如何基于opencv实现简单的数字识别
目录
- 前言
- 要解决的问题
- 解决问题的思路
- 总结
前言
由于自己学识尚浅,不能用python深度学习来识别这里的数字,所以就完全采用opencv来识别数字,然后在这里分享、记录一下自己在学习过程中的一些所见所得和所想

要解决的问题
这是一个要识别的数字,我这里首先是对图像进行一个ROI的提取,提取结果就仅仅剩下数字,把其他的一些无关紧要的要素排除在外,

这是ROI图片,我们要做的就是识别出该照片中的数字,
解决问题的思路
1、先把这个图片中的数字分割,分割成为5张小图片,每张图片包含一个数字,为啥要分割呢?因为我们没办法让计算机知道这个数字是多少,所以只能根据特征,让计算机去识别特征,然后每一个特征对应一个值,首先贴出分割图片的程序,然后在程序下方会有一段思路解释
#include <opencv2/core/core.hpp>
#include <opencv.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <iostream>
#include <ctime>
using namespace std ;
using namespace cv;
#include <map>
Mat src_threshold;
Mat src_dil;
int sunImage(Mat &image);
vector<Mat>ROI_image;//待测图片
int main()
{
clock_t start ,finish;
start=clock();
Mat src;
src=imread("D:\\vspic\\picture\\number6.jpg");
resize(src,src,Size(src.cols/7,src.rows/7));
imshow("src",src);
Mat src_gray;
cvtColor(src,src_gray,COLOR_BGR2GRAY);
//imshow("gsrc_ray",src_gray);
Mat src_blur;
blur(src_gray,src_blur,Size(9,9));
//GaussianBlur(src_gray,src_blur,Size(11,11),1,1);
Mat src_threshold;
threshold(src_blur,src_threshold,150,255,THRESH_OTSU);
//imshow("src_threshold",src_threshold);
Mat src_canny;
Canny(src_threshold,src_canny,125,255,3);
//imshow("src_canny",src_canny);
vector<vector<Point>>contours_src;
vector<Vec4i>hierarchy_src(contours_src.size());
findContours(src_canny,contours_src,hierarchy_src,RETR_EXTERNAL,CHAIN_APPROX_NONE);
Rect rect_s;
Rect choose_rect;
for (size_t i=0;i<contours_src.size();i++)
{
rect_s=boundingRect(contours_src[i]);
double width=rect_s.width;
double height= rect_s.height;
double bizhi=width/height;
if (bizhi>1.5&&height>50)
{
/*rectangle(src,rect_s.tl(),rect_s.br(),Scalar(255,255,255),1,1,0);*/
choose_rect=Rect(rect_s.x+20,rect_s.y+30,rect_s.x-30,rect_s.y-108);
}
}
Mat roi;
roi=src(choose_rect);
//imshow("src_",roi);
Mat img =roi;
Mat gray_img;
// 生成灰度图像
cvtColor(img, gray_img, CV_BGR2GRAY);
// 高斯模糊
Mat img_gau;
GaussianBlur(gray_img, img_gau, Size(3, 3), 0, 0);
// 阈值分割
Mat img_seg;
threshold(img_gau, img_seg, 0, 255, THRESH_BINARY + THRESH_OTSU);
Mat element;
element=getStructuringElement(MORPH_RECT,Size(8,8));
erode(img_seg,src_dil,element);
//imshow("src_dil",src_dil);
// 边缘检测,提取轮廓
Mat img_canny;
Canny(src_dil, img_canny, 200, 100);
