Swin Transformer图像处理深度学习模型
目录
- Swin Transformer
- 整体架构
- Swin Transformer 模块
- 滑动窗口机制
- Cyclic Shift
- Efficient batch computation for shifted configuration
- Relative position bias
- 代码实现:
Swin Transformer
Swin Transformer是一种用于图像处理的深度学习模型,它可以用于各种计算机视觉任务,如图像分类、目标检测和语义分割等。它的主要特点是采用了分层的窗口机制,可以处理比较大的图像,同时也减少了模型参数的数量,提高了计算效率。Swin Transformer在图像处理领域取得了很好的表现,成为了最先进的模型之一。
Swin Transformer通过从小尺寸的图像块(用灰色轮廓线框出)开始,并逐渐合并相邻块,构建了一个分层的表示形式,在更深层的Transformer中实现。
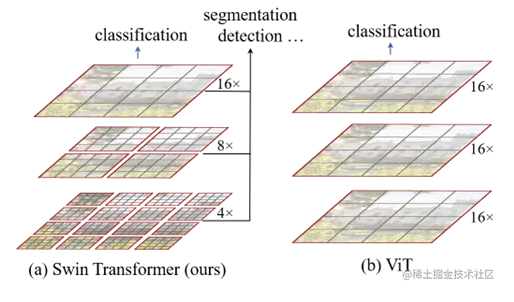
整体架构


Swin Transformer 模块
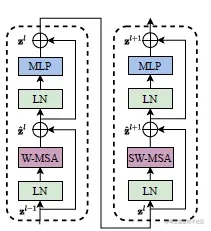
Swin Transformer模块是基于Transformer块中标准的多头自注意力模块(MSA)进行替换构建的,用的是一种基于滑动窗口的模块(在后面细说),而其他层保持不变。如上图所示,Swin Transformer模块由基于滑动窗口的多头注意力模块组成,后跟一个2层MLP,在中间使用GELU非线性激活函数。在每个MSA模块和每个MLP之前都应用了LayerNorm(LN)层,并在每个模块之后应用了残差连接。
滑动窗口机制


Cyclic Shift
Cyclic Shift是Swin Transformer中一种有效的处理局部特征的方法。在Swin Transformer中,为了处理高分辨率的输入特征图,需要将输入特征图分割成小块(一个patch可能有多个像素)进行处理。然而,这样会导致局部特征在不同块之间被分割开来,影响了局部特征的提取。Cyclic Shift将输入特征图沿着宽度和高度方向分别平移一个固定的距离,使得每个块的局部特征可以与相邻块的局部特征进行交互,从而增强了局部特征的表达能力。另外,Cyclic Shift还可以通过多次平移来增加块之间的交互,进一步提升了模型的性能。需要注意的是,Cyclic Shift只在训练过程中使用,因为它会改变输入特征图的分布。在测试过程中,输入特征图的大小和分布与训练时相同,因此不需要使用Cyclic Shift操作。
Efficient batch computation for shifted configuration
Cyclic Shift会将输入特征图沿着宽度和高度方向进行平移操作,以便让不同块之间的局部特征进行交互。这样的操作会导致每个块的特征值的位置发生改变,从而需要在每个块上重新计算注意力机制。
为了加速计算过程,Swin Transformer中引入了"Efficient batch computation for shifted configuration"这一技巧。该技巧首先将每个块的特征值复制多次,分别放置在Cyclic Shift平移后的不同位置上,使得每个块都可以在平移后的不同的位置上参与到注意力机制的计算中。然后,将这些位置不同的块的特征值进行合并拼接,计算注意力。
需要注意的是,这种技巧只在训练时使用,因为它会增加计算量,而在测试时,可以将每个块的特征值计算一次,然后在不同位置上进行拼接,以得到最终的输出。
Relative position bias
在传统的Transformer模型中,为了考虑单词之间的位置关系,通常采用绝对位置编码(Absolute Positional Encoding)的方式。这种方法是在每个单词的embedding中添加位置编码向量,以表示该单词在序列中的绝对位置。但是,当序列长度很长时,绝对位置编码会面临两个问题:
- 编码向量的大小会随着序列长度的增加而增加,导致模型参数量增大,训练难度加大;
- 当序列长度超过一定限制时,模型的性能会下降。
为了解决这些问题,Swin Transformer采用了Relative Positional Encoding,它通过编码单词之间的相对位置信息来代替绝对位置编码。相对位置编码是由每个单词对其它单词的相对位置关系计算得出的。在计算相对位置时,Swin Transformer引入了Relative Position Bias,即相对位置偏置,它是一个可学习的参数矩阵,用于调整不同位置之间的相对位置关系。这样做可以有效地减少相对位置编码的参数量,同时提高模型的性能和效率。相对位置编码可以通过以下公式计算:

最终,相对位置编码和相对位置偏置的结果会被加到点积注意力机制中,用于计算不同位置之间的相关性,从而实现序列的建模。
代码实现:
下面是一个用PyTorch实现Swin B模型的示例代码,其中包含了相对位置编码和相对位置偏置的实现:
import torch
import torch.nn as nn
from einops.layers.torch import Rearrange
class SwinBlock(nn.Module):
def __init__(self, in_channels, out_channels, window_size=7, shift_size=0):
super(SwinBlock, self).__init__()
self.window_size = window_size
self.shift_size = shift_size
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
self.norm1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=window_size, stride=1, padding=window_size//2, groups=out_channels)
self.norm2 = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(out_channels, out_channels, kernel_size=1, stride=1, padding=0)
self.norm3 = nn.BatchNorm2d(out_channels)
if in_channels == out_channels:
self.downsample = None
else:
self.downsample = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
self.norm_downsample = nn.BatchNorm2d(out_channels)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.norm1(out)
out = nn.functional.relu(out)
out = Rearrange(out, 'b c h w -> b (h w) c')
out = self.shift_window(out)
out = Rearrange(out, 'b (h w) c -> b c h w', h=int(x.shape[2]), w=int(x.shape[3]))
out = self.conv2(out)
out = self.norm2(out)
out = nn.functional.relu(out)
out = self.conv3(out)
out = self.norm3(out)
