Python编程实现下载器自动爬取采集B站弹幕示例
目录
- 实现效果
- UI界面
- 数据采集
- 小结
大家好,我是小张!
在《Python编程实现小姐姐跳舞并生成词云视频示例》文章中简单介绍了B站弹幕的爬取方法,只需找到视频中的参数 cid,就能采集到该视频下的所有弹幕;思路虽然很简单,但个人感觉还是比较麻烦,例如之后的某一天,我想采集B站上的某个视频弹幕,还需要从头开始:找cid参数、写代码,重复单调;
因此我在想有没有可能一步到位,以后采集某个视频弹幕时只需一步操作,比如输入想爬取的视频链接,程序能自动识别下载
实现效果
基于此,借助 PyQt5 我写了一个小工具,只需提供目标视频的 url 以及目标 txt 路径,程序对该视频下的弹幕自动采集并把数据保存至目标txt文本,先看一下预览效果:
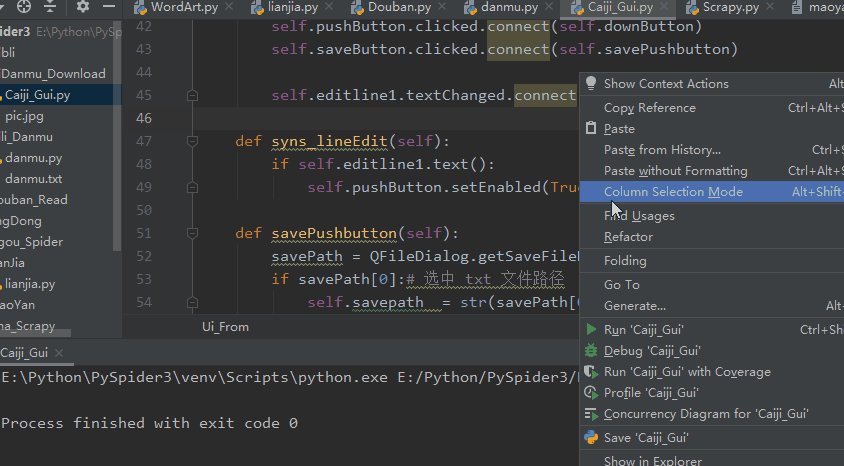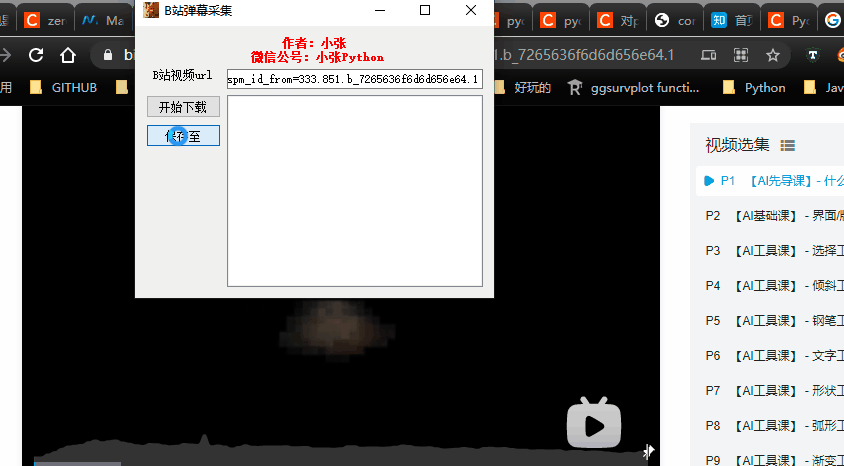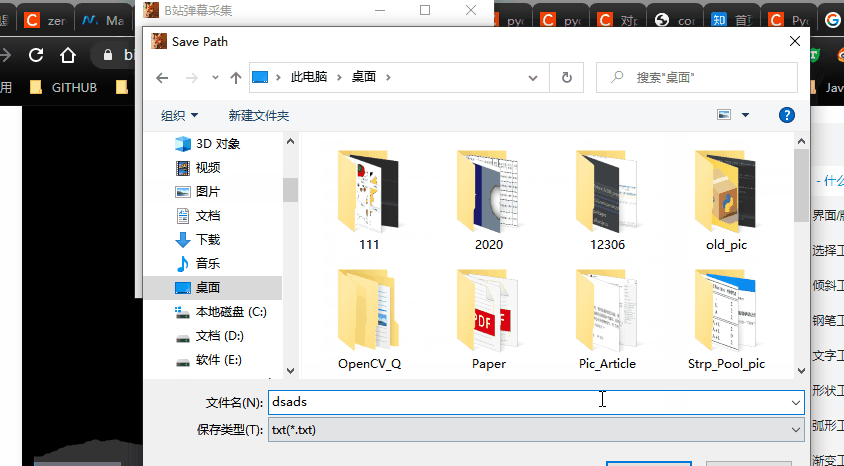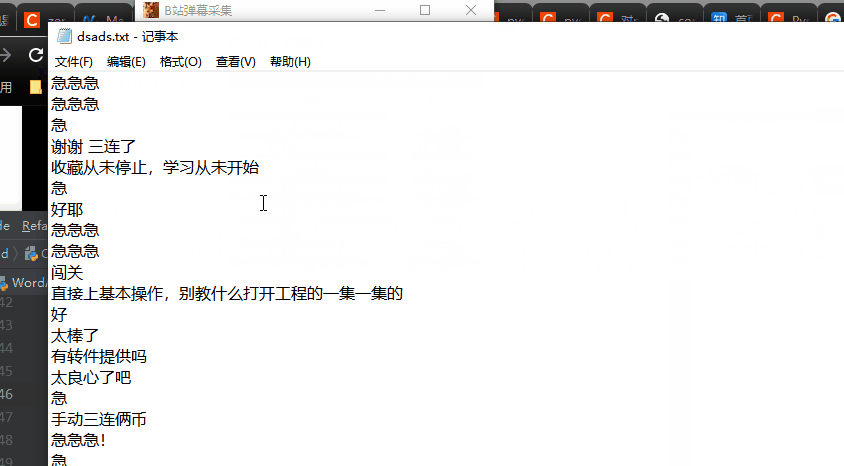
PS 微信公号对动图帧数有限制,制作动图时我删减了一部分内容,因此效果可能会不太流畅
工具实现整体分为UI界面、数据采集 两个部分,用到的Python库:
import requests import re from PyQt5.QtWidgets import * from PyQt5 import QtCore from PyQt5.QtGui import * from PyQt5.QtCore import QThread, pyqtSignal from bs4 import BeautifulSoup
UI界面
UI 界面借助了 PyQt5,放置了了两个按钮(开始下载、保存至),输入视频链接 的 editline 控件及调试窗口;
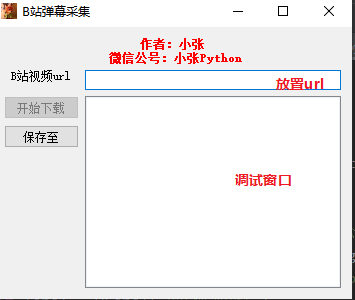
代码如下:
def __init__(self,parent =None):
super(Ui_From,self).__init__(parent=parent)
self.setWindowTitle("B站弹幕采集")
self.setWindowIcon(QIcon('pic.jpg'))# 图标
self.top_label = QLabel("作者:小张\n 微信公号:小张Python")
self.top_label.setAlignment(QtCore.Qt.AlignHCenter)
self.top_label.setStyleSheet('color:red;font-weight:bold;')
self.label = QLabel("B站视频url")
self.label.setAlignment(QtCore.Qt.AlignHCenter)
self.editline1 = QLineEdit()
self.pushButton = QPushButton("开始下载")
