浅析redis cluster介绍与gossip协议
一、redis cluster 介绍
- 自动将数据进行分片,每个 master 上放一部分数据
- 提供内置的高可用支持,部分 master 不可用时,还是可以继续工作的
redis cluster架构下的每个redis都要开放两个端口号,比如一个是6379,另一个就是加1w的端口号16379。
- 6379端口号就是redis服务器入口。
- 16379端口号是用来进行节点间通信的,也就是 cluster bus 的东西,cluster bus 的通信,用来进行故障检测、配置更新、故障转移授权。cluster bus 用的是一种叫gossip 协议的二进制协议,用于节点间高效的数据交换,占用更少的网络带宽和处理时间。
二、节点间的内部通信机制
集群元数据的维护有两种方式:集中式、Gossip 协议。
redis cluster 节点间采用 gossip 协议进行通信。
1. 集中式
将集群元数据集中存储在一个节点上。典型代表是大数据领域的 storm。它是分布式的大数据实时计算引擎,是集中式的元数据存储的结构,底层基于 zookeeper对所有元数据进行存储维护。
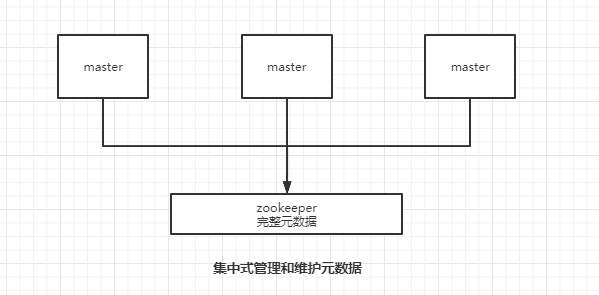
优点
元数据的读取和更新时效性非常好,元数据的变更都能立即更新到集中式存储节点中,其它节点读取的时候就可以感知到;
缺点
所有的元数据的更新压力全部集中在一个地方,可能会导致元数据的存储有压力。
2. gossip 协议
redis 维护集群元数据采用的是gossip 协议,所有节点都持有一份元数据,不同的节点如果出现了元数据的变更,就不断将元数据发送给其它的节点,让其它节点也进行元数据的变更。
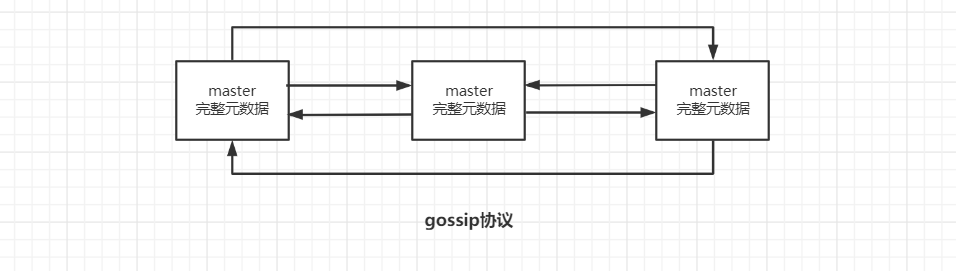
优点
元数据的更新比较分散,不是集中在一个地方,降低了压力;
缺点
元数据的更新有延时,可能导致集群中的一些操作会有一些滞后。
三、深入剖析gossip 协议
gossip 协议包含多种消息,包含 ping、pong、meet、fail等等。
meet:某个节点在内部发送了一个gossip meet 消息给新加入的节点,通知那个节点去加入我们的集群。然后新节点就会加入到集群的通信中
redis-trib.rb add-node
- ping:每个节点都会频繁给其它节点发送 ping,其中包含自己的状态还有自己维护的集群元数据,互相通过 ping 交换元数据。
- pong:ping 和 meet消息的返回响应,包含自己的状态和其它信息,也用于信息广播和更新。
- fail:某个节点判断另一个节点 fail 之后,就发送 fail 给其它节点,通知其它节点说这个节点已宕机。
继续深入剖析ping消息
- ping 时要携带一些元数据,如果很频繁,可能会加重网络负担。因此,一般每个节点每秒会执行 10 次 ping,每次会选择 5 个最久没有通信的其它节点。
- 当然如果发现某个节点通信延时达到了 cluster_node_timeout / 2,那么立即发送 ping,避免数据交换延时过长导致信息严重滞后。比如说,两个节点之间都 10 分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题。所以 cluster_node_timeout 可以调节,如果调得比较大,那么会降低 ping 的频率。
- 每次 ping,会带上自己节点的信息,还有就是带上 1/10 其它节点的信息,发送出去,进行交换。至少包含 3 个其它节点的信息,最多包含 总节点数减 2 个其它节点的信息。
10000 端口:
每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如 6379,那么用于节点间通信的就是16379端口。每个节点每隔一段时间都会往另外几个节点发送 ping 消息,同时其它几个节点接收到 ping 之后返回 pong。
交换的信息:信息包括故障信息,节点的增加和删除,hash slot 信息等等。
总结
到此这篇关于redis cluster介绍与gossip协议的文章就介绍到这了,更多相关redis cluster和gossip协议内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Windows环境下Redis Cluster环境搭建(图文)
