Python 给我一个链接西瓜视频随便下载爬虫

1.实现原理
- 首先,我们需要来到西瓜视频的官网,链接为:西瓜视频,随便点击其中一个视频进入,点击电脑键盘的F12来到开发者模式,按ctrl+F进行搜索,输入video,如下:
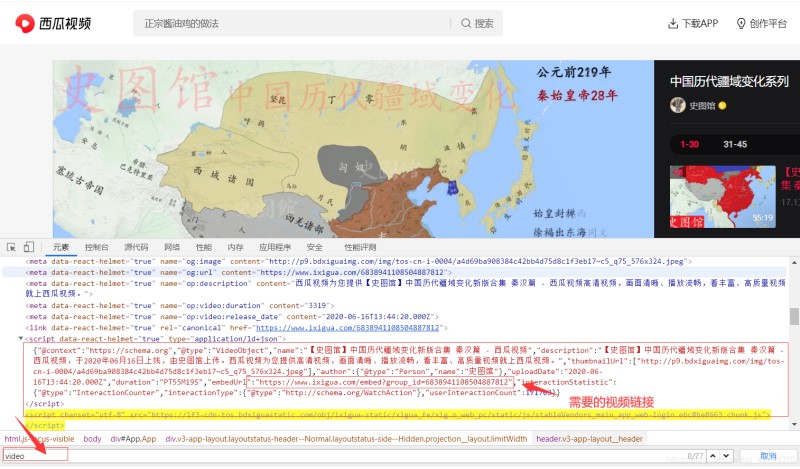
- 我们可以发现,这里有一个视频链接,我们点击这个链接进入,依旧按电脑F12键来到开发者模式,继续搜索video,可以发现,这里直接有视频的下载链接,如下:
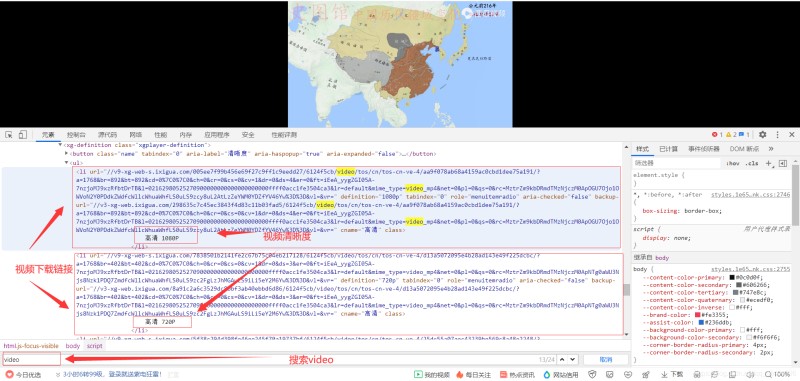
- 我们是不是只要运用代码就可以找到视频的下载链接呢?不过,由于上述图片这些视频下载链接是动态加载的,这里需要用到selenium模块哈!不懂这个模块的 读者可以看看小编之前写的博客哈!这里小编给出一篇博客,博客链接为:selenium模块太强大了,网易云音乐都可下载

2.程序代码
程序代码如下:
import re
from selenium import webdriver
# url="https://www.ixigua.com/6982149651281478152?logTag=cc6bf98fd0f8fe35fe0e"
url=input("输入视频链接:")
group_id=re.findall('https://www.ixigua.com/(.*)\?logTag=.*',url)
url='https://www.ixigua.com/embed?group_id='+group_id[0]
# 进入浏览器设置
options = webdriver.ChromeOptions()
# 设置中文
options.add_argument('lang=zh_CN.UTF-8')
# 更换头部
options.add_argument('user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"')
driver=webdriver.Chrome(options=options)
driver.get(url=url)
driver.implicitly_wait(5)
infos=driver.find_elements_by_xpath("//xg-definition/ul/li")
for info in infos[:-1]:
print(info.get_attribute("definition"))
print('http:'+info.get_attribute("url"))
- 别看总共代码就这么点,如果不知道其中的原理,或许这么点代码都敲不出来呢?
- 由于视频下载直接用代码实现可能需要较长的时间,使用这里直接把视频的下载链接给出来哈!之后读者就可以拿视频下载链接去浏览器上下载即可。

3.运行结果


Python爬虫下载西瓜视频
到此这篇关于Python 给我一个链接 西瓜视频随便下载 爬虫的文章就介绍到这了,更多相关Python爬虫视频内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

