Python字符编码与函数的基本使用方法
一、Python2中的字符存在的解码编码问题
如果是现在正在用Python2的人应该都知道存在字符编码问题,就举一个最简单的例子吧:Python2是无法在命令行直接打印中文的,当然他也是不会报错的,顶多是一堆你看不懂的乱码。如果想在直接显示中文,我们是可以在Python2文件头部申明字符编码的格式。如下图

这里 #-*-coding:utf-8 -*- 是用来申明下面的代码是用什么编码来解释;
1.1.Python2中的解码和编码:
在编码和解码的世界中,我们得需要找一个大家都知道的文字。也可以这么理解。我是一个中国人现在和一个日本人沟通,我肯定是无法理解他说的是什么,他同样也无法理解,但是这样就没有办法了吗?或许我们需要一个国际的语言——英语。这样来自不同国家的人也可以进行沟通了(虽然我知道 are you ok 0-0)。在编码中也是一样,gbk和utf-8都不知道对方的格式是什么吊意思。所以如果要上gbk读懂utf-8的编码就得将utf-8 decode成 Unicode,而Unicode有知道gkb,这里需要将Unicode在encode成gbk就行了
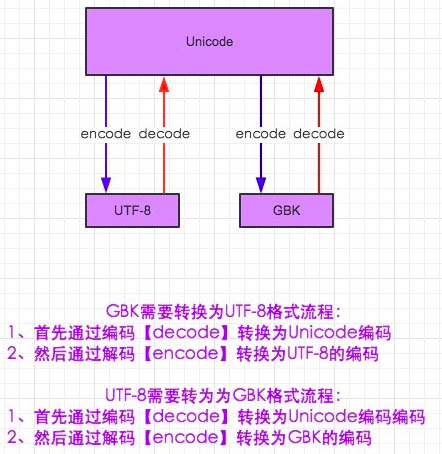
#-*- coding:utf-8 -*- msg = "中国" print msg #解码在编码的过程,encoding是申明用申明这段代码是什么编码 gbk_str = msg.decode(encoding='utf-8').encode(encoding='gbk') print gbk_str #其实两种输出的结果是一样的
在Python2中默认是使用gbk来解释IDE中的代码的,所以无法直接在Python命令行中直接输入中文,所以我们才会使用 #-*-coding:utf-8 -*-来申明头部,我们到底需要使用什么语言来解释下面代码。细心的人肯定是发现了一个问题,申明头部只是使用utf-8来解释下面的话,按理说命令行中虽然不报错,但是应该也是乱码才是,这里为啥会直接输出中文呢毕竟DOS命令行中默认支持的是gbk格式的字符代码呀?这里就涉及到另外的一个概念了。Python到内存解释器里面,默认是用的Unicode,文件加载到内存后自动解码成Unicode,而Unicode是外国码,自然也就可以翻译来自utf-8的编码,也可以翻译成gbk的编码了。顾可以显示中文了。
PS:这里我们得出一个结论:python2 中解码动作是必须的,但是编码可以不用,因为内存就是Unicode
1.2、Python3中字符编码的问题:
额,这还有什么可以说的呢?Python3默认就是使用utf-8解释代码的。也就是行首自带 #-*-coding:utf-8 -*-(GBM),所以也就不存在解码的问题。但是我在这里提上一嘴(其实就是怕自己以后也忘了,嘿嘿),如果我们将utf-8的字符编码的格式给编码成gbk。这里会输出bytes格式的东西。
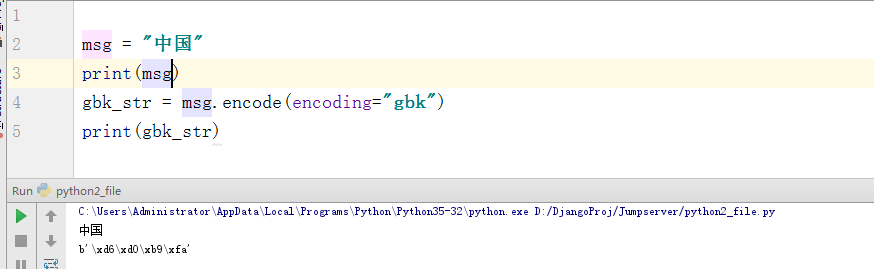
bytes到底是什么东西呢?这里我简单的说一下。其实就是这个字符在ASCII码中对应的位置。不信,我们通过一段代码截图看看:
