
int main()
{
#ifdef TEST
#pragma message("TEST macor activated!")
#endif
return 0;
}
当我们定义了 TEST 这个宏后,应用程序在编译时就会在编译输出窗口里显示TEST macor activated! 因此我们就不会因为不记得自己定义的一些宏而着急了!
3.3.2 #pragma once
这个还是比较常用的,只要在头文件的最开始加入这条指令就能够保证头文件被编译一次,但是考虑到兼容性的问题,并没有太多的使用。
3.3.3 #pragma warning
#pragma warning(disable : 4507 34; once : 4385; error : 164) //等价于: #pragma warning(disable : 4507 34) //不显示 4507 和 34 号警告信息 #pragma warning(once : 4385) //4385 号警告信息仅报告一次 #pragma warning(error : 164) //把 164 号警告信息作为一个错误
当使用 windows vs 环境的小伙伴们,在使用库函数的时候比如 scanf 会说这个函数不安全,推荐你使用 scanf_s,那我们要保证代码可以移植性如何办呢?通过查看报错发现是 4996 报错,那我们则可以:
#pragma warning(disable : 4996) //这样就解决问题了!
3.3.4 #pragma pack
设置结构体内存对齐,我们还没更新到结构体,加上用的并不算多,所以感兴趣的可以先去自行研究哦。
3.4 # 和 ##
假设说我们今天定义了一个打印宏:
#define PRINT(x) printf("hello x is %d.\n", ((x)*(x)))
调用宏 PRINT(8); 则会输出:hello x is 64.
如果你希望字符串中包含宏参数,那我们就可以使用 "#",它可以把语言符号转换成字符串:
#define PRINT(x) printf("hello "#x" is %d.\n", ((x)*(x)))
这样调用PRINT(8); 则会输出:hello 8is 64.
## 使用起来也很简单,就是将两个相连的符号,连接成为一个符号:
#define XNAME(n) x##n
如果这样使用宏: XNAME(8)则会被展开成为:x8
在 "#" 或 "##" 预处理操作符相关的计算次序,如果未被指定则会产生问题,为了避免该问题,在单一的宏定义中只能使用其中一种操作符。除非是必须使用,否则尽量不适用这两个预处理操作符!
到此这篇关于C语言零基础彻底掌握预处理下篇的文章就介绍到这了,更多相关C语言预处理内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C语言深入探究程序的编译之预处理
目录 1.程序的翻译环境和执行环境 2.详解编译与链接 2.1翻译环境 2.2编译本身也分为几个阶段 2.3运行环境 3.预处理详解 3.1预处理符号 3.2#define 3.2.1#define定义标识符 3.2.2#define定义宏 3.2.3#define的替换规则 3.2.4 宏和函数对比 3.2.5命名约定 3.3#undef 3.4条件编译 1.程序的翻译环境和执行环境 在ANSI C中任何一种实现中,存在两个不同的环境. 第一种是翻译环境,在这个环境中源代码被转换为可执行的机器
-
一起来看看C语言的预处理注意点
目录 C 预处理器 1.取消已定义宏 2.使用#ifdef来调试 常用预定义宏 预处理器运算符 1.宏延续运算符 2.字符串常量化运算符# 3.标记粘贴运算符## 参数化的宏 总结 C 预处理器 C 预处理器不是编译器的组成部分,但是它是编译过程中一个单独的步骤.简言之,C 预处理器只不过是一个文本替换工具而已,它们会指示编译器在实际编译之前完成所需的预处理. 指令 描述 #define 定义宏 #include 包含一个源代码文件 #undef 取消已定义的宏 #ifdef 如果宏已经定义,则
-
C语言零基础彻底掌握预处理上篇
目录 1.#define的深度认识 1.1 数值宏常量 1.2 字符串宏常量 1.3 用宏充当注释符号 1.4 用宏替换多条语句 1.5 宏定义的使用建议 2.#undef 撤销宏 2.1 宏的定义位置和有效范围 2.2 宏的取消 2.3 一道笔试题 1.#define的深度认识 1.1 数值宏常量 宏定义数值常量相信大家都不陌生,相信很多小伙伴用过,这里我们就简单的提一下,我们前面也讲过,#define 本质上是替换,它可以出现在代码的任何地方,也可以把任何东西都定义成宏,编译器会在预编译的时
