R语言-实现按日期分组求皮尔森相关系数矩阵
R语言按日期分组求相关系数
前几天得到了3700+支股票一周内的波动率,想要计算每周各个股票之间的相关系数并将其可视化。最终结果保存在制定文件夹中。
部分数据如下:

先读取数据
data<-read.csv("D:/data/stock_day_close_price_week_series.csv",
header = TRUE,blank.lines.skip = TRUE)
利用mice包处理缺失值:
library(lattice) library(MASS) library(mice) aggr(data,prop=FALSE,numbers=TRUE,sortVars=TRUE)#查看缺失值 imp<-mice(data[,3:7],1)#用链式方程法填补缺失值 stripplot(imp,pch=20,cex=1.2)#查看填补结果 data1<-complete(imp,action = 1)
缺失值比例图如下:
2
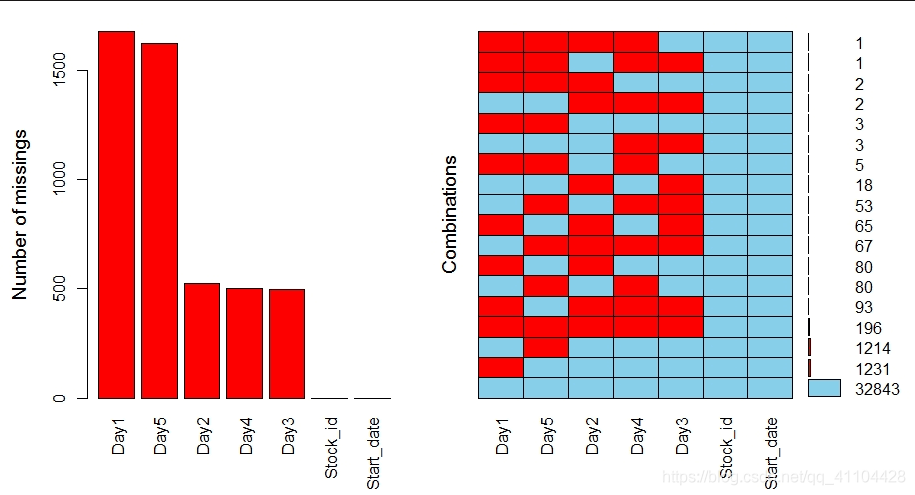
分组计算并分组保存:
d<-unlist(levels(factor(dat[,2])))#得到各个开始日期
mydata<-list()
mydatap<-list()
xg<-list()
for (i in 1:11 ) {#修改组数有多少个开始日期
mydata[[i]] <- filter(dat,Start_date==d[[i]])#按照开始日期对数据分组
mydatap[[i]] <- mydata[[i]][1:nrow(mydata[[i]]),3:7]
xg[[i]]<- cor(t(mydatap[[i]]))#计算相关系数矩阵
rownames(xg[[i]])=mydata[[i]][,1]
colnames(xg[[i]])=mydata[[i]][,1]
dat<-filter(dat,Start_date!=d[[i]])
write.csv (xg[[i]],file=paste0('D:/data/','relation_graph_',d[[i]],'.csv'))#将相关系数矩阵存到文件中
}
部分计算结果:

总代码如下:
data<-read.csv("D:/data/stock_day_close_price_week_series.csv",
header = TRUE,blank.lines.skip = TRUE)
library(colorspace)
library(grid)
library(lattice)
library(mice)
library(data.table)
library(VIM)
library(dplyr)
library(corrplot)
matrixplot(data)
aggr(data,prop=FALSE,numbers=TRUE,sortVars=TRUE)#查看缺失值
imp<-mice(data[,3:7],1)#用链式方程法填补缺失值
stripplot(imp,pch=20,cex=1.2)
data1<-complete(imp,action = 1)
dat<-cbind(data[,1:2],data1)
d<-unlist(levels(factor(dat[,2])))#得到各个开始日期
mydata<-list()
mydatap<-list()
xg<-list()
for (i in 1:11 ) {#修改组数有多少个开始日期
mydata[[i]] <- filter(dat,Start_date==d[[i]])#按照开始日期对数据分组
mydatap[[i]] <- mydata[[i]][1:nrow(mydata[[i]]),3:7]
xg[[i]]<- cor(t(mydatap[[i]]))#计算相关系数矩阵
rownames(xg[[i]])=mydata[[i]][,1]
colnames(xg[[i]])=mydata[[i]][,1]
dat<-filter(dat,Start_date!=d[[i]])
write.csv (xg[[i]],file=paste0('D:/data/','relation_graph_',d[[i]],'.csv'))#将相关系数矩阵存到文件中
}
补充:Pearson相关系数R代码实现
Pearson相关系数(Pearson Correlation Coefficient)
Pearson's r,称为皮尔逊相关系数(Pearson correlation coefficient),用来反映两个随机变量之间的线性相关程度。
要理解皮尔逊相关系数,首先要理解协方差(Covariance)。协方差可以反映两个随机变量之间的关系,如果一个变量跟随着另一个变量一起变大或者变小,那么这两个变量的协方差就是正值,就表示这两个变量之间呈正相关关系,反之相反。
如果协方差的值是个很大的正数,我们可以得到两个可能的结论:
(1) 两个变量之间呈很强的正相关性
(2) 两个变量之间并没有很强的正相关性,协方差的值很大是因为X或Y的标准差很大
那么到底哪个结论正确呢?只要把X和Y变量的标准差,从协方差中剔除不就知道了吗?