搭建 Redis集群,三个主节点,三个从节点,多主节点为了分布集群,从节点是为了高可用性. 1. 下载redis 地址:https://github.com/MicrosoftArchive/redis/releases 此次案例中使用的版本为3.0.503 Source code可以一起下载,下文会用到. 2. 安装redis 解压Redis-x64-3.0.503.zip,并复制,如下图 3. 修改每台redis.windows.conf,修改里面的端口号,以及集群的配置 port 6380
-
如何用docker部署redis cluster的方法
前言 由于本人是个docker控,不喜欢安装各种环境,而且安装redis-trib也有点繁琐,索性用docker来做redis cluster. 本文用的是伪集群,真正的集群放到不同的机器即可.端口是7001-7006. 工作目录: /data/redis 创建文件夹 首先创建一堆对应端口的文件夹,下面是脚本 create.sh for i in `seq 7001 7006` do mkdir -p ${i}/data done 添加执行权限并执行 chmod 777 create.sh ./
-
Spring-data-redis操作redis cluster的示例代码
Redis 3.X版本引入了集群的新特性,为了保证所开发系统的高可用性项目组决定引用Redis的集群特性.对于Redis数据访问的支持,目前主要有二种方式:一.以直接调用jedis来实现:二.使用spring-data-redis,通过spring的封装来调用.下面分别对这二种方式如何操作Redis进行说明. 一.利用Jedis来实现 通过Jedis操作Redis Cluster的模型可以参考Redis官网,具体如下: Set<HostAndPort> jedisClusterNodes =
-
Redis Cluster添加、删除的完整操作步骤
前言 最近学习了Redis,发现Redis还是挺好玩的,今天测试了集群的添加.删除节点.重分配slot等.更深入的理解redis的游戏规则.步骤繁多,但是详细,话不多说了,来一起看看详细的介绍吧. 环境解释: 我是在一台Centos 6.9上测试的,各个redis节点以端口号区分.文中针对各个redis,我只是以端口号代表. ~~~~Master Node~~~~~ 172.16.32.116:7000 172.16.32.116:7001 172.16.32.116:7002 ~~~~Slav
-
浅析redis cluster介绍与gossip协议
一.redis cluster 介绍 自动将数据进行分片,每个 master 上放一部分数据 提供内置的高可用支持,部分 master 不可用时,还是可以继续工作的 redis cluster架构下的每个redis都要开放两个端口号,比如一个是6379,另一个就是加1w的端口号16379. 6379端口号就是redis服务器入口. 16379端口号是用来进行节点间通信的,也就是 cluster bus 的东西,cluster bus 的通信,用来进行故障检测.配置更新.故障转移授权.cluste
-
Redis Cluster集群数据分片机制原理
Redis Cluster数据分片机制 Redis 集群简介 Redis Cluster 是 Redis 的分布式解决方案,在 3.0 版本正式推出,有效地解决了 Redis 分布式方面的需求. Redis Cluster 一般由多个节点组成,节点数量至少为 6 个才能保证组成完整高可用的集群,其中三个为主节点,三个为从节点.三个主节点会分配槽,处理客户端的命令请求,而从节点可用在主节点故障后,顶替主节点. 如上图所示,该集群中包含 6 个 Redis 节点,3主3从,分别为M1,M2,M3,S
-

解析Redis Cluster原理
