谈谈Python进行验证码识别的一些想法
用python加“验证码”为关键词在baidu里搜一下,可以找到很多关于验证码识别的文章。我大体看了一下,主要方法有几类:一类是通过对图片进行处理,然后利用字库特征匹配的方法,一类是图片处理后建立字符对应字典,还有一类是直接利用ocr模块进行识别。不管是用什么方法,都需要首先对图片进行处理,于是试着对下面的验证码进行分析。
一、图片处理
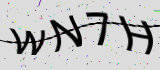
这个验证码中主要的影响因素是中间的曲线,首先考虑去掉图片中的曲线。考虑了两种算法:
第一种是首先取到曲线头的位置,即x=0时,黑点的位置。然后向后移动x的取值,观察每个x下黑点的位置,判断前后两个相邻黑点之间的距离,如果距离在一定范围内,可以基本判断该点是曲线上的点,最后将曲线上的点全部绘成白色。试了一下这种方法,结果得到的图片效果很一般,曲线不能完全去除,而且容量将字符的线条去除。
第二种考虑用单位面积内点的密度来进行计算。于是首先计算单位面积内点的个数,将单位面积内点个数少于某一指定数的面积去除,剩余的部分基本上就是验证码字符的部分。本例中,为了便于操作,取了5*5做为单位范围,并调整单位面积内点的标准密度为11。处理后的效果:
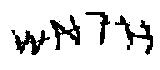
二、字符验证
这里我使用的方法是利用pytesser进行ocr识别,但由于这类验证码字符的不规则性,使得验证结果的准确性并不是很高。具体哪位大牛,有什么好的办法,希望能给指点一下。
三、准备工作与代码实例
1、PIL、pytesser、tesseract
(1)安装PIL:下载地址:http://www.pythonware.com/products/pil/
(2)pytesser:下载地址:http://code.google.com/p/pytesser/,下载解压后直接放在代码相同的文件夹下,即可使用。
(3)Tesseract OCR engine下载:http://code.google.com/p/tesseract-ocr/,下载后解压,找到tessdata文件夹,用其替换掉pytesser解压后的tessdata文件夹即可。
2、具体代码
#encoding=utf-8
###利用点的密度计算
import Image,ImageEnhance,ImageFilter,ImageDraw
import sys
from pytesser import *
#计算范围内点的个数
def numpoint(im):
w,h = im.size
data = list( im.getdata() )
mumpoint=0
for x in range(w):
for y in range(h):
if data[ y*w + x ] !=255:#255是白色
mumpoint+=1
return mumpoint
#计算5*5范围内点的密度
def pointmidu(im):
w,h = im.size
p=[]
for y in range(0,h,5):
for x in range(0,w,5):
box = (x,y, x+5,y+5)
im1=im.crop(box)
a=numpoint(im1)
if a<11:##如果5*5范围内小于11个点,那么将该部分全部换为白色。
for i in range(x,x+5):
for j in range(y,y+5):
im.putpixel((i,j), 255)
im.save(r'img.jpg')
def ocrend():##识别
image_name = "img.jpg"
im = Image.open(image_name)
im = im.filter(ImageFilter.MedianFilter())
enhancer = ImageEnhance.Contrast(im)
im = enhancer.enhance(2)
im = im.convert('1')
im.save("1.tif")
print image_file_to_string('1.tif')
if __name__=='__main__':
image_name = "1.png"
im = Image.open(image_name)
im = im.filter(ImageFilter.DETAIL)
im = im.filter(ImageFilter.MedianFilter())
enhancer = ImageEnhance.Contrast(im)
im = enhancer.enhance(2)
im = im.convert('1')
##a=remove_point(im)
pointmidu(im)
ocrend()
本人的这个方法,最终识别率确实不高,写出来,哪位高手有好的思路或者做法,望不惜赐教!
