python利用不到一百行代码实现一个小siri
前言
如果想要容易理解核心的特征计算的话建议先去看看我之前的听歌识曲的文章,传送门:http://www.jb51.net/article/97305.htm
本文主要是实现了一个简单的命令词识别程序,算法核心一是提取音频特征,二是用DTW算法进行匹配。当然,这样的代码肯定不能用于商业化,大家做出来玩玩娱乐一下还是不错的。
设计思路
就算是个小东西,我们也要先明确思路再做。音频识别,困难不小,其中提取特征的难度在我听歌识曲那篇文章里能看得出来。而语音识别难度更大,因为音乐总是固定的,而人类说话常常是变化的。比如说一个“芝麻开门”,有的人就会说成“芝麻开门”,有的人会说成“芝麻开门”。而且在录音时说话的时间也不一样,可能很紧迫的一开始录音就说话了,也可能不紧不慢的快要录音结束了才把这四个字说出来。这样难度就大了。
算法流程:
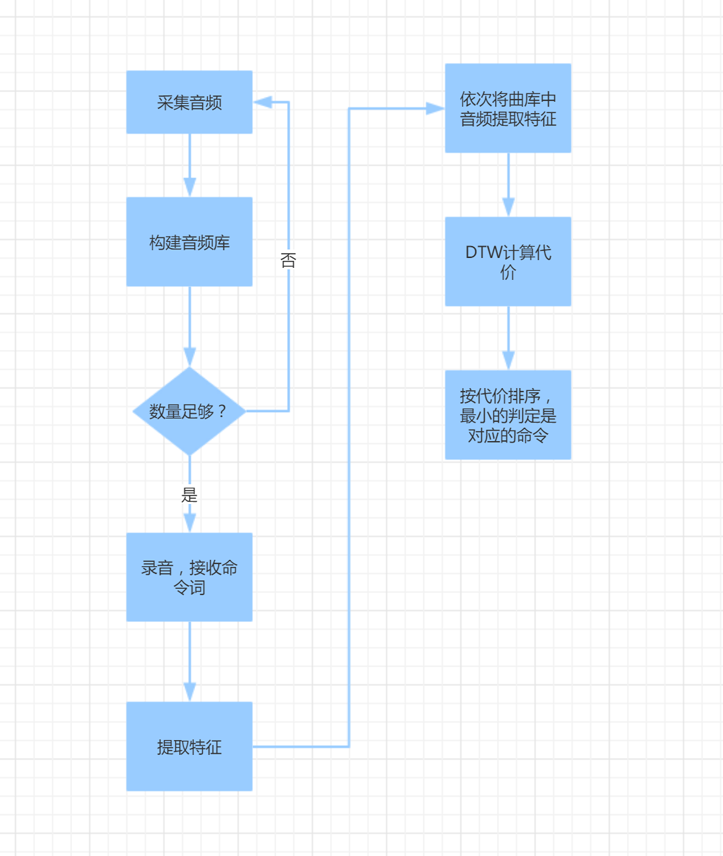
特征提取
和之前的听歌识曲一样,同样是将一秒钟分成40块,对每一块进行傅里叶变换,然后取模长。只是这不像之前听歌识曲中进一步进行提取峰值,而是直接当做特征值。
看不懂我在说什么的朋友可以看看下面的源代码,或者看听歌识曲那篇文章。
DTW算法
DTW,Dynamic Time Warping,动态时间归整。算法解决的问题是将不同发音长短和位置进行最适合的匹配。
算法输入两组音频的特征向量: A:[fp1,fp2,fp3,......,fpM1] B:[fp1,fp2,fp3,fp4,.....fpM2]
A组共有M1个特征,B组共有M2个音频。每个特征向量中的元素就是之前我们将每秒切成40块之后FFT求模长的向量。计算每对fp之间的代价采用的是欧氏距离。
设D(fpa,fpb)为两个特征的距离代价。
那么我们可以画出下面这样的图

我们需要从(1,1)点走到(M1,M2)点,这会有很多种走法,而每种走法就是一种两个音频位置匹配的方式。但我们的目标是走的总过程中代价最小,这样可以保证这种对齐方式是使我们得到最接近的对齐方式。
我们这样走:首先两个坐标轴上的各个点都是可以直接计算累加代价和求出的。然后对于中间的点来说D(i,j) = Min{D(i-1,j)+D(fpi,fpj) , D(i,j-1)+D(fpi,fpj) , D(i-1,j-1) + 2 * D(fpi,fpj)}
为什么由(i-1,j-1)直接走到(i,j)这个点需要加上两倍的代价呢?因为别人走正方形的两个直角边,它走的是正方形的对角线啊
按照这个原理选择,一直算到D(M1,M2),这就是两个音频的距离。



源代码和注释
# coding=utf8
import os
import wave
import dtw
import numpy as np
import pyaudio
def compute_distance_vec(vec1, vec2):
return np.linalg.norm(vec1 - vec2) #计算两个特征之间的欧氏距离
class record():
def record(self, CHUNK=44100, FORMAT=pyaudio.paInt16, CHANNELS=2, RATE=44100, RECORD_SECONDS=200,
WAVE_OUTPUT_FILENAME="record.wav"):
#录歌方法
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(''.join(frames))
wf.close()
class voice():
def loaddata(self, filepath):
try:
f = wave.open(filepath, 'rb')
params = f.getparams()
self.nchannels, self.sampwidth, self.framerate, self.nframes = params[:4]
str_data = f.readframes(self.nframes)
self.wave_data = np.fromstring(str_data, dtype=np.short)
self.wave_data.shape = -1, self.sampwidth
self.wave_data = self.wave_data.T #存储歌曲原始数组
f.close()
self.name = os.path.basename(filepath) # 记录下文件名
return True
except:
raise IOError, 'File Error'
def fft(self, frames=40):
self.fft_blocks = [] #将音频每秒分成40块,再对每块做傅里叶变换
blocks_size = self.framerate / frames
for i in xrange(0, len(self.wave_data[0]) - blocks_size, blocks_size):
self.fft_blocks.append(np.abs(np.fft.fft(self.wave_data[0][i:i + blocks_size])))
@staticmethod
def play(filepath):
chunk = 1024
wf = wave.open(filepath, 'rb')
p = pyaudio.PyAudio()