目录 一.前言 二.为什么需要Redis Cluster 三.Redis Cluster是什么 四.节点负载均衡 五.什么是一致性哈希 六.虚拟节点机制 七.Redis Cluster采用的什么算法 八.Redis Cluster如何做到高可用 8.1.集群如何进行扩容 8.2.高可用及故障转移 九.简单了解gossip协议 十.gossip协议消息类型 十一.使用gossip的优劣 十二.总结 一.前言 Sentinel集群会对Redis的主从架构中的Redis实例进行监控,一旦发现了mast
-
浅析Redis Sentinel 与 Redis Cluster
一.前言 互联网高速发展的今天,对应用系统的抗压能力要求越来越高,传统的应用层+数据库已经不能满足当前的需要.所以一大批内存式数据库和Nosql数据库应运而生,其中redis,memcache,mongodb,hbase等被广泛的使用来提高系统的吞吐性,所以如何正确使用cache是作为开发的一项基技能.本文主要介绍Redis Sentinel 及 Redis Cluster的区别及用法,Redis的基本操作可以自行去参看其官方文档 . 其他几种cache有兴趣的可自行找资料去学习. 二.Redi
-
Redis cluster集群的介绍
1.前言 Redis集群模式主要有2种: 主从集群.分布式集群. 前者主要是为了高可用或是读写分离,后者为了更好的存储数据,负载均衡. redis集群提供了以下两个好处 1.将数据自动切分(split)到多个节点 2.当集群中的某一个节点故障时,redis还可以继续处理客户端的请求. 一个 redis 集群包含 16384 个哈希槽(hash slot),数据库中的每个数据都属于这16384个哈希槽中的一个.集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽.集群中
-
Redis cluster集群模式的原理解析
redis cluster redis cluster是Redis的分布式解决方案,在3.0版本推出后有效地解决了redis分布式方面的需求 自动将数据进行分片,每个master上放一部分数据 提供内置的高可用支持,部分master不可用时,还是可以继续工作的 支撑N个redis master node,每个master node都可以挂载多个slave node 高可用,因为每个master都有salve节点,那么如果mater挂掉,redis cluster这套机制,就会自动将某个slave
-
k8s部署redis cluster集群的实现
Redis 介绍 Redis代表REmote DIctionary Server是一种开源的内存中数据存储,通常用作数据库,缓存或消息代理.它可以存储和操作高级数据类型,例如列表,地图,集合和排序集合. 由于Redis接受多种格式的密钥,因此可以在服务器上执行操作,从而减少了客户端的工作量. 它仅将磁盘用于持久性,而将数据完全保存在内存中. Redis是一种流行的数据存储解决方案,并被GitHub,Pinterest,Snapchat,Twitter,StackOverflow,Flickr等技
-
基于Redis6.2.6版本部署Redis Cluster集群的问题
目录 1.Redis6.2.6简介以及环境规划 2.二进制安装Redis程序 2.1.二进制安装redis6.2.6 2.2.创建Reids Cluster集群目录 3.配置Redis Cluster三主三从交叉复制集群 3.1.准备六个节点的redis配置文件 3.2.将六个节点全部启动 3.3.配置集群节点之间相互发现 3.4.为集群中的充当Master的节点分配槽位 3.5.配置三主三从交叉复制模式 4.快速搭建Redis Cluster集群 1.Redis6.2.6简介以及环境规划 在R
-
浅析Redis 切片集群的数据倾斜问题
目录 Redis 中如何应对数据倾斜 什么是数据倾斜 数据量倾斜 bigkey导致倾斜 Slot分配不均衡导致倾斜 Hash Tag导致倾斜 数据访问倾斜 总结 参考 Redis 中如何应对数据倾斜 什么是数据倾斜 如果 Redis 中的部署,采用的是切片集群,数据是会按照一定的规则分散到不同的实例中保存,比如,使用 Redis Cluster 或 Codis. 数据倾斜会有下面两种情况: 1.数据量倾斜:在某些情况下,实例上的数据分布不均衡,某个实例上的数据特别多. 2.数据访问倾斜:虽然每个