详解Java中一维、二维数组在内存中的结构
前言 我们知道在Java中数组属于引用数据类型,它整个数组的数组元素既可以是基本数据类型的(如 byte \ int \ short \ long \ float \ double \ char \ boolean 这些),也可以是引用数据类型的.当它的数组元素是基本数据类型时,这个数组就是一个一维数组:当它的数组元素是引用数据类型时,它就是一个多维数组.比如,在一个数组中它的某个元素值其实是一个一维数组,而其他不同的元素也各自包含了一个一维数组,我们就把这个包含很多个一维数组的数组叫做二维数组
-
Python 利用scrapy爬虫通过短短50行代码下载整站短视频
近日,有朋友向我求助一件小事儿,他在一个短视频app上看到一个好玩儿的段子,想下载下来,可死活找不到下载的方法.这忙我得帮,少不得就抓包分析了一下这个app,找到了视频的下载链接,帮他解决了这个小问题. 因为这个事儿,勾起了我另一个念头,这不最近一直想把python爬虫方面的知识梳理梳理吗,干脆借机行事,正凑着短视频火热的势头,做一个短视频的爬虫好了,中间用到什么知识就理一理. 我喜欢把事情说得很直白,如果恰好有初入门的朋友想了解爬虫的技术,可以将就看看,或许对你的认识会有提升.如果有高手路过,
-
Python爬虫获取图片并下载保存至本地的实例
1.抓取煎蛋网上的图片. 2.代码如下: import urllib.request import os #to open the url def url_open(url): req=urllib.request.Request(url) req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0') response=urllib.request.u
-
Python实现爬虫从网络上下载文档的实例代码
最近在学习Python,自然接触到了爬虫,写了一个小型爬虫软件,从初始Url解析网页,使用正则获取待爬取链接,使用beautifulsoup解析获取文本,使用自己写的输出器可以将文本输出保存,具体代码如下: Spider_main.py # coding:utf8 from baike_spider import url_manager, html_downloader, html_parser, html_outputer class SpiderMain(object): def __ini
-
Python3.x爬虫下载网页图片的实例讲解
一.选取网址进行爬虫 本次我们选取pixabay图片网站 url=https://pixabay.com/ 二.选择图片右键选择查看元素来寻找图片链接的规则 通过查看多个图片路径我们发现取src路径都含有 https://cdn.pixabay.com/photo/ 公共部分且图片格式都为.jpg 因此正则表达式为 re.compile(r'^https://cdn.pixabay.com/photo/.*?jpg$') 通过以上的分析我们可以开始写程序了 #-*- coding:utf-8 -
-
Python爬虫 批量爬取下载抖音视频代码实例
这篇文章主要为大家详细介绍了python批量爬取下载抖音视频,具有一定的参考价值,感兴趣的小伙伴们可以参考一下 项目源码展示: ''' 在学习过程中有什么不懂得可以加我的 python学习交流扣扣qun,934109170 群里有不错的学习教程.开发工具与电子书籍. 与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容. ''' # -*- coding:utf-8 -*- from contextlib import closing import request
-
Python 给我一个链接西瓜视频随便下载爬虫
1.实现原理 首先,我们需要来到西瓜视频的官网,链接为:西瓜视频,随便点击其中一个视频进入,点击电脑键盘的F12来到开发者模式,按ctrl+F进行搜索,输入video,如下: 我们可以发现,这里有一个视频链接,我们点击这个链接进入,依旧按电脑F12键来到开发者模式,继续搜索video,可以发现,这里直接有视频的下载链接,如下: 我们是不是只要运用代码就可以找到视频的下载链接呢?不过,由于上述图片这些视频下载链接是动态加载的,这里需要用到selenium模块哈!不懂这个模块的 读者可以看看小编之前
-
Python 超简洁且详细爬取西瓜视频案例
一.写在前面 真的,为什么别人发游戏这么多人看,我发了两次了加起来才一百个. 算了算了,不整游戏了,反正你们也不爱看~ 今天来试试把头条上扭腰上热门的那些妹子爬一爬,不知道我顶不顶得住~ 二.准备工作 1.使用的环境 python 3.8pycharm 2021.2 专业版 2.要用的第三方模块 seleniumrequestsparsel 三.大致流程 鉴于你们不喜欢我啰嗦,但是流程呢,我还是要给你们写出来,所以我就单独把它列出来了. 1.网站分析(明确需求) 在视频网页源代码当中找到 emb
-
Python 超简洁且详细爬取西瓜视频案例