相关推荐
-
详解Python验证码识别
以前写过一个刷校内网的人气的工具,Java的(以后再也不行Java程序了),里面用到了验证码识别,那段代码不是我自己写的:-) 校内的验证是完全单色没有任何干挠的验证码,识别起来比较容易,不过从那段代码中可以看到基本的验证码识别方式.这几天在写一个程序的时候需要识别验证码,因为程序是Python写的自然打算用Python进行验证码的识别. 以前没用Python处理过图像,不太了解PIL(Python Image Library)的用法,这几天看了看PIL,发现它太强大了,简直和ImageMagi
-

python验证码识别的示例代码
写爬虫有一个绕不过去的问题就是验证码,现在验证码分类大概有4种: 图像类 滑动类 点击类 语音类 今天先来看看图像类,这类验证码大多是数字.字母的组合,国内也有使用汉字的.在这个基础上增加噪点.干扰线.变形.重叠.不同字体颜色等方法来增加识别难度. 相应的,验证码识别大体可以分为下面几个步骤: 灰度处理 增加对比度(可选) 二值化 降噪 倾斜校正分割字符 建立训练库 识别 由于是实验性质的,文中用到的验证码均为程序生成而不是批量下载真实的网站验证码,这样做的好处就是可以有大量的知道明确结果的数据
-
python验证码识别的实例详解
其实关于验证码识别涉及很多方面的内容,入手难度大,但是入手后,可拓展性又非常广泛,可玩性极强,成就感也很足,对这感兴趣的朋友们下面跟着小编一起来学习学习吧. 依赖 sudo apt-get install python-imaging sudo apt-get install tesseract-ocr pip install pytesseract 利用google ocr来识别验证码 from PIL import Image import pytesseract image = Image
-
Python验证码识别处理实例
一.准备工作与代码实例 (1)安装PIL:下载后是一个exe,直接双击安装,它会自动安装到C:\Python27\Lib\site-packages中去, (2)pytesser:下载解压后直接放C:\Python27\Lib\site-packages(根据你安装的Python路径而不同),同时,新建一个pytheeer.pth,内容就写pytesser,注意这里的内容一定要和pytesser这个文件夹同名,意思就是pytesser文件夹,pytesser.pth,及内容都要一样! (3)Te
-
Python验证码识别的方法
本文实例讲述了Python验证码识别的方法.分享给大家供大家参考.具体实现方法如下: #encoding=utf-8 import Image,ImageEnhance,ImageFilter import sys image_name = "./22.jpeg" #去处 干扰点 im = Image.open(image_name) im = im.filter(ImageFilter.MedianFilter()) enhancer = ImageEnhance.Contrast(
-
Python+Selenium+PIL+Tesseract自动识别验证码进行一键登录
本文介绍了Python+Selenium+PIL+Tesseract自动识别验证码进行一键登录,分享给大家,具体如下: Python 2.7 IDE Pycharm 5.0.3 Firefox浏览器:47.0.1 Selenium PIL Pytesser Tesseract 扯淡 我相信每个脚本都有自己的故事,我这个脚本来源于自己GRD教务系统,每次进行登录时,即使我输入全部正确,第一次登录一定是登不上去的!我不知道设计人员什么想法?难道是为了反爬机制?你以为一次登不上,我tm就不爬了?我
-
Python网站验证码识别
0x00 识别涉及技术 验证码识别涉及很多方面的内容.入手难度大,但是入手后,可拓展性又非常广泛,可玩性极强,成就感也很足. 验证码图像处理 验证码图像识别技术主要是操作图片内的像素点,通过对图片的像素点进行一系列的操作,最后输出验证码图像内的每个字符的文本矩阵. 读取图片 图片降噪 图片切割 图像文本输出 验证字符识别 验证码内的字符识别主要以机器学习的分类算法来完成,目前我所利用的字符识别的算法为KNN(K邻近算法)和SVM (支持向量机算法),后面我 会对这两个算法的适用场景进行详细描述.
-
python下调用pytesseract识别某网站验证码的实现方法
一.pytesseract介绍 1.pytesseract说明 pytesseract最新版本0.1.6,网址:https://pypi.python.org/pypi/pytesseract Python-tesseract is a wrapper for google's Tesseract-OCR ( http://code.google.com/p/tesseract-ocr/ ). It is also useful as a stand-alone invocation scrip
-
python入门教程之识别验证码
前言 验证码?我也能破解? 关于验证码的介绍就不多说了,各种各样的验证码在人们生活中时不时就会冒出来,身为学生日常接触最多的就是教务处系统的验证码了,比如如下的验证码: 识别办法 模拟登陆有着复杂的步骤,在这里咱们不管其他操作,只负责根据输入的一张验证码图片返回一个答案字符串. 我们知道验证码为了制作干扰,会把图片弄成五颜六色的样子,而我们首先就是要去除这些干扰,这一步就需要不断试验了,增强图片色彩,加大对比度等等都可以产生帮助. 在经过各种对图片的操作之后,终于找到了比较完美的去除干扰方案.可
-
