R语言-t分布正态分布分位数图的实例
R是用于统计分析、绘图的语言和操作环境。
R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
它是一套由数据操作、计算和图形展示功能整合而成的套件。
包括:有效的数据存储和处理功能,一套完整的数组(特别是矩阵)计算操作符,拥有完整体系的数据分析工具,为数据分析和显示提供的强大图形功能,一套(源自S语言)完善、简单、有效的编程语言(包括条件、循环、自定义函数、输入输出功能)。
如何用RStudio做分位数图呢?
#分位数图,画t分布密度带p值
x=seq(-6,6,length=1000);
y=dt(x,19)
r1=-6;
r2=-2.89;
x2=c(r1,r1,x[x<r2&x>r1],r2,r2)
y2=c(0,dt(c(r1,x[x<r2&x>r1],r2),19),0)
plot(x,y,type="l",ylab="Density oft(19)",xlim=c(-5,5))
abline(h=0);polygon(x2,y2,col="red")
title("Tail Probability for t(19)")
text(c(-4.1,-2,5),c(0.02,-0.07),c("p-value=0.0047","t=-2.89"))
#对称#
x=seq(-6,6,length=1000);
y=dt(x,19)
r1=6;
r2=2.89;
x2=c(r1,r1,x[x<r2&x>r1],r2,r2)
y2=c(0,dt(c(r1,x[x<r2&x>r1],r2),19),0)
plot(x,y,type="l",ylab="Density oft(19)",xlim=c(-5,5))
abline(h=0);polygon(x2,y2,col="red")
title("Tail Probability for t(19)")
text(c(-4.1,-2,5),c(0.02,-0.07),c("p-value=0.0047","t=-2.89"))
#两边#
x=seq(-6,6,length=1000);
y=dt(x,19)
r1=-6
;r2=-2.89;
r3=2.89;
r4=6;
x2=c(r1,r1,x[x<r2&x>r1],r2,r2)
y2=c(0,dt(c(r1,x[x<r2&x>r1],r2),19),0)
x3=c(r3,r3,x[x<r4&x>r3],r4,r4)
y3=c(0,dt(c(r3,x[x<r4&x>r3],r4),19),0)
plot(x,y,type="l",ylab="Density oft(19)",xlim=c(-5,5))
abline(h=0);polygon(c(x2,x3),c(y2,y3),col="red");
title("Tail Probability for t(19)")
text(c(-4.1,-2.5),c(0.02,-0.007),c("p-value=0.0047",
"t=-2.89"))
text(c(2.5,4.1),c(0.02,-0.007),c("p-value=0.9953",
"t=2.89"))
#正态分布
x=seq(-5,5,0.01) #得到步长0.01的x范围
plot(x,dnorm(x),type="l",xlim=c(-5,5),ylim=c(0,2),
main="The Normal Density Distribution") #画
curve(dnorm(x,1,0.5),add=T,lty=2,col="blue")
lines(x,dnorm(x,0,0.25),col="green")
lines(x,dnorm(x,-2,0.5),col="orange")
legend("topright",legend=paste("m=",c(0,1,0,-2),"sd=", #m:均值 sd:方差
c(1,0.5,0.25,0.5)),lwd=3,
lty=c(1,2,1,1),col=c("black","blue","green","red"))
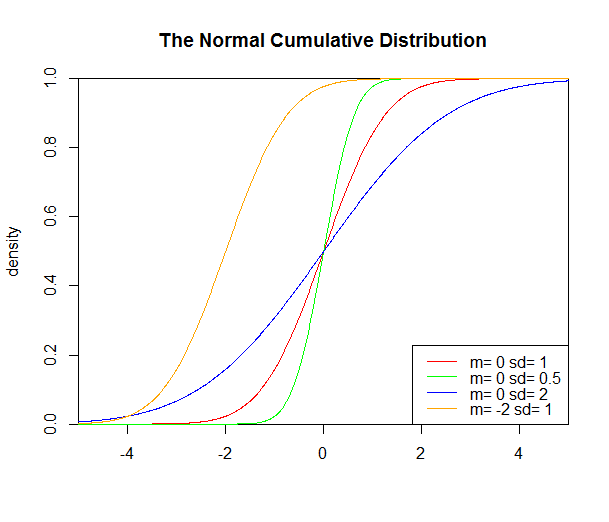
#分布函数
set.seed(1)
X<-seq(-5,5,length.out=100)
y<-pnorm(x,0,1)
plot(x,y,col="red",xlim=c(-5,5),ylim=c(0,1),type="l",
xaxs="i",yaxs="i",ylab='density',xlab='',
main="The Normal Cumulative Distribution")