# 播放音乐方法
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True)
while True:
data = wf.readframes(chunk)
if data == "": break
stream.write(data)
stream.close()
p.terminate()
if __name__ == '__main__':
r = record()
r.record(RECORD_SECONDS=3, WAVE_OUTPUT_FILENAME='record.wav')
v = voice()
v.loaddata('record.wav')
v.fft()
file_list = os.listdir(os.getcwd())
res = []
for i in file_list:
if i.split('.')[1] == 'wav' and i.split('.')[0] != 'record':
temp = voice()
temp.loaddata(i)
temp.fft()
res.append((dtw.dtw(v.fft_blocks, temp.fft_blocks, compute_distance_vec)[0],i))
res.sort()
print res
if res[0][1].find('open_qq') != -1:
os.system('C:\program\Tencent\QQ\Bin\QQScLauncher.exe') #我的QQ路径
elif res[0][1].find('zhimakaimen') != -1:
os.system('chrome.exe')#浏览器的路径,之前已经被添加到了Path中了
elif res[0][1].find('play_music') != -1:
voice.play('C:\data\music\\audio\\audio\\ (9).wav') #播放一段音乐
# r = record()
# r.record(RECORD_SECONDS=3,WAVE_OUTPUT_FILENAME='zhimakaimen_09.wav')
事先可以先用这里的record方法录制几段命令词,尝试用不同语气说,不同节奏说,这样可以提高准确度。然后设计好文件名,根据匹配到的最接近音频的文件名就可以知道是哪种命令,进而自定义执行不同的任务
这是一段演示视频:http://www.iqiyi.com/w_19ruisynsd.html
总结
以上就是这篇文章的全部内容,希望本文的内容对大家的学习或者使用python能带来一定的帮助,如果有疑问大家可以留言交流。
相关推荐
-

听歌识曲--用python实现一个音乐检索器的功能
听歌识曲,顾名思义,用设备"听"歌曲,然后它要告诉你这是首什么歌.而且十之八九它还得把这首歌给你播放出来.这样的功能在QQ音乐等应用上早就出现了.我们今天来自己动手做一个自己的听歌识曲 我们设计的总体流程图很简单: ----- 录音部分 ----- 我们要想"听",就必须先有录音的过程.在我们的实验中,我们的曲库也要用我们的录音代码来进行录音,然后提取特征存进数据库.我们用下面这样的思路来录音 # coding=utf8 import wave import pya
-
python3音乐播放器简单实现代码
本文实例为大家分享了python3音乐播放器的关键代码,供大家参考,具体内容如下 from tkinter import * from traceback import * from win32com.client import Dispatch import time,eyed3,threading name = [] def openfile(index = [1]): global total,name filenames = filedialog.askopenfilenames(tit
-
Python通过90行代码搭建一个音乐搜索工具
下面小编把具体实现代码给大家分享如下: 之前一段时间读到了这篇博客,其中描述了作者如何用java实现国外著名音乐搜索工具shazam的基本功能.其中所提到的文章又将我引向了关于shazam的一篇论文及另外一篇博客.读完之后发现其中的原理并不十分复杂,但是方法对噪音的健壮性却非常好,出于好奇决定自己用python自己实现了一个简单的音乐搜索工具-- Song Finder, 它的核心功能被封装在SFEngine 中,第三方依赖方面只使用到了 scipy. 工具demo 这个demo在ipython
-
Python实现提取谷歌音乐搜索结果的方法
本文实例讲述了Python实现提取谷歌音乐搜索结果的方法.分享给大家供大家参考.具体如下: Python的简单脚本,用于提取谷歌音乐搜索页面中的歌曲信息,包括歌曲名,作者,专辑名,现在链接等,最多只提取10页结果. #! /usr/bin/env python #coding=utf-8 ''' Created on 2011-8-19 @author: yaoboyuan ''' from urllib import request,parse import re,sys def extrac
-
python利用不到一百行代码实现一个小siri