-
一起来学习C语言的程序环境与预处理
目录 1.程序的翻译环境和执行环境 2.gcc C语言编译器来演示编译过程 2.1编译 2.2编译: 2.3运行环境 3详解预处理 3.1预定义符号 3.2#define 3.2.1#define定义标识符 3.2.2 #define定义宏 3.2.3 #define替换规则 3.2.4 #和## 3.2.5带副作用的宏参数 3.2.6宏和函数对比 3.2.7 命名的约定 3.3 undef 3.4命令行定义 3.5 条件编译 常见的条件编译指令: 3.6文件包含 3.6.1头文件被包含的方式
-
C语言中的程序环境与预处理详情
目录 1.程序的翻译环境和执行环境 2.详解编译和链接 2.1程序翻译环境下的编译和链接 2.2深入编译和链接过程 2.3运行环境 3.预处理详解 3.1预定义符号 3.2#define 3.2.1#define定义的标识符 3.2.2#define定义宏 3.2.3#define替换规则 3.3.4#和## 3.2.5带副作用的宏参数 3.2.6宏和函数对比 3.3#undef 3.4命令行定义 3.5条件编译 3.6文件包含 3.6.1头文件被包含的方式 3.6.2嵌套文件包含 1.程序的翻
-
C语言超全面define预处理指令的使用说明
目录 前言 #define 定义宏(无参) #define 定义宏函数 宏的更多规则特性 宏的缺点 常见预处理指令 前言 C语言中源代码到可执行文件的第一阶段,也就是预处理阶段,会检查源文件中的预处理指令语句和宏定义,并对源代码进行相应的替换,预处理过程还会删除程序中的注释和多余的空白符号. 预处理指令是以#开头的代码行,#必须是该行除了空白符外的第一个字符,#后是指令关键字,在#和指令关键字之间允许存在若干个空白字符,define是宏定义命令.在C语言程序中允许用一个标识符来表示一个字符串,称
-
C语言程序的编译与预处理基础定义讲解
目录 程序的翻译环境和执行环境 1.翻译环境 2.运行环境 预处理详解 预定义符号 #define #define定义宏 #define替换规则 #和## 带副作用的宏参数 宏和函数对比 命名约定 #undef 命令行定义 条件编译 文件包含 程序的翻译环境和执行环境 在ANSIC的任何一种实现中,存在两个不同的环境:翻译环境和执行环境 翻译环境:源代码被转换为可执行的机器指令. 执行环境:实际执行代码. 1.翻译环境 组成一个程序的每个源文件通过编译分别转换成目标文件(object code)
-
C语言预编译#define(预处理)
目录 一.预定义符号 二.#define 定义标识符 三.#define 定义宏 四.#define 替换规则: 五.#和## 两个符号(少见) 六.宏和函数的对比 七.#undef 一.预定义符号 预定义符号是系统本身定义的: FILE 进行编译的源文件的位置 LINE 文件当前的行号 DATE 文件被编译的日期 TIME 文件被编译的时间 STDC 如果编译器遵循 ASNSI C,其值为1,否者未定义 二.#define 定义标识符 语法:#define name stuff (用stuff
-
C语言详细分析宏定义与预处理命令的应用
目录 宏定义与预处理命令 预处理命令 - 宏定义 定义符号常量 定义傻瓜表达式 定义代码段 预定义的宏 函数 VS 宏定义 预处理命令 - 条件式编译 示例 宏定义与预处理命令 预处理阶段:处理宏定义与预处理命令: 编译期:检查代码,分析语法.语义等,最后生成.o或.obj文件: 链接期:链接所有的.o或.obj文件,生成可执行文件. 预处理命令 - 宏定义 定义符号常量 #define PI 3.1415926 #define MAX_N 10000 定义傻瓜表达式 #define MAX(a
-
C语言零基础彻底掌握预处理下篇
目录 1.条件编译 1.1 条件编译如何使用 1.2 用 #if 模拟 #ifdef 1.3 为何要有条件编译 2.文件包含 2.1 #include 究竟干了什么 2.2 防止头文件重复包含的条件编译是如何做到的 3.选学内容 3.1 #error 预处理 3.2 #line 预处理 3.3 #pragma 预处理 3.3.1 #pragma message 3.3.2 #pragma once 3.3.3 #pragma warning 3.3.4 #pragma pack 3.4 # 和
-
C语言零基础讲解指针和数组