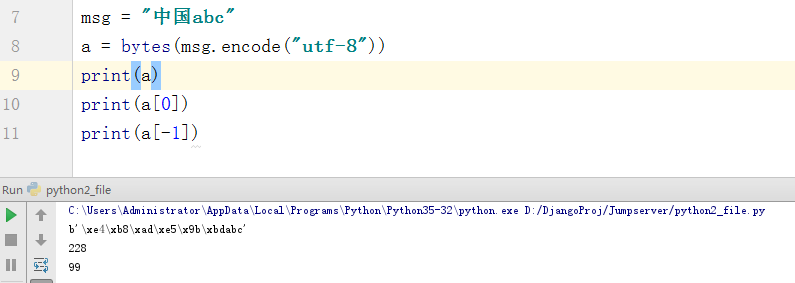
在这一幅图中我们看到中国被传成了一堆看不懂的鸟文。而英文还是显示出来了。但是我们通过列表的截取,看出最后一位的c输出的是99,其实这里输出的就是ASCII中c对应的位置,而3个bytes是一个中文,所以我们看到了6段鸟文字,这里我们就不过多解释了。
PS:大家得记得一个东西就是:Python2 里面的str 就是Python3中的bytes格式,而Python2中的str其实就是Unicode
二、Python3对文件操作补充
2.1、带“+”的文件操作:
在这里我会说三个,但是其实这些东西都没有什么鸟用,只是这算上一个知识点
r+: 可读,可以追加
w+:清空源文件,再写入新内容
a+:追加,可以读
f = open('lyrics','r+',encoding='utf-8') #这里的lyrics是文件名字
f.read() #我先读取
f.write("Leon Have Dream") #在后面追加
f.close()
r+:如果是先f.read()再f.write()就是在文件的结尾追加,如果是直接f.write()就直接将文件开始的内容替换成()中的内容;
f = open('lyricsback','w+',encoding='utf-8')
f.read()
f.write("Leon Have Dream")
f.read()
f.close()
w+:其实就是清空内容再重新写入write()中的内容,并且f.read()也不会报错,个人建议可以在快要离职的时候执行这个操作
f = open('lyricsback','a+',encoding='utf-8')
f.read()
f.write("Leon Have A Draem")
f.read()
f.close()
a+:其实和r+非常相似是在结尾中追加内容,可读内容
PS:这里的补充一下,为什么在使用r+的时候先执行f.read()再执行f.write()就会在文件的结尾追加和直接使用f.write()直接就替换文件最前边的内容呢?这是因为Python在读文件的时候自己维护这一个“指针”,如果我们使用f.read()就相当于读完了这个文件,这时候指针也就会在最后面了。下面我在补充“f”这个对象的几个用法来证明Python文件指针。
f = open('lyricsback','r+' ,encoding='utf-8')
print(f.tell()) #this number is 0
f.seek(12) # 将指针向后面移动几个字节,一个汉字是三个字节
print(f.tell()) # this is seek number
f.write("Love Girl") #这里就从seek到地方替换
print(f.tell()) # tell()用法就是文件的指针位置
f.close()
2.2、加b的方式对文件进行操作
rb:将文件以二进制的方式从硬盘中读取出来,这里得记住在open()函数中不要加encoding= 这个参数因为二进制不存在编码上的问题