self.pushButton.setEnabled(False)#关闭启动
self.Console = QListWidget()
self.saveButton = QPushButton("保存至")
self.layout = QGridLayout()
self.layout.addWidget(self.top_label,0,0,1,2)
self.layout.addWidget(self.label,1,0)
self.layout.addWidget(self.editline1,1,1)
self.layout.addWidget(self.pushButton,2,0)
self.layout.addWidget(self.saveButton,3,0)
self.layout.addWidget(self.Console,2,1,3,1)
self.setLayout(self.layout)
self.savepath = None
self.pushButton.clicked.connect(self.downButton)
self.saveButton.clicked.connect(self.savePushbutton)
self.editline1.textChanged.connect(self.syns_lineEdit)
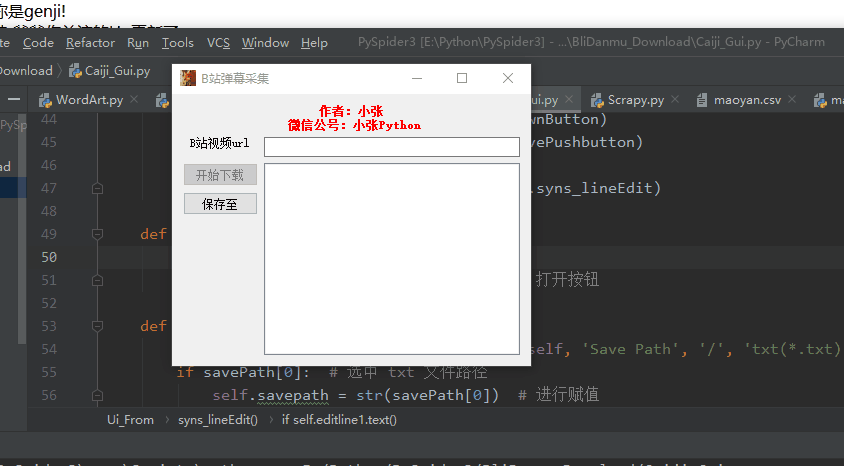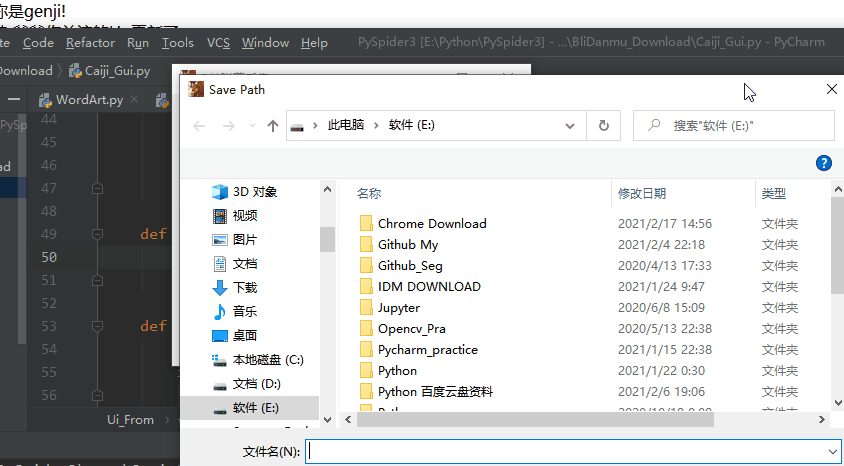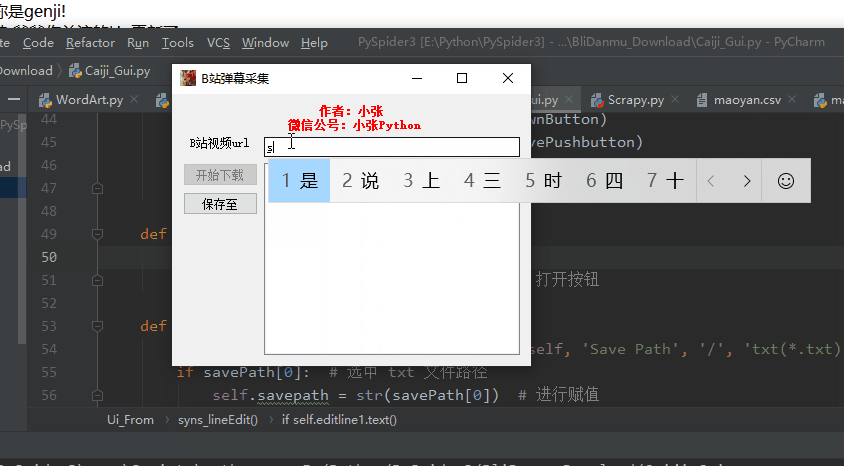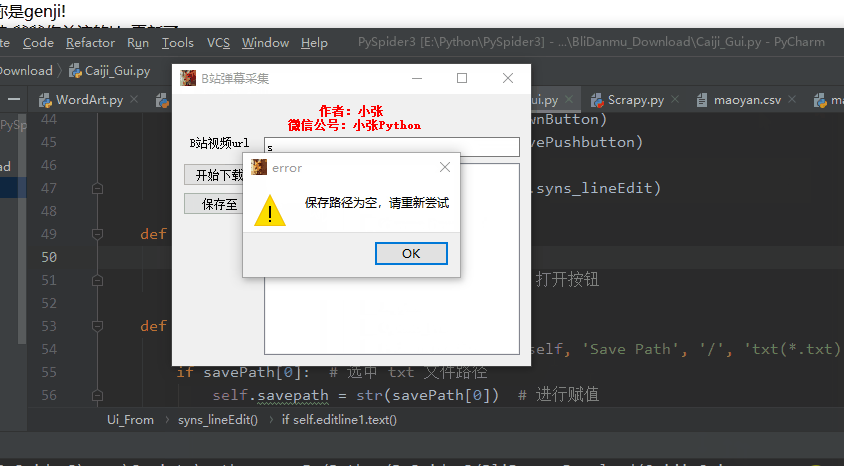
