SQL SERVER中关于exists 和 in的简单分析
In与Exists这两个函数是差不多的,但由于优化方案不同,通常NOT Exists要比NOT IN要快,因为NOT EXISTS可以使用结合算法二NOT IN就不行了,而EXISTS则不如IN快,因为这时候IN可能更多的使用结合算法。
如图,现在有两个数据集,左边表示#tempTable1,右边表示#tempTable2。现在有以下问题:
1.求两个集的交集?
2.求tempTable1中不属于集#tempTable2的集?
先创建两张临时表:
create table #tempTable1
(
argument1 nvarchar(50),
argument2 varchar(20),
argument3 datetime,
argument4 int
);
insert into #tempTable1(argument1,argument2,argument3,argument4)
values('preacher001','13023218757',GETDATE()-1,1);
insert into #tempTable1(argument1,argument2,argument3,argument4)
values('preacher002','23218757',GETDATE()-2,2);
insert into #tempTable1(argument1,argument2,argument3,argument4)
values('preacher003','13018757',GETDATE()-3,3);
insert into #tempTable1(argument1,argument2,argument3,argument4)
values('preacher004','13023257',GETDATE()-4,4);
insert into #tempTable1(argument1,argument2,argument3,argument4)
values('preacher005','13023218',GETDATE()-5,5);
insert into #tempTable1(argument1,argument2,argument3,argument4)
values('preacher006','13023218',GETDATE()-6,6);
insert into #tempTable1(argument1,argument2,argument3,argument4)
values('preacher007','13023218',GETDATE()-7,7);
insert into #tempTable1(argument1,argument2,argument3,argument4)
values('preacher008','13023218',GETDATE()-8,8);
create table #tempTable2
(
argument1 nvarchar(50),
argument2 varchar(20),
argument3 datetime,
argument4 int
);
insert into #tempTable2(argument1,argument2,argument3,argument4)
values('preacher001','13023218757',GETDATE()-1,1);
insert into #tempTable2(argument1,argument2,argument3,argument4)
values('preacher0010','23218757',GETDATE()-10,10);
insert into #tempTable2(argument1,argument2,argument3,argument4)
values('preacher003','13018757',GETDATE()-3,3);
insert into #tempTable2(argument1,argument2,argument3,argument4)
values('preacher004','13023257',GETDATE()-4,4);
insert into #tempTable2(argument1,argument2,argument3,argument4)
values('preacher009','13023218',GETDATE()-9,9);
比如,我现在以#tempTable1和#tempTable2的argument1作为参照
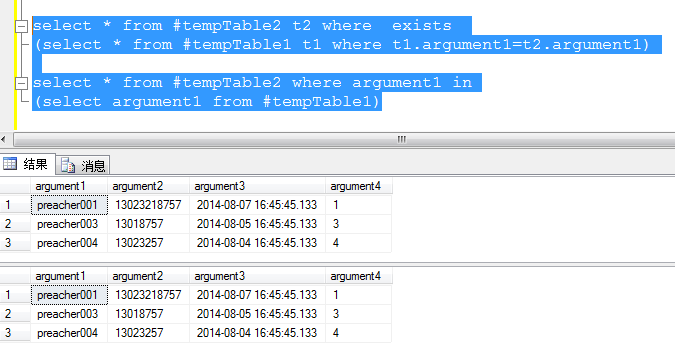
1.求两集的交集:
1)in 方式
select * from #tempTable2 where argument1 in (select argument1 from #tempTable1)
2)exists 方式
select * from #tempTable2 t2 where exists (select * from #tempTable1 t1 where t1.argument1=t2.argument1)
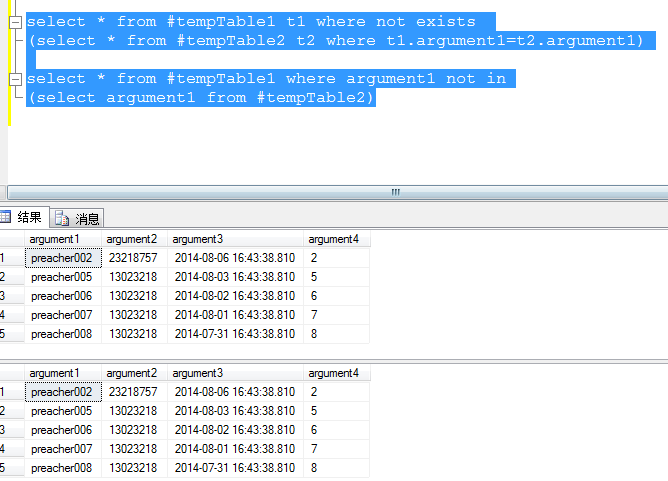
2.求tempTable1中不属于集#tempTable2的集
1)in 方式
select * from #tempTable1 where argument1 not in (select argument1 from #tempTable2)
2)exists 方式
select * from #tempTable1 t1 where not exists (select * from #tempTable2 t2 where t1.argument1=t2.argument1)
相关推荐
-
MySQL: mysql is not running but lock exists 的解决方法