wb:将文件以二进制的方式写入内容,不过在f.write()中加上encode="utf-8",意思就是申明编码的格式,并且会清楚原来文件内容
ab:只能以二进制方式追加。
三、函数
什么是函数?函数可以简单理解一段命令的集合。为什么需要用函数?这里有一个非常简单的原因,比如说你需要对一段代码反复进行操作,这里你当然可以一直复制再粘贴,但是这样灵活性和日后的维护成本将会变大。
#比方说现在需要写一个报警(调用接口)的程序,这里就用监控做比喻 if cpu > 80%: 连接邮箱服务器 发送消息 关闭连接 if memery > 80%: 连接邮箱服务器 发送消息 关闭连接 if disk > 80% 连接邮箱服务器 发送消息 关闭连接 #通过写这样的一个程序我们发现我们一直在重复调用发送邮箱的这一套接口。这样我们是否能想出一个办法解决这样的重复操作呢?请看下一个版本 发送邮件(): l连接邮箱服务器 发送连接 关闭连接 if cpu > 80% 发送邮件() if memery > 80%: 发送邮件() ....... # 这样以此类推,我们只需要挑用发送邮件的这个接口就可以节省代码的发送邮件了
通过上面的代码我们发现,我们只需要将报警的这一套流程放到一个公共的地方,等下面触发报警的条件的时候调用报警的函数,这样我们就可以省去当每次触发报警的时候我们自己在写报警的步骤了。但是函数是怎么定义呢?又有什么语法和定义呢?请看下面的一段代码,其中代码输出的是“Leon Have A Dream”
def leon(): #leon是函数名字
print("Leon Have A Dream")
leon() #调用函数
带参数的函数:
a = 10 b = 5 def calc(a,b): print(a ** b) c = calc(a,b) print(c)
首先上面这些代码执行完会输出两个字符,一个是10000,一个是None,为什么会这样呢?首先c是等于执行了一遍calc这个函数,所以输出10000这个数字是肯定的,但是为什么还会输出一个None呢?原来我们的“c”执行了仪表calc函数,而calc函数中没有任何的返回值,所以c == None 。
PS:函数的返回结果就是return,其中return的含义就是:把函数的执行结果返回给外面,从而让挑用函数的“对象”得到执行结果
下面我们在看与之相似的列子
a = 10 b = 5 def calc(a,b): print(a ** b) return a + b c = calc(a,b) c = calc(10,6) print(c)
首先会输出的有三个值,分别是100000,1000000,16,为什么会是这三个呢,下面用一副图来说一下

PS:
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
Python中的全局变量和局部变量

PS:函数内部是可以修改列表,字典,集合,实例(class),我们通过下面一个图来说明
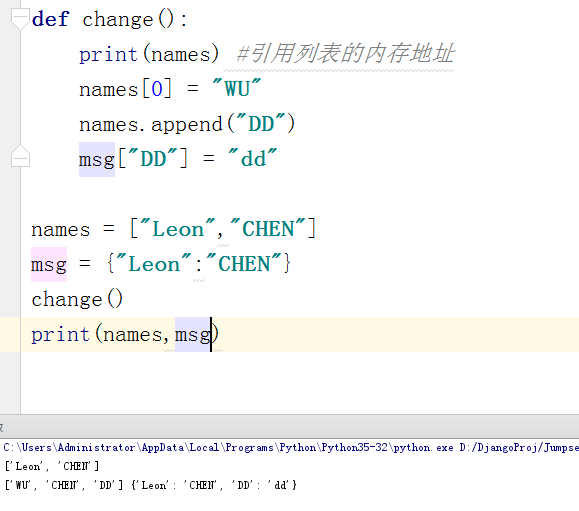
为什么列表和字典等会被添加和修改呢,原来函数内部知识引用了字典和列表的内存地址,而内存地址无法修改(可以重新开辟一块内存地址),而每个字典和列表中的每一个值都有对应的内存地址,但是记住我们函数是引用的列表或者字典本身的内存地址,所以这样打印到出来的也就会跟着改变了。
