布隆过滤器面试如何快速判断元素是否在集合里
目录
- 1、什么叫布隆过滤器
- 2、实现原理
- 3、作用
- 4、具体实现
- 5、代码的实现
- 6、实战
- 7、小结
如何快速判断一个元素是不是在一个集合里?这个题目是我最近面试的时候常问的一个问题,这个问题不同人都有很多不同的回答。
今天想介绍一个很少有人会提及到的方案,那就是借助布隆过滤器。
1、什么叫布隆过滤器
布隆过滤器(Bloom Filter)是一个叫做 Bloom 的老哥于1970年提出的。
实际上可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。
它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。

2、实现原理
先来一张图

布隆过滤器算法主要思想就是利用 n 个哈希函数进行 hash 过后,得到不同的哈希值,根据 hash 映射到数组(这个数组的长度可能会很长很长)的不同的索引位置上,然后将相应的索引位上的值设置为1。
判断该元素是否出现在集合中,就是利用k个不同的哈希函数计算哈希值,看哈希值对应相应索引位置上面的值是否是1,如果有1个不是1,说明该元素不存在在集合中。
但是也有可能判断元素在集合中,但是元素不在,这个元素所有索引位置上面的1都是别的元素设置的,这就导致一定的误判几率(这就是为什么上面是活可能在一个集合中的根本原因,因为会存在一定的 hash 冲突)。
注意:误判率越低,相应的性能就会越低。
3、作用
布隆过滤器是可以用于判断一个元素是不是(可能)在一个集合里,并且相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。
注意上面的一个词:可能。这里先预留一个悬念,下文会详细分析到。
判断给定数据是否存在
防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。
4、具体实现
看完了布隆过滤器的算法思想,那就开始具体的实现的讲解。
我先来举个例子,假设有旺财和小强两个字符串,他们分别经过三次的 hash 算法,然后根据 hash 的结果将对应的数组(假设数组长度为 16)的索引位置的值置为1,先来看下旺财这个词组:
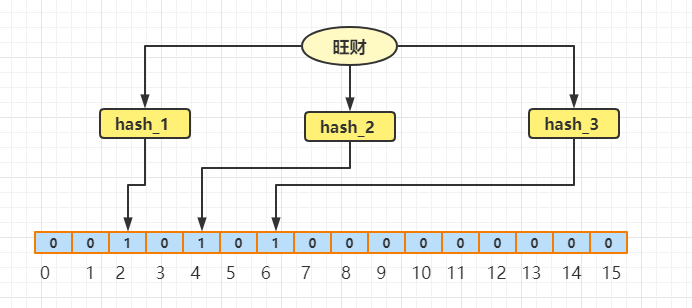
旺财经过三次 hash 过后,值分别为2,4,6 那么根据可以得到索引值分别为 2、4、6,于是就将该数组的索引(2、4、6)位置的值置为1,其余当做是0,现在假设需要查找旺财 ,同样经过这个三个hash 然后发现得到的索引 2、4、6对应的位置的值都为1,那么可以判断旺财可能是存在的。
接着有将小强插入到布隆过滤器中,实际的过程和上面的一样,假设得到的下标是 1、3、5

抛开旺财的存在,小强此时是这样子在布隆过滤器中的,结合旺财和小强实际的数组是这样子的:

现在有来一个数据:9527,现在要求是判断 9527 是否存在,假设9527 经过三次 hash 过后得到的下标分别为:5、6、7。结果发现下标为 7 的位置的值为0,那么可以肯定的判断出,9527 一定不存在。
接着又来了一个 国产007,经过三次 hash 过后得到的下标分别为:2、3、5,结果发现 2、3、5下标对应的值全是1,于是可以大致判断出 国产007可能存在。但是实际上经过我们刚刚的演示,国产007 根本就不存在,之所以 2、3、5 索引位置的值为1 ,那是因为其他的数据设置的。
说到这里,不知道大家有没有明白布隆过滤器的作用。
5、代码的实现
作为 java 程序员,我们真的是很幸福了,我们使用到很多的框架和工具,基本都被封装好了,布隆过滤器,我们就使用 google 封装好的工具类。当然还有其他方法,大家可以探索探索。
首先添加依赖
<!--布隆过滤依赖-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>25.1-jre</version>
</dependency>
代码的实现
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.nio.charset.Charset;
public class BloomFilterDemo {
public static void main(String[] args) {
/**
* 创建一个插入对象为一亿,误报率为0.01%的布隆过滤器
* 不存在一定不存在
* 存在不一定存在
* ----------------
* Funnel 对象:预估的元素个数,误判率
* mightContain :方法判断元素是否存在
*/
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 100000000, 0.0001);
bloomFilter.put("死");
bloomFilter.put("磕");
bloomFilter.put("Redis");
System.out.println(bloomFilter.mightContain("Redis"));
System.out.println(bloomFilter.mightContain("Java"));
}
}
具体的解释已经写在注释中了。到这里相信大家一定明白了布隆过滤器和其怎么使用了。
6、实战
我们来模拟这样的场景:通过布隆过滤器来解决缓存穿透。
首先你的知道什么叫缓存穿透吧?
缓存穿透是指用户访问一个缓存和数据库中都没有的数据,因为缓存中不存在,所以就会去访问数据库,如果并发很高。很容易会击垮数据库
那布隆过滤器是如何解决这个问题的呢?他
的原理是这样子的:将数据库中所有的查询条件,放入布隆过滤器中,当一个查询请求过来时,先经过布隆过滤器进行查,如果判断请求查询值存在,则继续查;如果判断请求查询不存在,直接丢弃。
其代码如下:
String get(String key) {
String value = redis.get(key);
if (value == null) {
if(!bloomfilter.mightContain(key)){
return null;
}else{
value = db.get(key);
redis.set(key, value);
}
}
return value;
}
7、小结
本文详细介绍了布隆过滤器是什么?有什么作用?实现原理以及从代码层面多方面来阐述布隆过滤器。希望能为各位在学习进阶的路上添砖加瓦。
以上就是布隆过滤器面试如何快速判断元素是否在集合里的详细内容,更多关于布隆过滤器面试判断元素是否在集合里的资料请关注我们其它相关文章!
相关推荐
-
Java中高效判断数组中是否包含某个元素的几种方法
目录 检查数组是否包含某个值的方法 使用List 使用Set 使用循环判断 使用Arrays.binarySearch() 时间复杂度 使用一个长度为1k的数组 使用一个长度为10k的数组 总结 补充 使用ArrayUtils 完整测试代码 长字符串数据 如何检查一个数组(无序)是否包含一个特定的值?这是一个在Java中经常用到的并且非常有用的操作.同时,这个问题在Stack Overflow中也是一个非常热门的问题.在投票比较高的几个答案中给出了几种不同的方法,但是他们的时间复杂度也是各不相同
-
Java函数式编程(四):在集合中查找元素
查找元素 现在我们对这个设计优雅的转化集合的方法已经不陌生了,但它对查找元素却也是无能为力.不过filter方法却是为这个而生的. 我们现在要从一个名字列表中,取出那些以N开头的名字.当然可能一个也没有,结果可能是个空集合.我们先用老方法实现一把. 复制代码 代码如下: final List<String> startsWithN = new ArrayList<String>(); for(String name : friends) { if(name.startsWith(&
-
Java中高效的判断数组中某个元素是否存在详解
一.检查数组是否包含某个值的方法 使用List public static boolean useList(String[] arr, String targetValue) { return Arrays.asList(arr).contains(targetValue); } 使用Set public static boolean useSet(String[] arr, String targetValue) { Set<String> set = new HashSet<Stri
-
java判定数组或集合是否存在某个元素的实例
引言: 今天群里有朋友问"怎么知道一个数组集合是否已经存在当前对象",大家都知道循环比对,包括我这位大神群友.还有没其他办法呢?且看此篇. 正文: 能找到这里的都是程序员吧,直接上代码应该更清楚些. import java.io.Serializable; import java.util.ArrayList; import java.util.Arrays; import java.util.Collection; import java.util.regex.Matcher; im
-
Java判断List中有无重复元素的方法
Talk is cheap, show me the code: import java.util.ArrayList; import java.util.HashSet; import java.util.List; /** * 通过简单的代码判断List中是否包含相同元素 * @author wei 2017年7月10日 下午8:34:47 */ public class ListHaveRepeat { public static void main(String[] args) { Li
-