前言 如果想要容易理解核心的特征计算的话建议先去看看我之前的听歌识曲的文章,传送门:http://www.jb51.net/article/97305.htm 本文主要是实现了一个简单的命令词识别程序,算法核心一是提取音频特征,二是用DTW算法进行匹配.当然,这样的代码肯定不能用于商业化,大家做出来玩玩娱乐一下还是不错的. 设计思路 就算是个小东西,我们也要先明确思路再做.音频识别,困难不小,其中提取特征的难度在我听歌识曲那篇文章里能看得出来.而语音识别难度更大,因为音乐总是固定的,而人类说话常
-
Python+tkinter使用80行代码实现一个计算器实例
本文主要探索的是使用Python+tkinter编程实现一个简单的计算器代码示例,具体如下. 闲话不说,直奔主题.建议大家跟着敲一遍代码,体会一下代码复用.字符串方法的运用和动态创建组件的妙处,然后在这个框架的基础上进行补充和发挥. 选择任何一款Python开发环境,创建一个程序文件,命名为tkinter_Calculator.pyw,然后编写下面的代码: 1)导入标准库re和tkinter,创建并简单设置应用主程序,在窗口顶部放置一个只读的文本框用来显示信息. 2)编写计算器上各种按钮的通用处
-
Python利用turtle库绘制彩虹代码示例
语言:Python IDE:Python.IDE 需求 做出彩虹效果 颜色空间 RGB模型:光的三原色,共同决定色相 HSB/HSV模型:H色彩,S深浅,B饱和度,H决定色相 需要将HSB模型转换为RGB模型 代码示例: #-*- coding:utf-8 –*- from turtle import * def HSB2RGB(hues): hues = hues * 3.59 #100转成359范围 rgb=[0.0,0.0,0.0] i = int(hues/60)%6 f = hues/
-
python 利用jinja2模板生成html代码实例
这篇文章主要介绍了python 利用jinja2模板生成html代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 from jinja2 import Environment, FileSystemLoader import json def generate_html(data): env = Environment(loader=FileSystemLoader('./')) # 加载模板 template = env.get_tem
-
Python使用5行代码批量做小姐姐的素描图
目录 1. 流程分析 2. 具体实现 3. 百度图片爬虫+生成素描图 我给大家带来的是 50行代码,生成一张素描图.让自己也是一个素描"大师".那废话不多说,我们直接先来看看效果吧. 上图的右边就是我们的效果,那具体有哪些步骤呢? 1. 流程分析 对于上面的流程来说是非常简单的,接下来我们来看看具体的实现. 2. 具体实现 安装所需要的库: pip install opencv-python 导入所需要的库: import cv2 编写主体代码也是非常的简单的,代码如下: import
-
80行代码写一个Webpack插件并发布到npm
1. 前言 最近在学习 Webpack 相关的原理,以前只知道 Webpack 的配置方法,但并不知道其内部流程,经过一轮的学习,感觉获益良多,为了巩固学习的内容,我决定尝试自己动手写一个插件. 这个插件实现的功能比较简单: 默认清除 js 代码中的 console.log 的打印输出: 可通过传入配置,实现移除 console 的其它方法,如 console.warn.console.error 等: 2. Webpack 的构建流程以及 plugin 的原理 2.1 Webpack 构建流程
-
100行代码实现一个vue分页组功能
今天用vue来实现一个分页组件,总体来说,vue实现比较简单,样式部分模仿了elementUI.所有代码的源码可以再github上下载的到:下载地址 先来看一下实现效果: 点击查看效果 整体思路 我们先看一下使用到的文件的目录: 我们在 pageComponentsTest.vue 页面引入了 pageComponent.vue 分页组件.整体思路是通过 props 来达到组件的灵活通用的效果,整体语法是使用vue的VM语法. pageComponent.vue实现 首先实现一个分页,需要知道数
-
iOS使用核心的50行代码撸一个路由组件
使用组件化是为了解耦处理,多个模块之间通过协议进行交互.而负责解析协议,找到目的控制器,或者是返回对象给调用者的这个组件就是路由组件.本文讲解如何使用核心的50行代码实现一个路由组件. 组件化和路由 路由的实现 路由注册实现 路由使用实现 客户端的使用 一些小想法 组件化和路由 之前看过挺多的关于路由管理.路由处理的文章,常常会和组件化出现在一起,一开始不知道为何路由和组件化出现在一起,后来公司的项目中使用了路由组件(他本身也是一个组件,确切的说是一个中间人或者中介者),才突然想明白了,原来如此
-
python 实现在一张图中绘制一个小的子图方法
有时候为了直观展现图的信息,可以在大图中添加小子图的方式进行数据分析,如下图所示: 具体的代码如下:该图连接了数据库,当然重要的不是数据展示,而是添加子图的方法. import matplotlib.pyplot as plt import MySQLdb as mdb import numpy as np from mpl_toolkits.axes_grid1.inset_locator import inset_axes from mpl_toolkits.axes_grid1.inset