一.写在前面 真的,为什么别人发游戏这么多人看,我发了两次了加起来才一百个. 算了算了,不整游戏了,反正你们也不爱看~ 今天来试试把头条上扭腰上热门的那些妹子爬一爬,不知道我顶不顶得住~ 二.准备工作 1.使用的环境 python 3.8 pycharm 2021.2 专业版 2.要用的第三方模块 selenium requests parsel 三.大致流程 鉴于你们不喜欢我啰嗦,但是流程呢,我还是要给你们写出来,所以我就单独把它列出来了. 1.网站分析(明确需求) 在视频网页源代码当中找到
-
python爬取bilibili网页排名,视频,播放量,点赞量,链接等内容并存储csv文件中
首先要了解html标签,标签有主有次,大致了解以一下,主标签是根标签,也是所有要爬取的标签的结合体 先了解一下待会要使用代码属性: #获取属性 a.attrs 获取a所有的属性和属性值,返回一个字典 a.attrs['href'] 获取href属性 a['href'] 也可简写为这种形式 #获取内容 a.string 获取a标签的直系文本 注意:如果标签还有标签,那么string获取到的结果为None,而其它两个,可以获取文本内容 a.text 这是属性,获取a子类的所
-
十行Python代码制作一个视频倒放神器
目录 导语 正文 源码如下 效果展示 总结 补充 导语 大家好,我是栗子同学! 今天给大家分享一个好玩的东西 让时光倒流——当当当,其实就是让视频倒放而已 正常的视频如下 倒放视频如下 效果很赞吧,等你学会了这个,你才会发现,抖音上那些杯子里的水倒流,倒着跑步等看似很炫酷很神秘的视频,其实就是一键倒放而已! 那么,今天小编就来探索Python代码如何实现这个倒放的功能叭~ 正文 这些搞笑的gif跟小视频都是将正常的流畅通过倒放产生的效果啦 其实制作起来却非常简单,原理就是将gif图片拆分出来每一
-
利用Python+Excel制作一个视频下载器
说起Excel,那绝对是数据处理领域王者般的存在. 而作为网红语言Python,在数据领域也是被广泛使用. 其中Python的第三方库-xlwings,一个Python和Excel的交互工具,可以轻松地通过VBA来调用Python脚本,实现复杂的数据分析. 今天,小F就给大家介绍一个Python+Excel的项目[视频下载器]. 主要使用到下面这些Python库. import os import sys import ssl import ffmpeg import xlwings as xw
-
Python实现Youku视频批量下载功能
前段时间由于收集视频数据的需要,自己捣鼓了一个YouKu视频批量下载的程序.东西虽然简单,但还挺实用的,拿出来分享给大家. 版本:Python2.7+BeautifulSoup3.2.1 import urllib,urllib2,sys,os from BeautifulSoup import BeautifulSoup import itertools,re url_i =1 pic_num = 1 #自己定义的引号格式转换函数 def _en_to_cn(str): obj = itert
-
python3.5+tesseract+adb实现西瓜视频或头脑王者辅助答题
最近的答题赢钱很火爆,我也参与了几次,有些题目确实很难答,但是10秒钟的时间根本不够百度的,所以写了个辅助挂,这样可以出现题目时自动百度,这个时间也就花掉2秒钟,剩下的7.8秒钟可以进行分析和作答,提升了赢钱概率. 源码可以见我的github:点击链接 原理分析下:使用adb命令,抓取手机视频播放的界面,然后通过python的截取和ocr,获得到题目和答案, 然后百度得到结果.这个环境怎么搭建,有需要的童鞋可以联系我,因为使用本地的ocr所以解析不花钱,也没有使用的限制. github上的代码中
-
python爬虫爬取快手视频多线程下载功能
环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍. 配置允许https 配置允许远程连接 也就是打开http代理 电脑ip: 192.168.1.110 然后 确保手机和电脑是在一个局域网下,可以通信.由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的. 打开手机浏览器,输入192.168.1.110:8888 也就是设置的代理地址,安装证书之后才能
-
Python爬虫进阶之爬取某视频并下载的实现
这几天在家闲得无聊,意外的挖掘到了一个资源网站(你懂得),但是网速慢广告多下载不了种种原因让我突然萌生了爬虫的想法. 下面说说流程: 一.网站分析 首先进入网站,F12检查,本来以为这种低端网站很好爬取,是我太低估了web主.可以看到我刷新网页之后,出现了很多js文件,并且响应获取的代码与源代码不一样,这就不难猜到这个网站是动态加载页面. 目前我知道的动态网页爬取的方法只有这两种:1.从网页响应中找到JS脚本返回的JSON数据:2.使用Selenium对网页进行模拟访问.源代码问题好解决,重要的