布隆过滤器面试如何快速判断元素是否在集合里
目录 1.什么叫布隆过滤器 2.实现原理 3.作用 4.具体实现 5.代码的实现 6.实战 7.小结 如何快速判断一个元素是不是在一个集合里?这个题目是我最近面试的时候常问的一个问题,这个问题不同人都有很多不同的回答. 今天想介绍一个很少有人会提及到的方案,那就是借助布隆过滤器. 1.什么叫布隆过滤器 布隆过滤器(Bloom Filter)是一个叫做 Bloom 的老哥于1970年提出的. 实际上可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构. 它的
-
go语言中布隆过滤器低空间成本判断元素是否存在方式
目录 简介 原理 数据结构 添加 判断存在 哈希函数 布隆过滤器大小.哈希函数数量.误判率 应用场景 数据库 黑名单 实现 数据结构 初始化 添加元素 判断元素是否存在 简介 布隆过滤器(BloomFilter)是一种用于判断元素是否存在的方式,它的空间成本非常小,速度也很快. 但是由于它是基于概率的,因此它存在一定的误判率,它的Contains()操作如果返回true只是表示元素可能存在集合内,返回false则表示元素一定不存在集合内.因此适合用于能够容忍一定误判元素存在集合内的场景,比如缓存
-
Redis使用元素删除的布隆过滤器来解决缓存穿透问题
目录 前言 缓存雪崩 解决方案 缓存击穿 解决方案 缓存穿透 解决方案 布隆过滤器(Bloom Filter) 什么是布隆过滤器 位图(Bitmap) 哈希碰撞 布隆过滤器的2大特点 fpp 布隆过滤器的实现(Guava) 布隆过滤器的如何删除 带有计数器的布隆过滤器 总结 前言 在我们日常开发中,Redis使用场景最多的就是作为缓存和分布式锁等功能来使用,而其用作缓存最大的目的就是为了降低数据库访问.但是假如我们某些数据并不存在于Redis当中,那么请求还是会直接到达数据库,而一旦在同一时间大
-
C++ 数据结构之布隆过滤器
布隆过滤器 一.历史背景知识 布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率和查询时间都远超过一般的算法,缺点是有一定的误识别率和删除错误.而这个缺点是不可避免的.但是绝对不会出现识别错误的情况出现(即假反例False negatives,如果某个元素确实没有在该集合中,那么Bloom Filter 是不会报告该元素存在集合中的,所以不会漏报) 在 FBI,一个
-
Redis实现布隆过滤器的方法及原理
布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难. 本文将介绍布隆过滤器的原理以及Redis如何实现布隆过滤器. 应用场景 1.50亿个电话号码,现有10万个电话号码,如何判断这10万个是否已经存在在50亿个之中?(可能方案:数据库,set, hyperloglog) 2.新闻客户端看新闻时,它会不
-
布隆过滤器的原理以及java 简单实现
一.布隆过滤器 布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难. 如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定.链表.树.散列表(又叫哈希表,Hash table)等等数据结构都是这种思路.但是随着集合中元素的增加,我们需要的存储空间越来越大.同时检索
-
什么是Java布隆过滤器?如何使用你知道吗
目录 一.布隆过滤器简介 二.布隆过滤器的结构 三.布隆过滤器应用 四.布隆过滤器的优缺点 五.布隆过滤器实战 六.总结 Redis缓存穿透可以通过布隆过滤器进行解决,那么什么是布隆过滤器呢?请往下看. 通常你判断某个元素是否存在用的是什么? 很多人想到的是HashMap. 确实可以将值映射到 HashMap 的 Key,然后可以在 O(1) 的时间复杂度内返回结果,效率奇高.但是 HashMap 的实现也有缺点,例如存储容量占比高,考虑到负载因子的存在,通常空间是不能被用满的,而一旦你的值很多
-
Redis BloomFilter布隆过滤器原理与实现
目录 Bloom Filter 概念 Bloom Filter 原理 缓存穿透 Bloom Filter的缺点 常见问题 go语言实现 Bloom Filter 概念 布隆过滤器(英语:Bloom Filter)是1970年由一个叫布隆的小伙子提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难. Bloom Filter 原理 布隆过滤器的原理是,当一个元素
-
Java布隆过滤器的原理和实现分析
目录 前言 1. 预备知识 1.1 哈希函数 2. 布隆过滤器 2.1 概念 2.2 实现原理 2.3 步骤 2.4 实现 前言 数组.链表.树等数据结构会存储元素的内容,一旦数据量过大,消耗的内存也会呈现线性增长 所以布隆过滤器是为了解决数据量大的一种数据结构 讲述布隆过滤器的时候需要了解一些预备的知识点:比如哈希函数 1. 预备知识 1.1 哈希函数 哈希函数指将哈希表中元素的关键键值映射为元素存储位置的函数 一般的线性表,树中,记录在结构中的相对位置是随机的,即和记录的关键字之间不存在确定
-
Python+Redis实现布隆过滤器
布隆过滤器是什么 布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难. 布隆过滤器的基本思想 通过一种叫作散列表(又叫哈希表,Hash table)的数据结构.它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点.这样一来,我们只要看看这个点是不是1就可以知道集合中有没