网站渗透常用Python小脚本查询同ip网站
旁站查询来源:
http://dns.aizhan.com
http://s.tool.chinaz.com/same
http://i.links.cn/sameip/
http://www.ip2hosts.com/
效果图如下:
以百度网站和小残博客为例:
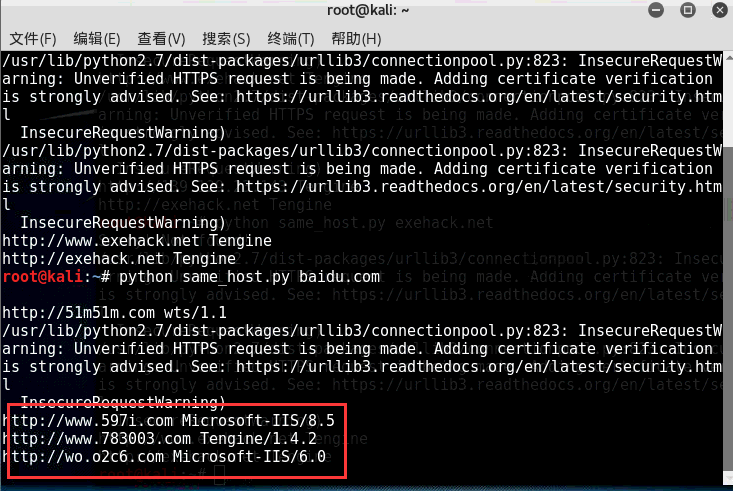

PS:直接调用以上4个旁注接口查询同服服务器域名信息包含服务器类型 比如小残博客使用的是Tengine
#!/usr/bin/env python
#encoding: utf-8
import re
import sys
import json
import time
import requests
import urllib
import requests.packages.urllib3
from multiprocessing import Pool
from BeautifulSoup import BeautifulSoup
requests.packages.urllib3.disable_warnings()
headers = {'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20'}
def links_ip(host):
'''
查询同IP网站
'''
ip2hosts = []
ip2hosts.append("http://"+host)
try:
source = requests.get('http://i.links.cn/sameip/' + host + '.html', headers=headers,verify=False)
soup = BeautifulSoup(source.text)
divs = soup.findAll(style="word-break:break-all")
if divs == []: #抓取结果为空
print 'Sorry! Not found!'
return ip2hosts
for div in divs:
#print div.a.string
ip2hosts.append(div.a.string)
except Exception, e:
print str(e)
return ip2hosts
return ip2hosts
def ip2host_get(host):
ip2hosts = []
ip2hosts.append("http://"+host)
try:
req=requests.get('http://www.ip2hosts.com/search.php?ip='+str(host), headers=headers,verify=False)
src=req.content
if src.find('result') != -1:
result = json.loads(src)['result']
ip = json.loads(src)['ip']
if len(result)>0:
for item in result:
if len(item)>0:
#log(scan_type,host,port,str(item))
ip2hosts.append(item)
except Exception, e:
print str(e)
return ip2hosts
return ip2hosts
def filter(host):
'''
打不开的网站...
'''
try:
response = requests.get(host, headers=headers ,verify=False)
server = response.headers['Server']
title = re.findall(r'<title>(.*?)</title>',response.content)[0]
except Exception,e:
#print "%s" % str(e)
#print host
pass
else:
print host,server
def aizhan(host):
ip2hosts = []
ip2hosts.append("http://"+host)
regexp = r'''<a href="[^']+?([^']+?)/" rel="external nofollow" target="_blank">\1</a>'''
regexp_next = r'''<a href="http://dns.aizhan.com/[^/]+?/%d/" rel="external nofollow" >%d</a>'''
url = 'http://dns.aizhan.com/%s/%d/'
page = 1
while True:
if page > 2:
time.sleep(1) #防止拒绝访问
req = requests.get(url % (host , page) ,headers=headers ,verify=False)
try:
html = req.content.decode('utf-8') #取得页面
if req.status_code == 400:
break
except Exception as e:
print str(e)
pass
for site in re.findall(regexp , html):
ip2hosts.append("http://"+site)
if re.search(regexp_next % (page+1 , page+1) , html) is None:
return ip2hosts
break
page += 1
return ip2hosts
def chinaz(host):
ip2hosts = []
ip2hosts.append("http://"+host)
regexp = r'''<a href='[^']+?([^']+?)' target=_blank>\1</a>'''
regexp_next = r'''<a href="javascript:" rel="external nofollow" val="%d" class="item[^"]*?">%d</a>'''
url = 'http://s.tool.chinaz.com/same?s=%s&page=%d'
page = 1
while True:
if page > 1:
time.sleep(1) #防止拒绝访问
req = requests.get(url % (host , page) , headers=headers ,verify=False)
html = req.content.decode('utf-8') #取得页面
for site in re.findall(regexp , html):
ip2hosts.append("http://"+site)
if re.search(regexp_next % (page+1 , page+1) , html) is None:
return ip2hosts
break
page += 1
return ip2hosts
def same_ip(host):