//imshow("canny",img_canny);
vector<vector<Point>> contours;
vector<Vec4i> hierarchy(contours.size());
findContours(img_canny, contours, hierarchy, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_NONE, Point());//寻找轮廓
int size = (int)(contours.size());//轮廓的数量
//cout<<size<<endl;6个
// 保存符号边框的序号
vector<int> num_order;//定义一个整型int容器
map<int, int> num_map;//容器,需要关键字和模板对象两个模板参数,此处定义一个int作为索引,并拥有相关连的指向int的指针
for (int i = 0; i < size; i++)
{
// 获取边框数据
Rect number_rect = boundingRect(contours[i]);
int width = number_rect.width;//获取矩形的宽
int height = number_rect.height;//获取矩形的高
// 去除较小的干扰边框,筛选出合适的区域
if (width > img.cols/20 )
{
rectangle(img,number_rect.tl(),number_rect.br(),Scalar(255,255,255),1,1,0);//绘制矩形
imshow("img",img);//显示矩形框
num_order.push_back(number_rect.x);//把矩形的x坐标放入number_order容器中,将一个新的元素添加到vector的最后面,
//位置为当前元素的下一个元素
num_map[number_rect.x] = i;//向map中存入键值对,number_rect.x是关键字,i是值
/*把矩形框的x坐标与对应的i值一起放入map容器中,形成一一对应的键值对
*/
}
}
// 按符号顺序提取
sort(num_order.begin(), num_order.end());/*把number_order容器中的内容按照从小到大的顺序排列,这里面是X的坐标*/
for (int i = 0; i < num_order.size(); i++) {
Rect number_rect = boundingRect(contours[num_map.find(num_order[i])->second]);//num_order里面放的是坐标
//cout<<"num_map的值是:"<<num_map.find(num_order[i])->second<<endl;
Rect choose_rect(number_rect.x, 0, number_rect.width, img.rows);//矩形左上角x,y的坐标以及矩形的宽和高
Mat number_img = img(choose_rect);
resize(number_img,number_img,Size(30,100));//归一化尺寸
ROI_image.push_back(number_img);//保存为待测图片
//imshow("number" + to_string(i), number_img);
char name[50];
sprintf_s(name,"D:\\vs2012\\model\\%d.jpg",i);//保存模板
imwrite(name, number_img);
}
cout<<"图片分割完毕"<<endl;
//加载模板
vector<Mat>temptImage;//存放模板
for (int i=0;i<4;i++)
{
char name[50];
sprintf_s(name,"D:\\vs2012\\model\\%d.jpg",i);
Mat temp;
temp=imread(name);
//cout<<"加载模板图片通道数:"<<temp.channels()<<endl;
temptImage.push_back(temp);
}
vector<int>seq;//存放顺序结果
for (int i=0;i<ROI_image.size();i++)
{
Mat subImage;
int sum=0;
int min=50000;
int seq_min=0;//记录最小的和对应的数字
for (int j=0;j<4;j++)
{
absdiff(ROI_image[i],temptImage[j],subImage);//待测图片像素减去模板图片像素
sum=sunImage(subImage);//统计像素和
if (sum<min)
{
min=sum;
seq_min=j;
}
sum=0;
}
seq.push_back(seq_min);
}
cout<<"输出数字匹配结果:";//endl是换行的意思