全局与局部变量
在子程序中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量。
全局变量作用域是整个程序,局部变量作用域是定义该变量的子程序。
当全局变量与局部变量同名时:
在定义局部变量的子程序内,局部变量起作用;在其它地方全局变量起作用。
位置参数:
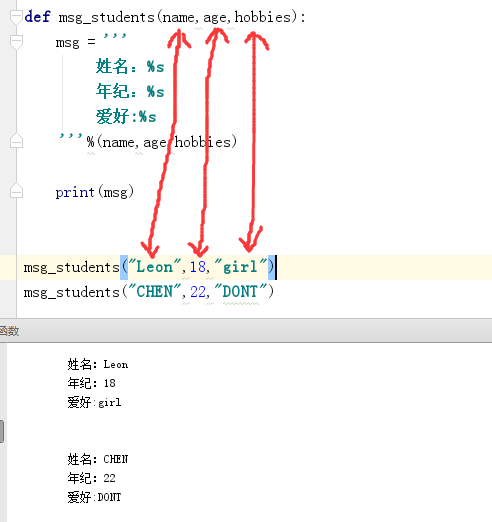
像上面这样实参和形参一一对应的上就是就是位置参数
默认参数:

在函数将一个位置参数设置成一个默认的值的那一个变量就是默认参数,记住默认参数得在位置参数得后面
关键参数:
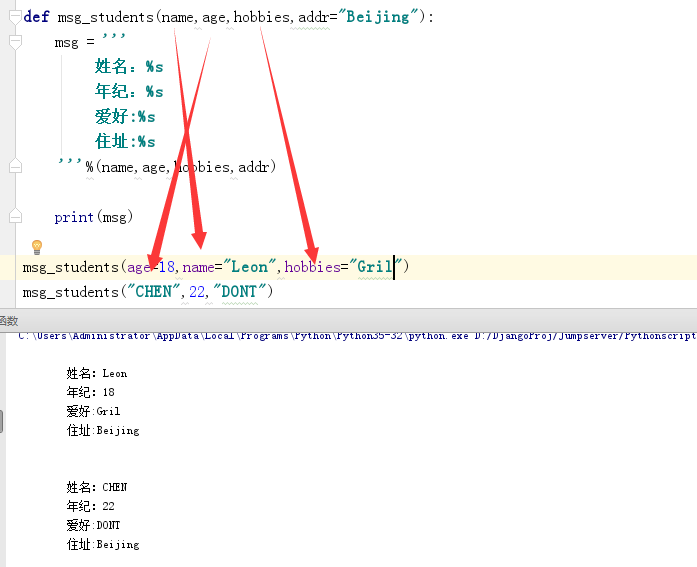
像上面这样实参和形参不一一对应,并且在调用函数的时候给参数赋值的叫做关键参数
非固定函数:
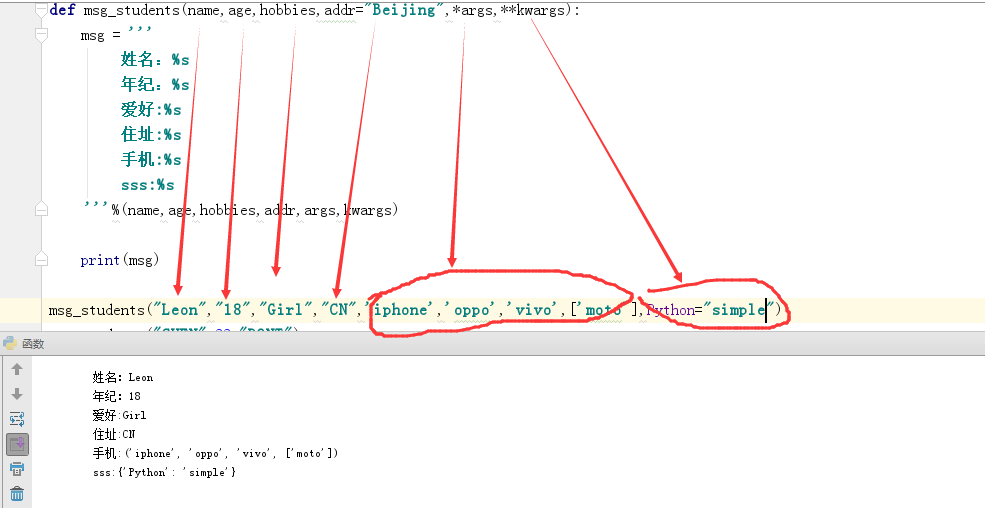
通过输出结果我们发现*args是接收多余的字符串类型的参数,而想Python="simple"(字典)类型的会传入给**kwargs,这就是非固定参数;当你不知道这个参数需要多少个参数时可以使用该函数类型
递归函数——二分查找
a = [1,2,3,4,5,7,9,10,11,12,14,15,16,17,19,21]
def calc(num,find_num):
print(num)
mid = int(len(num) / 2)
if mid == 0:
if num[mid] == find_num:
print("find it %s"%find_num)
else:
print("cannt find num")
if num[mid] == find_num:
print("find_num %s"%find_num)
elif num[mid] > find_num:
calc(num[0:mid],find_num)
elif num[mid] < find_num:
calc(num[mid+1:],find_num)
calc(a,12)
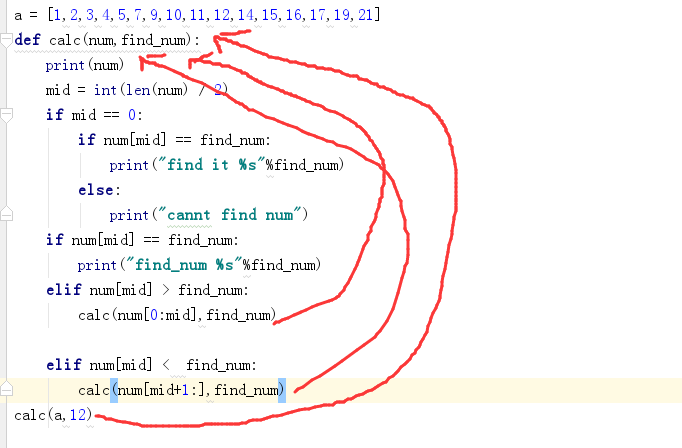
递归的特性
函数必须有明确的结束(判断)条件,也就是上图一开始的mid[0] 不能等于0,因为这样就会没有意义了
每次进入更深一层递归时,问题规模相比上次递归都应有所减少
递归函数每次向下递归一次,上次的函数占用的内存地址不会被释放,而是一直会被阻塞主,等待函数全部执行完毕后释放,所以也可以说递归是相当消耗内存空间的,对此Python有递归的深度,如果超过该深度函数将会被推出(栈溢出)
匿名函数:
calc = lambda x:x+2 # x是形参,冒号后的内容是该匿名函数执行的动作 print(calc(5)) #匿名函数意识需要通过调用来执行的 calc = lambda x,y,z:x*y*z #匿名函数可以传入多个形参,各个参数之间用逗号隔开 print(calc(2,4,6)) c = map(lambda x:x*2,[2,5,4,6]) #map方法需要 传入两个参数一个是function(函数),itrables(可迭代)的数据类型 for i in c: print(i) #三元运算 for i in map(lambda x:x**2 if x >5 else x - 1,[1,2,3,5,7,8,9]): #lambda最多支持三元运算,map是直接调用匿名函数,但是如果想打印map的内容,需要循环 print(i)
高阶函数:
def calc(x,y,f): print(f(x) + f(y)) calc(10,-10,abs)
高阶函数的特性
把一个函数的内存地址传给另外一个函数,当做参数
一个函数把另外一个函数的当做返回值返回
满足上面的这个两个特性中的一个就可以称为高阶函数,这里因为偷懒,就是直接调用了Python中的内置函数
以上这篇Python字符编码与函数的基本使用方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python中字符编码简介、方法及使用建议
1. 字符编码简介 1.1. ASCII ASCII(American Standard Code for Information Interchange),是一种单字节的编码.计算机世界里一开始只有英文,而单字节可以表示256个不同的字符,可以表示所有的英文字符和许多的控制符号.不过ASCII只用到了其中的一半(\x80以下),这也是MBCS得以实现的基础. 1.2. MBCS 然而计算机世界里很快就有了其他语言,单字节的ASCII已无法满足需求.后来每个语言就制定了一套自己的编码,由于单字节
-
Python获取系统默认字符编码的方法
本文实例讲述了Python获取系统默认字符编码的方法.分享给大家供大家参考.具体分析如下: 在Python代码中,普通字符串的编码方式与程序源文件编码方式一致的,而很多IDE在默认情况下,将程序源文件按照系统默认字符编码来保存的. 下面给出用Python获取系统默认编码的例子: #!/usr/bin/env python #coding=utf-8 """ 获取系统默认编码 """ import sys print sys.getdefaulte
-

详解Python当中的字符串和编码
字符编码 我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节.比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295. 由于计算机是美国人发明的,因此,最早只有1
-
Python字符编码判断方法分析
本文实例讲述了Python字符编码判断方法.分享给大家供大家参考,具体如下: 方法一: isinstance(s, str) 用来判断是否为一般字符串 isinstance(s, unicode) 用来判断是否为unicode 或 if type(str).__name__!="unicode": str=unicode(str,"utf-8") else: pass 方法二: Python chardet 字符编码判断 使用 chardet 可以很方便的实现字符串