启动MySQL出错,查看了下状态,发现提示MySQL is not running,but lock exists: 一个网友说可能和log文件有关,于是将log文件给移除了,再重启MySQL终于OK了找了下资料,基本上都是说: 复制代码 代码如下: # chown -R mysql:mysql /var/lib/mysql # rm /var/lock/subsys/mysql # service mysql restart 执行完发现还是这个提示. 因为是在cPanel服务器上,所以又通过命
-
sql语句优化之用EXISTS替代IN、用NOT EXISTS替代NOT IN的语句
在许多基于基础表的查询中,为了满足一个条件,往往需要对另一个表进行联接.在这种情况下, 使用EXISTS(或NOT EXISTS)通常将提高查询的效率.在子查询中,NOT IN子句将执行一个内部的排序和合并.无论在哪种情况下,NOT IN都是最低效的 (因为它对子查询中的表执行了一个全表遍历).为了避免使用NOT IN ,我们可以把它改写成外连接(Outer Joins)或NOT EXISTS. 如 我要查询 Sendorder表中的冗余数据(没有和reg_person或worksite相连的数
-
SQL查询中in和exists的区别分析
select * from A where id in (select id from B); select * from A where exists (select 1 from B where A.id=B.id); 对于以上两种情况,in是在内存里遍历比较,而exists需要查询数据库,所以当B表数据量较大时,exists效率优于in. 1.select * from A where id in (select id from B); in()只执行一次,它查出B表中的所有id字段并缓存
-
php数组查找函数in_array()、array_search()、array_key_exists()使用实例
php在数组中查找指定值是否存在的方法有很多,记得很久以前我一直都是傻傻的用foreach循环来查找的,下面我主要分享一下用php内置的三个数组函数来查找指定值是否存在于数组中,这三个数组分别是 in_array(),array_search(),array_key_exists(). 首先分别介绍一下各自的定义与作用 in_array(value,array,type) 该函数的作用是在数组array中搜索指定的value值,type是可选参数,如果设置该参数为 true ,则检查搜索的数据与
-
mysql insert if not exists防止插入重复记录的方法
MySQL 当记录不存在时插入(insert if not exists) 在 MySQL 中,插入(insert)一条记录很简单,但是一些特殊应用,在插入记录前,需要检查这条记录是否已经存在,只有当记录不存在时才执行插入操作,本文介绍的就是这个问题的解决方案. 在 MySQL 中,插入(insert)一条记录很简单,但是一些特殊应用,在插入记录前,需要检查这条记录是否已经存在,只有当记录不存在时才执行插入操作,本文介绍的就是这个问题的解决方案. 问题:我创建了一个表来存放客户信息,我知道可以用
-
mysql not in、left join、IS NULL、NOT EXISTS 效率问题记录
NOT IN.JOIN.IS NULL.NOT EXISTS效率对比 语句一:select count(*) from A where A.a not in (select a from B) 语句二:select count(*) from A left join B on A.a = B.a where B.a is null 语句三:select count(*) from A where not exists (select a from B where A.a = B.a) 知道以上三
-
UCenter info: MySQL Query Error SQL:SELECT value FROM [Table]vars WHERE noteexists
大家先看下数据库权限问题,然后再进行如下操作. SQL:SELECT value FROM [Table]vars WHERE name='noteexists2′ UCenter info: MySQL Query Error SQL:SELECT value FROM [Table]vars WHERE name='noteexists2′ Error:SELECT command denied to user '数据库'@'IP地址' for table 'pre_ucenter_vars
-
sql not in 与not exists使用中的细微差别
上面两个简单的Sql,我们从表面理解,查询的最终结果应该是一样的,但实际结果却和我们想象的不一样 第一条sql查询的结果有一条数据 第二条sql查询的结果却为空 原因: not exists的子查询,对于子查询不返回行和子查询返回行的查询结果是有区别的 这些细小的差别千万不要被我们所忽视,一旦项目庞大了,想跟踪到具体的错误所花费的时间也是可观的.尽量把这些不必要的错误扼杀在摇篮里. 啰嗦了,呵呵. 上面两个简单的Sql,我们从表面理解,查询的最终结果应该是一样的,但实际结果却和我们想象的不一样
-
Oracle In和exists not in和not exists的比较分析
把这两个很普遍性的网友比较关心的问题总结回答一下. in和exist的区别 从sql编程角度来说,in直观,exists不直观多一个select, in可以用于各种子查询,而exists好像只用于关联子查询 从性能上来看 exists是用loop的方式,循环的次数影响大,外表要记录数少,内表就无所谓了 in用的是hash join,所以内表如果小,整个查询的范围都会很小,如果内表很大,外表如果也很大就很慢了,这时候exists才真正的会快过in的方式. not in和not exists的区别
-

SQL SERVER中关于exists 和 in的简单分析