lines(x,pnorm(x,0,0.5),col="green")
lines(x,pnorm(x,0,2),col="blue")
lines(x,pnorm(x,-2,1),col="orange")
legend("bottomright",legend=paste("m=",c(0,0,0,-2),"sd=",
c(1,0.5,2,1)),lwd=1,col=c("red","green","blue","orange"))
得到的图形结果如下:
补充:R语言绘制不同自由度下的卡方分布、t分布和F分布
看代码吧~
# === chi-squared distribution ===
chif <- function(x, df) {
dchisq(x, df = df)
}
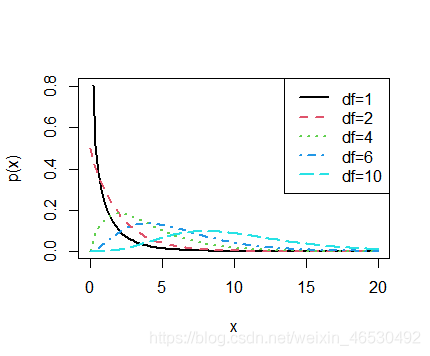
## === chi-squared distribution with df=1,2, 4, 6 and 10 ===
curve(chif(x, df = 1), 0, 20, ylab = "p(x)", lwd = 2)
curve(chif(x, df = 2), 0, 20, col = 2, add = T, lty = 2, lwd = 2)
curve(chif(x, df = 4), 0, 20, col = 3, add = T, lty = 3, lwd = 2)
curve(chif(x, df = 6), 0, 20, col = 4, add = T, lty = 4, lwd = 2)
curve(chif(x, df = 10), 0, 20, col = 5, add = T, lty = 5, lwd = 2)
legend("topright", legend = c("df=1", "df=2", "df=4", "df=6", "df=10"), col = 1:5, lty = 1:5, lwd = 2)
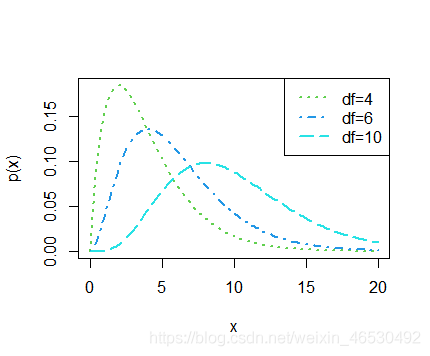
## === chi-squared distribution with df=4,6 and 10 ===
curve(dchisq(x, 4), 0, 20, col = 3, lty = 3, lwd = 2, ylab = "p(x)")
curve(dchisq(x, 6), 0, 20, col = 4, add = T, lty = 4, lwd = 2)
curve(dchisq(x, 10), 0, 20, col = 5, add = T, lty = 5, lwd = 2)
legend("topright", legend = c("df=4", "df=6", "df=10"), col = 3:5, lty = 3:5, lwd = 2)
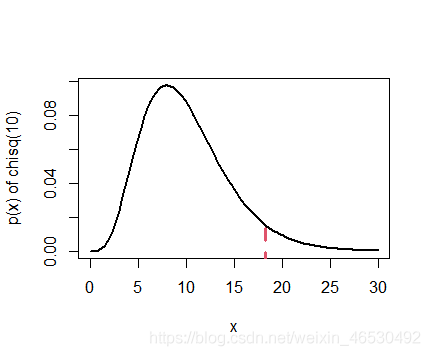
### quantiles
curve(dchisq(x, 10), 0, 30, col = 1, lty = 1, lwd = 2, ylab = "p(x) of chisq(10)")
lines(c(qchisq(0.95, 10), qchisq(0.95, 10)), c(-0.05, dchisq(qchisq(0.95, 10), 10)), col = 2, lwd = 3,
lty = 2)
qchisq(0.95,10)
## ==== t ===
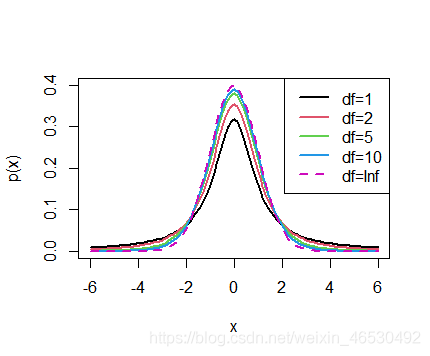
curve(dt(x, 1), -6, 6, ylab = "p(x)", lwd = 2, ylim = c(0, 0.4))
curve(dt(x, 2), -6, 6, col = 2, add = T, lwd = 2)
curve(dt(x, 5), -6, 6, col = 3, add = T, lwd = 2)
curve(dt(x, 10), -6, 6, col = 4, add = T, lwd = 2)
curve(dnorm(x), col = 6, add = T, lwd = 2, lty = 2)
legend("topright", legend = c("df=1", "df=2", "df=5", "df=10", "df=Inf"), col = c(1:4, 6), lty = c(rep(1,
4), 2), lwd = 2)
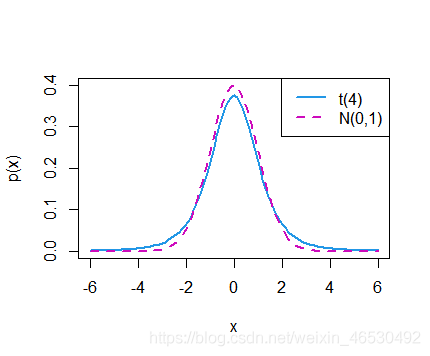
