Python模拟登录微博并爬取表情包
一、开发工具
**Python****版本:**3.6.4
相关模块:
DecryptLogin模块;
argparse模块;
requests模块;
prettytable模块;
tqdm模块;
lxml模块;
fake_useragent模块;
以及一些Python自带的模块。
二、环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
三、原理简介
本来这个爬虫是想作为讲python异步爬虫的一个例子的,昨天代码写完测试了一下,结果是我微博账号和ip都直接被封了(并发数设的500)。
然后我去谷歌搜了一下别人写的异步爬虫教程,测试用的都是些没啥反爬措施的小网站。
于是今天改了下代码,就先整个普普通通的微博小爬虫算了。
言归正传,和之前的微博爬虫类似,我们还是先利用DecryptLogin进行微博账户的模拟登录:
'''模拟登录''' @staticmethod def login(username, password): lg = login.Login() _, session = lg.weibo(username, password, 'mobile') return session
然后让使用者输入目标微博用户的id:
user_id = input('请输入目标用户ID(例如: 2168613091) ——> ')
微博用户id在这可以看到:
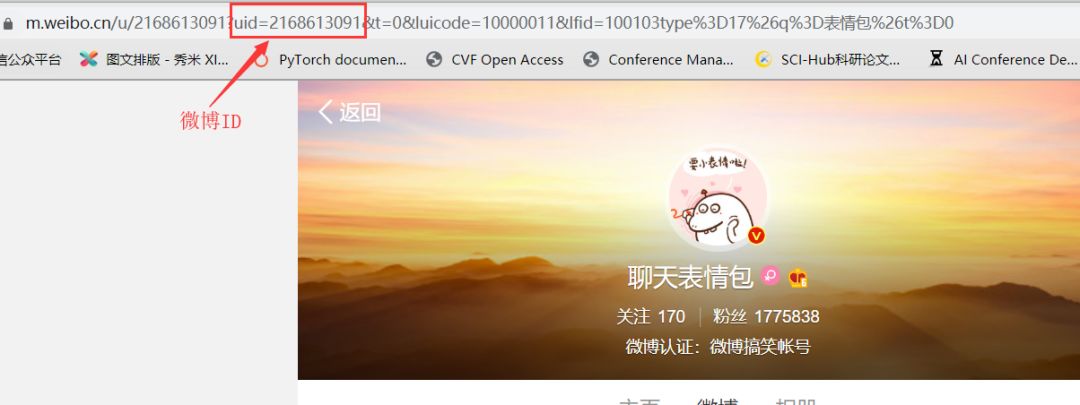
根据用户输入的微博用户id,我们访问如下两个链接:
url = f'https://weibo.cn/{user_id}'
url = f'https://weibo.cn/{user_id}/info'
然后利用xpath提取用户的基本信息:


打印这些信息,让使用者确认自己输入的微博用户id是否无误:
tb = prettytable.PrettyTable()
tb.field_names = ['用户名', '关注数量', '被关注数量', '微博数量', '微博页数']
tb.add_row([nickname, num_followings, num_followers, num_wbs, num_wb_pages])
print('获取的用户信息如下:')
print(tb)
is_download = input('是否爬取该微博用户发的所有图片?(y/n, 默认: y) ——> ')
如果无误,就开始爬取该用户发的所有微博里的图片:
'''下载所有图片'''
def __downloadImages(self, userinfos, savedir):
# 一些必要的信息
num_wbs = userinfos.get('num_wbs')
user_id = userinfos.get('user_id')
num_wb_pages = userinfos.get('num_wb_pages')
# 提取图片链接并下载图片
page_block_size = random.randint(1, 5)
page_block_count = 0
for page in tqdm(range(1, num_wb_pages+1)):
# --提取图片链接
response = self.session.get(f'https://weibo.cn/{user_id}?page={page}', headers=self.headers)
image_urls = self.__extractImageUrls(response)
# --下载图片
for url in image_urls:
try:
res = requests.get(url, headers={'user-agent': self.ua.random}, stream=True)
with open(os.path.join(savedir, url.split('/')[-1]), 'wb') as fp:
for chunk in res.iter_content(chunk_size=32):
fp.write(chunk)
print('[INFO]: Download an image from: ', url)
except:
pass
# --避免给服务器带来过大压力and避免被封, 每爬几页程序就休息一下
page_block_count += 1
