jupyter notebook 多环境conda kernel配置方式
一直记不住在jupyter notebook配置多环境编译器技巧,今总结于此,也希望对其他小伙伴有所帮助,如果有用请点赞!
1.对windows用户,win+R,输入cmd进去进入命令行,激活环境:

2.首先,确定自己是否安装包‘ipykernel',若是没有安装,则进行安装;已安装进行下一步。

3.然后输入命令:
python -m ipykernel install --user --name deeplearningproject --display-name "deeplearningproject"
注:上述两个 deeplearningproject,前者是自身环境名称,不能变化;后者是在jupyter notebook的显示名称,可修改。
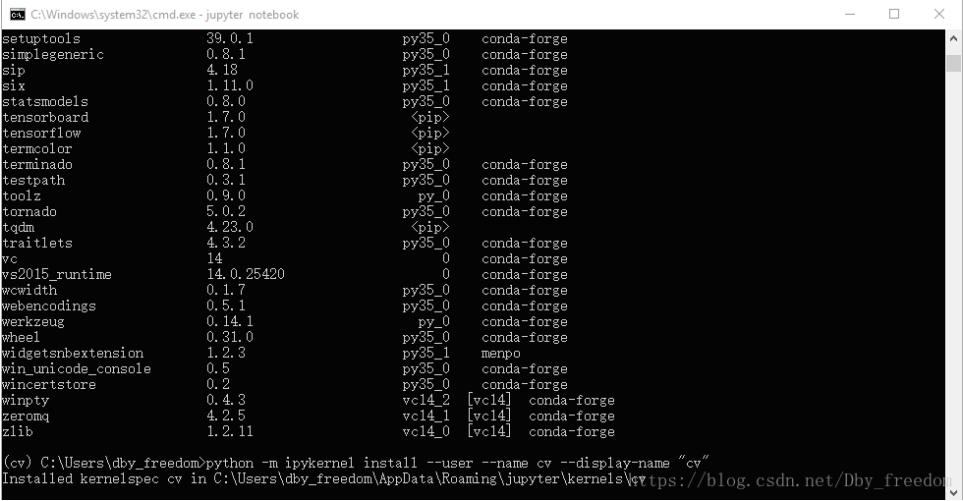
4.至此,完成所有操作,输入jupyter notebook进行验证

5.大功告成
至此,完成所有操作。
补充知识:Python Jupyter notebook 运行 multiprocessing 跑不了的问题
最近工作中为了解决python支持多核cpu,遇到一个Jupyter notebook跑不了multiprocessing的问题。
网上找了些multiprocessing的例子,Pycharm可以跑,但是在Jupyter notebook上跑了就只有In[*],error log:
AttributeError: Can't get attribute 'task' on <module '__main__' <built-in>>
最后找到一个解决方案:把方法写到临时文件里,再读出来。
from multiprocessing import Pool
from functools import partial
import inspect
def parallal_task(func, iterable, *params):
with open(f'./tmp_func.py', 'w') as file:
file.write(inspect.getsource(func).replace(func.__name__, "task"))
from tmp_func import task
if __name__ == '__main__':
func = partial(task, params)
pool = Pool(processes=8)
res = pool.map(func, iterable)
pool.close()
return res
else:
raise "Not in Jupyter Notebook"
def long_running_task(params, id): # Heavy job here return params, id data_list = range(8) for res in parallal_task(long_running_task, data_list, "a", 1, "b"): print(res)
以上这篇jupyter notebook 多环境conda kernel配置方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
在PyCharm环境中使用Jupyter Notebook的两种方法总结
方法一: 1.安装Jupyter Notebook pip install jupyter 2.在PyCharm中新建Jupyter Notebook文件 步骤:File->New...->Jupyter Notebook->输入文件名 建好之后效果如下图所示,就是熟悉的Jupyter Notebook界面: 3.运行 输入代码,点击绿色小三角运行代码. 方法二: 1.安装Jupyter Notebook pip install jupyter 2.打开Python Console 打开
-
jupyter notebook 多行输出实例
很多时候在一个cell中,我们不只有一个print,但默认只有一个print,所以我们进行多行输出,加入代码 from IPython.core.interactiveshell import InteractiveShell InteractiveShell.ast_node_interactivity = "all" 补充知识:jupyter notebook 输出中文PDF的简便方法哦 一个简单的 Jupyter notebook 输出中文PDF文件的方法 直接浏览器虚拟打印
-
Jupyter notebook远程访问服务器的方法
1.背景 一直苦恼于本地机器和服务器上都要配置一些机器学习方面的环境,今天花了点时间研究了下Jupter notebook远程访问服务器,所以记录一下. 有些步骤非必须,这里尽量写清楚,读者理解后自行决定如何安装,本文以非root用户安装. 2.安装步骤 (1)登录服务器 (2)检查是否有安装jupyter notebook,终端输入jupyter notebook,如果报错就是没有啦,那么就要用下面命令安装. $sudo pip install pyzmq $sudo pip install
-
jupyter notebook 多环境conda kernel配置方式
一直记不住在jupyter notebook配置多环境编译器技巧,今总结于此,也希望对其他小伙伴有所帮助,如果有用请点赞! 1.对windows用户,win+R,输入cmd进去进入命令行,激活环境: 2.首先,确定自己是否安装包'ipykernel',若是没有安装,则进行安装:已安装进行下一步. 3.然后输入命令: python -m ipykernel install --user --name deeplearningproject --display-name "deeplearningp
-
jupyter notebook 调用环境中的Keras或者pytorch教程
1.安装插件,在非虚拟环境 conda install nb_conda conda install ipykernel 2.安装ipykernel包,在虚拟环境下安装 在Windows使用下面命令:激活环境并安装插件(这里的 Keras 是我的环境名,安装的时候换成自己的环境名即可) activate keras conda install ipykernel 在linux 使用下面的命令: 激活环境并安装插件 source activate keras conda install ipyke
-
Jupyter Notebook的连接密码 token查询方式
换用非默认浏览器时需要输入密码或token 查询方法: 在XX:\AnacondaXX\Scripts下 运行 jupyter-notebook.exe list 可得token 密码:(设成了用不了..???) 在jupyter notebook正常开的文件里打 in[1]from notebook.auth import passwd in[2]passwd() 补充知识:Anaconda3中自带Jupyter notebook如何查找token 最近在使用Anaconda3学习tensor
-
TensorFlow安装及jupyter notebook配置方法
tensorflow利用anaconda在ubuntu下安装方法及jupyter notebook运行目录及远程访问配置 Ubuntu下安装Anaconda bash ~/file_path/file_name.sh 出现许可后可按Ctrl+C跳过,yes同意. 安装完成后询问是否加入path路径,亦可自行修改文件内容 关闭命令台重开 python -V 可查看是否安装成功 修改anaconda的python版本,以符合tf要求 conda install python=3.5 Anaconda
-