curve(dt(x, 4), -6, 6, col = 4, lwd = 2, ylim = c(0, 0.4), ylab = "p(x)")
curve(dnorm(x), col = 6, add = T, lwd = 2, lty = 2)
legend("topright", legend = c("t(4)", "N(0,1)"), col = c(4, 6), lty = c(1, 2), lwd = 2)
qt(0.025,10)
qt(0.975,10)
## === F ==
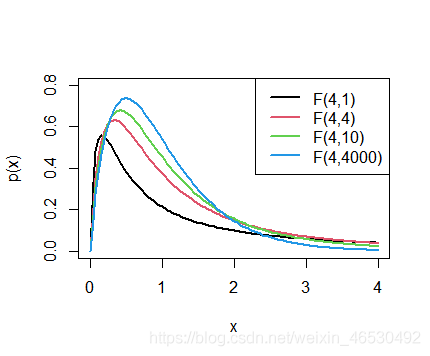
curve(df(x, 4, 1), 0, 4, ylab = "p(x)", lwd = 2, ylim = c(0, 0.8))
curve(df(x, 4, 4), 0, 4, col = 2, add = T, lwd = 2)
curve(df(x, 4, 10), 0, 4, col = 3, add = T, lwd = 2)
curve(df(x, 4, 4000), 0, 4, col = 4, add = T, lwd = 2)
legend("topright", legend = c("F(4,1)", "F(4,4)", "F(4,10)", "F(4,4000)"), col = 1:4, lwd = 2)
qf(0.95,10,5)
qf(0.05,5,10)
1/qf(0.05,5,10)
卡方分布
t分布
F分布
#卡方分布 > qchisq(0.95,5) [1] 11.0705 > qchisq(0.95,10) [1] 18.30704 > qchisq(0.95,15) [1] 24.99579 > qchisq(0.95,20) [1] 31.41043 > qchisq(0.95,25) [1] 37.65248 > qchisq(0.95,30) [1] 43.77297
#t分布 > qt(0.95,5) [1] 2.015048 > qt(0.95,10) [1] 1.812461 > qt(0.95,15) [1] 1.75305 > qt(0.95,20) [1] 1.724718 > qt(0.95,25) [1] 1.708141 > qt(0.95,30) [1] 1.697261
> qf(0.95,10,5) [1] 4.735063 > qf(0.95,5,10) [1] 3.325835 > qf(0.95,5,5) [1] 5.050329 > qf(0.95,10,10) [1] 2.978237
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
R语言-如何定义数据框的列名
1.在定义数据框时,定义列名: 例如: a<-c(2,23,45,6,7,1,6,7) b<-c(4,6,1,2,5,66,10,2) df<-data.frame(a,b) 此时数据框df中的列名分别是a.b 也可以如下: df<-data.frame(a1=a,b1=b) 此时的列名是a1.b1 2.修改数据框中列的名字 如果希望修改数据框中的列名,可以使用name函数进行修改 例如: names(df)<-c("a2","b2")
-
R语言科学计数法介绍:digits和scipen设置方式
控制R语言科学计算法显示有两个option: digitis和scipen.介绍的资料很少,而且有些是错误的.经过翻看R语言的帮助和做例子仔细琢磨,总结如下: 默认的设置是: getOption("digits") [1] 7 getOption("scipen") [1] 0 digits 有效数字字符的个数,默认是7, 范围是[1,22] scipen 科学计数显示的penalty,可以为正为负,默认是0 R输出数字时,使用普通数字表示的长度 <= 科学计
-
R语言-计算平均值不同函数的区别说明
函数mean > mean(x) > num x1 x2 x3 10378050.50 89.45 81.18 80.45 此时对编号也求了平均值,不过往往我们只想对后面的数据求平均值.而且此时会出现一个警告.因为x是一个数据框,不是数值,所以不能直接用mean()函数. 函数colMeans() > colMeans(x) num x1 x2 x3 10378050.50 89.45 81.18 80.45 > colMeans(x)[c("x1","
-
R语言中do.call()的使用说明