mydomains = []
mydomains.extend(ip2host_get(host))
mydomains.extend(links_ip(host))
mydomains.extend(aizhan(host))
mydomains.extend(chinaz(host))
mydomains = list(set(mydomains))
p = Pool()
for host in mydomains:
p.apply_async(filter, args=(host,))
p.close()
p.join()
if __name__=="__main__":
if len(sys.argv) == 2:
same_ip(sys.argv[1])
else:
print ("usage: %s host" % sys.argv[0])
sys.exit(-1)
大家可以发挥添加或者修改任意查询接口。注意是这个里面的一些思路与代码。
相关推荐
-

网站渗透常用Python小脚本查询同ip网站
旁站查询来源: http://dns.aizhan.com http://s.tool.chinaz.com/same http://i.links.cn/sameip/ http://www.ip2hosts.com/ 效果图如下: 以百度网站和小残博客为例: PS:直接调用以上4个旁注接口查询同服服务器域名信息包含服务器类型 比如小残博客使用的是Tengine #!/usr/bin/env python #encoding: utf-8 import re import sys import
-
python常用小脚本实例总结
目录 前言 打印16进制字符串 文件合并 多线程下载图集 多线程下载图片 爬虫抓取信息 爬虫多线程下载电影名称 串口转tcp工具 远程读卡器server端 黑客rtcp反向链接 调用c的动态库示例 tcp的socket连接报文测试工具 报文拼接与加解密测试 二进制文件解析工具 抓取动漫图片 抓取网站模板 总结 前言 日常生活中常会遇到一些小任务,如果人工处理会很麻烦. 用python做些小脚本处理,能够提高不少效率.或者可以把python当工具使用,辅助提高一下办公效率.(比如我常拿python
-
Python版Mssql爆破小脚本
Mssql Python版本爆破小脚本,需要安装 MSSQL-python.exe 可以看出代码量很少,用法:保存代码为MssqlDatabaseBlasting.py,cmd切换到 MssqlDatabaseBlasting.py路径下,并 执行 MssqlDatabaseBlasting.py即可开始破解 import pymssql common_weak_password = ('','123456','test','root','admin','user')#密码字典 mssql_us
-
python小程序基于Jupyter实现天气查询的方法
天气查询python小程序第0步:导入工具库第一步:生成查询天气的url链接第二步:访问url链接,解析服务器返回的json数据,变成python的字典数据第三步:对字典进行索引,获取气温.风速.风向等天气信息第四步:遍历forecast列表中的五个元素,打印天气信息完整Python代码 本案例是一个非常有趣的python小程序,调用网络API查询指定城市的天气,并打印输出天气信息. 你将学到以下技能: 向网络API发起请求,解析和处理服务器返回的json数据,可以迁移到各种各样的API中,如P
-
Python猜解网站数据库管理员密码的脚本
目录 一.功能分析 二.思路分析 三.步骤实现 1)判断注入点 2)猜解长度 3)猜解数据 4)猜解脚本 一.功能分析 简单分析一下网站的功能,大致如下: 需要用户在地址栏中提交参数,根据参数中的id查询对应的用户信息. 如果id存在,则显示查询成功,比如 输入?id=1 如果id不存在,则页面空显示,比如输入 ?id=0(用户id不能是0或负数,id为0时,查询结果为空,会导致页面空显示) 如果数据库报错,页面也是空显示,比如输入?id=1’ 或 ?id=1"(参数中携带引号会导致数据库报错,
-
python用于url解码和中文解析的小脚本(python url decoder)
复制代码 代码如下: # -*- coding: utf8 -*- #! python print(repr("测试报警,xxxx是大猪头".decode("UTF8").encode("GBK")).replace("\\x","%")) 注意第一个 decode("UTF8") 要与文件声明的编码一样. 最开始对这个问题的接触,来自于一个Javascript解谜闯关的小游戏,某一关的
-
Python版Mysql爆破小脚本
Mysql Python版本爆破小脚本,需要安装Python插件MySQL-python.exe,可以看出代码量很少,(注意:里用户名和密码都是类似字典.用法:保存代码为MysqlDatabaseBlasting.py,cmd切换到 MysqlDatabaseBlasting.py路径下,并 执行 MysqlDatabaseBlasting.py即可开始破解 ) import MySQLdb #coding=gbk #目标IP mysql数据库必须开启3360远程登陆端口 mysql_usern
-
利用Python实现自动扫雷小脚本
自动扫雷一般分为两种,一种是读取内存数据,而另一种是通过分析图片获得数据,并通过模拟鼠标操作,这里我用的是第二种方式. 一.准备工作 1.扫雷游戏 我是win10,没有默认的扫雷,所以去扫雷网下载 http://www.saolei.net/BBS/ 2.python 3 我的版本是 python 3.6.1 3.python的第三方库 win32api,win32gui,win32con,Pillow,numpy,opencv 可通过 pip install --upgrade SomePac
-
python 实现网易邮箱邮件阅读和删除的辅助小脚本
简介: 在Windows下的网易邮箱大师客户端中,阅读邮件时,可以使用快捷键Delete删除邮件,然后自动跳到下一封,如果再按一次Delete键,再跳到下一封.为了迅速的阅读邮件,同时删除没有必要的邮件,特地写了如下脚本,自用同时放出来共享. 问题: 1. 如上图,我积累太多未读邮件,原因是每天邮件太多,根本看不完,数量马上到上限了: 2. 我想看到每封邮件: 3. 邮件有时内容太过鸡肋,属于知晓型即可,看完即可删除: 4. 大多数看完就要删除,一个个删除太麻烦: 一句话,需要自动删除我看完之后
-
Python写脚本常用模块OS基础用法详解
收集了一些关于OS库的用法,整理归纳一下,方便使用 import os # 系统操作 print(os.sep) # 获取当前系统的路径分隔符 print(os.name) # 获取当前使用的工作平台 print(os.getenv('PATH')) # 获取名为 PATH 的环境变量 print(os.getcwd()) # 获取当前的路径 print(os.environ['PATH']) # 可以返回环境相关的信息 不传参时,以字典的方式返回所有环境变量 # 调用系统命令 os.syste