pyspark操作hive分区表及.gz.parquet和part-00000文件压缩问题
目录
- pyspark 操作hive表
pyspark 操作hive表
pyspark 操作hive表,hive分区表动态写入;最近发现spark动态写入hive分区,和saveAsTable存表方式相比,文件压缩比大约 4:1。针对该问题整理了 spark 操作hive表的几种方式。
1> saveAsTable写入
saveAsTable(self, name, format=None, mode=None, partitionBy=None, **options)
示例:
df.write.saveAsTable("表名",mode='overwrite')
注意:
1、表不存在则创建表,表存在全覆盖写入;
2、表存在,数据字段有变化,先删除后重新创建表;
3、当正在存表时报错或者终止程序会导致表丢失;
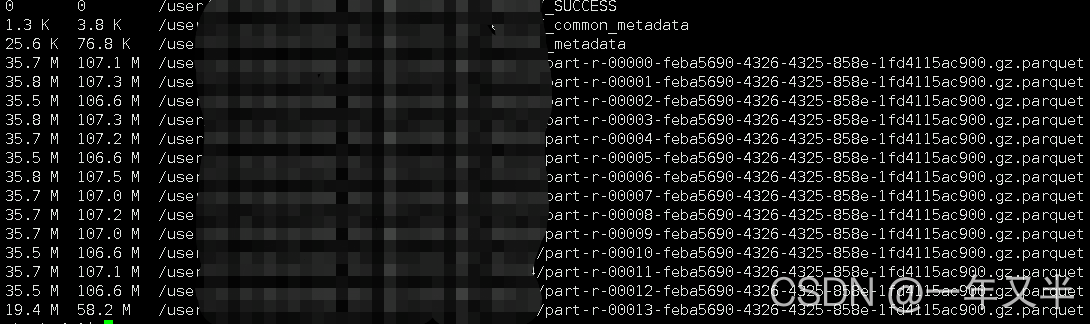
4、数据默认采用parquet压缩,文件名称 part-00000-5efbfc08-66fe-4fd1-bebb-944b34689e70.gz.parquet
数据文件在hdfs上显示:
2> insertInto写入
insertInto(self, tableName, overwrite=False):
示例:
# append 写入
df.repartition(1).write.partitionBy('dt').insertInto("表名")
# overwrite 写入
df.repartition(1).write.partitionBy('dt').insertInto("表名",overwrite=True)
# 动态分区使用该方法
注意:
1、df.write.mode("overwrite").partitionBy("dt").insertInto("表名") 不会覆盖数据
2、需要表必须存在且当前DF的schema与目标表的schema必须一致
3、插入的文件不会压缩;文件以part-00....结尾。文件较大
数据文件在hdfs上显示:

2.1> 问题说明
两种方式存储数据量一样的数据,磁盘文件占比却相差很大,.gz.parquet 文件 相比 part-00000文件要小很多。想用spark操作分区表,又想让文件压缩,百度了一些方式,都没有解决。
从stackoverflow中有一个类似的问题 Spark compression when writing to external Hive table 。用里面的方法并没有解决。
最终从hive表数据文件压缩角度思考,问题得到解决。
hive 建表指定压缩格式
下面是hive parquet的几种压缩方式
-- 使用snappy
CREATE TABLE if not exists ods.table_test(
id string,
open_time string
)
COMMENT '测试'
PARTITIONED BY (`dt` string COMMENT '按天分区')
row format delimited fields terminated by '\001'
STORED AS PARQUET
TBLPROPERTIES ('parquet.compression'='SNAPPY');
-- 使用gzip
CREATE TABLE if not exists ods.table_test(
id string,
open_time string
)
COMMENT '测试'
PARTITIONED BY (`dt` string COMMENT '按天分区')
row format delimited fields terminated by '\001'
STORED AS PARQUET
TBLPROPERTIES ('parquet.compression'='GZIP');
-- 使用uncompressed
CREATE TABLE if not exists ods.table_test(
id string,
open_time string
)
COMMENT '测试'
PARTITIONED BY (`dt` string COMMENT '按天分区')
row format delimited fields terminated by '\001'
STORED AS PARQUET
TBLPROPERTIES ('parquet.compression'='UNCOMPRESSED');
-- 使用默认
CREATE TABLE if not exists ods.table_test(
id string,
open_time string
)
COMMENT '测试'
PARTITIONED BY (`dt` string COMMENT '按天分区')
row format delimited fields terminated by '\001'
STORED AS PARQUET;
-- 设置参数 set parquet.compression=SNAPPY;
2.2> 解决办法
建表时指定TBLPROPERTIES,采用gzip 压缩
示例:
drop table if exists ods.table_test
CREATE TABLE if not exists ods.table_test(
id string,
open_time string
)
COMMENT '测试'
PARTITIONED BY (`dt` string COMMENT '按天分区')