if page_block_count % page_block_size == 0:
time.sleep(random.randint(6, 12))
page_block_size = random.randint(1, 5)
page_block_count = 0
这里避免爬虫被BAN的措施主要有以下几点:
- 每爬n页数据就暂停x秒,其中n是随机生成的,且n一直在变化,x也是随机生成的,且x也一直在变化;
- 下载图片时,使用随机的ua,并且不使用登录后的session来请求图片链接来下载该图片。
从返回的微博页内容里提取图片链接时,需要注意:
- 对转发微博的微博id和原创微博的微博id提取方式不同;
- 只有单张图片的微博和有多张图片的微博提取图片链接的方式是不同的;
- 有时候图片链接提取会出错,http变成了ttp,所以需要对提取的图片链接进行后处理,然后再去请求这些链接来下载图片。
大体的思路就是这样,因为其实没啥难点,就是用xpath来提取我们需要的信息就行了,所以就这么粗略地介绍一下吧。T_T
运行方式:
python weiboEmoji.py --username 用户名 --password 密码
到此这篇关于Python模拟登录微博并爬取表情包的文章就介绍到这了,更多相关Python爬取微博表情包内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python模拟登录和登录跳转的参考示例
# coding:utf-8 import urllib import urllib2 import cookielib from bs4 import BeautifulSoup # 设置登录url login_url = "******************" # 创建登录类 class Login(object): #初始化 def __init__(self): self.username = '' self.password = '' # 验证码 self.rode = '
-

使用Python制作表情包实现换脸功能
"表情包"是现在非常流行的交流方式,通过一张图片就能把文字不能表达或不便于表达的情感给表示出来,表情包一经诞生,就统治了中国人的社交圈,尤其是年轻人,他们的社交方式是所谓"天可不聊,图不可不斗",几乎任何对话都会出现表情包的身影,一言不合就斗图,自己也会在聊天中发几个表情包,可是总会造成一些小误会,比如下面的图 有好多朋友看到这个表情包之后误以为这也是我用Python做的,其实不然,这个图就是网上普通的表情包,但是今天我要用Python做几个表情包. 今天制作表情包
-
python爬虫豆瓣网的模拟登录实现
思路 一.想要实现登录豆瓣关键点 分析真实post地址 ----寻找它的formdata,如下图,按浏览器的F12可以找到. 实战操作 实现:模拟登录豆瓣,验证码处理,登录到个人主页就算是success 数据:没有抓取数据,此实战主要是模拟登录和处理验证码的学习.要是有需求要抓取数据,编写相关的抓取规则即可抓取内容. 登录成功展示如图: spiders文件夹中DouBan.py主要代码如下: # -*- coding: utf-8 -*- import scrapy,urllib,re from
-
Python实现微信表情包炸群功能
Python实现微信表情包炸群效果,具体代码如下所示: # -*- coding = utf-8 -*- # @Time : 2021/1/26 15:19 # @Author : 陈良兴 # @File : 微信表情包炸群.py # @Software : PyCharm # 运行程序 > 输入次数 > 回车 > 打开微信对话框 > 将鼠标放置在"发送"按钮处即可 from pynput.keyboard import Controller as KB #控制
-
Python3以GitHub为例来实现模拟登录和爬取的实例讲解
我们先以一个最简单的实例来了解模拟登录后页面的抓取过程,其原理在于模拟登录后 Cookies 的维护. 1. 本节目标 本节将讲解以 GitHub 为例来实现模拟登录的过程,同时爬取登录后才可以访问的页面信息,如好友动态.个人信息等内容. 我们应该都听说过 GitHub,如果在我们在 Github 上关注了某些人,在登录之后就会看到他们最近的动态信息,比如他们最近收藏了哪个 Repository,创建了哪个组织,推送了哪些代码.但是退出登录之后,我们就无法再看到这些信息. 如果希望爬取 GitH
-