-
Python 字符串操作方法大全
1.去空格及特殊符号 复制代码 代码如下: s.strip().lstrip().rstrip(',') 2.复制字符串 复制代码 代码如下: #strcpy(sStr1,sStr2)sStr1 = 'strcpy'sStr2 = sStr1sStr1 = 'strcpy2'print sStr2 3.连接字符串 复制代码 代码如下: #strcat(sStr1,sStr2)sStr1 = 'strcat'sStr2 = 'append'sStr1 += sStr2print sStr1 4.查
-
Python字符编码与函数的基本使用方法
一.Python2中的字符存在的解码编码问题 如果是现在正在用Python2的人应该都知道存在字符编码问题,就举一个最简单的例子吧:Python2是无法在命令行直接打印中文的,当然他也是不会报错的,顶多是一堆你看不懂的乱码.如果想在直接显示中文,我们是可以在Python2文件头部申明字符编码的格式.如下图 这里 #-*-coding:utf-8 -*- 是用来申明下面的代码是用什么编码来解释: 1.1.Python2中的解码和编码: 在编码和解码的世界中,我们得需要找一个大家都知道的文字.也可以
-
彻底搞懂Python字符编码
不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久,你一定遇到过UnicodeEncodeError.UnicodeDecodeError 错误,每当遇到错误我们就拿着 encode.decode 函数翻来覆去的转换,有时试着试着问题就解决了,有时候怎么试都没辙,只有借用 Google 大神帮忙,但似乎很少去关心问题的本质是什么,下次遇到类似的问题重蹈覆辙,那么你有没有想过一次性彻底把 Python 字符编码给搞懂呢? 完全理解字符编码 与 Python 的渊源前,我们有
-
浅析Python 字符编码与文件处理
Python字符编码 目前计算机内存的字符编码都是Unicode,目前国内的windows操作系统采用的是gbk. python2默认的字符编码方式是ASCII python3默认的字符编码方式是Unicode .py文件头部的#coding:utf-8是帮助python识别.py文件的编码方式,故在写.py文件时要注意文件头和文件保存时的编码方式要相同,否则可能会出现乱码 python程序运行过程: python的解释器现在内存中启动 解释器把要运行的文件以文本文件的形式读进内存 解释器按照文
-
关于Python字符编码与二进制不得不说的一些事
二进制 核心思想: 冯诺依曼 + 图灵机 电如何表示状态,才能稳定? 计算机开始设计的时候并不是考虑简单,而是考虑能自动完成任务与结果的可靠性, 简单始终是建立再稳定.可靠基础上 经过尝试10进制,但很难检查电流的状态差异并且很难稳定状态,最稳定的检查是 通电和不通电状态,共两种状态那就规定 通电为 1 不通电 为 0,1和0的状态逻 辑被称为比特 Bit 那么如何用 0 和 1 表示数字和字符呢? 首先找出需要表示的字符,英文字符和数字字符才100多个,需要 7 个二进制位就 可以全部表示,但