当 url 不为空以及目标文本存放路径已经设置好之后,才能进入数据采集模块
实现此功能的代码:
def syns_lineEdit(self):
if self.editline1.text():
self.pushButton.setEnabled(True)#打开按钮
def savePushbutton(self):
savePath = QFileDialog.getSaveFileName(self,'Save Path','/','txt(*.txt)')
if savePath[0]:# 选中 txt 文件路径
self.savepath = str(savePath[0])#进行赋值
数据采集
程序获取到 url 之后,第一步就是访问 url 提取当前页面中该视频的cid 参数(一连串数字)
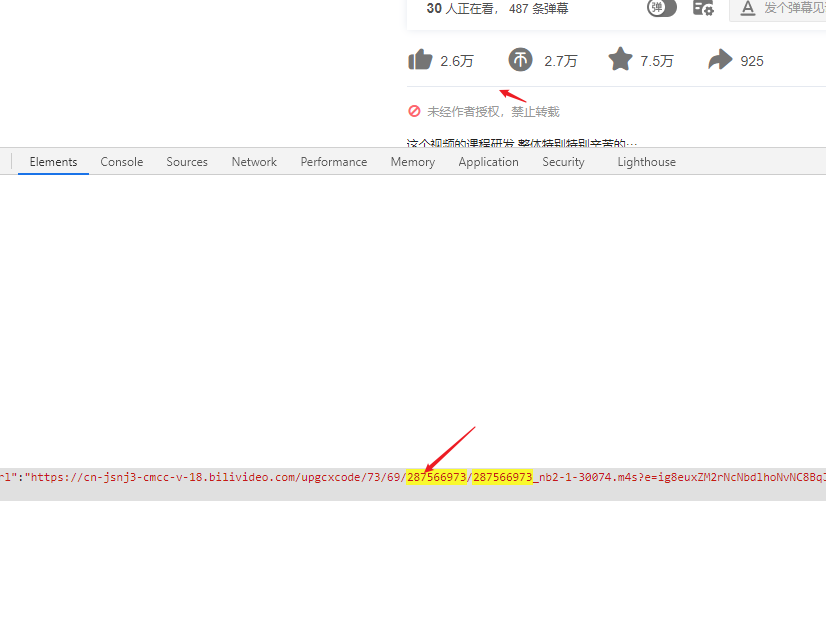
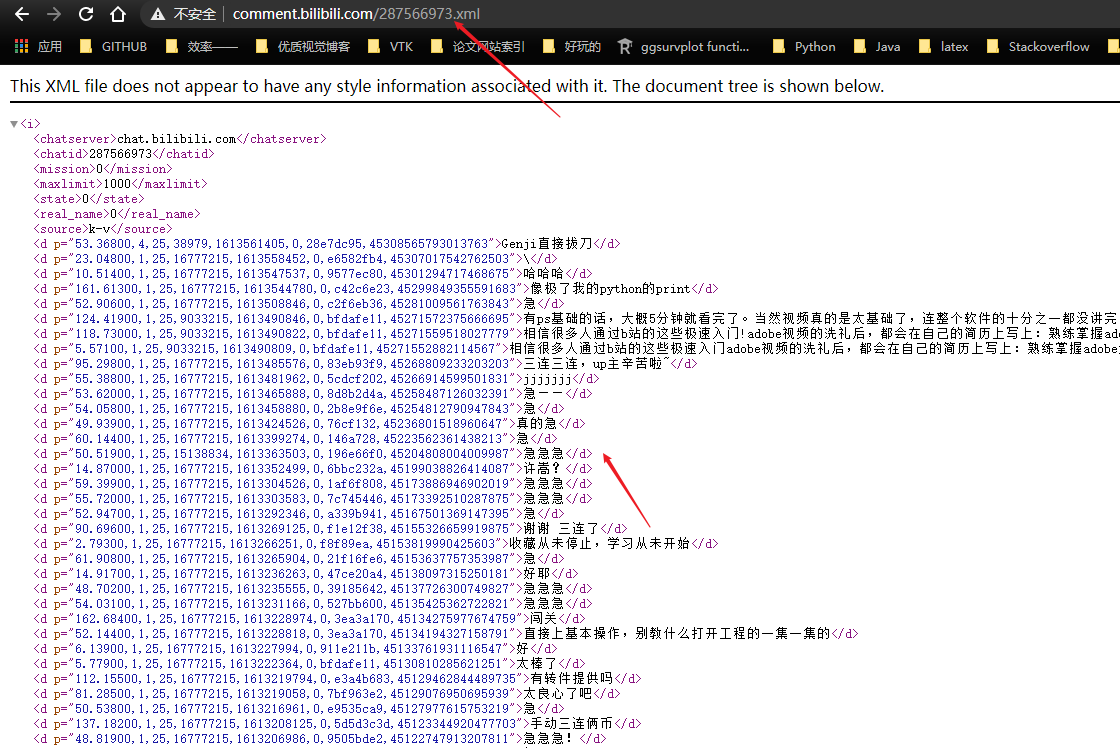
利用cid 参数构造该存放该视频弹幕的 API 接口,随后用常规 requests 和 bs4 包实现文本采集
数据采集部分代码:
f = open(self.savepath, 'w+', encoding='utf-8') # 打开 txt 文件
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'lxml')
items = soup.find_all('d') # 找到 d 标签
for item in items:
text = item.text
f.write(text)
f.write('\n')
f.close()
cid 参数 并不是位于常规 html 的标签上,提取时我选择 re 正则匹配;但这一步骤比较耗机子内存,为了减少对UI界面响应速度的影响,这一步骤单独用一个线程来实现
class Parsetext(QThread):
trigger = pyqtSignal(str) # 信号发射;
def __init__(self,text,parent = None):
super(Parsetext,self).__init__()
self.text = text
def __del__(self):
self.wait()
def run(self):
print('解析 -----------{}'.format(self.text))
result_url = re.findall('.*?"baseUrl":"(.*?)","base_url".*?', self.text)[0]
self.trigger.emit(result_url)
小结
好了,以上就是本篇文章的全部内容了,希望内容能够对你工作或者学习上有所帮助。
最后感谢大家的阅读,我们下期见
以上就是Python编程实现下载器自动采集B站弹幕示例的详细内容,更多关于Python实现自动爬取的资料请关注我们其它相关文章!
