asp.net安全、实用、简单的大容量存储过程分页第1/2页
基本上我下面要讲述的侧重点是如何使用,因为其实分页存储过程网上很多,如果你懒得找,那么可以直接使用下面这个我经过测试,并通过修改,网上评价都比较高的分页存储过程。
这个分页主要优点如下:
1、大容量下的数据分页,我的测试数据是520W。
2、我结合aspnetpager控件,使得使用起来更加方便。
3、为了结构清晰,实用3层。
4、安全,你就放心的用吧。SQL注入的问题在这里你可以放心了。网上有文章说只要存储过程是用sql拼接的就存在sql注入的问题,并且直接在sql查询分析器中测试了注入的情况。其实是不对的,采用存储过程和参数化的提交语句并没有sql注入的问题。因为它进数据库的时候会有替换的过程。
准备工作:
1、直接使用一个DB库,数据访问层基类,用它返回一个dataset对象,使用的时候我们只需要类似下面的语句就可以返回一个dataset对象。
sosuo8.DBUtility.DbHelperSQL.RunProcedure("pagination",parameter,"userinfo");
pagination是我在网上找的存储过程,我进行了修改的,主要是添加输出总记录数。这里总记录数也特意说一下,一般我们都是使用类似下面的语句:
代码如下:
sosuo8.DBUtility.DbHelperSQL.RunProcedure("pagination",parameter,"userinfo");
pagination是我在网上找的存储过程,我进行了修改的,主要是添加输出总记录数。这里总记录数也特意说一下,一般我们都是使用类似下面的语句:
代码如下:
select count(*) from sosuo8data
这里我又要说两句,网上有网友说使用count(某列),例如count(userName)会比count(*)快也是不对,如果找的列不对,那么并不会比count(*)快。而count(*)会自动帮我们查找可以实现最快统计的那列,而其实在使用中,一般就是我们的那个主键id,count(id)是最快的。
2、建立数据库data_test,建立两个表:
(1)、userinfo这个表用来放数据。
代码如下:
CREATE TABLE [dbo].[userinfo](
[id] [int] IDENTITY(1,1) NOT NULL,
[userName] [nchar](50) COLLATE Chinese_PRC_CI_AS NULL,
[userWebName] [nchar](50) COLLATE Chinese_PRC_CI_AS NULL,
[createDate] [datetime] NULL CONSTRAINT [DF_userinfo_createDate] DEFAULT (getdate()),
CONSTRAINT [PK_userinfo] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
id是自递增,且是聚合索引。OK?开始往数据库中添加520W条记录:
代码如下:
set identity_insert userinfo on -- 标识可以插入自递增列
declare @count int
declare @date datetime
set @count=1
set @date = '2009-4-5 00:00:00'
while @count<=5200000
begin
insert into userinfo(id,userName,userWebName,createDate) values(@count,'阿会楠','sosuo8.com',@date)
set @count=@count+1
set @date=@date+'00:00:01'--加一秒,避免重复,否则会造成分页不准确的情况,排序的字段切忌不要出现过多重复值
end
set identity_insert userinfo off
如果你的电脑配置比较一般,千万不要尝试,否则可能会当机;如果没当机,那耐心等下,插入这么多条记录需要一点时间。
(2)tmp表用来存放无搜索条件时的总记录数。这里我要说下,为什么需要一个表用来专门存放总记录数,总记录数你可以在后台每隔一段时间就去更新一次,把最新的总记录数写进去。否则的话,520W的记录你每次都要用count(id)那么耗费的时间也不少。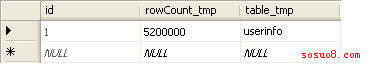
建表的语句如下:
代码如下:
CREATE TABLE [dbo].[tmp](
[id] [int] IDENTITY(1,1) NOT NULL,
[rowCount_tmp] [int] NULL,
[table_tmp] [varchar](255) COLLATE Chinese_PRC_CI_AS NULL,
CONSTRAINT [PK_tmp] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
这里不得不提一下,为什么只要取得表的行总记录数,而不在存储过程里面把分页都算好。因为我们就将采用aspnetpager这个控件,这个控件我们只需要传入3个值,函数定义如下:
代码如下:
public DataSet GetList(int PageIndex, string strWhere,ref int rowCount)