协方差能告诉我们两个随机变量之间的关系,但是却没法衡量变量之间相关性的强弱。
因此,为了更好地度量两个随机变量之间的相关程度,引入了皮尔逊相关系数。
可以看到,皮尔逊相关系数就是用协方差除以两个变量的标准差得到的。
代码如下:
> setwd("F:\\CSDN\\blog")
> states <- state.x77[,1:5]
> cov(states) #计算方差和协方差
Population Income Illiteracy Life Exp Murder
Population 19931683.7588 571229.7796 292.8679592 -407.8424612 5663.523714
Income 571229.7796 377573.3061 -163.7020408 280.6631837 -521.894286
Illiteracy 292.8680 -163.7020 0.3715306 -0.4815122 1.581776
Life Exp -407.8425 280.6632 -0.4815122 1.8020204 -3.869480
Murder 5663.5237 -521.8943 1.5817755 -3.8694804 13.627465
> cor(states) #计算Pearson积差相关系数
Population Income Illiteracy Life Exp Murder
Population 1.00000000 0.2082276 0.1076224 -0.06805195 0.3436428
Income 0.20822756 1.0000000 -0.4370752 0.34025534 -0.2300776
Illiteracy 0.10762237 -0.4370752 1.0000000 -0.58847793 0.7029752
Life Exp -0.06805195 0.3402553 -0.5884779 1.00000000 -0.7808458
Murder 0.34364275 -0.2300776 0.7029752 -0.78084575 1.0000000
> cor(states,method = "spearman") #计算spearman等级相关系数
Population Income Illiteracy Life Exp Murder
Population 1.0000000 0.1246098 0.3130496 -0.1040171 0.3457401
Income 0.1246098 1.0000000 -0.3145948 0.3241050 -0.2174623
Illiteracy 0.3130496 -0.3145948 1.0000000 -0.5553735 0.6723592
Life Exp -0.1040171 0.3241050 -0.5553735 1.0000000 -0.7802406
Murder 0.3457401 -0.2174623 0.6723592 -0.7802406 1.0000000
> cor.test(states[,3],states[,5]) #进行相关性系数
Pearson's product-moment correlation
data: states[, 3] and states[, 5]
t = 6.8479, df = 48, p-value = 1.258e-08
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.5279280 0.8207295
sample estimates:
cor
0.7029752
> #cor.test()只能检验一种相关关系,psych包提供了更多的选择
> #install.packages("psych")
> library(psych)
> corr.test(states,use = "complete")
Call:corr.test(x = states, use = "complete")
Correlation matrix
Population Income Illiteracy Life Exp Murder
Population 1.00 0.21 0.11 -0.07 0.34
Income 0.21 1.00 -0.44 0.34 -0.23
Illiteracy 0.11 -0.44 1.00 -0.59 0.70
Life Exp -0.07 0.34 -0.59 1.00 -0.78
Murder 0.34 -0.23 0.70 -0.78 1.00
Sample Size
[1] 50
Probability values (Entries above the diagonal are adjusted for multiple tests.)