-
一篇文章彻底弄懂Python字符编码
目录 1. 字符编码简介 1.1. ASCII 1.2. MBCS 1.3. Unicode 2. Python2.x中的编码问题 2.1. str和unicode 2.2. 字符编码声明 2.3. 读写文件 2.4. 与编码相关的方法 3.建议 3.1.字符编码声明 3.2. 抛弃str,全部使用unicode. 3.3. 使用codecs.open()替代内置的open(). 3.4. 绝对需要避免使用的字符编码:MBCS/DBCS和UTF-16. 1. 字符编码简介 1.1. ASCII
-
php中的字符编码转换函数用法示例
本文实例讲述了php中的字符编码转换函数的用法,分享给大家供大家参考.具体实现方法如下: 一般来说,在网页程序中,尤其是涉及到数据库的读出过程中,往往最恼火的就是字符编码的问题,php4.0.6以上的版本提供了mb_convert_encoding 可以方便的转换编码. 具体如下: 复制代码 代码如下: <?php /* Convert internal character encoding to SJIS */ $str = mb_convert_encoding($str, "SJIS
-
快速入手Python字符编码
前言 对于很多接触Python的人而言,字符的处理和语言整体的温顺可靠相比显得格外桀骜不驯难以驾驭. 文章针对Python 2.7,主要因为3对的编码已经有了很大的改善并且实际原理一样,更改一下操作命令即可. 了解完本文,你可以轻松解决文字处理,特殊平台(Windows?)下的编码,爬虫编码等问题. 阅读建议 本文分为如下几个部分: 1.原理 2.具体操作 3.建议的使用习惯 4.疑难问题解答 如果想要了解我给出的使用习惯,可以直接跳到建议的使用习惯. 如果只想要解决相关问题可以直接跳到疑难问题
-
基于python 字符编码的理解
一.字符编码简史: 美国:1963年 ASCII (包含127个字符 占1个字节) 中国:1980年 GB2312 (收录7445个汉字,包括6763个汉字和682个其它符号) 1993年 GB13000 (收录20902个汉字) 1995年 GBK1.0 (收录 21003个汉字) 2000年 GB18030 (收录70244个汉字) 世界:1991年 unicode('万国码'也就统一编码,通常占2字节,复杂的汉字占4字节) UTF-8 (可变长的字符编码) 二.python中的编码解码应
-
Python字符编码转码之GBK,UTF8互转
一.Python字符编码介绍 1.须知: 在python 2中默认编码是 ASCII,而在python 3中默认编码是 unicode unicode 分为utf-32 (占4个字节),utf-16(占两个字节),utf-8(占1-4个字节),所以utf-16 是最常用的unicode版本,但是在文件里存的还是utf-8,因为utf8省空间 在python 3,encode编码的同时会把stringl变成bytes类型,decode解码的同时会把bytes类型变成string类型 在unicod