简单参数设置就能搞定的事情,是不会用到do.call的. 在运用R的过程中总会碰到这样一类函数,它们接受的参数数量可以是任意的,该函数会处理这些参数,并返回处理结果. 最简单的例子就是data.frame 比如: > x1 = 1:10 > x2 = 11:20 > x3 = 21:30 > data.frame(x1,x2,x3) x1 x2 x3 1 1 11 21 2 2 12 22 3 3 13 23 4 4 14 24 5 5 15 25 6 6 16 26 7 7 17
-
R语言实现对数据框按某一列分组求组内平均值
可使用aggregate函数 如: aggregate(.~ID,data=这个数据框名字,mean) 如果是对数据框分组,组内有重复的项,对于重复项保留最后一行数据用: pcm_df$duplicated <- duplicated(paste(pcm_df$OUT_MAT_NO, pcm_df$Posit, sep = "_"), fromLast = TRUE) pcm_df <- subset(pcm_df, !duplicated) pcm_df$duplicat
-

R语言-如何将科学计数法表示的数字转化为文本
统赛B组我们选择了图书馆课题,获得了数据,一时兴起尝试处理了一下门禁的数据,遇到了一些问题,特此记下,方便以后查阅. 门禁数据分为两个变量,第一列为学号,第二列为进门时间,原本是Excel文件,为了方便读入R我把它另存为了csv文件,但在读入R以后出现了一些问题 1.学号被存储为了科学计数法表示的数字 2.时间显示的也不全面,有些乱码 时间问题可以在Excel中把单元格格式设置一下就解决了,但是学号问题却遇到了一些小麻烦,我本来是想用 menjin$studentcode <- as.chara
-
R语言中igraph包的用法(邻接矩阵)
先导入igraph包: library(igraph) graph包最简单的用法就是graph方法,两句代码就完成绘制如下所示,1的loop表示为(1,1),1和2之间有3条edge,表示为(1,2,1,2,1,2) g <- graph(c(1,1,1,2,1,2,1,2,1,5,2,3,2,4,2,5,3,3,3,4,3,4,3,4,4,5),directed = FALSE) plot(g) 如果用顶点的邻接矩阵表示,仍以上图为例: 则对1,1有loop,与2有条edge,与5有一条edg
-
R语言ggplot2包之坐标轴详解
引言 我们还可以对图形中的坐标轴进行处理,包括x.y轴对换.设定坐标轴范围.刻度线修改与去除等等.要想对图形玩得转,坐标轴处理精通不可或缺. 坐标轴对换 我们使用coord_flip()函数来对换坐标轴. library(ggplot2) library(gcookbook) ggplot(PlantGrowth, aes(x=group, y=weight)) + geom_boxplot() ggplot(PlantGrowth, aes(x=group, y=weight)) + geom
-
R语言-t分布正态分布分位数图的实例
R是用于统计分析.绘图的语言和操作环境. R是属于GNU系统的一个自由.免费.源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具. 它是一套由数据操作.计算和图形展示功能整合而成的套件. 包括:有效的数据存储和处理功能,一套完整的数组(特别是矩阵)计算操作符,拥有完整体系的数据分析工具,为数据分析和显示提供的强大图形功能,一套(源自S语言)完善.简单.有效的编程语言(包括条件.循环.自定义函数.输入输出功能). 如何用RStudio做分位数图呢? #分位数图,画t分布密度带p值 x=se
-
R语言利用ggplot2绘制QQ图和箱线图详解
目录 绘制qq图 函数介绍 例子 绘制boxplot 函数介绍 例子 利用分位点绘制箱线图 将QQ图和箱线图进行融合 函数介绍 参数介绍 注意事项 例子 绘制qq图 在ggplot2中绘制qq图需要两步,geom_qq()将绘制样本分位点,geom_qq_line()将绘制标准正态线 函数介绍 geom_qq() geom_qq( mapping = NULL, data = NULL, geom = "point", position = "identity",
-
R语言开发之输出折线图的操作
线形图是通过在多个点之间绘制线段来连接一系列点所形成的图形,这些点按其坐标(通常是x坐标)的值排序,并且它通常用于识别数据趋势. 在R中的通过使用plot()函数来创建线形图,语法如下: plot(v,type,col,xlab,ylab) 参数描述如下: v - 是包含数值的向量. type - 取值"p"表示仅绘制点,"l"表示仅绘制线条,"o"表示仅绘制点和线. xlab - 是x轴的标签. ylab - 是y轴的标签. main - 是图