Jupyter Notebook 远程访问配置详解
问题 Jupyter Notebook可以说是非常好用的小工具,但是不经过配置只能够在本机访问 笔者参阅了文档对jupyter notebook进行配置,实现了跨主机浏览器访问 安装jupyter notebook 笔者使用conda包管理 conda install jupyter notebook 生成默认配置文件 jupyter notebook --generate-config 将会在用户主目录下生成.jupyter文件夹,其中jupyter_notebook_config.py就是刚
-
Jupyter notebook运行Spark+Scala教程
今天在intellij调试spark的时候感觉每次有新的一段代码,都要重新跑一遍,如果用spark-shell,感觉也不是特别方便,如果能像python那样,使用jupyter notebook进行编程就很方便了,同时也适合代码展示,网上查了一下,试了一下,碰到了很多坑,有些是旧的版本,还有些是版本不同导致错误,这里就记录下来安装的过程. 1.运行环境 硬件:Mac 事先装好:Jupyter notebook,spark2.1.0,scala 2.11.8 (这个版本很重要,关系到后面的安装)
-
Jupyter notebook快速入门教程(推荐)
本文主要介绍了Jupyter notebook快速入门教程,分享给大家,具体如下: 本篇将给大家介绍一款超级好用的工具:Jupyter notebook. 为什么要介绍这款工具呢? 如果你想使用Python学习数据分析或数据挖掘,那么它应该是你第一个应该知道并会使用的工具,它很容易上手,用起来非常方便,是个对新手非常友好的工具.而事实也证明它的确很好用,在数据挖掘平台 Kaggle 上,使用 Python 的数据爱好者绝大多数使用 jupyter notebook 来实现分析和建模的过程,因此,
-
Jupyter Notebook安装及使用方法解析
一.Jupyter Notebook是什么? 1.notebook jupyter简介 Jupyter Notebook是一个开源Web应用程序,允许您创建和共享包含实时代码,方程式,可视化效果和叙述文本的文档.用途包括:数据清理和转换,数值模拟,统计建模,数据可视化,机器学习等 Jupyter Notebook是一个交互式的笔记本,支持运行超过40种编程语言,Jupyter Notebook可以通过网页的形式打开,在网页页面中直接编写代码和运行代码,代码的运行结果也会直接在代码块下面进行显示.
-
在jupyter notebook 添加 conda 环境的操作详解
1. 激活conda环境 source activate cym 2. 安装ipykernel conda install ipykernel 3. 将环境写入notebook的kernel中 python -m ipykernel install --user --name 环境名 --display-name "python 环境名" python -m ipykernel install --user --name cym --display-name "python
-
jupyter notebook参数化运行python方式
Updates (2019.8.14 19:53)吃饭前用这个方法实战了一下,吃完回来一看好像不太行:跑完一组参数之后,到跑下一组参数时好像没有释放之占用的 GPU,于是 notebook 上的结果,后面好几条都报错说 cuda out of memory. 现在改成:将 notebook 中的代码写在一个 python 文件中,然后用命令行运行这个文件,比如: # autorun.py import os # print(os.getcwd()) over = [ # 之前手工改参数跑完的参数