if self.downsample is not None:
residual = self.downsample(x)
residual = self.norm_downsample(residual)
out += residual
out = nn.functional.relu(out)
return out
def shift_window(self, x):
# x: (B, L, C)
B, L, C = x.shape
if self.shift_size == 0:
shifted_x = torch.zeros_like(x)
shifted_x[:, self.window_size//2:L-self.window_size//2, :] = x[:, self.window_size//2:L-self.window_size//2, :]
return shifted_x
else:
# pad feature maps to shift window
left_pad = self.window_size // 2 + self.shift_size
right_pad = left_pad - self.shift_size
x = nn.functional.pad(x, (0, 0, left_pad, right_pad), mode='constant', value=0)
# Reshape X to (B, H, W, C)
H = W = int(x.shape[1] ** 0.5)
x = Rearrange(x, 'b (h w) c -> b c h w', h=H, w=W)
# Shift window
x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(2, 3))
# Reshape back to (B, L, C)
x = Rearrange(x, 'b c h w -> b (h w) c')
return x[:, self.window]
class SwinTransformer(nn.Module):
def __init__(self, in_channels=3, num_classes=1000, num_layers=12, embed_dim=96, window_sizes=(7, 3, 3, 3), shift_sizes=(0, 1, 2, 3)):
super(SwinTransformer, self).__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.num_layers = num_layers
self.embed_dim = embed_dim
self.window_sizes = window_sizes
self.shift_sizes = shift_sizes
self.conv1 = nn.Conv2d(in_channels, embed_dim, kernel_size=4, stride=4, padding=0)
self.norm1 = nn.BatchNorm2d(embed_dim)
self.blocks = nn.ModuleList()
for i in range(num_layers):
self.blocks.append(SwinBlock(embed_dim * 2**i, embed_dim * 2**(i+1), window_size=window_sizes[i%4], shift_size=shift_sizes[i%4]))
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(embed_dim * 2**num_layers, num_classes)
# add relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * (2 * window_sizes[-1] - 1), embed_dim // 8, embed_dim // 8)),
requires_grad=True)
nn.init.kaiming_uniform_(self.relative_position_bias_table, a=1)
# add relative position encoding
self.pos_embed = nn.Parameter(
torch.zeros(1, embed_dim * 2**num_layers, 7, 7),
requires_grad=True)
nn.init.kaiming_uniform_(self.pos_embed, a=1)
def forward(self, x):
out = self.conv1(x)
out = self.norm1(out)
out = nn.functional.relu(out)
for block in self.blocks:
out = block(out)
out = self.avgpool(out)
out = Rearrange(out, 'b c h w -> b (c h w)')
out = self.fc(out)
return out
def get_relative_position_bias(self, H, W):
# H, W: height and width of feature maps in the last block
# output: (2HW-1, 8, 8)
relative_position_bias_h = self.relative_position_bias_table[:,
:(2 * H - 1), :(2 * W - 1)].transpose(0, 1)
relative_position_bias_w = self.relative_position_bias_table[:,
(2 * H - 1):, (2 * W - 1):].transpose(0, 1)
relative_position_bias = torch.cat([relative_position_bias_h, relative_position_bias_w], dim=0)
return relative_position_bias
def get_relative_position_encoding(self, H, W):
# H, W: height and width of feature maps in the last block
# output: (1, HW, C)
pos_x, pos_y = torch.meshgrid(torch.arange(H), torch.arange(W))
pos_x, pos_y = pos_x.float(), pos_y.float()
pos_x = pos_x / (H-1) * 2 - 1
pos_y = pos_y / (W-1) * 2 - 1
pos_encoding = torch.stack((pos_y, pos_x), dim=-1)
pos_encoding = pos_encoding.reshape(1, -1, 2)
pos_encoding = pos_encoding.repeat(1, 1, embed_dim // 2)
pos_encoding = pos_encoding.transpose(1, 2)
return pos_encoding
以上就是Swin Transformer图像处理深度学习模型的详细内容,更多关于Swin Transformer深度学习的资料请关注我们其它相关文章!