相关推荐
-

Python基于Tkinter开发一个爬取B站直播弹幕的工具
简介 使用Python Tkinter开发一个爬取B站直播弹幕的工具,启动后在弹窗中输入房间号即可,弹幕内容会保存在脚本文件同级目录下的.log扩展名的文件中 开发工具 python 3.7.9 pycharm 2019.3.5 实现代码 import threading import time import tkinter.simpledialog # 使用Tkinter前需要先导入 from tkinter import END, messagebox import requests # 全
-
写一个Python脚本自动爬取Bilibili小视频
我身边的很多小伙伴们在朋友圈里面晒着出去游玩的照片,简直了,人多的不要不要的,长城被堵到水泄不通,老实人想想啊,既然人这么多,哪都不去也是件好事,没事还可以刷刷 B 站 23333 .这时候老实人也有了一个大胆地想法,能不能让这些在旅游景点排队的小伙伴们更快地打发时间呢?考虑到视频的娱乐性和大众观看量,我决定对 B 站新推出的小视频功能下手,于是我跑到B站去找API接口,果不起然,B站在小视频功能处提供了 API 接口,小伙伴们有福了哟! B 站小视频网址在这里哦: http://vc.bili
-
python3写爬取B站视频弹幕功能
需要准备的环境: 一个B站账号,需要先登录,否则不能查看历史弹幕记录 联网的电脑和顺手的浏览器,我用的Chrome Python3环境以及request模块,安装使用命令,换源比较快: pip3 install request -i http://pypi.douban.com/simple 爬取步骤: 登录后打开需要爬取的视频页面,打开开发者工具台,Chrome可以使用F12快捷键,选择network监听请求 点击查看历史弹幕,获取请求 其中rolldate后面的数字表示该视频对应的弹幕号,返
-
用python制作个视频下载器
前言 某个夜深人静的夜晚,夜微凉风微扬,月光照进我的书房~ 当我打开文件夹以回顾往事之余,惊现许多看似杂乱的无聊代码.我拍腿正坐,一个想法油然而生:"生活已然很无聊,不如再无聊些叭". 于是,我决定开一个专题,便称之为kimol君的无聊小发明. 妙-啊~~~ 众所周知,视频是一个学习新姿势知识的良好媒介.那么,如何利用爬虫更加方便快捷地下载视频呢?本文将从数据包分析到代码实现来进行一个相对完整的讲解. 一.爬虫分析 本次选取的目标视频网站为某度旗下的好看视频: https://haok
-
Python编程实现下载器自动爬取采集B站弹幕示例
目录 实现效果 UI界面 数据采集 小结 大家好,我是小张! 在<Python编程实现小姐姐跳舞并生成词云视频示例>文章中简单介绍了B站弹幕的爬取方法,只需找到视频中的参数 cid,就能采集到该视频下的所有弹幕:思路虽然很简单,但个人感觉还是比较麻烦,例如之后的某一天,我想采集B站上的某个视频弹幕,还需要从头开始:找cid参数.写代码,重复单调: 因此我在想有没有可能一步到位,以后采集某个视频弹幕时只需一步操作,比如输入想爬取的视频链接,程序能自动识别下载 实现效果 基于此,借助 PyQt5
-
Python爬虫实现的根据分类爬取豆瓣电影信息功能示例
本文实例讲述了Python爬虫实现的根据分类爬取豆瓣电影信息功能.分享给大家供大家参考,具体如下: 代码的入口: if __name__ == '__main__': main() #! /usr/bin/python3 # -*- coding:utf-8 -*- # author:Sirius.Zhao import json from urllib.parse import quote from urllib.request import urlopen from urllib.reque
-
基于Python实现ComicReaper漫画自动爬取脚本过程解析