row format delimited fields terminated by '\001'
STORED AS PARQUET
TBLPROPERTIES ('parquet.compression'='GZIP');
执行效果
数据文件在hdfs上显示:

可以看到文件大小占比已经和 *.gz.parquet 文件格式一样了
3>saveAsTextFile写入直接操作文件saveAsTextFile(self, path, compressionCodecClass=None)
该方式通过rdd 以文件形式直接将数据存储在hdfs上。
示例:
rdd.saveAsTextFile('hdfs://表全路径')
文件操作更多方式见官方文档
到此这篇关于pyspark操作hive分区表及.gz.parquet和part-00000文件压缩问题的文章就介绍到这了,更多相关pyspark hive分区表parquet内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Linux下远程连接Jupyter+pyspark部署教程
博主最近试在服务器上进行spark编程,因此,在开始编程作业之前,要先搭建一个便利的编程环境,这样才能做到舒心地开发.本文主要有以下内容: 1.python多版本管理利器-pythonbrew 2.Jupyter notebooks 安装与使用以及远程连接方法 3.Jupyter连接pyspark,实现web端sprak开发 一.python多版本管理利器-pythonbrew 在利用python进行编程开发的时候,很多时候我们需要多个Python版本进行测试,博主之前一直在Python2.x和
-
pyspark给dataframe增加新的一列的实现示例
熟悉pandas的pythoner 应该知道给dataframe增加一列很容易,直接以字典形式指定就好了,pyspark中就不同了,摸索了一下,可以使用如下方式增加 from pyspark import SparkContext from pyspark import SparkConf from pypsark.sql import SparkSession from pyspark.sql import functions spark = SparkSession.builder.conf
-
在python中使用pyspark读写Hive数据操作
1.读Hive表数据 pyspark读取hive数据非常简单,因为它有专门的接口来读取,完全不需要像hbase那样,需要做很多配置,pyspark提供的操作hive的接口,使得程序可以直接使用SQL语句从hive里面查询需要的数据,代码如下: from pyspark.sql import HiveContext,SparkSession _SPARK_HOST = "spark://spark-master:7077" _APP_NAME = "test" spa
-

pyspark对Mysql数据库进行读写的实现
pyspark是Spark对Python的api接口,可以在Python环境中通过调用pyspark模块来操作spark,完成大数据框架下的数据分析与挖掘.其中,数据的读写是基础操作,pyspark的子模块pyspark.sql 可以完成大部分类型的数据读写.文本介绍在pyspark中读写Mysql数据库. 1 软件版本 在Python中使用Spark,需要安装配置Spark,这里跳过配置的过程,给出运行环境和相关程序版本信息. win10 64bit java 13.0.1 spark 3.0
-
Pyspark读取parquet数据过程解析
parquet数据:列式存储结构,由Twitter和Cloudera合作开发,相比于行式存储,其特点是: 可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量:压缩编码可以降低磁盘存储空间,使用更高效的压缩编码节约存储空间:只读取需要的列,支持向量运算,能够获取更好的扫描性能. 那么我们怎么在pyspark中读取和使用parquet数据呢?我以local模式,linux下的pycharm执行作说明. 首先,导入库文件和配置环境: import os from pyspark import
-
PyCharm+PySpark远程调试的环境配置的方法
前言:前两天准备用 Python 在 Spark 上处理量几十G的数据,熟料在利用PyCharm进行PySpark远程调试时掉入深坑,特写此博文以帮助同样深处坑中的bigdata&machine learning fans早日出坑. Version :Spark 1.5.0.Python 2.7.14 1. 远程Spark集群环境 首先Spark集群要配置好且能正常启动,版本号可以在Spark对应版本的官方网站查到,注意:Spark 1.5.0作为一个比较古老的版本,不支持Python 3.6+
-
pyspark操作hive分区表及.gz.parquet和part-00000文件压缩问题
目录 pyspark 操作hive表 pyspark 操作hive表 pyspark 操作hive表,hive分区表动态写入:最近发现spark动态写入hive分区,和saveAsTable存表方式相比,文件压缩比大约 4:1.针对该问题整理了 spark 操作hive表的几种方式. 1> saveAsTable写入 saveAsTable(self, name, format=None, mode=None, partitionBy=None, **options) 示例: df.write.