相关推荐
-
Transformer导论之Bert预训练语言解析
目录 Bert Pre-training BERT Fine-tuning BERT 代码实现 Bert BERT,全称为“Bidirectional Encoder Representations from Transformers”,是一种预训练语言表示的方法,意味着我们在一个大型文本语料库(如维基百科)上训练一个通用的“语言理解”模型,然后将该模型用于我们关心的下游NLP任务(如问答).BERT的表现优于之前的传统NLP方法,因为它是第一个用于预训练NLP的无监督的.深度双向系统. Ber
-
Swin Transformer模块集成到YOLOv5目标检测算法中实现
目录 一.YOLOv5简介 二.Swin Transformer简介 三.添加Swin Transformer模块到YOLOv5 四.训练和测试YOLOv5+Swin Transformer 五.实验结果 一.YOLOv5简介 YOLOv5是一种目标检测算法,由ultralytics公司开发.它采用单一神经网络同时完成对象识别和边界框回归,并使用anchor box技术提高定位精度和召回率.此外,它具有较快的速度,可在GPU上实现实时目标检测.YOLOv5发布以来,其已被广泛应用于工业领域和学术
-
详解基于Transformer实现电影评论星级分类任务
目录 Transformer模型概述 数据集准备 模型训练 模型调整和优化 总结 Transformer模型概述 Transformer是一种用于序列到序列学习的神经网络架构,专门用于处理输入和输出序列之间的依赖关系.该模型被广泛应用于机器翻译.音频转录.语言生成等多个自然语言处理领域. Transformer基于attention机制来实现序列到序列的学习. 在RNN(循环神经网络)中,网络必须按顺序遍历每个单词,并在每个时间步计算隐层表示. 这样,在长段文本中,信息可能会从网络的起点传递到终
-
Swin Transformer图像处理深度学习模型
目录 Swin Transformer 整体架构 Swin Transformer 模块 滑动窗口机制 Cyclic Shift Efficient batch computation for shifted configuration Relative position bias 代码实现: Swin Transformer Swin Transformer是一种用于图像处理的深度学习模型,它可以用于各种计算机视觉任务,如图像分类.目标检测和语义分割等.它的主要特点是采用了分层的窗口机制,可以
-

PyTorch深度学习模型的保存和加载流程详解
一.模型参数的保存和加载 torch.save(module.state_dict(), path):使用module.state_dict()函数获取各层已经训练好的参数和缓冲区,然后将参数和缓冲区保存到path所指定的文件存放路径(常用文件格式为.pt..pth或.pkl). torch.nn.Module.load_state_dict(state_dict):从state_dict中加载参数和缓冲区到Module及其子类中 . torch.nn.Module.state_dict()函数
-
Python人工智能深度学习模型训练经验总结
目录 一.假如训练集表现不好 1.尝试新的激活函数 2.自适应学习率 ①Adagrad ②RMSProp ③ Momentum ④Adam 二.在测试集上效果不好 1.提前停止 2.正则化 3.Dropout 一.假如训练集表现不好 1.尝试新的激活函数 ReLU:Rectified Linear Unit 图像如下图所示:当z<0时,a = 0, 当z>0时,a = z,也就是说这个激活函数是对输入进行线性转换.使用这个激活函数,由于有0的存在,计算之后会删除掉一些神经元,使得神经网络变窄.