for (int i=0;i<seq.size();i++)//输出结果,小数点固定在第3位
{
cout<<seq[i];
if (i==1)
{
cout<<".";
}
}
finish=clock();
double all_time=double(finish-start)/CLOCKS_PER_SEC;
/*cout<<"运行总时间是:"<<all_time<<endl;*/
waitKey(0);
return 0;
}
//计算像素和
int sunImage(Mat &image)
{
int sum=0;
for (int i=0;i<image.cols;i++)
{
for (int j=0;j<image.rows;j++)
{
sum+=image.at<uchar>(j,i);
}
}
return sum;
}
整体思路是这样子的:0-9这10个数字也都是已经被分割好的,并且保存好了,也就是模板,然后我们把待测的图片也分割掉,然后从0-9模板文件夹中去读取模板图片,让待测的分割完毕的图片去和10个模板逐个相减,然后去统计他们相减后的像素和,如果这个在这10个中最低,那么他们就是同一个数字,然后输出值就可以了,分割后的大概是这样

上边是第一种方法,然后还有第二种,是穿针引线的方法,是根据晶体管数字特征来识别的
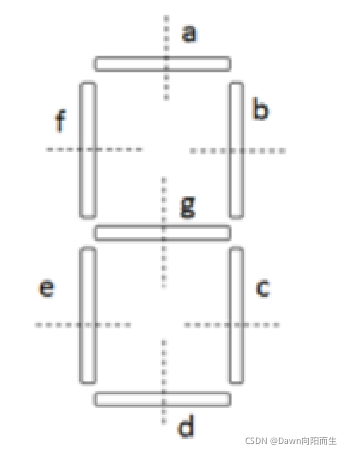
这是晶体管数字的特征,每个0-9每个数字都是不一样的,我们下一篇文章再做详细的介绍
总结
到此这篇关于如何基于opencv实现简单的数字识别的文章就介绍到这了,更多相关opencv实现数字识别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python基于OpenCV模板匹配识别图片中的数字
前言 本博客主要实现利用OpenCV的模板匹配识别图像中的数字,然后把识别出来的数字输出到txt文件中,如果识别失败则输出"读取失败". 操作环境: OpenCV - 4.1.0 Python 3.8.1 程序目标 单个数字模板:(这些单个模板是我自己直接从图片上截取下来的) 要处理的图片: 终端输出: 文本输出: 思路讲解 代码讲解 首先定义两个会用到的函数 第一个是显示图片的函数,这样的话在显示图片的时候就比较方便了 def cv_show(name, img): cv2.imsh
-
python opencv实现信用卡的数字识别
本项目利用python以及opencv实现信用卡的数字识别 前期准备 导入工具包 定义功能函数 模板图像处理 读取模板图像 cv2.imread(img) 灰度化处理 cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) 二值化 cv2.threshold() 轮廓 - 轮廓 信用卡图像处理 读取信用卡图像 cv2.imread(img) 灰度化处理 cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) 礼帽处理 cv2.morphologyEx(gray
-
详解Python OpenCV数字识别案例
前言 实践是检验真理的唯一标准. 因为觉得一板一眼地学习OpenCV太过枯燥,于是在网上找了一个以项目为导向的教程学习.话不多说,动手做起来. 一.案例介绍 提供信用卡上的数字模板: 要求:识别出信用卡上的数字,并将其直接打印在原图片上.虽然看起来很蠢,但既然可以将数字打印在图片上,说明已经成功识别数字,因此也可以将其转换为数字文本保存.车牌号识别等项目的思路与此案例类似. 示例: 原图 处理后的图 二.步骤 大致分为如下几个步骤: 1.模板读入 2.模板预处理,将模板数字分开,并排序 3.输入
-
Python+Opencv实现数字识别的示例代码
一.什么是数字识别? 所谓的数字识别,就是使用算法自动识别出图片中的数字.具体的效果如下图所示: 上图展示了算法的处理效果,算法能够自动的识别到LCD屏幕上面的数字,这在现实场景中具有很大的实际应用价值.下面我们将对它的实现细节进行详细解析. 二.如何实现数字识别? 对于数字识别这个任务而言,它并不是一个新的研究方向,很久之前就有很多的学者们在关注这个问题,并提出了一些可行的解决方案,本小节我们将对这些方案进行简单的总结. 方案一:使用现成的OCR技术. OCR,即文字识别,它是一个比较
-
如何基于opencv实现简单的数字识别
目录 前言 要解决的问题 解决问题的思路 总结 前言 由于自己学识尚浅,不能用python深度学习来识别这里的数字,所以就完全采用opencv来识别数字,然后在这里分享.记录一下自己在学习过程中的一些所见所得和所想 要解决的问题 这是一个要识别的数字,我这里首先是对图像进行一个ROI的提取,提取结果就仅仅剩下数字,把其他的一些无关紧要的要素排除在外, 这是ROI图片,我们要做的就是识别出该照片中的数字, 解决问题的思路 1.先把这个图片中的数字分割,分割成为5张小图片,每张图片包含一个数字,为啥
-
Python基于opencv的简单图像轮廓形状识别(全网最简单最少代码)
