Python机器学习利用随机森林对特征重要性计算评估
目录
- 1 前言
- 2 随机森林(RF)简介
- 3 特征重要性评估
- 4 举个例子
- 5 参考文献
1 前言
随机森林是以决策树为基学习器的集成学习算法。随机森林非常简单,易于实现,计算开销也很小,更令人惊奇的是它在分类和回归上表现出了十分惊人的性能,因此,随机森林也被誉为“代表集成学习技术水平的方法”。
2 随机森林(RF)简介
只要了解决策树的算法,那么随机森林是相当容易理解的。随机森林的算法可以用如下几个步骤概括:
1.用有抽样放回的方法(bootstrap)从样本集中选取n个样本作为一个训练集
2.用抽样得到的样本集生成一棵决策树。在生成的每一个结点:
- 随机不重复地选择d个特征
- 利用这d个特征分别对样本集进行划分,找到最佳的划分特征(可用基尼系数、增益率或者信息增益判别)
3.重复步骤1到步骤2共k次,k即为随机森林中决策树的个数。
4.用训练得到的随机森林对测试样本进行预测,并用票选法决定预测的结果。
下图比较直观地展示了随机森林算法(图片出自文献2):
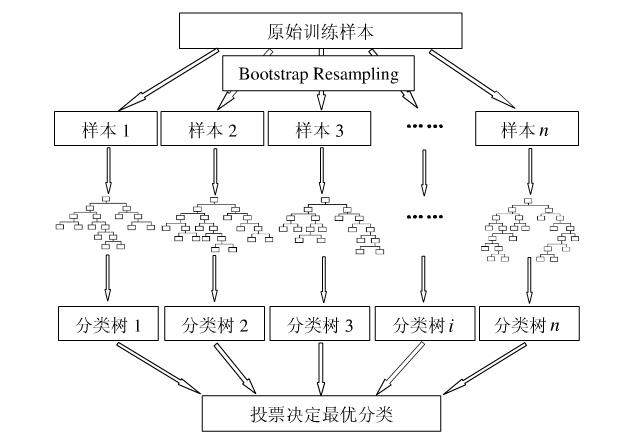
图1:随机森林算法示意图
没错,就是这个到处都是随机取值的算法,在分类和回归上有着极佳的效果,是不是觉得强的没法解释~
然而本文的重点不是这个,而是接下来的特征重要性评估。
3 特征重要性评估
现实情况下,一个数据集中往往有成百上前个特征,如何在其中选择比结果影响最大的那几个特征,以此来缩减建立模型时的特征数是我们比较关心的问题。这样的方法其实很多,比如主成分分析,lasso等等。不过,这里我们要介绍的是用随机森林来对进行特征筛选。
用随机森林进行特征重要性评估的思想其实很简单,说白了就是看看每个特征在随机森林中的每颗树上做了多大的贡献,然后取个平均值,最后比一比特征之间的贡献大小。
好了,那么这个贡献是怎么一个说法呢?通常可以用基尼指数(Gini index)或者袋外数据(OOB)错误率作为评价指标来衡量。
我们这里只介绍用基尼指数来评价的方法,想了解另一种方法的可以参考文献2。


4 举个例子
值得庆幸的是, sklearn已经帮我们封装好了一切,我们只需要调用其中的函数即可。
我们以UCI上葡萄酒的例子为例,首先导入数据集。
import pandas as pd
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data'
df = pd.read_csv(url, header = None)
df.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash',
'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins',
'Color intensity', 'Hue', 'OD280/OD315 of diluted wines', 'Proline']
然后,我们来大致看下这时一个怎么样的数据集
import numpy as np np.unique(df['Class label'])
输出为
array([1, 2, 3], dtype=int64)
可见共有3个类别。然后再来看下数据的信息:
df.info()
输出为
<class 'pandas.core.frame.DataFrame'> RangeIndex: 178 entries, 0 to 177 Data columns (total 14 columns): Class label 178 non-null int64 Alcohol 178 non-null float64 Malic acid 178 non-null float64 Ash 178 non-null float64 Alcalinity of ash 178 non-null float64 Magnesium 178 non-null int64 Total phenols 178 non-null float64 Flavanoids 178 non-null float64 Nonflavanoid phenols 178 non-null float64 Proanthocyanins 178 non-null float64 Color intensity 178 non-null float64 Hue 178 non-null float64 OD280/OD315 of diluted wines 178 non-null float64 Proline 178 non-null int64 dtypes: float64(11), int64(3) memory usage: 19.5 KB
可见除去class label之外共有13个特征,数据集的大小为178。
按照常规做法,将数据集分为训练集和测试集。
from sklearn.cross_validation import train_test_split from sklearn.ensemble import RandomForestClassifier x, y = df.iloc[:, 1:].values, df.iloc[:, 0].values x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0) feat_labels = df.columns[1:] forest = RandomForestClassifier(n_estimators=10000, random_state=0, n_jobs=-1) forest.fit(x_train, y_train)
好了,这样一来随机森林就训练好了,其中已经把特征的重要性评估也做好了,我们拿出来看下。
importances = forest.feature_importances_
indices = np.argsort(importances)[::-1]
for f in range(x_train.shape[1]):
print("%2d) %-*s %f" % (f + 1, 30, feat_labels[indices[f]], importances[indices[f]]))
输出的结果为
1) Color intensity 0.182483 2) Proline 0.158610 3) Flavanoids 0.150948 4) OD280/OD315 of diluted wines 0.131987 5) Alcohol 0.106589 6) Hue 0.078243 7) Total phenols 0.060718 8) Alcalinity of ash 0.032033 9) Malic acid 0.025400 10) Proanthocyanins 0.022351 11) Magnesium 0.022078 12) Nonflavanoid phenols 0.014645 13) Ash 0.013916
对的就是这么方便。
如果要筛选出重要性比较高的变量的话,这么做就可以
threshold = 0.15 x_selected = x_train[:, importances > threshold] x_selected.shape
输出为
(124, 3)
瞧,这不,帮我们选好了3个重要性大于0.15的特征了吗~
5 参考文献
[1] Raschka S. Python Machine Learning[M]. Packt Publishing, 2015.