-
Pytorch模型定义与深度学习自查手册
目录 定义神经网络 权重初始化 方法1:net.apply(weights_init) 方法2:在网络初始化的时候进行参数初始化 常用的操作 利用nn.Parameter()设计新的层 nn.Flatten nn.Sequential 常用的层 全连接层nn.Linear() torch.nn.Dropout 卷积torch.nn.ConvNd() 池化 最大池化torch.nn.MaxPoolNd() 均值池化torch.nn.AvgPoolNd() 反池化 最大值反池化nn.MaxUnpoo
-
Python深度学习之Keras模型转换成ONNX模型流程详解
目录 从Keras转换成PB模型 从PB模型转换成ONNX模型 改变现有的ONNX模型精度 部署ONNX 模型 总结 从Keras转换成PB模型 请注意,如果直接使用Keras2ONNX进行模型转换大概率会出现报错,这里笔者曾经进行过不同的尝试,最后都失败了. 所以笔者的推荐的情况是:首先将Keras模型转换为TensorFlow PB模型. 那么通过tf.keras.models.load_model()这个函数将模型进行加载,前提是你有一个基于h5格式或者hdf5格式的模型文件,最后再通过改
-
python人工智能深度学习算法优化
目录 1.SGD 2.SGDM 3.Adam 4.Adagrad 5.RMSProp 6.NAG 1.SGD 随机梯度下降 随机梯度下降和其他的梯度下降主要区别,在于SGD每次只使用一个数据样本,去计算损失函数,求梯度,更新参数.这种方法的计算速度快,但是下降的速度慢,可能会在最低处两边震荡,停留在局部最优. 2.SGDM SGM with Momentum:动量梯度下降 动量梯度下降,在进行参数更新之前,会对之前的梯度信息,进行指数加权平均,然后使用加权平均之后的梯度,来代替原梯度,进行参数的
-
Python-OpenCV深度学习入门示例详解
目录 0. 前言 1. 计算机视觉中的深度学习简介 1.1 深度学习的特点 1.2 深度学习大爆发 2. 用于图像分类的深度学习简介 3. 用于目标检测的深度学习简介 4. 深度学习框架 keras 介绍与使用 4.1 keras 库简介与安装 4.2 使用 keras 实现线性回归模型 4.3 使用 keras 进行手写数字识别 小结 0. 前言 深度学习已经成为机器学习中最受欢迎和发展最快的领域.自 2012 年深度学习性能超越机器学习等传统方法以来,深度学习架构开始快速应用于包括计算机视觉
-
python深度学习之多标签分类器及pytorch实现源码
目录 多标签分类器 多标签分类器损失函数 代码实现 多标签分类器 多标签分类任务与多分类任务有所不同,多分类任务是将一个实例分到某个类别中,多标签分类任务是将某个实例分到多个类别中.多标签分类任务有有两大特点: 类标数量不确定,有些样本可能只有一个类标,有些样本的类标可能高达几十甚至上百个 类标之间相互依赖,例如包含蓝天类标的样本很大概率上包含白云 如下图所示,即为一个多标签分类学习的一个例子,一张图片里有多个类别,房子,树,云等,深度学习模型需要将其一一分类识别出来. 多标签分类器损失函数 代
-
Python人工智能深度学习RNN模型结构流程
目录 1.RNN基础模型 2.LSTM 3.流程结构 1.RNN基础模型 RNN主要特点是,在DNN隐藏层的输出内容会被存储,并且可以作为输入给到下一个神经元. 如下图所示,当"台北"这个词被输入的时候,前面的词有可能是"离开",有可能是"到达",如果把上一次输入的"离开",所得的隐藏层内容,输入给下一层,这样就有可能区分开是"离开台北",还是"到达台北". 如果隐藏层存储的内容并给下次
-
Python深度学习之Unet 语义分割模型(Keras)
目录 前言 一.什么是语义分割 二.Unet 1.基本原理 2.mini_unet 3. Mobilenet_unet 4.数据加载部分 参考 前言 最近由于在寻找方向上迷失自我,准备了解更多的计算机视觉任务重的模型.看到语义分割任务重Unet一个有意思的模型,我准备来复现一下它. 一.什么是语义分割 语义分割任务,如下图所示: 简而言之,语义分割任务就是将图片中的不同类别,用不同的颜色标记出来,每一个类别使用一种颜色.常用于医学图像,卫星图像任务. 那如何做到将像素点上色呢? 其实语义分割的输