可以直接跳到最后整体代码看一看是不是很少的代码!!!! 思路: 1. 数据的整合 2. 图片的灰度转化 3. 图片的二值转化 4. 图片的轮廓识别 5. 得到图片的顶点数 6. 依据顶点数判断图像形状 一.原数据的展示 图片文件共36个文件夹,每个文件夹有100张图片,共3600张图片. 每一个文件夹里都有形同此类的图形 二.数据的整合 对于多个文件夹,分析起来很不方便,所有决定将其都放在一个文件夹下进行分析,在python中具体实现如下: 本次需要的包 import cv2 import os
-
OpenCV简单标准数字识别的完整实例
在学习openCV时,看到一个问答做数字识别,里面配有代码,应用到了openCV里面的ml包,很有学习价值. https://stackoverflow.com/questions/9413216/simple-digit-recognition-ocr-in-opencv-python# import sys import numpy as np import cv2 im = cv2.imread('t.png') im3 = im.copy() gray = cv2.cvtColor(im
-
Python基于OpenCV库Adaboost实现人脸识别功能详解
本文实例讲述了Python基于OpenCV库Adaboost实现人脸识别功能.分享给大家供大家参考,具体如下: 以前用Matlab写神经网络的面部眼镜识别算法,研究算法逻辑,采集大量训练数据,迭代,计算各感知器的系数...相当之麻烦~而现在运用调用pythonOpenCV库Adaboost算法,无需知道算法逻辑,无需进行模型训练,人脸识别变得相当之简单了. 需要用到的库是opencv(open source computer vision),下载安装方式如下: 使用pip install num
-
Python开发之基于模板匹配的信用卡数字识别功能
环境介绍 Python 3.6 + OpenCV 3.4.1.15 原理介绍 首先,提取出模板中每一个数字的轮廓,再对信用卡图像进行处理,提取其中的数字部分,将该部分数字与模板进行匹配,即可得到结果. 模板展示 完整代码 # !/usr/bin/env python # -*- coding: utf-8 -*- # @Time: 2020/1/11 14:57 # @Author: Martin # @File: utils.py # @Software:PyCharm import cv2
-
基于OpenMV的图像识别之数字识别功能
目录 基于OpenMV的图像识别 OpenMV简介 一.数字识别 基于OpenMV的图像识别 OpenMV简介 什么是OpenMV OpenMV是由美国克里斯团队基于MicroPython发起的开源机器视觉项目,目的是创建低成本,可扩展,使用python驱动的机器视觉模块.OpenMV搭载了MicroPython解释器,使其可以在嵌入式端进行python开发,关于MicroPython可以参照我之前的博客专栏:MicroPython. OpenMV基于32位,ARM Cortex-M7内核的Op
-
基于Opencv图像识别实现答题卡识别示例详解
目录 1. 项目分析 2.项目实验 3.项目结果 总结 在观看唐宇迪老师图像处理的课程中,其中有一个答题卡识别的小项目,在此结合自己理解做一个简单的总结. 1. 项目分析 首先在拿到项目时候,分析项目目的是什么,要达到什么样的目标,有哪些需要注意的事项,同时构思实验的大体流程. 图1. 答题卡测试图像 比如在答题卡识别的项目中,针对测试图片如图1 ,首先应当实现的功能是: 能够捕获答题卡中的每个填涂选项. 将获取的填涂选项与正确选项做对比计算其答题正确率. 2.项目实验 在对测试图像进行形态学操
-
基于Python实现简单的人脸识别系统
目录 前言 基本原理 代码实现 创建虚拟环境 安装必要的库 前言 最近又多了不少朋友关注,先在这里谢谢大家.关注我的朋友大多数都是大学生,而且我简单看了一下,低年级的大学生居多,大多数都是为了完成课程设计,作为一个过来人,还是希望大家平时能多抽出点时间学习一下,这种临时抱佛脚的策略要少用嗷.今天我们来python实现一个人脸识别系统,主要是借助了dlib这个库,相当于我们直接调用现成的库来进行人脸识别,就省去了之前教程中的数据收集和模型训练的步骤了. B站视频:用300行代码实现人脸识别系统_哔
-
基于opencv和pillow实现人脸识别系统(附demo)
目录 一.人脸检测和数据收集 二.训练识别器 三.人脸识别和显示 本文不涉及分类器.训练识别器等算法原理,仅包含对其应用(未来我也会写自己对机器学习算法原理的一些观点和了解) 首先我们需要知道的是利用现有框架做一个人脸识别系统并不难,然后就开始我们的系统开发吧. 我们的系统主要分为三个部分,然后我还会提出对补获图片不能添加中文的解决方案.我们需要完成的任务:1.人脸检测和数据收集2.训练识别器3.人脸识别和显示 在读此篇文章之前我相信你已经做了python环境部署和opencv模块的下载安装工作