谈谈Python进行验证码识别的一些想法
用python加"验证码"为关键词在baidu里搜一下,可以找到很多关于验证码识别的文章.我大体看了一下,主要方法有几类:一类是通过对图片进行处理,然后利用字库特征匹配的方法,一类是图片处理后建立字符对应字典,还有一类是直接利用ocr模块进行识别.不管是用什么方法,都需要首先对图片进行处理,于是试着对下面的验证码进行分析. 一.图片处理 这个验证码中主要的影响因素是中间的曲线,首先考虑去掉图片中的曲线.考虑了两种算法: 第一种是首先取到曲线头的位置,即x=0时,黑点的位置.然后向后移动
-
python实现验证码识别功能
本文实例为大家分享了python实现验证码识别的具体代码,供大家参考,具体内容如下 1.通过二值化处理去掉干扰线 2.对黑白图片进行降噪,去掉那些单独的黑色像素点 3.消除边框上附着的黑色像素点 4.识别图像中的文字,去掉空格与'.' python代码: from PIL import Image from aip import AipOcr file='1-1-7' # 二值化处理,转化为黑白图片 def two_value(): for i in range(1, 5): # 打开文件夹中的
-
Python实现验证码识别
大致介绍 在python爬虫爬取某些网站的验证码的时候可能会遇到验证码识别的问题,现在的验证码大多分为四类: 1.计算验证码 2.滑块验证码 3.识图验证码 4.语音验证码 这篇博客主要写的就是识图验证码,识别的是简单的验证码,要想让识别率更高,识别的更加准确就需要花很多的精力去训练自己的字体库. 识别验证码通常是这几个步骤: 1.灰度处理 2.二值化 3.去除边框(如果有的话) 4.降噪 5.切割字符或者倾斜度矫正 6.训练字体库 7.识别 这6个步骤中前三个步骤是基本的,4或者5
-
python图片验证码识别最新模块muggle_ocr的示例代码
一.官方文档 https://pypi.org/project/muggle-ocr/ 二模块安装 pip install muggle-ocr # 因模块过新,阿里/清华等第三方源可能尚未更新镜像,因此手动指定使用境外源,为了提高依赖的安装速度,可预先自行安装依赖:tensorflow/numpy/opencv-python/pillow/pyyaml 三.使用代码 # 导入包 import muggle_ocr # 初始化:model_type 包含了 ModelType.OCR/Model
-
Python免费验证码识别之ddddocr识别OCR自动库实现
目录 安装过程: 完成之后,找个参考图片 附ddddocr-验证码识别案例 总结 需要ocr识别,推荐一个Python免费的验证码识别-ddddocr 安装过程: 1.镜像安装:pip install ddddocr -i https://pypi.tuna.tsinghua.edu.cn/simple pip install ddddocr -i https://pypi.tuna.tsinghua.edu.cn/simple 2.python.exe -m pip install --upg
-
Python通用验证码识别OCR库之ddddocr验证码识别
目录 前言 传统验证码 滑动验证码 文字点选验证码 总结 前言 相信做自动化测试的同学一定不可忽视的问题就是验证码,他几乎是一个网站登录的标配,当然,我一般是不建议在这上面浪费时间去做识别的. 举个例子,现在你的目的是进入自己家的房子,房子为了防止小偷进入于是上了一把锁.我们没必要花费力气去研究开锁技术.去找锁匠配置一把万能钥匙(让开发设置验证码的万能码),或者干脆先去上锁匠把验证码去掉(让开发暂时屏蔽验证码).严格来说识别验证码不是我们自动化测试的重点.除非你是验证码厂商的员工,破解识别验证码
-
Python通用验证码识别OCR库ddddocr的安装使用教程
目录 前言 一.安装ddddocr 二.使用ddddocr 1. 使用举例 2. 完整代码 3. 验证码样例 4. 识别结果 三.代码说明 总结 前言 在使用自动化登录网站的时候,经常输入用户名和密码后会遇到验证码.今天介绍一款通用验证码识别 OCR库,对验证码识别彻底说拜拜,它的名字是 ddddocr(带带弟弟 OCR ).这里主要以字母数字类验证码进行说明. 项目地址:https://github.com/sml2h3/ddddocr 一.安装ddddocr 通过命令将自动安装符合自己电脑环
-
python简单验证码识别的实现方法
利用SVM向量机进行4位数字验证码识别 主要是思路和步骤如下: 一,素材收集 检查环境是否包含有相应的库: 1.在cmd中,通过 pip list命令查看安装的库 2.再使用pip installRequests 安装Requests库 3.再次使用pip list 命令 4.利用python获取验证码资源 编写代码:_DownloadPic.py #!/usr/bin/nev python3 #利用python从站点下载验证码图片 import requests ## 1.在 http://w
-
python简单验证码识别的实现过程
目录 1. 环境准备 1.1 安装pillow 和 pytesseract 1.2 安装Tesseract-OCR.exe 1.3 更改pytesseract.py的ocr路径 2. 测试识别效果 3. 实战案例–实现古诗文网验证码自动识别登录 总结 1. 环境准备 1.1 安装pillow 和 pytesseract python模块库需要 pillow 和 pytesseract 这两个库,直接pip install 安装就好了. pip install pillow pip install