这篇文章主要介绍了基于Python实现ComicReaper漫画自动爬取脚本过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 讲真的, 手机看漫画翻页总是会手残碰到页面上的广告好吧... 要是能只需要指定一本漫画的主页URL就能给我返回整本漫画就好了... 这促使我产生了使用Python 3来实现, 做一个 ComicReaper(漫画收割者) 的想法! 本文所用漫画链接 : http://www.manhuadb.com/manhua/
-
python绕过图片滑动验证码实现爬取PTA所有题目功能 附源码
最近学了python爬虫,本着学以致用的态度去应用在生活中.突然发现算法的考试要来了,范围就是PTA刷过的题.让我一个个复制粘贴?不可能,必须爬它! 先开页面,人傻了,PTA的题目是异步加载的,爬了个寂寞(空数据).AJAX我又不熟,突然想到了selenium. selenium可以模拟人的操作让浏览器自动执行动作,具体的自己去了解,不多说了.干货来了: 登录界面有个图片的滑动验证码 破解它的最好方式就是用opencv,opencv巨强,自己了解. 思路开始: 1.将背景图片和可滑动的图片下载
-
python爬虫爬取某网站视频的示例代码
把获取到的下载视频的url存放在数组中(也可写入文件中),通过调用迅雷接口,进行自动下载.(请先下载迅雷,并在其设置中心的下载管理中设置为一键下载) 实现代码如下: from bs4 import BeautifulSoup import requests import os,re,time import urllib3 from win32com.client import Dispatch class DownloadVideo: def __init__(self): self.r = r
-
python爬虫 正则表达式使用技巧及爬取个人博客的实例讲解
这篇博客是自己<数据挖掘与分析>课程讲到正则表达式爬虫的相关内容,主要简单介绍Python正则表达式爬虫,同时讲述常见的正则表达式分析方法,最后通过实例爬取作者的个人博客网站.希望这篇基础文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵.真的太忙了,太长时间没有写博客了,抱歉~ 一.正则表达式 正则表达式(Regular Expression,简称Regex或RE)又称为正规表示法或常规表示法,常常用来检索.替换那些符合某个模式的文本,它首先设定好了一些特殊的字及字符组合,通过组合的&
-
Python实战快速上手BeautifulSoup库爬取专栏标题和地址
目录 安装 解析标签 解析属性 根据class值解析 根据ID解析 多层筛选 提取a标签中的网址 实战-获取博客专栏 标题+网址 BeautifulSoup库快速上手 安装 pip install beautifulsoup4 # 上面的安装失败使用下面的 使用镜像 pip install beautifulsoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple 使用PyCharm的命令行 解析标签 from bs4 import BeautifulS
-
Python+Selenium实现短视频热点爬取
目录 涉及知识点 目标分析 1. 分析热榜目录 2.分析视频播放页面 3. 分析弹出框 核心代码 1. 遍历热点目录 2. 获取真实短视频url 3. 下载视频 4. 关闭弹出的登录窗口 5. 保存日志 示例截图 总结 随着短视频的大火,不仅可以给人们带来娱乐,还有热点新闻时事以及各种知识,刷短视频也逐渐成为了日常生活的一部分.本文以一个简单的小例子,简述如何通过Pyhton依托Selenium来爬取短视频,仅供学习分享使用,如有不足之处,还请指正. 涉及知识点 1.selenium,作为浏览器
-
Python爬取附近餐馆信息代码示例
本代码主要实现抓取大众点评网中关村附近的餐馆有哪些,具体如下: import urllib.request import re def fetchFood(url): # 模拟使用浏览器浏览大众点评的方式浏览大众点评 headers = {'User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'} ope