目录 一.指针和数组分析-上 1.数组的本质 2.指针的运算 3.指针的比较 4.小结 二.指针与数组分析-下 1.数组的访问方式 2.下标形式 VS 指针形式 3.a 和 &a 的区别 4.数组参数 5.小结 一.指针和数组分析-上 1.数组的本质 数组是一段连续的内存空间 数组的空间大小为 sizeof(array_type) * array_size 数组名可看做指向数组第一个元素的常量指针 下面看一段代码: #include <stdio.h> int main() { int
-
C语言零基础入门(1)
目录 1.C语言简介 1.1C语言发展史 1.2C语言的特点 1.3算法及其表示 1.4常用算法介绍 总结 1. C语言简介 1.1 C语言发展史 C语言是一种广泛使用的面向过程的计算机程序设计语言,既适合于系统程序设计,又适合于应用程序设计.C语言的发展历程大致如图1-1所示: 图1-1 C语言的发展历程 1.2 C语言的特点 C语言是一种通用的程序设计语言,语言本身简洁.灵活.表达能力强,被广泛用于系统软件和应用软件的开发,并且具有良好的可移植性. C语言的特点可概括如下: (1)简洁.紧凑
-
C语言零基础入门(2)
目录 1.数组 1.1一维数组 1.1.1一维数组的定义 1.1.2一维数组的初始化 1.1.3一维数组的引用 1.2二维数组及多维数组 1.2.1二维数组的定义 1.2.2二维数组的初始化 1.2.3二维数组的引用 总结 1. 数组 数组是一组相同类型变量的有序集合,用于存放一组相同类型的数据.这一组变量用数组名和从0开始的下标标识,使用内存中一块连续的存储空间.依据数组中元素下标的个数分为一维数组.二维数组和多维数组. 1.1 一维数组 1.1.1 一维数组的定义 一维数组定义的一般形式为:
-
零基础易语言入门教程(六)之逻辑型命令
逻辑型命令,就是非真即假的. 具体方法和步骤如下所示: 1.如果(): 属于逻辑型,不是真就是假,这种时间我们基本在编写程序时,会有两个选择方向,见下图所示: 2.如上图,如果命令属于逻辑型数据,且有两条输出方向,当我们在如果命令里填写的为真,那么我们的系统将会显示输出真的一个,反之则为假. 3.如果()命令在我们编写程序时属于常用命令,他在运行时我们需要给他一个条件,然后才能输出内容,有了条件我们在运行时给他一个输出方向即可, 以上所述是小编给大家介绍的零基础易语言入门教程(六)之逻辑型命令的
-
零基础易语言入门教程(五)之逻辑型数据类型
在上篇文章给大家介绍了零基础易语言入门教程(四)之数据类型,上篇针对数值到文本类型知识,今天给大家介绍下逻辑型数据. 具体方法和步骤如下所示: 1.逻辑型数据非真即假: 首先申请一个局部变量(A)类型为:逻辑型,编写代码为:A=1>2,那么输出的结果应为假,因等于1是赋值与1,然后代码中写道1大于2,所以这是假的,见下图所示: 2.关系运算符: 在上图大家需注意的是,A后面的等于号是赋值符号,而后面的≥,≠,<一些符号则是关系运算符. 关系运算符不是非要设置变量给其赋值才可以使用的,同样他可以
-
零基础易语言入门教程(四)之数据类型
我们一起了解下易语言的数据类型,跟我们现实生活是一样的,分为文本型和数值型,即是我们所说的文科生和理科生的区别. 参考文章:详解易语言中的数据类型 方法和步骤如下所示: 1.数值型(到数值命令): 使用该命令可将文本型等一类数据更改为数值型:我们来输入一行代码看看其作用: 2.到文本()命令: 我们先输入一行代码试试,见下图 3.小结: 每一行代码前后的数据类型必须转换为同一种,方可进行相连,相加,"+"在数据为文本型时是连接作用,数值型的跟数学里的符号一样. 以上所述是小编给大家介绍
-
零基础易语言入门教程(三)之了解控制台程序
易语言简介: 易语言是一门以中文作为程序代码编程语言.以"易"著称.创始人为吴涛.早期版本的名字为E语言.易语言最早的版本的发布可追溯至2000年9月11日.创造易语言的初衷是进行用中文来编写程序的实践.从2000年至今,易语言已经发展到一定的规模,功能上.用户数量上都十分可观. 易语言和其它编程语言一样都有后台程序,它也不一定必须是窗口程序的了,下面小编带大家了解易语言的控制台程序. 方法和步骤如下所示: 1.延时命令: 首先学习一个第一个命令,该命令可将其脚本界面延时.1000毫秒
-
零基础易语言入门教程(二)之编程思路
易语言简介: 易语言是一门以中文作为程序代码编程语言.以"易"著称.创始人为吴涛.早期版本的名字为E语言.易语言最早的版本的发布可追溯至2000年9月11日.创造易语言的初衷是进行用中文来编写程序的实践.从2000年至今,易语言已经发展到一定的规模,功能上.用户数量上都十分可观. 上一篇跟大家讲了零基础易语言入门教程(一)编写第一个程序,然后接下来大家应该自己把支持库和易语言组件里面的控件全部认真的看一下,下面我直接跟大家分享下易语言简单编程思路. 方法和步骤如下所示: 1.易语言程序