PageIndex:当前页,对应aspnetpager中的CurrentPageIndex
strWhere:搜索的条件,这篇文章将不重点讲搜索部分。所以代码中用string.Empty,大容量下的数据搜索那需要另写一篇文章来说明。
rowCount:总记录数,由存储过程重新返回。
当前1/2页 12下一页阅读全文
相关推荐
-
asp.net 结合mysql存储过程进行分页代码
不过在网上找了一些,发现都有一个特点--就是不能传出总记录数,干脆自己研究吧.终于,算是搞出来了,效率可能不是很好,但是我也觉得不错了.贴代码吧直接:也算是对自己学习mysql的一个记录. 复制代码 代码如下: CREATE PROCEDURE p_pageList ( m_pageNo int , m_perPageCnt int , m_column varchar(1000) , m_table varchar(1000) , m_condition varchar(1000), m_or
-

ASP.NET Core Project.json文件(5)
如果您的应用程序要做任何有用的工作,然后你需要库和框架来完成工作,这种存储和检索数据从一个数据库或呈现复杂的HTML. 在这一章,我们将讨论 project.json 文件.此文件使用 JavaScript 对象符号来存储配置信息,它是.NET 应用程序的核心.如果没有这个文件,你的项目就不会一个 ASP.NET Core项目.在这里,我们将讨论这个文件的一些最重要的特征.让我们双击 project.json 文件打开它. 目前,新建的项目中默认实现的project.json文件代码如下: {
-
在ASP.NET中用存储过程执行SQL语句
存储过程执行效率比单独的SQL语句效率高. 样编写存储过程?存储过程在SQL Server 2005对应数据库的可编程性目录下. 比如,创建一个存储过程 复制代码 代码如下: create procedure procNewsSelectNewNews as begin select top 10 n.id,n.title,n.createTime,c.name from news n inner join category c on n.caId=c.id order by n.createT
-
asp.net 存储过程调用
1.调用存储过程,但无返回值 复制代码 代码如下: Private Function SqlProc1(ByVal ProcName As String) As Boolean '定义数据链接部分省略, myConn为链接对象 ProcName为存储过程名 Dim myCommand As New SqlClient.SqlCommand(ProcName, myConn) With myCommand .CommandType = CommandType.StoredProcedure .Pa
-
asp.net sql存储过程
Visual Studio.Net为SQL的存储过程提供了强大的支持,您既可以通过visual studio.net来新建存储过程,也可以直接在Sql Server的查询分析器中运行,还可以通过企业管理器创建,使用起来也非常方便.大家一直都误认为SQL存储过程是一个比较"高深"的技术,其实掌握一般的语法是没有什么大问题的,而我们在使用存储教程中也主要是增删减的操作,学会使用一般的T-SQL就很容易上手了. 我们先来看一下在Sql-server中是如何创建一个存储过程的吧,我们可以使用S
-
.Net下二进制形式的文件(图片)的存储与读取详细解析
.Net下图片的常见存储与读取凡是有以下几种:存储图片:以二进制的形式存储图片时,要把数据库中的字段设置为Image数据类型(SQL Server),存储的数据是Byte[]. 1.参数是图片路径:返回Byte[]类型: 复制代码 代码如下: public byte[] GetPictureData(string imagepath) { ////根据图片文件的路径使用文件流打开,并保存为byte[] FileStream fs =
-
.net调用存储过程详细介绍
连接字符串 复制代码 代码如下: string conn = ConfigurationManager.ConnectionStrings["NorthwindConnectionString"].ConnectionString; confige文件 复制代码 代码如下: <connectionStrings> <add name="NorthwindConnectionString" connectionString="
-
asp.net安全、实用、简单的大容量存储过程分页第1/2页
基本上我下面要讲述的侧重点是如何使用,因为其实分页存储过程网上很多,如果你懒得找,那么可以直接使用下面这个我经过测试,并通过修改,网上评价都比较高的分页存储过程. 这个分页主要优点如下: 1.大容量下的数据分页,我的测试数据是520W. 2.我结合aspnetpager控件,使得使用起来更加方便. 3.为了结构清晰,实用3层. 4.安全,你就放心的用吧.SQL注入的问题在这里你可以放心了.网上有文章说只要存储过程是用sql拼接的就存在sql注入的问题,并且直接在sql查询分析器中测试了注入的情况
-
asp.net 安全、实用、简单的大容量存储过程分页第1/2页