-
R语言编程学习绘制动态图实现示例
在讨论级数时,可能需要比对前 n n n项和的变化情况,而随着 n n n的递增,通过动态图来反映这种变化会更加直观,而通过R语言绘制动态图也算是一门不那么初级的技术,所以在此添加一节,补充一下R语言的绘图知识. 绘图需要用到ggplot2,为多张图加上时间轴则需要用到gganimate,为了让这些动态图片被渲染,需要用到av.此外,ggplot2绘图需要输入的数据格式为tibble. install.packages("ggplot2") install.packages("
-
R语言绘制数据可视化小提琴图画法示例
目录 Step1. 绘图数据的准备 Step2. 绘图数据的读取 Step3. 绘图所需package的安装.调用 Step4. 绘图 小提琴图之前已经画过了,不过最近小仙又看到一种貌美的画法,决定复刻一下.文献中看到的图如下: Step1. 绘图数据的准备 首先要把你想要绘图的数据调整成R语言可以识别的格式,建议大家在excel中保存成csv格式.作图数据如下: Step2. 绘图数据的读取 data<-read.csv("your file path", header = T
-
R语言绘制line plot线图示例详解
目录 Step1.绘图数据的准备 Step2.绘图数据的读取 Step3.绘图所需package的安装.调用 Step4.绘图 最近小仙同学在Nature Cell Biology上看到了这样一张图,很常见的折线图画成这个样子——原来很常见的图标类型也可以“焕发新春”! 今天小仙同学就尝试用R复刻一张类似的折线图. Step1. 绘图数据的准备 首先要把你想要绘图的数据调整成R语言可以识别的格式,建议大家在excel中保存成csv格式.数据的格式如下图:一列表示一种变量,最后一列是每一行的行名.
-
R语言绘制数据可视化小提琴图Violin plot with dot画法
目录 Step1.绘图数据的准备 Step2.绘图数据的读取 Step3.绘图所需package的安装.调用 Step4.绘图 小提琴图之前已经画过了,不过最近小仙又看到一种貌美的画法,决定复刻一下.文献中看到的图如下: Step1. 绘图数据的准备 首先要把你想要绘图的数据调整成R语言可以识别的格式,建议大家在excel中保存成csv格式.作图数据如下: Step2. 绘图数据的读取 data<-read.csv("your file path", header = T) #注
-
R语言实现漂亮的ROC图效果
目录 1.读取数据 2.AUC和CI的计算 3.利用ggplot2绘图 4.合并多个ROC曲线结果 pROC是一个专门用来计算和绘制ROC曲线的R包,目前已被CRAN收录,因此安装也非常简单,同时该包也兼容ggplot2函数绘图,本次就教大家怎么用pROC来快速画出ROC图.在医学领域主要用于判断某种因素对于某种疾病的诊断是否有诊断价值.什么是ROC曲线和AUC,以及如何去看ROC曲线的结果,可以这样总结:ROC曲线呢,其实就是每个对应的cutoff值都有一个对应的真阳性率(纵坐标)和假阳性率(
-
R语言ComplexHeatmap绘制复杂热图heatmap
目录 一 载入R包 数据 1.1 载入ComplexHeatmap包,数据 1.2 绘制最简单的热图 二 常见“表型”注释 读入注释文件 2.1 添加注释,且设置颜色 三 添加“块”注释 3.1 k-means指定K个数 3.2 先验知识知道样本分为几个簇 3.3 根据富集结果添加行注释 四 目标基因分析 4.1 标签展示目标基因 4.2 绘制目标基因热图 ComplexHeatmap|绘制单个热图介绍了单个热图绘制的内容 一 载入R包 数据 1.1 载入ComplexHeatmap包,数据 为
-
R语言 实现将两张图放在同一张画布
我就废话不多说了,大家还是直接看代码吧~ ts1<-ts(test_data$tot_num,frequency = 365,start=c(2017,11,21)) plot(ts1,col='blue',lty='dotted',ylim=c(50,550)) par(new=TRUE) ts2<-ts(test_data$pre_result,frequency = 365,start=c(2017,11,21)) plot(ts2,col='red',ylim=c(50,550)) 好