In与Exists这两个函数是差不多的,但由于优化方案不同,通常NOT Exists要比NOT IN要快,因为NOT EXISTS可以使用结合算法二NOT IN就不行了,而EXISTS则不如IN快,因为这时候IN可能更多的使用结合算法. 如图,现在有两个数据集,左边表示#tempTable1,右边表示#tempTable2.现在有以下问题: 1.求两个集的交集? 2.求tempTable1中不属于集#tempTable2的集? 先创建两张临时表: create table #tempTable1
-
SQL Server中修改“用户自定义表类型”问题的分析与方法
前言 SQL Server开发过程中,为了传入数据集类型的变量(比如接受C#中的DataTable类型变量),需要定义"用户自定义表类型",通过"用户自定义表类型"可以接收二维数据集作为参数,在需要修改"用户自定义表类型"的时候,增加字段,删除字段,修改字段类型等,它没有像表一样的alter table语法来进行修改. 只能通过删除重建来实现,但是在删除"用户自定义表类型"的时候会提示有对象引用它(某些存储过程用到了这个&qu
-
细说SQL Server中的视图
1,什么是视图? 2,为什么要用视图: 3,视图中的ORDER BY; 4,刷新视图: 5,更新视图: 6,视图选项: 7,索引视图: 1.什么是视图 视图是由一个查询所定义的虚拟表,它与物理表不同的是,视图中的数据没有物理表现形式,除非你为其创建一个索引:如果查询一个没有索引的视图,Sql Server实际访问的是基础表. 如果你要创建一个视图,为其指定一个名称和查询即可.Sql Server只保存视图的元数据,用户描述这个对象,以及它所包含的列,安全,依赖等.当你查询视图时,无论是获取数据还
-
SQL Server中关于基数估计计算预估行数的一些方法探讨
关于SQL Server 2014中的基数估计,官方文档Optimizing Your Query Plans with the SQL Server 2014 Cardinality Estimator里有大量细节介绍,但是全部是英文,估计也没有几个人仔细阅读.那么SQL Server 2014中基数估计的预估行数到底是怎么计算的呢? 有哪一些规律呢?我们下面通过一些例子来初略了解一下,下面测试案例仅供参考,如有不足或肤浅的地方,敬请指教! 下面实验测试的环境主要为SQL Server 201
-
在SQL Server中实现最短路径搜索的解决方法
开始这是去年的问题了,今天在整理邮件的时候才发现这个问题,感觉顶有意思的,特记录下来. 在表RelationGraph中,有三个字段(ID,Node,RelatedNode),其中Node和RelatedNode两个字段描述两个节点的连接关系:现在要求,找出从节点"p"至节点"j",最短路径(即经过的节点最少). 图1. 解析: 了能够更好的描述表RelationGraph中字段Node和 RelatedNode的关系,我在这里特意使用一个图形来描述,如图2. 图2
-
Sql Server中判断表、列不存在则创建的方法
一.Sql Server中如何判断表中某列是否存在 首先跟大家分享Sql Server中判断表中某列是否存在的两个方法,方法示例如下: 比如说要判断表A中的字段C是否存在两个方法: 第一种方法 IF EXISTS ( SELECT 1 FROM SYSOBJECTS T1 INNER JOIN SYSCOLUMNS T2 ON T1.ID=T2.ID WHERE T1.NAME='A' AND T2.NAME='C' ) PRINT '存在' ELSE PRINT '不存在' 第二种方法,短小
-
在SQL SERVER中导致索引查找变成索引扫描的问题分析
SQL Server 中什么情况会导致其执行计划从索引查找(Index Seek)变成索引扫描(Index Scan)呢? 下面从几个方面结合上下文具体场景做了下测试.总结.归纳. 1:隐式转换会导致执行计划从索引查找(Index Seek)变为索引扫描(Index Scan) Implicit Conversion will cause index scan instead of index seek. While implicit conversions occur in SQL Serve
-
SQL Server中的SQL语句优化与效率问题
很多人不知道SQL语句在SQL SERVER中是如何执行的,他们担心自己所写的SQL语句会被SQL SERVER误解.比如: select * from table1 where name='zhangsan' and tID > 10000 和执行: select * from table1 where tID > 10000 and name='zhangsan' 一些人不知道以上两条语句的执行效率是否一样,因为如果简单的从语句先后上看,这两个语句的确是不一样,如果tID是一个聚合索引,那
-
SQL Server中函数、存储过程与触发器的用法
一.函数 函数分为(1)系统函数,(2)自定义函数. 其中自定义函数又可以分为(1)标量值函数(返回单个值),(2)表值函数(返回查询结果) 本文主要介绍自定义函数的使用. (1)编写一个函数求该银行的金额总和 create function GetSumCardMoney() returns money as begin declare @AllMOney money select @AllMOney = (select SUM(CardMoney) from BankCard) return
-
SQL Server 中 RAISERROR 的用法详细介绍
SQL Server 中 RAISERROR 的用法 raiserror 的作用: raiserror 是用于抛出一个错误.[ 以下资料来源于sql server 2005的帮助 ] 其语法如下: RAISERROR ( { msg_id | msg_str | @local_variable } { ,severity ,state } [ ,argument [ ,...n ] ] ) [ WITH option [ ,...n ] ] 简要说明一下: 第一个参数:{ msg_id | ms