基本上我下面要讲述的侧重点是如何使用,因为其实分页存储过程网上很多,如果你懒得找,那么可以直接使用下面这个我经过测试,并通过修改,网上评价都比较高的分页存储过程. 这个分页主要优点如下: 1.大容量下的数据分页,我的测试数据是520W. 2.我结合aspnetpager控件,使得使用起来更加方便. 3.为了结构清晰,实用3层. 4.安全,你就放心的用吧.SQL注入的问题在这里你可以放心了.网上有文章说只要存储过程是用sql拼接的就存在sql注入的问题,并且直接在sql查询分析器中测试了注入的情况
-
asp.net结合aspnetpager使用SQL2005的存储过程分页
SQL2005的存储过程: 复制代码 代码如下: set ANSI_NULLS ON set QUOTED_IDENTIFIER ON go ALTER PROCEDURE [dbo].[P_GetPagedReCord] (@startIndex INT, -- 开始索引号 @endindex INT, -- 结束索引号 @tblName varchar(255), -- 表名 @fldName varchar(255), -- 显示字段名 @OrderfldName varchar(255)
-
ASP之简化创建关闭记录集对象并创建使用简单的MSSQL存储过程
ASP 技巧一则之 简化创建关闭记录集对象并创建使用简单的MSSQL存储过程 By shawl.qiu 1. 建造 创建关闭记录集函数 2. 在MSSQL查询分析器中创建简单的MSSQL存储过程 3. 在ASP中应用步骤1,2 shawl.qiu 2006-8-26 http://blog.csdn.net/btbtd 1. 建造 创建关闭记录集函数 linenum function createRs(rs) set rs=createObject("adodb.recordset
-
ASP.NET的实用技巧详细介绍
关于ASP.NET的实用技巧,其实我们已经接触到很多了.下面为大家总结一下,供大家参考. 1.跟踪页面执行 设置断点是页面调试过程中的常用手段,除此之外,还可以通过查看页面的跟踪信息进行错误排查以及性能优化.ASP.NET中启用页面跟踪非常方便,只需在Page指令中加入Trace="True"属性即可: <%@ Page Language="C#" Trace="true"> 跟踪信息可以分为两类: a.页面执行详细情况 其中主要包括
-
一些Asp技巧和实用解决方法
一些Asp技巧和实用解决方法 随机数: <%randomize%> <%=(int(rnd()*n)+1)%> 查询数据时得到的记录关键字用红色显示: <% =replace(RS("字段X"),searchname,"<font color=#FF0000>" & searchname & "</font>") %> 通过asp的手段来检查来访者是否用了代理 <%
-
通用SQL存储过程分页以及asp.net后台调用的方法
创建表格并添加300万数据 use Stored CREATE TABLE UserInfo( --创建表 id int IDENTITY(1,1) PRIMARY KEY not null,--添加主键和标识列 UserName varchar(50) ) declare @i int --添加3百万数据,大概4分钟时间 set @i=1 while @i<3000000 begin insert into UserInfo (UserName) values(@i) set @i=@i+1
-
利用JQuery直接调用asp.net后台的简单方法
利用JQuery的$.ajax()可以很方便的调用asp.net的后台方法. [WebMethod] 命名空间 1.无参数的方法调用, 注意:1.方法一定要静态方法,而且要有[WebMethod]的声明 后台<C#>: using System.Web.Script.Services; [WebMethod] public static string SayHello() { return "Hello Ajax!"; } 前台<jQuery>: $(fun
-
asp.net利用后台实现直接生成html分页的方法
本文实例讲述了asp.net利用后台实现直接生成html分页的方法,是一个比较实用的功能.分享给大家供大家参考之用.具体方法如下: 1.建立存储过程: ALTER procedure [dbo].[p_news_query] @Page int as begin select top 5 new_id,new_title,new_url,new_content_text,create_time,user_name from (select *,ROW_NUMBER() over(order by
-
asp.net Repeater之非常好的数据分页
分页控件源代码如下: 复制代码 代码如下: using System; using System.Collections.Generic; using System.ComponentModel; using System.Text; using System.Web; using System.Web.UI; using System.Web.UI.WebControls; using System.Collections; #region Assembly Resource Attribut