Population Income Illiteracy Life Exp Murder
Population 0.00 0.44 0.91 0.91 0.09
Income 0.15 0.00 0.01 0.09 0.43
Illiteracy 0.46 0.00 0.00 0.00 0.00
Life Exp 0.64 0.02 0.00 0.00 0.00
Murder 0.01 0.11 0.00 0.00 0.00
To see confidence intervals of the correlations, print with the short=FALSE option
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

R语言实现导出矩阵
程序实在是调不出来了,我决定破釜沉舟,直接把所有表格都打印出来,看看数据到底哪儿有问题. 然后就开始了闹心的矩阵导出... 首先,百度了一下,数据导出的代码为: write.table (x, file ="", sep ="", row.names =TRUE, col.names =TRUE, quote =TRUE) 其中: x:需要导出的数据 file:导出的文件路径 sep:分隔符,默认为空格(" "),也就是以空格为分割列 row.n
-
R语言-解决处理矩阵遇到内存不足的问题
如下: Error : cannot allocate vector of size X Gb 类似于这种问题的可能处理办法: 1. 可以用matrix尽量不要用data frame; 2. 可以用integer matrix尽量不要用 double matrix; 3. 对于大量运算后最好加上一个gc(), 强制R语言回收内存: 4. 对于大矩阵而言用bigmemory包,可以将大矩阵放到临时文件中,不占用内存. 补充:R语言之内存管理 在处理大型数据过程中,R语言的内存管理就显得十分重要,以
-
R语言 实现矩阵相乘100次
[D1 D2]2*1 [T1 T2]1*2 要求D1和D2随机的变动, 矩阵相乘100次 rm(list=ls()) gc() options(scipen = 2000) ##################写成函数###########3 #################定义TT矩阵(1*2) TT <- matrix(c(1,3),1,2) DD<- matrix(c(1,2),2,1) result1 <- DD %*% TT m1=result1 ##############
-
R语言-如何将循环所得的矩阵组成一个矩阵
在矩阵合并中,常见的方法有cbind()和rbind() 其中,前者为按列合并,后者为按行合并. 但是这两个函数有个缺点,就是不能应用到循环之中.例如: A<-matrix(1:12,nrow = 4,byrow = T) B<-matrix(1:8,nrow = 4,byrow = T) C<-cbind(A,B) 得到的矩阵C为[按列合并两者行数必须相同]: 但是如果将这个方法应用在循环中,就无法取得预期效果: A<-matrix(1:12,nrow = 4,byrow = T
-
R语言中常见的几种创建矩阵形式总结
矩阵概述 R语言的实质实质上是与matlab差不多的,都是以矩阵为基础的 在R语言中,矩阵(matrix)是将数据按行和列组织数据的一种数据对象,相当于二维数组,可以用于描述二维的数据.与向量相似,矩阵的每个元素都拥有相同的数据类型.通常用列来表示来自不同变量的数据,用行来表示相同的数据. R中创建矩阵的语法格式 在R语言中可以使用matrix()函数来创建矩阵,其语法格式如下: matrix(data=NA, nrow = 1, ncol = 1, byrow = FALSE, dimname
-
R语言矩阵知识点总结及实例分析
矩阵是其中元素以二维矩形布局布置的R对象. 它们包含相同原子类型的元素. 虽然我们可以创建一个只包含字符或只包含逻辑值的矩阵,但它们没有太多用处. 我们使用包含数字元素的矩阵用于数学计算. 使用matrix()函数创建一个矩阵. 语法 在R语言中创建矩阵的基本语法是 matrix(data, nrow, ncol, byrow, dimnames) 以下是所使用的参数的说明 数据是成为矩阵的数据元素的输入向量. nrow是要创建的行数. ncol是要创建的列数. byrow是一个逻辑线索. 如果
-
R语言中矩阵matrix和数据框data.frame的使用详解
本文主要介绍了R语言中矩阵matrix和数据框data.frame的一些使用,分享给大家,具体如下: "一,矩阵matrix" "创建向量" x_1=c(1,2,3) x_1=c(1:3) x_2=1:3 typeof(x_1)==typeof(x_2)#查看目标类型 x_3=seq(1,6,length=3)#将1--6分为3个数 a<-rep(1:3,each=3) #1到3依次重复 c<-rep(1:3,times=3) #1到3重复3次 d<
-
R语言中igraph包的用法(邻接矩阵)
先导入igraph包: library(igraph) graph包最简单的用法就是graph方法,两句代码就完成绘制如下所示,1的loop表示为(1,1),1和2之间有3条edge,表示为(1,2,1,2,1,2) g <- graph(c(1,1,1,2,1,2,1,2,1,5,2,3,2,4,2,5,3,3,3,4,3,4,3,4,4,5),directed = FALSE) plot(g) 如果用顶点的邻接矩阵表示,仍以上图为例: 则对1,1有loop,与2有条edge,与5有一条edg