[2] 杨凯, 侯艳, 李康. 随机森林变量重要性评分及其研究进展[J]. 2015.
以上就是Python机器学习利用随机森林对特征重要性计算评估的详细内容,更多关于Python随机森林重要性计算的资料请关注我们其它相关文章!
相关推荐
-
Python机器学习入门(三)数据准备
目录 1.数据预处理 1.1调整数据尺度 1.2正态化数据 1.3标准化数据 1.4二值数据 2.数据特征选定 2.1单变量特征选定 2.2递归特征消除 2.3数据降维 2.4特征重要性 总结 特征选择时困难耗时的,也需要对需求的理解和专业知识的掌握.在机器学习的应用开发中,最基础的是特征工程. --吴恩达 1.数据预处理 数据预处理需要根据数据本身的特性进行,有缺失的要填补,有无效的要剔除,有冗余维的要删除,这些步骤都和数据本身的特性紧密相关. 1.1调整数据尺度 如果数据的各个属性按照不同的
-
python实现H2O中的随机森林算法介绍及其项目实战
H2O中的随机森林算法介绍及其项目实战(python实现) 包的引入:from h2o.estimators.random_forest import H2ORandomForestEstimator H2ORandomForestEstimator 的常用方法和参数介绍: (一)建模方法: model =H2ORandomForestEstimator(ntrees=n,max_depth =m) model.train(x=random_pv.names,y='Catrgory',train
-
python机器学习之随机森林(七)
机器学习之随机森林,供大家参考,具体内容如下 1.Bootstraping(自助法) 名字来自成语"pull up by your own bootstraps",意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法,它是非参数统计中一种重要的估计统计量方差进而进行区间估计的统计方法.其核心思想和基本步骤如下: (1) 采用重抽样技术从原始样本中抽取一定数量(自己给定)的样本,此过程允许重复抽样. (2) 根据抽出的样本计算给定的统计量T. (3) 重复上述N次(一般大于100
-
pyspark 随机森林的实现
随机森林是由许多决策树构成,是一种有监督机器学习方法,可以用于分类和回归,通过合并汇总来自个体决策树的结果来进行预测,采用多数选票作为分类结果,采用预测结果平均值作为回归结果. "森林"的概念很好理解,"随机"是针对森林中的每一颗决策树,有两种含义:第一种随机是数据采样随机,构建决策树的训练数据集通过有放回的随机采样,并且只会选择一定百分比的样本,这样可以在数据集合存在噪声点.异常点的情况下,有些决策树的构造过程中不会选择到这些噪声点.异常点从而达到一定的泛化作用在
-

Python机器学习利用随机森林对特征重要性计算评估
目录 1 前言 2 随机森林(RF)简介 3 特征重要性评估 4 举个例子 5 参考文献 1 前言 随机森林是以决策树为基学习器的集成学习算法.随机森林非常简单,易于实现,计算开销也很小,更令人惊奇的是它在分类和回归上表现出了十分惊人的性能,因此,随机森林也被誉为"代表集成学习技术水平的方法". 2 随机森林(RF)简介 只要了解决策树的算法,那么随机森林是相当容易理解的.随机森林的算法可以用如下几个步骤概括: 1.用有抽样放回的方法(bootstrap)从样本集中选取n个样本作为一个
-
Python决策树和随机森林算法实例详解
本文实例讲述了Python决策树和随机森林算法.分享给大家供大家参考,具体如下: 决策树和随机森林都是常用的分类算法,它们的判断逻辑和人的思维方式非常类似,人们常常在遇到多个条件组合问题的时候,也通常可以画出一颗决策树来帮助决策判断.本文简要介绍了决策树和随机森林的算法以及实现,并使用随机森林算法和决策树算法来检测FTP暴力破解和POP3暴力破解,详细代码可以参考: https://github.com/traviszeng/MLWithWebSecurity 决策树算法 决策树表现了对象属性和
-
Python实现的随机森林算法与简单总结