Python基础进阶之海量表情包多线程爬虫功能的实现
一.前言 在我们日常聊天的过程中会使用大量的表情包,那么如何去获取表情包资源呢?今天老师带领大家使用python中的爬虫去一键下载海量表情包资源 二.知识点 requests网络库 bs4选择器 文件操作 多线程 三.所用到得库 import os import requests from bs4 import BeautifulSoup 四. 功能 # 多线程程序需要用到的一些包 # 队列 from queue import Queue from threading import Thread
-
python中requests模拟登录的三种方式(携带cookie/session进行请求网站)
一,cookie和session的区别 cookie在客户的浏览器上,session存在服务器上 cookie是不安全的,且有失效时间 session是在cookie的基础上,服务端设置session时会向浏览器发送设置一个设置cookie的请求,这个cookie包括session的id当访问服务端时带上这个session_id就可以获取到用户保存在服务端对应的session 二,爬虫处理cookie和session 带上cookie和session的好处: 能够请求到登录后的界面 带上cook
-
python爬取企查查企业信息之selenium自动模拟登录企查查
最近接了个小项目需要批量搜索企查查上的相关企业并把指定信息保存到Excel文件中,由于企查查需要登录后才能查看所有搜索到的信息所以第一步需要模拟登录企查查. python模拟登录企查查最重要的是自动拖拽验证插件 先介绍下项目中使用到的工具与库 Python的selenium库: Web应用程序测试的工具,Selenium可以模拟用户在浏览器中的操作,就像真实用户使用一样. 官方技术文档:https://www.selenium.dev/selenium/docs/api/py/index.htm
-
Python自动生产表情包
作为一个数据分析师,应该信奉一句话--"一图胜千言".不过这里要说的并不是数据可视化,而是一款全民向的产品形态--表情包!!!! 表情包不仅仅是一种符号,更是一种文化--是促进社交乃至社会发展的动力之一,就像懒.我们坚持认为,一张优秀的表情包,应该是一幅艺术品,是那忽如一夜春风来的灵感爆发,是那嘈嘈切切错杂弹的情思激荡,是那直挂云帆济沧海的壮志豪情,是那一览天下众山小的荣耀胜利--是不可以容忍码农用其惯有的形式固定.流程固定.毫无美感.毫无艺术的变幻和惊喜的直线思维解构.然而,在生产表
-
Python模拟登录微博并爬取表情包
一.开发工具 **Python****版本:**3.6.4 相关模块: DecryptLogin模块: argparse模块: requests模块: prettytable模块: tqdm模块: lxml模块: fake_useragent模块: 以及一些Python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 本来这个爬虫是想作为讲python异步爬虫的一个例子的,昨天代码写完测试了一下,结果是我微博账号和ip都直接被封了(并发数
-
Python基于百度AI实现抓取表情包
本文先抓取网络上的表情图像,然后利用百度 AI 识别表情包上的说明文字,并利用表情文字重命名文件,这样当发表情包时,不需要逐个打开查找,直接根据文件名选择表情并发送. 一.百度 AI 开放平台的 Key 申请方法 本例使用了百度 AI 的 API 接口实现文字识别.因此需要先申请对应的 API 使用权限,具体步骤如下: 在网页浏览器(比如 Chrome 或者火狐) 的地址栏中输入 ai.baidu.com,进入到百度云 AI 的官网,在该页面中单击右上角的 控制台 按钮. 进入到百度云 AI 官
-
python制作微博图片爬取工具
有小半个月没有发博客了,因为一直在研究python的GUI,买了一本书学习了一些基础,用我所学做了我的第一款GUI--微博图片爬取工具.本软件源代码已经放在了博客中,另外软件已经打包好上传到网盘中以供下载学习. 一.准备工作 本次要用到以下依赖库:re json os random tkinter threading requests PIL 其中后两个需要安装后使用 二.预览 1.启动 2.运行中 3.结果 这里只将拿一张图片作为展示. 三.设计流程 设计流程分为总体设计和详细设计,这里我会使
-