-
R语言-实现按日期分组求皮尔森相关系数矩阵
R语言按日期分组求相关系数 前几天得到了3700+支股票一周内的波动率,想要计算每周各个股票之间的相关系数并将其可视化.最终结果保存在制定文件夹中. 部分数据如下: 先读取数据 data<-read.csv("D:/data/stock_day_close_price_week_series.csv", header = TRUE,blank.lines.skip = TRUE) 利用mice包处理缺失值: library(lattice) library(MASS) libra
-
R语言 实现data.frame 分组计数、求和等
df为1个data.frame对象,有stratum和psu两列,这里统计stratum列计数 方法1: cnt = table(df$stratum) 方法2: cnt = tapply(df$psu, INDEX=df$stratum, FUN=length) 在方法2的基础上,只要改变FUN函数就可以实现分组求和.求均值等功能,如下 分组求均值: tapply(df$psu, INDEX=df$stratum, FUN=mean) #(等价于python中的df.groupby('stra
-
R语言与格式,日期格式,格式转化的操作
R语言的基础包中提供了两种类型的时间数据,一类是Date日期数据,它不包括时间和时区信息,另一类是POSIXct/POSIXlt类型数据,其中包括了日期.时间和时区信息. 基本总结如下: 日期data,存储的是天: 时间POSIXct 存储的是秒,POSIXlt 打散,年月日不同: 日期-时间=不可运算. 一般来讲,R语言中建立时序数据是通过字符型转化而来,但由于时序数据形式多样,而且R中存贮格式也是五花八门,例如Date/ts/xts/zoo/tis/fts等等.lubridate包(后续有介
-
R语言绘制直方图实例讲解
直方图表示被存储到范围中的变量的值的频率. 直方图类似于条形图,但不同之处在于将值分组为连续范围. 直方图中的每个柱表示该范围中存在的值的数量的高度. R语言使用hist()函数创建直方图. 此函数使用向量作为输入,并使用一些更多的参数来绘制直方图. 语法 使用R语言创建直方图的基本语法是 hist(v,main,xlab,xlim,ylim,breaks,col,border) 以下是所使用的参数的描述 v是包含直方图中使用的数值的向量. main表示图表的标题. col用于设置条的颜色. b
-
R语言实现线性回归的示例
在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析. 简单对来说就是用来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法. 回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析.如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析. 一元线性回归分析法的数学方程: y = ax + b
-
R语言绘制散点图实例分析
散点图显示在笛卡尔平面中绘制的许多点. 每个点表示两个变量的值. 在水平轴上选择一个变量,在垂直轴上选择另一个变量. 使用plot()函数创建简单散点图. 语法 在R语言中创建散点图的基本语法是 - plot(x, y, main, xlab, ylab, xlim, ylim, axes) 以下是所使用的参数的描述 - x是其值为水平坐标的数据集. y是其值是垂直坐标的数据集. main要是图形的图块. xlab是水平轴上的标签. ylab是垂直轴上的标签. xlim是用于绘图的x的值的极限.
-
R语言中因子相关知识点详解
因子是用于对数据进行分类并将其存储为级别的数据对象. 它们可以存储字符串和整数. 它们在具有有限数量的唯一值的列中很有用. 像"男性","女性"和True,False等.它们在统计建模的数据分析中很有用. 使用factor()函数通过将向量作为输入创建因子. 例 # Create a vector as input. data <- c("East","West","East","North
-
R语言线性回归知识点总结
回归分析是一种非常广泛使用的统计工具,用于建立两个变量之间的关系模型. 这些变量之一称为预测变量,其值通过实验收集. 另一个变量称为响应变量,其值从预测变量派生. 在线性回归中,这两个变量通过方程相关,其中这两个变量的指数(幂)为1.数学上,线性关系表示当绘制为曲线图时的直线. 任何变量的指数不等于1的非线性关系将创建一条曲线. 线性回归的一般数学方程为 y = ax + b 以下是所使用的参数的描述 y是响应变量. x是预测变量. a和b被称为系数常数. 建立回归的步骤 回归的简单例子是当人的
-
R语言关于二项分布知识点总结
二项分布模型处理在一系列实验中仅发现两个可能结果的事件的成功概率. 例如,掷硬币总是给出头或尾. 在二项分布期间估计在10次重复抛掷硬币中精确找到3个头的概率. R语言有四个内置函数来生成二项分布. 它们描述如下. dbinom(x, size, prob) pbinom(x, size, prob) qbinom(p, size, prob) rbinom(n, size, prob) 以下是所使用的参数的描述 x是数字的向量. p是概率向量. n是观察的数量. size是试验的数量. pro