-
pyspark操作MongoDB的方法步骤
如何导入数据 数据可能有各种格式,虽然常见的是HDFS,但是因为在Python爬虫中数据库用的比较多的是MongoDB,所以这里会重点说说如何用spark导入MongoDB中的数据. 当然,首先你需要在自己电脑上安装spark环境,简单说下,在这里下载spark,同时需要配置好JAVA,Scala环境. 这里建议使用Jupyter notebook,会比较方便,在环境变量中这样设置 PYSPARK_DRIVER_PYTHON=jupyter PYSPARK_DRIVER_PYTHON_OPTS=
-
python 操作hive pyhs2方式
使用kerberos时 import pyhs2 class HiveClient: # 初始化 def __init__(self, db_host, user, password, database, port=10000, authMechanism="PLAIN", configuration=None): self.conn = pyhs2.connect(host=db_host, port=port, authMechanism=authMechanism, user=u
-
JS操作XML实例总结(加载与解析XML文件、字符串)
本文实例讲述了JS操作XML的方法.分享给大家供大家参考,具体如下: 我的xml文件Login.xml如下. <?xml version="1.0" encoding="utf-8" ?> <Login> <Character> <C Text="热血" Value="0"></C> <C Text="弱气" Value="1&qu
-
PHP 实现文件压缩解压操作的方法
在php中,有时我们需要使用到压缩文件操作,压缩文件可以节省磁盘空间:且压缩文件更小,便于网络传输,效率高,下面我们就来了解php的压缩解压相关操作 在PHP中有一个ZipArchive类,专门用于文件的压缩解压相关操作 在ZipArchive类中主要使用到了如下方法: 1:open(打开一个压缩包文件) $zip = new \ZipArchive; $zip->open('test_new.zip', \ZipArchive::CREATE) 第一个参数:要打开的压缩包文件 第二个参数: Z
-
java文件操作练习代码 读取某个盘符下的文件
复制代码 代码如下: import java.io.BufferedReader;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileReader;import java.io.IOException;import java.io.InputStream;import java.io.Reader; public class IORea
-
数据库之Hive概论和架构和基本操作
目录 Hive概论 Hive架构 Hive安全和启动 Hive数据库操作 Hive内部表操作-数据添加 Hive内部表特点 Hive外部表操作 Hive表操作-分区表 Hive概论 Hive是一个构建在Hadoop上的数据仓库框架,最初,Hive是由Facebook开发,后台移交由Apache软件基金会开发,并做为一个Apache开源项目. Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能. Hive它能够存储很大的数据集,可以直接访
-
使用mysqldump对MySQL的数据进行备份的操作教程
MySQL 自身的 mysqldump 工具支持单线程工作, 依次一个个导出多个表,没有一个并行的机 ,这就使得它无法迅速的备份数据. mydumper 作为一个实用工具,能够良好支持多线程工作, 可以并行的多线程的从表中读入数据并同时写到不同的文件里 ,这使得它在处理速度方面快于传统的 mysqldump .其特征之一是在处理过程中需要对列表加以锁定,因此如果我们需要在工作时段执行备份工作,那么会引起 DML 阻塞.但一般现在的 MySQL 都有主从,备份也大部分在从上进行,所以锁的问题可以不
-
java使用POI操作excel文件
一.POI的定义 JAVA中操作Excel的有两种比较主流的工具包: JXL 和 POI .jxl 只能操作Excel 95, 97, 2000也即以.xls为后缀的excel.而poi可以操作Excel 95及以后的版本,即可操作后缀为 .xls 和 .xlsx两种格式的excel. POI全称 Poor Obfuscation Implementation,直译为"可怜的模糊实现",利用POI接口可以通过JAVA操作Microsoft office 套件工具的读写功能.官网:htt