详解如何用Python登录豆瓣并爬取影评
目录 一.需求背景 二.功能描述 三.技术方案 四.登录豆瓣 1.分析豆瓣登录接口 2.代码实现登录豆瓣 3.保存会话状态 4.这个Session对象是我们常说的session吗? 五.爬取影评 1.分析豆瓣影评接口 2.爬取一条影评数据 3.影评内容提取 4.批量爬取 六.分析影评 1.使用结巴分词 七.总结 上一篇我们讲过Cookie相关的知识,了解到Cookie是为了交互式web而诞生的,它主要用于以下三个方面: 会话状态管理(如用户登录状态.购物车.游戏分数或其它需要记录的信息) 个性化
-
Python 微信公众号文章爬取的示例代码
一.思路 我们通过网页版的微信公众平台的图文消息中的超链接获取到我们需要的接口 从接口中我们可以得到对应的微信公众号和对应的所有微信公众号文章. 二.接口分析 获取微信公众号的接口: https://mp.weixin.qq.com/cgi-bin/searchbiz? 参数: action=search_biz begin=0 count=5 query=公众号名称 token=每个账号对应的token值 lang=zh_CN f=json ajax=1 请求方式: GET 所以这个接口中我们
-
详解如何用Python模拟登录淘宝
目录 一.淘宝登录流程 二.模拟登录实现 1.判断是否需要验证码 2.验证用户名密码 3.申请st码 4.使用st码登录 5.获取淘宝昵称 三.总结 1.代码结构 2.存在问题 看了下网上有很多关于模拟登录淘宝,但是基本都是使用scrapy.pyppeteer.selenium等库来模拟登录,但是目前我们还没有讲到这些库,只讲了requests库,那我们今天就来使用requests库模拟登录淘宝! 讲模拟登录淘宝之前,我们来回顾一下之前用requests库模拟登录豆瓣和新浪微博的过程:这一类模拟
-
python爬虫实战项目之爬取pixiv图片
自从接触python以后就想着爬pixiv,之前因为梯子有点问题就一直搁置,最近换了个梯子就迫不及待试了下. 爬虫无非request获取html页面然后用正则表达式或者beautifulsoup之类现成工具截取我们想要的页面,pixiv也不例外. 首先我们来实现模拟登陆,虽然大多数情况不需要我们实现模拟登录,但如果你是会员之类的,登录和不登录网页就有区别.思路是登录时抓包抓到post请求,看pixiv构建的post的数据表格是什么格式,我们根据这个格式构建form,然后调用post方法去请求,再
-
python爬虫系列Selenium定向爬取虎扑篮球图片详解
前言: 作为一名从小就看篮球的球迷,会经常逛虎扑篮球及湿乎乎等论坛,在论坛里面会存在很多精美图片,包括NBA球队.CBA明星.花边新闻.球鞋美女等等,如果一张张右键另存为的话真是手都点疼了.作为程序员还是写个程序来进行吧! 所以我通过Python+Selenium+正则表达式+urllib2进行海量图片爬取. 运行效果: http://photo.hupu.com/nba/tag/马刺 http://photo.hupu.com/nba/tag/陈露 源代码: # -*- coding: utf
-
Python进阶之使用selenium爬取淘宝商品信息功能示例
本文实例讲述了Python进阶之使用selenium爬取淘宝商品信息功能.分享给大家供大家参考,具体如下: # encoding=utf-8 __author__ = 'Jonny' __location__ = '西安' __date__ = '2018-05-14' ''' 需要的基本开发库文件: requests,pymongo,pyquery,selenium 开发流程: 搜索关键字:利用selenium驱动浏览器搜索关键字,得到查询后的商品列表 分析页码并翻页:得到商品页码数,模拟翻页
-
python根据用户需求输入想爬取的内容及页数爬取图片方法详解
本次小编向大家介绍的是根据用户的需求输入想爬取的内容及页数. 主要步骤: 1.提示用户输入爬取的内容及页码. 2.根据用户输入,获取网址列表. 3.模拟浏览器向服务器发送请求,获取响应. 4.利用xpath方法找到图片的标签. 5.保存数据. 代码用面向过程的形式编写的. 关键字:requests库,xpath,面向过程 现在就来讲解代码书写的过程: 1.导入模块 import parsel # 该模块主要用来将请求后的字符串格式解析成re,xpath,css进行内容的匹配 import req