本文实例讲述了Python实现的随机森林算法.分享给大家供大家参考,具体如下: 随机森林是数据挖掘中非常常用的分类预测算法,以分类或回归的决策树为基分类器.算法的一些基本要点: *对大小为m的数据集进行样本量同样为m的有放回抽样: *对K个特征进行随机抽样,形成特征的子集,样本量的确定方法可以有平方根.自然对数等: *每棵树完全生成,不进行剪枝: *每个样本的预测结果由每棵树的预测投票生成(回归的时候,即各棵树的叶节点的平均) 著名的python机器学习包scikit learn的文档对此算法有
-
Python实现孤立随机森林算法的示例代码
目录 1 简介 2 孤立随机森林算法 2.1 算法概述 2.2 原理介绍 2.3 算法步骤 3 参数讲解 4 Python代码实现 5 结果 1 简介 孤立森林(isolation Forest)是一种高效的异常检测算法,它和随机森林类似,但每次选择划分属性和划分点(值)时都是随机的,而不是根据信息增益或基尼指数来选择. 2 孤立随机森林算法 2.1 算法概述 Isolation,意为孤立/隔离,是名词,其动词为isolate,forest是森林,合起来就是“孤立森林”了,也有叫“独异森林”,好
-
python实现决策树、随机森林的简单原理
本文申明:此文为学习记录过程,中间多处引用大师讲义和内容. 一.概念 决策树(Decision Tree)是一种简单但是广泛使用的分类器.通过训练数据构建决策树,可以高效的对未知的数据进行分类.决策数有两大优点:1)决策树模型可以读性好,具有描述性,有助于人工分析:2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度. 看了一遍概念后,我们先从一个简单的案例开始,如下图我们样本: 对于上面的样本数据,根据不同特征值我们最后是选择是否约会,我们先自定义的一个决策树
-
Python机器学习之决策树和随机森林
目录 什么是决策树 决策树组成 节点的确定方法 决策树基本流程 决策树的常用参数 代码实现决策树之分类树 网格搜索在分类树上的应用 分类树在合成数据的表现 什么是随机森林 随机森林的原理 随机森林常用参数 决策树和随机森林效果 实例用随机森林对乳腺癌数据的调参 什么是决策树 决策树属于经典的十大数据挖掘算法之一,是通过类似于流程图的数形结构,其规则就是iIF-THEN-的思想.,可以用于数值型因变量的预测或离散型因变量的分类,该算法简单直观,通俗易懂,不需要研究者掌握任何领域的知识或者复杂的数学
-
python机器学习基础决策树与随机森林概率论
目录 一.决策树原理概述 1.决策树原理 2.信息论 ①信息熵 ②决策树的分类依据 ③其他决策树使用的算法 ④决策树API 二.决策树算法案例 1.案例概述 2.数据处理 3.特征工程 4.使用决策树进行预测 5.决策树优缺点及改进 三.随机森林 1.集成学习方法 2.单个树建立过程 3.随机森林API 4.随机森林使用案例 5.随机森林的优点 一.决策树原理概述 1.决策树原理 决策树的分类原理,相当于程序中的if-then结构,通过条件判断,来决定结果. 2.信息论 ①信息熵 假设有32支球
-
python 人工智能算法之随机森林流程详解
目录 随机森林 优缺点总结 随机森林 (Random Forest)是一种基于决策树(前文有所讲解)的集成学习算法,它能够处理分类和回归两类问题. 随机森林的基本思想是通过随机选择样本和特征生成多个决策树,然后通过取多数投票的方式(分类问题)或均值计算的方式(回归问题)来得出最终的结果.具体来说,随机森林的训练过程可以分为以下几个步骤: 首先从原始数据集中随机选择一定数量的样本,构成一个新的训练集 从所有特征中随机选择一定数量的特征,作为该节点的候选特征 利用上述训练集和候选特征生成一棵决策树
-
Python语言描述随机梯度下降法
1.梯度下降 1)什么是梯度下降? 因为梯度下降是一种思想,没有严格的定义,所以用一个比喻来解释什么是梯度下降. 简单来说,梯度下降就是从山顶找一条最短的路走到山脚最低的地方.但是因为选择方向的原因,我们找到的的最低点可能不是真正的最低点.如图所示,黑线标注的路线所指的方向并不是真正的地方. 既然是选择一个方向下山,那么这个方向怎么选?每次该怎么走? 先说选方向,在算法中是以随机方式给出的,这也是造成有时候走不到真正最低点的原因. 如果选定了方向,以后每走一步,都是选择最陡的方向,直到最低点.